
2026 年 LLM 总拥有成本 (TCO):为什么 Token 成本只是真实价格的一部分

2026 年 LLM 总拥有成本 (TCO):为什么 Token 成本只是真实价格的一部分
大多数团队使用单一指标来估算 LLM 功能的成本:每百万 Token 的价格。
该指标很重要 —— 但仅限于纸面上。
在实际生产系统中,LLM 总拥有成本 (TCO) 通常不仅仅由 Token 支出驱动,而是由工程开销驱动:集成工作、可靠性修复、Prompt 维护以及随着时间的推移悄悄侵蚀 AI 投资回报率 (ROI) 的评估差距。
本指南解释了 LLM 集成的隐性成本,并提供了一个实用框架来识别资金和工程时间的实际去向:
- 胶水代码 (Glue Code) — 持续的集成税
- 评估债务 (Eval Debt) — 不确定性的代价
- Prompt 漂移 (Prompt Drift) — 永无止境的迁移
10 分钟 LLM TCO 自查
在深入探讨之前,请回答这五个问题:
- 您的系统目前支持多少个模型或提供商(包括计划中的)?
- 您是否维护特定于提供商的适配器或条件分支?
- 您是否在每次模型变更时运行自动化评估?
- 您能否在不重写 Prompt 或业务逻辑的情况下将流量重新路由到另一个模型?
- 您是否拥有成本、延迟和故障率的单一视图?
隐性成本 #1 — 胶水代码:集成税
胶水代码是不产生面向用户的价值,但为了标准化提供商之间的差异而必须进行的工程工作。
它通常在三个可预测的领域增长。
1) 用量与上下文管理
一旦涉及多个模型,用量核算就不再统一。
胶水代码的常见来源包括:
- 上下文窗口计算和截断
- "安全最大输出"防护
- 不一致或缺失的用量字段
上下文溢出通常会导致重试、部分输出和意想不到的支出 —— 而不仅仅是错误。
2) 可靠性与故障标准化
不同的 API 以根本不同的方式失败:
- 结构化 API 错误 vs. 传输层故障
- 节流 (Throttling) vs. 无声超时
- 部分流式传输 vs. 突然断开连接
这使得"只需添加重试"变成了一个不断增长的决策树。
# 说明性示例:与提供商无关的故障标准化
def should_retry(err) -> bool:
if getattr(err, "status", None) in (408, 429, 500, 502, 503, 504):
return True
if "timeout" in str(err).lower() or "connection" in str(err).lower():
return True
return False这段代码使系统保持活力 —— 但对产品差异化没有任何贡献。
3) 工具调用与结构化输出
当您依赖工具或严格的 JSON 输出时,您就是在集成一种协议,而不仅仅是一个聊天 API。
即使是接受类似请求形状的 API,在以下方面也可能有所不同:
- 工具调用出现在响应中的位置
- 参数的编码方式
- 结构化输出的执行严格程度
这是 LLM API 碎片化的直接后果。
胶水代码嗅探测试
如果出现以下情况,您正在支付集成税:
- Prompt 因提供商而异
- 流式解析器因模型而异
- 适配器随着时间的推移成倍增加
- 可观测性以提供商为中心,而不是以功能为中心
隐性成本 #2 — 评估债务:不确定性的代价
当团队部署模型而没有将自动化评估与实际工作流绑定时,评估债务就会累积。
结果是可预测的:
- 迁移感觉风险很大
- 更便宜或更快的模型未被使用
- 团队坚持使用昂贵的默认设置
- AI 投资回报率随着时间的推移而下降
最小可行评估循环 (MVEL)
您不需要一个完整的 MLOps 平台来减少评估债务。
您需要一个能够回答一个问题的循环:
如果我们更换模型,用户会注意到吗?
许多团队可以在 1-2 天内实施的实用基准:
1) 小型、版本化的数据集 (50–300 个案例)
使用真实的生产示例:
- 常见的用户流程
- 边缘情况
- 历史故障
eval/
├── datasets/
│ ├── v1_core.jsonl
│ ├── v1_edges.jsonl
│ └── v1_failures.jsonl
2) 可重复的批处理运行器
一个脚本,用于:
- 跨模型运行相同的数据集
- 记录输出、延迟和成本
- 在本地或 CI 中运行
3) 轻量级评分 (侧重于回归)
至少跟踪:
- 格式有效性
- 必填字段是否存在
- 延迟和成本阈值
4) 简单的评估配置
dataset: datasets/v1_core.jsonl
model_targets:
- primary
- candidate
metrics:
- format_validity
- required_fields
thresholds:
format_validity: 0.98
latency_p95_ms: 1200
report:
output: reports/diff.html仅此结构就能显著降低迁移风险。
隐性成本 #3 — Prompt 漂移:永无止境的迁移
LLM 工程中最常见的误解是:
"我们稍后只需更换模型 ID。"
实际上,Prompt 会发生漂移,因为模型在以下方面存在差异:
- 格式化纪律
- 工具使用行为
- 拒绝阈值
- 指令遵循风格
一个常见的失败模式 (与提供商无关)
- Prompt 要求严格的 JSON 输出
- 模型 A 始终遵守
- 模型 B 添加简短的解释或拒绝句
- 下游解析失败
- 工程师修补 Prompt、解析器或两者
LLM TCO 冰山:成本实际上来自哪里
- 显性成本: Token 定价
- 隐性成本:
- 胶水代码维护
- Prompt 漂移修复
- 评估基础设施
- 调试、重试和回滚
关于多模态系统(图像和视频)的说明
虽然本文重点关注 LLM 集成,但同样的 TCO 框架更适用于图像和视频生成等多模态系统。
一旦超越文本,工程开销就会扩大到包括异步作业编排、Webhook 或轮询、临时资产存储、带宽成本、超时处理以及非确定性输出的质量评估。在实践中,这些因素通常超过单位定价 —— 无论单位是 Token、图像还是视频秒数。
这就是为什么构建生产级图像或视频工作流的团队经常会遇到比纯文本系统更高的胶水代码和评估成本,即使模型定价在纸面上看起来更便宜。
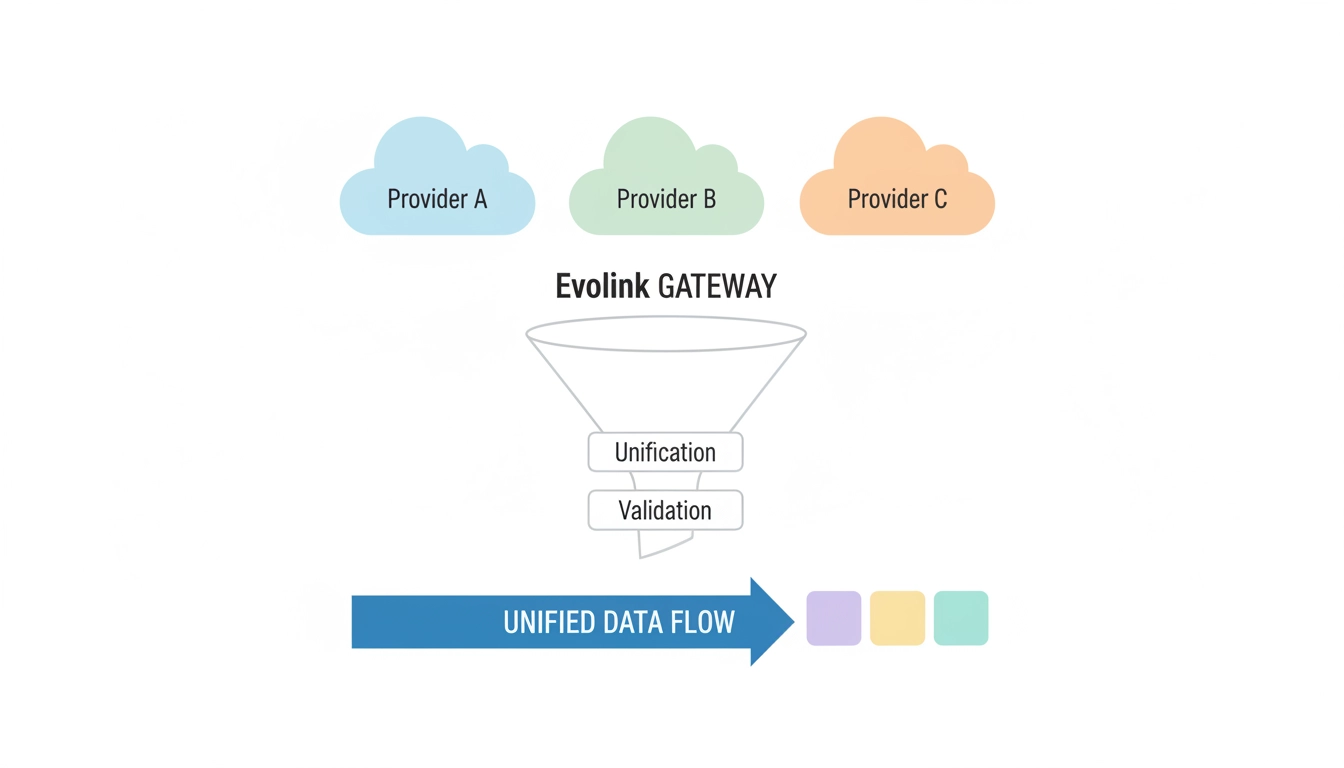
直接集成 vs. 标准化网关
| 成本领域 | 直接集成 | 标准化网关 |
|---|---|---|
| Token 成本 | 低–可变 | 低–可变 |
| 集成工作量 | 高 | 较低 |
| 维护 | 持续 | 集中化 |
| 迁移速度 | 慢 | 更快 |
| 可观测性 | 碎片化 | 统一 |
| 工程开销 | 重复 | 整合 |
在这个阶段,真正的决定不是使用哪个模型 —— 而是您希望这种复杂性存在于何处。
领先的团队将碎片化、路由和可观测性从应用程序代码中移出,通过专用的网关层进行处理。
这种架构转变正是 Evolink.ai 存在的原因。
常见问题解答 (SEO 优化)
您如何计算 LLM 集成的隐性成本?
通过核算用于集成、评估、Prompt 维护、可靠性修复和迁移的工程时间 —— 而不仅仅是 Token 支出。
多 LLM 策略的工程开销是多少?
它包括胶水代码、Prompt 漂移处理、评估基础设施和跨提供商的可观测性。
什么是 LLM 系统中的评估债务?
评估债务是由于部署没有自动化评估的模型而累积的风险,这使得未来的变更更慢、更昂贵。
LLM 网关如何提高 AI 投资回报率?
通过集中规范化、路由和可观测性,允许团队在不重写功能级集成代码的情况下优化或切换模型。


