
为什么多模型 AI 应用需要一个统一 API 层
TL;DR
多模型 AI 应用正在成为默认形态。一个产品可能同时使用一个模型做对话,一个模型做代码辅助,一个模型做结构化提取,再用图像或视频模型处理多模态工作流。
真正困难的地方不只是“多接几个 API”。困难在于:当模型组合不断变化时,团队还能不能稳定控制模型选择、用量记录、账单口径、成本策略、故障回退和生产运维。
统一 API 层的价值,不是让所有模型变得完全一样,也不是取代评估。它的价值在架构层面:在应用代码和模型能力之间提供一个稳定控制点,让产品团队和基础设施团队可以在同一层管理模型接入、模型切换、路由、可见性和运维策略。
大多数团队不是因为“想少记几个端点”才采用统一 LLM API。更准确地说,是因为多模型应用迟早需要一个控制层。
一旦应用依赖多个模型家族,问题就会从“能不能调用这个模型”变成“能不能在不反复改业务代码的前提下,管理模型选择、用量、成本、回退和可靠性”。
多模型应用正在成为默认架构
早期 AI 产品通常从一个模型和一个服务商开始。如果产品形态很窄,比如聊天框、摘要器、客服助手或简单内容生成器,这种做法很合理。
但现在的 AI 应用已经不同。一个真实产品可能同时包含:
- 用于分类或改写的快速模型
- 用于复杂用户问题的强推理模型
- 用于开发者工作流的代码模型
- 用于文档分析的长上下文模型
- 用于素材生成或编辑的图像模型
- 用于创意生产的视频模型
- 当某个服务商变慢、不可用或成本不合适时的回退路径
这会改变架构。模型选择不再是一次性的接入决策,而会变成一个持续运营决策:它可能随功能、用户层级、工作负载类型、延迟目标和预算变化。
对智能体构建者来说,这种压力更明显。一个智能体工作流可能包含意图分类、上下文检索、步骤规划、工具调用、结果总结和最终回复。每一步不一定需要同一个模型。如果所有模型选择都硬编码在应用代码里,产品后续会越来越难演进。
问题不只是 API 数量变多
很多团队一开始会把问题描述成:“我们需要接 OpenAI、Anthropic、Google,可能还要接几个图像或视频服务商。”这只是表层。
更深层的问题是运维口径不断漂移。
不同服务商可能在这些方面不一致:
- 鉴权和账号体系
- 模型标识
- 请求和响应结构
- 流式输出行为
- 限流和重试信号
- 用量报告
- 计费单位
- 错误语义
- 支持的模态和参数
- 发布节奏和废弃策略
即使两个服务商都提供 OpenAI 兼容端点,生产系统仍然需要处理模型级差异。OpenAI 兼容可以降低上手成本,但不能被当作完整的生产契约。
做架构判断时,问题不应该只是“能不能发出请求”。更关键的问题是:
应用能不能在不把服务商特定逻辑散落到代码库各处的前提下,切换模型、追踪用量、控制成本、处理故障并保持生产稳定?
这就是统一 API 层开始变得重要的地方。
常见误区:把统一 API 只当成接入捷径
一个常见错误,是只用“支持多少服务商”来评估统一 API。这会错过更重要的架构问题。
真正应该问的是:这个 API 层是否给团队提供了一个稳定位置,用来管理模型选择、用量可见性、成本策略、故障回退和生产运维。
如果某个层只是隐藏了服务商地址,却没有改善控制、可见性或运维一致性,那么它可能减少了一部分接入工作,但并没有解决多模型应用更难的问题。
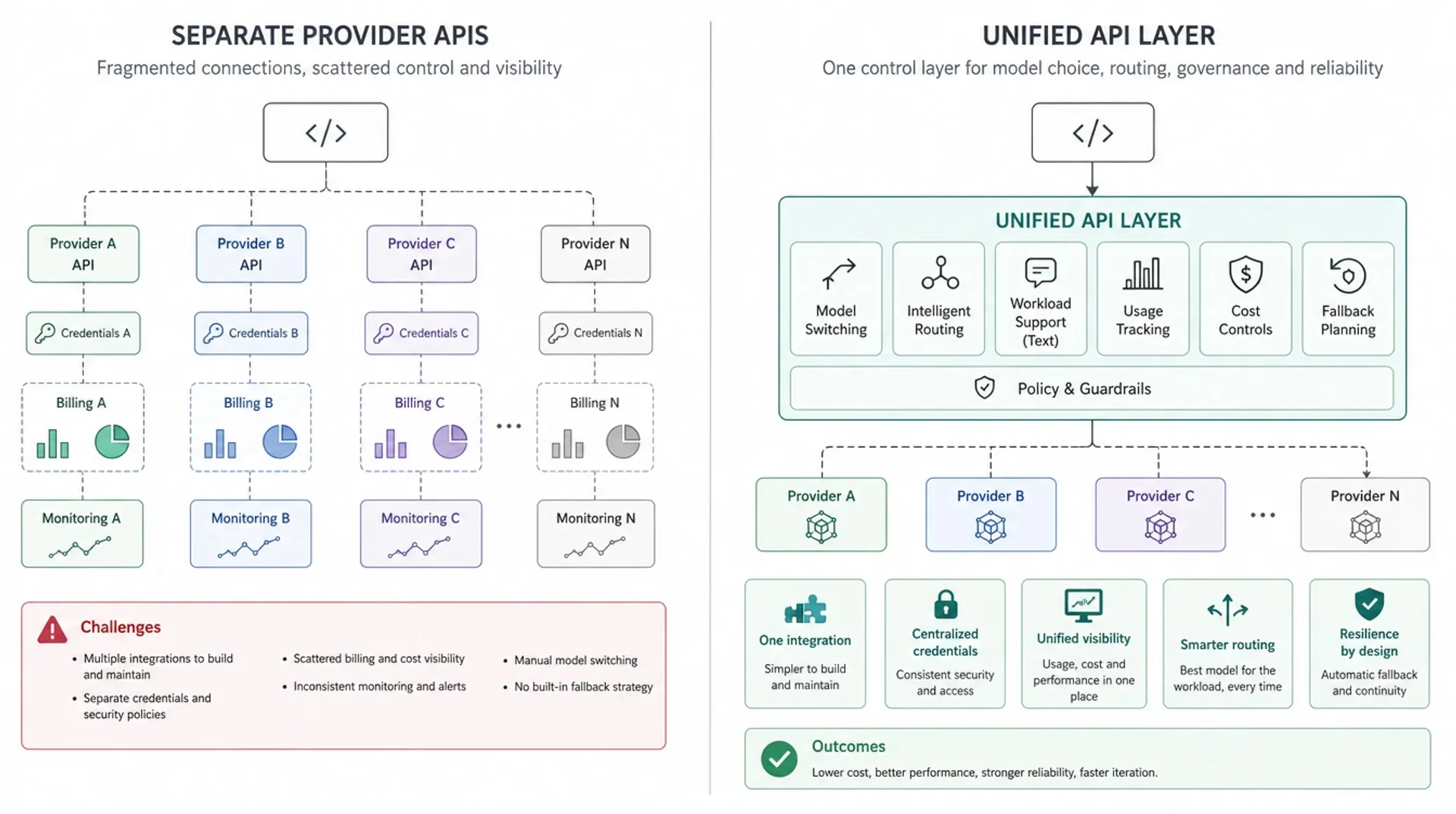
统一 API 层创造一个控制点
统一 API 层位于应用和底层模型服务商或模型路由之间。应用代码调用统一层,统一层承接那些不应该在每个功能团队里重复实现的共同能力。
最简单的版本通常提供:
- 一个基础地址
- 一套鉴权方式
- 一个选择支持模型的位置
- 一个用量和账单视图
- 一个未来引入路由、故障回退或策略控制的位置
更成熟的版本会演进成 AI 模型交付层:模型接入、面向支持的 LLM 请求的路由规则、用量可见性、成本控制、故障回退规划和生产运维,都围绕同一个 API 入口展开。
这不意味着所有模型都可以互换。统一 API 层不应该隐藏质量、延迟、模态、上下文窗口、工具调用行为或价格上的关键差异。好的架构应该让这些差异足够可见,便于评估,同时避免它们泄漏到应用代码的每个角落。
| 维度 | 分散接入模型服务商 API | 统一 API 层 |
|---|---|---|
| 集成方式 | 每个服务商都需要单独配置账号、密钥、SDK 和维护路径 | 对支持的模型保持一个集成入口 |
| 模型切换 | 经常需要改代码、换 SDK 路径或维护服务商适配器 | 通常变成模型或路由的选择问题 |
| 用量追踪 | 用量数据分散在不同服务商后台和内部日志里 | 可以汇总到更一致的报告视图 |
| 成本控制 | 团队需要跨不同账单后台和计费单位对账 | 成本策略可以更靠近 API 层管理 |
| 故障回退 | 每个服务可能各自实现重试或备用路径 | 可以在合适的位置集中规划故障回退 |
| 运维管理 | 事故、限流和模型变更会扩散到产品代码里 | 运维控制更靠近模型交付层 |
统一 API 层能带来什么
不重写应用也能切换模型
第一层价值很直接:模型切换的侵入性更低。
如果没有统一层,从一个服务商或模型家族切到另一个,可能意味着新的密钥、新的 SDK、请求映射、响应解析、用量统计调整和新的运维手册。
有了统一 API 层,应用可以保持相对稳定的集成契约,模型选择则在这个契约背后变化。这不代表输出质量会完全一致,而是意味着集成路径不再是主要阻碍。
举个例子:
- 客服工作流一开始使用一个平衡型模型。
- 后来,高频分类任务迁移到更快或更低成本的模型。
- 复杂升级场景使用更强的推理模型。
- 应用不需要因为每次模型组合变化而重建整套 AI 集成。
这里的业务价值不是“随便切模型”。真正价值是降低适应模型、价格和工作负载变化的成本。
基于工作负载做路由
多模型应用通常包含混合 LLM 工作负载。短文本格式化、长上下文分析和复杂智能体规划,不应该默认使用同一种模型配置。
统一 API 层给团队提供了一个自然位置,用来为支持的文本工作负载引入路由逻辑:
- 将简单任务路由到更低延迟或更低成本的模型
- 将重推理任务路由到能力更强的模型
- 对严格基准测试或有合规要求的工作流保留固定模型
- 在使用路由时返回实际命中的模型,方便团队记录和评估
用量可见性和账单口径一致
当应用开始使用多个模型,用量可见性就不再只是工程细节,而会变成产品和财务问题。
团队需要回答:
- 哪个功能正在使用哪个模型?
- 哪个客户分组贡献了主要消耗?
- 昂贵模型是否被用在了简单任务上?
- 某次模型切换是否提高了延迟、令牌使用量或失败率?
- 用量能否按功能、团队、环境或 API 密钥归因?
分散的服务商后台会让这些问题更难回答,因为每个服务商的用量报告方式都不同。统一 API 层可以为请求量、令牌、任务量和成本提供更一致的视图。
这种可见性是成本控制的基础。如果用量数据是碎片化的,模型经济性就很难被管理。
跨模型成本控制
成本控制不等于保证每个请求都更便宜。统一 API 层不应该承诺一定节省成本。
更现实的价值是控制能力:
- 按任务类型比较模型
- 避免简单任务默认使用高价模型
- 在 API 密钥、团队或产品层设置预算和限制
- 基于用量和质量数据评估模型变更
- 让成本策略更靠近平台层,而不是散落在应用代码里
在生产环境里,最大的成本问题往往不是某一次昂贵请求,而是一个昂贵默认值悄悄服务了大量简单请求,因为团队没有一个干净的位置去调整它。
故障回退和可靠性规划
生产级 AI 系统需要有故障预案:
- 服务商故障
- 配额耗尽
- 限流
- 延迟恶化
- 模型特定错误
- 模型更新后的质量回退
如果每个服务商都是独立集成,故障回退逻辑往往会出现在各个产品服务里。一个团队这样重试,另一个团队那样设置超时,第三个团队可能没有备用路径。
统一 API 层提供了更合适的位置,用来定义故障回退行为和运维策略。它可以帮助团队把应用逻辑和服务商可用性决策分开。
但故障回退仍然需要谨慎。备用模型可能有不同的输出行为、上下文限制、工具支持或价格。目标不是盲目替换,而是有一个可控位置来规划和测试替换路径。
更干净的生产运维
随着 AI 用量增长,模型层也需要像其他基础设施一样被运维:
- 日志记录
- 用量归因
- 延迟追踪
- 错误分类
- 访问控制
- 模型变更审核
- 事故响应
- 环境隔离
- 开发者文档
如果每个功能团队都自己维护服务商集成,这些实践会变得不一致。统一 API 层让团队更容易定义共享标准:模型调用应该如何发起、如何观察、如何变更。
所以,“一个 API”这个说法本身容易低估问题。真正的架构价值不只是一个端点,而是一个可以运营模型交付的位置。
什么时候简单统一 API 就够了
如果你的主要需求是集成稳定性,一个简单的统一 API 层可能已经足够。
适合这种情况的场景包括:
- 使用的模型数量不多
- 想要一个 API 密钥和一种请求模式
- 模型选择大多是显式的
- 流量规模仍然可控
- 故障回退要求有限
- 团队主要想降低集成维护成本
例如,一个创业团队可能用一个模型处理用户聊天,一个模型做内部摘要,再用一个图像模型做内容生成。如果产品还不需要动态路由或复杂治理,第一步价值就是建立一个稳定的共享接入层。
这个阶段仍然有价值。它能避免团队在真正理解工作负载之前,就长出三套互相独立的模型集成。
什么时候需要更高级的网关或路由层
当统一 API 层不只是提供接入能力,而需要承接更多生产责任时,就需要更高级的网关或路由层。
以下情况通常说明你需要进一步的路由、网关控制或托管模型交付层:
- 请求量已经大到模型选择会影响毛利
- 工作负载复杂度差异很大
- 可靠性要求已经明确
- 多个团队或服务依赖模型调用
- 用量必须按产品、客户或团队归因
- 故障回退行为需要测试和文档化
- 模型变更需要审核,而不是临时改代码
| 场景 | 你可能需要什么 | 原因 |
|---|---|---|
| 在原型里测试一个模型 | 直接 API 或简单统一 API | 速度比平台控制更重要 |
| 一个产品里使用 2-3 个模型 | 简单统一 API 层 | 一个集成入口可以减少服务商特定胶水代码 |
| 运行高流量生产负载 | 统一 API + 成本和用量控制 | 花费、延迟和用量归因开始变重要 |
| 构建任务变化大的智能体 | 统一 API + 支持的文本工作负载路由 | 不同智能体步骤可能需要不同模型配置 |
| 跨服务商管理可靠性 | 带故障回退规划的网关或路由层 | 故障处理不应该在每个服务里重复实现 |
这如何映射到 EvoLink
EvoLink 围绕这种模型交付模式构建:为支持的模型提供一个 API 入口,并在模型接入、成本可见性、文本工作负载路由和运维控制周围叠加平台能力。
团队不必把每个模型集成都当成一个单独项目,而可以把 EvoLink 作为跨支持模型家族的共享模型交付层。
这个定位很重要,因为 EvoLink 不是一个简单模型列表。长期看,它更接近 AI 模型交付基础设施:
- 统一接入: 用一条集成路径访问支持的模型,避免为每个服务商或模型家族重新建设接入层。
- 成本可控: 比较模型选择、查看价格和用量,让成本策略不要变成应用代码里的事后补丁。
- 调用可控: 将模型选择、支持的 LLM 请求路由决策、API 密钥和用量边界放到更靠近平台的位置。
- 生产可用: 把模型调用当作生产流量来管理,需要可见性、故障回退规划和稳定集成实践。
这里的边界也很重要:统一 API 层可以让模型交付更容易运维,但不能假装每个模型行为完全一致。团队仍然需要评估、日志、成本审核和工作流级质量验证。
决策清单
在决定使用统一 API 层、网关,还是直接调用模型服务商之前,可以先问这些问题:
- 你现在是否已经使用多个模型家族?
- 你是否计划加入图像、视频、音频、代码或长上下文模型?
- 你能否在不改多处应用代码的情况下切换模型?
- 你能否按功能、团队、客户或 API 密钥查看用量?
- 你能否在同一工作流里比较不同模型的成本?
- 你是否知道每个生产请求实际由哪个模型处理?
- 面对限流、服务商故障或延迟恶化,你是否有故障回退方案?
- 重试和超时行为在不同服务里是否一致?
- 开发者是否有一套清晰的模型接入文档?
- 模型选择是否被当作运维决策审核,而不只是代码改动?
如果大多数答案是否定的,问题就不只是接入便利性。你的模型层已经开始变成生产基础设施的一部分。
常见问题
什么是 AI 模型的统一 API?
AI 模型的统一 API 是一个集成层,让应用可以通过一致的 API 入口调用支持的模型。它可以减少重复的服务商配置,并为模型接入、用量可见性、账单口径、成本控制、路由和运维策略提供共享位置。
统一 API 和 LLM 网关是一回事吗?
不完全是。简单统一 API 可能只提供一个多模型访问入口。LLM 网关通常会增加更多基础设施能力,例如路由、故障回退、可观测性、策略控制、限流或治理。很多团队会先从统一接入开始,随着生产要求提高再演进到网关。
如果我只用一个模型,还需要统一 API 吗?
通常不需要。如果产品只使用一个模型、流量不高,也不需要故障回退或多服务商可见性,直接 API 可能更简单。统一 API 更适合那些预计会持续处理模型选择、成本控制或可靠性规划的团队。
统一 API 如何帮助模型路由?
模型路由需要一个稳定位置来做模型选择。统一 API 层让应用保持一条请求路径,而路由逻辑可以基于任务类型、延迟目标、成本画像或其他信号选择模型。生产环境里,路由还应该暴露实际命中的模型,方便团队记录、评估和排查问题。
统一 API 会让所有模型行为都一样吗?
不会。统一 API 可以规范接入、鉴权、请求结构、用量报告或路由策略的一部分,但不会让模型质量、延迟、上下文限制、工具调用行为、模态支持或价格完全一致。团队仍然需要用自己的工作流测试每个模型。


