
“为什么 LLM API 没有标准化”

LLM API 碎片化问题(以及为什么“OpenAI 兼容”还不够)
如果您正在搜索为什么 LLM API 没有标准化,您可能已经体验到了这种痛苦。
尽管所谓的“OpenAI 兼容”API 迅速兴起,但在现实世界的 LLM 集成中仍然会以微妙但昂贵的方式中断——特别是当您超越简单的文本生成时。
本指南解释了:
- 什么是 LLM API 碎片化问题
- 为什么在生产中“OpenAI 兼容”API 实际上还不够
- 2026 年的团队如何设计在不断变化的模型中生存的系统
太长不看 (TL;DR)
- LLM API 没有标准化,因为提供商优化的是不同的能力,而不是兼容性。
- “OpenAI 兼容”通常意味着请求形状兼容,而不是行为兼容。
- 碎片化最明显地表现在工具调用、推理 token 核算、流式传输和错误处理中。
- 团队不再等待标准,而是在专用网关层后面规范化 API 行为。
什么是 LLM API 碎片化问题?
当不同的语言模型提供商公开看起来相似但在实际工作负载下行为不同的 API 时,就会发生 LLM API 碎片化。
即使 API 共享:
- 相似的端点
- 相似的 JSON 请求模式
- 相似的参数名称
它们通常在以下方面存在分歧:
- 工具调用语义
- 推理 / 思考 token 核算
- 流式传输行为
- 错误代码和重试信号
- 结构化输出保证
随着时间的推移,应用程序逻辑充满了特定于提供商的例外。
为什么 LLM API 没有标准化
1. 提供商针对不同的原语进行优化
现代 LLM 不再是简单的文本输入 / 文本输出系统。
不同的提供商优先考虑不同的原语:
- 推理深度 vs 延迟
- 长上下文检索 vs 吞吐量
- 原生多模态(图像、视频、音频)
- 安全和策略执行
单一的刚性标准将要么:
- 隐藏高级功能
- 或者将创新减慢到最小公分母
在竞争激烈的市场中,这两种结果都是不现实的。
2. “OpenAI 兼容”仅涵盖快乐路径
大多数“OpenAI 兼容”API 旨在通过基本的冒烟测试:
client.chat.completions.create(
model="model-name",
messages=[{"role": "user", "content": "Hello"}]
)这对于演示很有效——但生产系统依赖的远不止这些。
为什么 2026 年“OpenAI 兼容”还不够
真正的破坏出现在您依赖行为而不仅仅是语法时。
🔽 表格:为什么“OpenAI 兼容”API 在生产中会中断
| 维度 | “OpenAI 兼容”承诺什么 | 生产中经常发生什么 |
|---|---|---|
| 请求形状 | 相似的 JSON 模式(消息、模型、工具) | 边缘参数被静默忽略或重新解释 |
| 工具调用 | 兼容的函数定义 | 工具调用以不同的位置或形状返回 |
| 工具参数 | 可以可靠解析的 JSON 字符串 | 扁平化、字符串化或部分丢失的参数 |
| 推理 Token | 透明的使用情况报告 | 不一致的 token 核算和计费语义 |
| 结构化输出 | 有效的 JSON 响应 | 打破模式保证的“尽力而为”JSON |
| 流式传输 | 稳定的增量块 | 不一致的块顺序或缺少完成信号 |
| 错误处理 | 明确的速率限制和重试信号 | 500 错误、模棱两可的故障或静默超时 |
| 迁移 | 轻松切换提供商 | 提示重写和胶水代码激增 |
这些差异很少出现在演示中。 它们仅在真实负载、复杂工具使用或成本敏感的生产系统下浮出水面。
示例 1:工具调用看起来相似——但在语义上中断
OpenAI 风格的期望(简化):
{
"tool_calls": [{
"id": "call_1",
"type": "function",
"function": {
"name": "search",
"arguments": "{\"query\":\"LLM API fragmentation\",\"filters\":{\"year\":2026}}"
}
}]
}常见的“兼容”现实:
{
"tool_call": {
"name": "search",
"arguments": "{\"query\":\"LLM API fragmentation\"}"
}
}两个响应都可能是“成功的”。 一旦您的应用程序依赖于嵌套参数、工具调用数组或稳定的响应路径,它们在行为上就不兼容了。
示例 2:推理 Token——2026 年的痛点
专注于推理的模型引入了额外的推理 / 思考 token。
即使使用“OpenAI 兼容”API,碎片化也会出现在:
- token 核算(如何计算和定价推理 token)
- 使用情况报告(推理 token 出现在哪里)
- 控制旋钮(推理工作的不同名称和语义)
- 可观察性(难以比较跨提供商的成本)
结果:
- 成本仪表板漂移
- 评估基线中断
- 跨提供商优化变得不可靠
推理行为可能具有可比性——但推理核算很少如此。
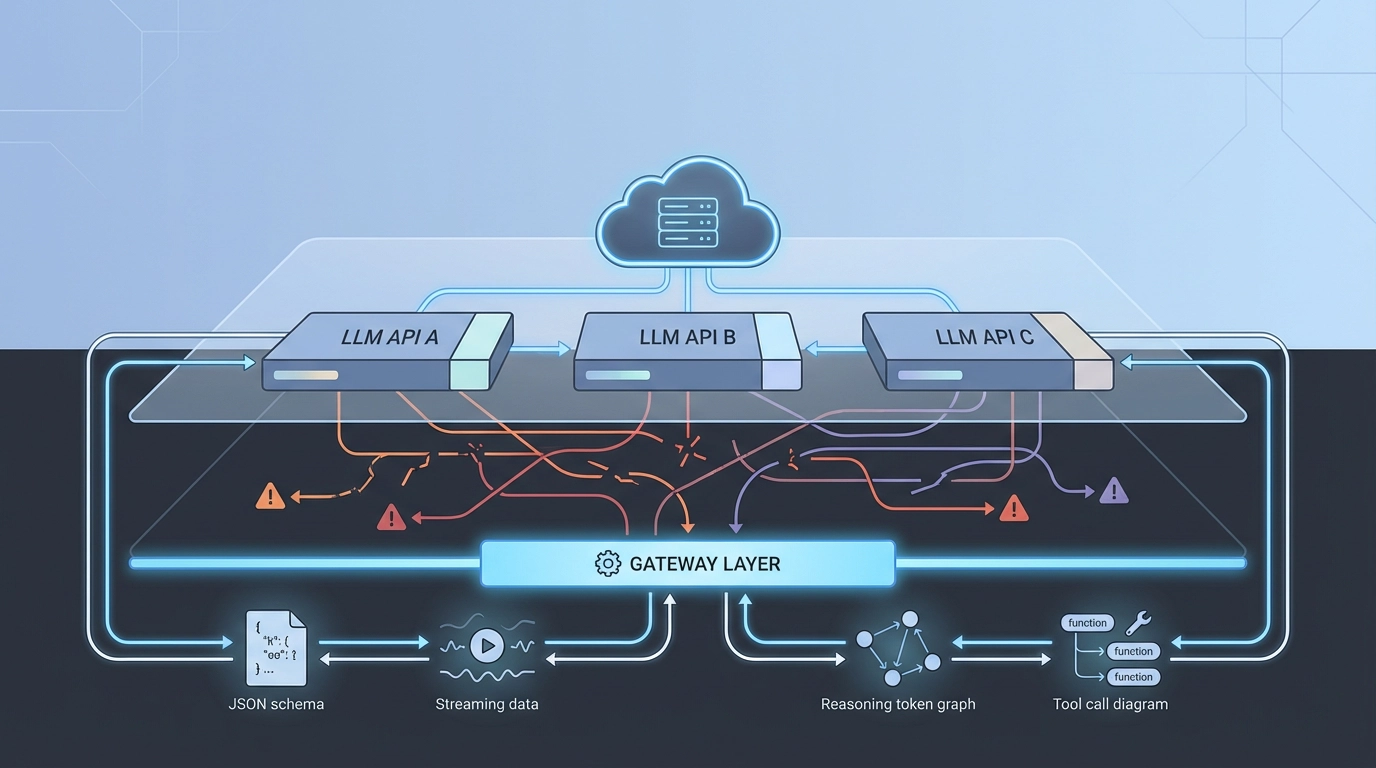
LLM API 碎片化的隐性成本
1. 胶水代码悄悄积累
def get_reasoning_usage(resp: dict) -> int | None:
details = resp.get("usage", {}).get("output_tokens_details", {})
if "reasoning_tokens" in details:
return details["reasoning_tokens"]
if "reasoning_tokens" in resp.get("usage", {}):
return resp["usage"]["reasoning_tokens"]
return None这种模式在工具、重试、流式传输和使用情况跟踪中重复出现。
胶水代码不交付功能。 它只防止中断。
2. 在 LLM 提供商之间迁移比预期更难
团队期望:
“我们稍后只需切换模型。”
实际发生的情况:
-
提示漂移
-
不兼容的工具模式
-
不同的速率限制语义
-
不匹配的使用指标
3. 多模态 API 使碎片化倍增
超越文本:
-
视频 API 在持续时间单位和安全规则上有所不同
-
图像 API 在蒙版格式和引用方面各不相同
今天没有共享的多模态契约。
为什么团队尝试(并努力)构建自己的包装器
最初,自定义抽象感觉很合理。
随着时间的推移,它变成:
-
第二个产品
-
维护负担
-
实验的瓶颈 许多团队独立地重新发现了相同的结论。
实用的标准化清单
在信任任何“兼容”API 或内部包装器之前,请询问:
- 工具调用是行为兼容还是仅模式兼容?
-
推理 token 是否一致地暴露?
-
使用情况可以跨提供商比较吗?
-
错误代码是否规范化?
-
流式传输在负载下是否稳定?
-
是否可以在不重写提示的情况下切换提供商?
-
流量可以动态重新路由吗?
从标准化到规范化
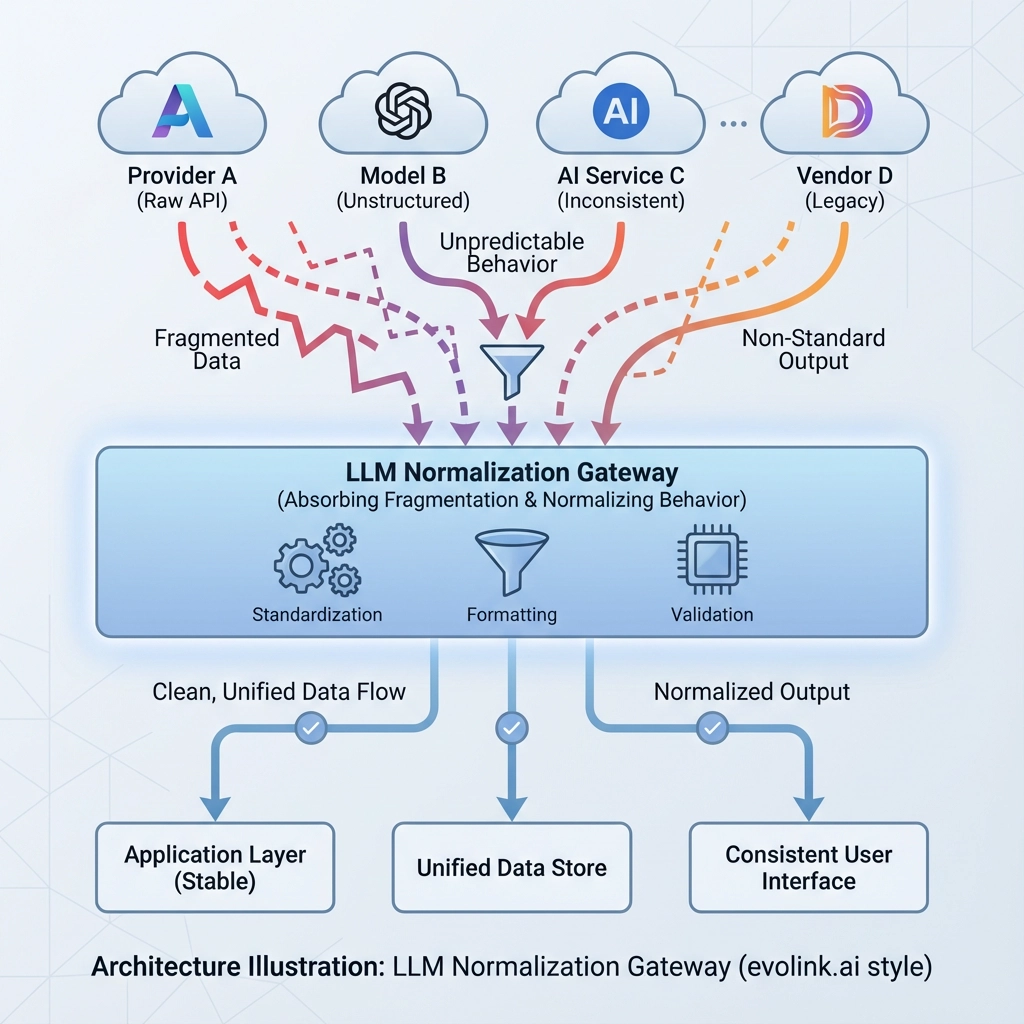

LLM API 没有标准化,因为生态系统发展太快而无法融合。 成熟的团队不再等待,而是演进他们的架构:
-
业务逻辑保持与模型无关
-
API 怪癖被规范化的网关层吸收
最后的收获
LLM API 没有标准化——而且很快也不会标准化。
“OpenAI 兼容”API 降低了入门门槛,但它们并没有消除生产风险。
为碎片化设计的系统寿命更长。
常见问题 (适用于 AI 概览和精选摘要)
为什么 LLM API 没有标准化?
LLM API 没有标准化,因为提供商针对不同的能力进行优化——例如推理深度、延迟、多模态和安全性。刚性标准会减缓创新或隐藏高级功能。
为什么 OpenAI 兼容的 API 还不够?
“OpenAI 兼容”通常只保证请求形状的相似性。在生产中,工具调用、推理 token 核算、流式传输和错误处理方面的差异会破坏兼容性。
什么是 LLM API 碎片化问题?
LLM API 碎片化问题是指外观相似的 API 在实际工作负载下行为不同,迫使开发者编写胶水代码并使迁移变得复杂。
团队如何处理 LLM API 碎片化?
大多数成熟的团队在吸收提供商差异的网关层后面规范化 API 行为,保持业务逻辑稳定。


