
成本优化
如何降低 OpenRouter 成本:路由与网关选择

Jessie
COO
2026年1月22日
更新于 2026年7月18日
19 分钟阅读
想要更全面的 OpenRouter 替代方案对比? 本文专注于成本优化。如需涵盖隐私、可观测性和部署控制的完整路由功能对比,请参阅 2026年最佳 OpenRouter 替代方案。如需排查 OpenRouter 错误,请参阅 修复 OpenRouter 429 “Provider Returned Error”。
如果你正在寻找降低 OpenRouter 成本的方法,你的真实意图通常不是“我想要一个新的路由”。
而是这个:
OpenRouter 很方便,但随着用量的增长,它开始让人觉得昂贵——你想要一个能在不把迁移变成重写代码的情况下,真正改善单元经济效益的切换方案。
本文对比了团队通常评估的五个选项:
- LiteLLM (自托管 LLM 网关)
- Replicate (基于计算时间的模型执行)
- fal.ai (生成式媒体平台)
- WaveSpeedAI (视觉生成工作流)
- EvoLink.ai (支持智能路由的聊天/图像/视频统一网关)
我们还将使用 OpenRouter 作为基准背景。
太长不看:你应该首先评估哪种替代方案?
- 如果你想要自托管治理 + 最大控制权 → LiteLLM
- 如果你的负载是计算/任务型,且想要公开的硬件定价 → Replicate
- 如果你的主要支出是图像/视频生成 → fal.ai 或 WaveSpeedAI
- 如果你的成本问题是由渠道差异驱动的,且想要将聊天 + 图像 + 视频统一在一个 API 后 → EvoLink.ai
如果你想在稍后阅读本指南时快速尝试 EvoLink:
→ 获取 EvoLink API 密钥
查看 EvoLink Smart Router
“觉得 OpenRouter 贵”在生产环境中的真实含义
大多数团队在早期原型设计阶段不会感到成本压力。当出现以下情况时,成本会变得令人痛苦:
- 你有了真实用户(以及不可预测的用量)
- 开始频繁重试(429 错误/超时爆发)
- 你引入了多模态功能(文本 + 图像 + video)
- 你开始优化毛利和单元经济效益
到那时,你不再只关心“Token 价格”,而是开始关心每个结果的实际成本 (effective cost per outcome):
- 每个成功的客服解决成本
- 每个智能体 (Agent) 工作流完成成本
- 每个图像素材成本(包括重试和失败)
- 每个短视频成本(包括失败和队列浪费)
15 分钟切换前检查清单
| 步骤 | 行动 | 输出 |
|---|---|---|
| 1 | 选择一个 KPI:每个结果的实际成本 | 一个团队可以共同努力的单一数字 |
| 2 | 测量重试率、错误率、p95 延迟 | “浪费” + 用户体验影响的基准 |
| 3 | 标记你的工作负载:纯文本 vs 多模态 | 决定“LLM 路由”是否足够 |
| 4 | 决定容忍度:托管 vs 自托管 | 决定选择 LiteLLM 还是托管工具 |
| 5 | 计划滚动:影子测试 → 金丝雀发布 → 逐步放量 | 防止风险巨大的全量迁移 |
“实际成本堆栈”(钱在哪儿流失了)
| 层级 | 成本驱动因素 | 具体表现 | 衡量指标 |
|---|---|---|---|
| L1 | 使用成本 | tokens / 按输出计费 / 按秒计费 | 每个会话/任务/素材的金额 |
| L2 | 渠道差异 | 同等能力,不同渠道的实际定价不同 | 跨路由的价格分布 |
| L3 | 失败浪费 | 重试、超时、429 爆发 | 重试率、每千次调用的错误数 |
| L4 | 工程开销 | 许多 SDK、许多计费账户、代码漂移 | 每次集成花费的时间 |
| L5 | 模态膨胀 | 跨平台的文本 + 图像 + 视频 | 关键路径中的供应商数量 |
如果觉得 OpenRouter 贵,通常是 L2–L5 层级的问题。
表 1 — 平台契合度矩阵(对接“OpenRouter 贵”的诉求)
| 平台 | 什么时候是 OpenRouter 的强力替代方案 | 典型计费方式(高层级) | 迁移阻力 | 权衡因素 |
|---|---|---|---|---|
| LiteLLM | 你想要自托管控制(预算、路由、治理)且能运行基础设施 | 开源网关/代理 + 你的基础架构成本 | 中–高 | 你负责运维:高可用、升级、供应商漂移、监控系统 |
| Replicate | 你的负载是计算/任务型,且想要公开的硬件定价 | 计算时间 / 硬件秒数(因模型而异) | 中 | 运行时波动会降低可预测性;需测试真实输入 |
| fal.ai | 你是媒体密集型(图像/视频/音频),想要广泛的模型库 + 规模化方案 | 按用量计费的生成式媒体平台 | 中 | 实际成本取决于选择的模型 + 工作流设计 |
| WaveSpeedAI | 你正在构建视觉生成工作流(图像/视频),媒体优先 | 按用量计费的媒体平台 | 中 | 通常是对 LLM 路由的补充,而非直接替代 |
| EvoLink.ai | 你想利用跨渠道智能路由降低实际成本,并统一聊天 + 图像 + 视频 | 按用量计费的网关;路由驱动的成本优化 | 低–中 | 如需严格自托管/本地化或特定合规需求,请验证契合度 |
| OpenRouter (基准) | 在一个 API 后快速切换 LLM 模型 | Token 样式的 LLM 访问 | 无 | 当实际成本上升(浪费 + 开销 + 膨胀)时会觉得贵 |
工作负载类型:选择与你的产品匹配的替代方案
| 工作负载类型 | 你优化的目标 | 最匹配的选项 | 原因 |
|---|---|---|---|
| SaaS 聊天 / 客服助手 | 每个会话成本、p95 延迟、重试浪费 | LiteLLM, EvoLink | LiteLLM 用于自托管治理;EvoLink 用于路由经济性 + 统一堆栈 |
| 编程智能体 / 开发工具 | 突发处理、组织预算/密钥、模型敏捷性 | LiteLLM, EvoLink | LiteLLM 用于平台控制;EvoLink 用于低阻力 + 成本意识路由 |
| 营销图像 (高容量变体) | 每个素材成本、吞吐量、异步/Webhooks | fal.ai, WaveSpeedAI, EvoLink | fal/WaveSpeed 媒体优先;EvoLink 如果你想跨模态统一界面 |
| 短视频生成 | 每个视频成本、队列行为、失败浪费 | fal.ai, WaveSpeedAI, EvoLink | 媒体平台更专业;EvoLink 如果你想要统一的多模态 + 路由经济性 |
| 研究 / 实验 | 覆盖范围、快速原型设计、基础架构定价清晰 | Replicate, OpenRouter | Replicate 与计算型任务匹配良好;OpenRouter 方便 LLM 迭代 |
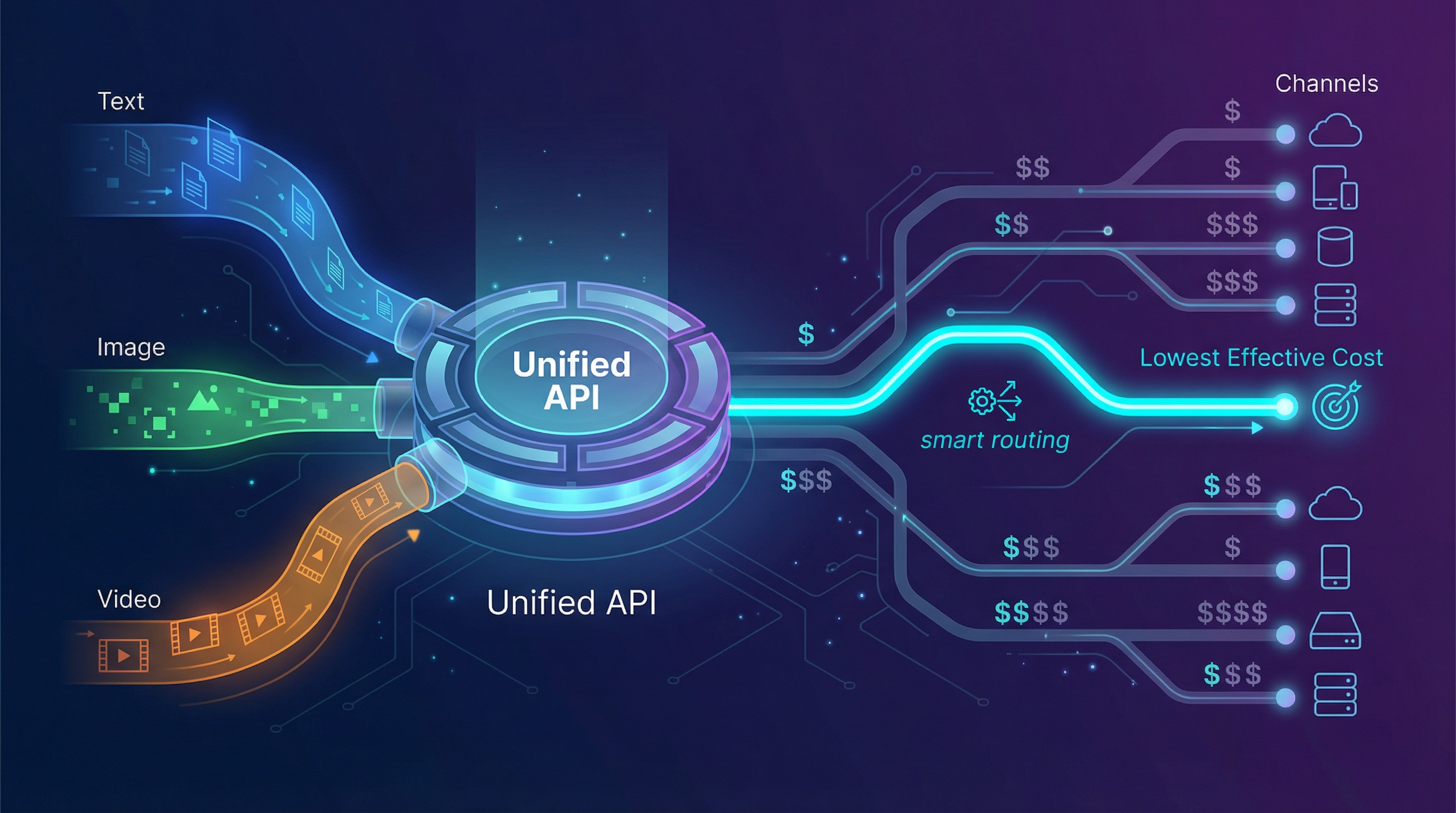
替代方案:评估什么(以及如何评估)
1) LiteLLM — 自托管网关控制 (OpenAI 格式)
团队通常在以下情况下考虑评估 LiteLLM:
- 跨供应商的 OpenAI 格式接口
- 集中化的预算、速率限制和治理
- 自托管 / 本地化部署选项
LiteLLM 如何胜出
- 你想在自己的环境中拥有策略层(预算、认证、路由规则)。
- 你愿意用工程时间和运营责任来交换供应商开销。
容易让团队意外的地方
- “路由”变成了你的责任:
- 高可用、扩缩容、事件响应
- 供应商漂移(API 变更)
- 日志/指标流水线
- 你必须主动管理重试/降级以避免浪费。
如何在不过度投入的情况下测试 LiteLLM
- 从测试环境开始
- 使用影子流量 (复制调用;不影响用户)
- 尽早添加支出限制
- 仅在输出一致性检查后才提升到金丝雀发布
2) Replicate — 具有公开硬件定价的计算时间模型执行
当你的负载更像“任务”而非对话轮次时,通常会评估 Replicate:
- 你将模型预测作为计算任务运行
- 你想要透明的硬件定价层级 (GPU 美元/秒)
Replicate 如何胜出
- 非常契合实验和计算型负载
- 硬件定价清晰有助于预测(当日运行时稳定时)
容易让团队意外的地方
- 运行时的可变性变成了成本的可变性。
- 生产级可靠性可能因模型和负载而异。
如何测试 Replicate
- 使用真实输入进行基准测试
- 记录运行时分布 (p50/p95/p99)
- 转换为每个结果的成本(资产/周期),而不仅仅是每秒成本
3) fal.ai — 生成式媒体平台 (广泛的目录 + 规模化故事)
fal.ai 通常被媒体密集型产品选择:
- 图像/视频/音频生成
- 广泛的模型库
- 性能和规模化定位
fal.ai 如何胜出
- 你想在一个平台下实现广泛的媒体覆盖。
- 你看重媒体 API 的速度/规模故事。
容易让团队意外的地方
- 实际成本高度依赖于所选模型和工作流设计。
- 异步/Webhook 的设计选择会强烈影响失败产生的浪费。
如何测试 fal.ai
- 选择 2–3 个与你产品匹配的端点/模型
- 测试:
- 单次运行延迟
- 批量吞吐量
- 追踪:失败浪费和每个素材的成本
4) WaveSpeedAI — 媒体优先的视觉工作流
WaveSpeedAI 通常在图像/视频生成工作流中被评估。
WaveSpeedAI 如何胜出
- 你想要一个针对视觉生成功能的媒体优先平台。
- 你的产品更偏向“生成素材”而非“聊天助手”。
容易让团队意外的地方
- 它可能是对 LLM 路由的补充,而非替代。
- “更便宜”取决于工作流结构(异步任务、重试等)。
如何测试 WaveSpeedAI
- 衡量每个素材的成本
- 衡量结果生成时间分布
- 验证批量负载下的稳定性
5) EvoLink.ai — 通过路由经济性 + 统一多模态 API 降低实际成本
如果你的抱怨是“OpenRouter 贵”,关键问题是:因为什么贵?
如果答案是:
- 你的实际成本因渠道差异而通胀
- 重试和失败造成了浪费
- 你的应用正变得多模态(文本 + 图像 + 视频)
- 你不想管理五个不同的供应商集成
……那么 EvoLink 正是为此而设计的。
EvoLink 的公开定位:
- 聊天、图像和视频的统一 API
- 170+ 模型
- 旨在降低成本的智能路由(宣称“节省高达 70%”)
- 可靠性声明包括 99.9% 正常运行时间和自动故障转移
如何评估 EvoLink (让财务和工程团队都信任)
- 选择一个有代表性的工作流(而非简单的测试提示词)。
- 运行 1–5% 的金丝雀发布,持续 24–48 小时。
- 对比每个结果的实际成本、重试率、p95 延迟。
- 保留回滚机制。
从这里开始
- 主要行动点:获取 API 密钥
- 模型目录:EvoLink 模型
- 实现:EvoLink API 文档
- 工程实战:GPT Image 1.5 生产指南
如何决定(不要想太多):简单的决策流程
-
你是否需要自托管 / 本地化 / 深度内控? → 从 LiteLLM 开始。
-
你的工作负载是否主要是媒体生成 (图像/视频)? → 从 fal.ai 或 WaveSpeedAI 开始。
-
你的负载是否为计算/任务型,且你关心运行时的经济效益? → 从 Replicate 开始。
-
你是否想要跨聊天/图像/视频的统一界面,且你的成本问题是实际成本(渠道差异 + 浪费)? → 测试 EvoLink:免费开始
表 2 — 实际成本缓解清单(无论使用哪个平台均应实施)
| 问题 | 症状 | 解决方法 |
|---|---|---|
| 重试风暴 | 供应商波动期间支出激增 | 重试上限 + 队列 + 退避机制 |
| 用户操作导致的双重计费 | 重复点击 = 重复调用 | 幂等密钥 + UI 节流 |
| 昂贵路径使用过于频繁 | 所有流量都使用高级选项 | 路由策略 + 预算控制 |
| 日志变成成本中心 | 永久存储所有内容 | 采样 + 保留期限限制 |
| 难以分配支出 | “AI 成本”是一个单一的池子 | 按功能/团队/用户标记请求 |
迁移手册:在不把“更便宜”变成“更危险”的情况下切换
表 3 — 低风险滚动计划 (可复制粘贴)
| 阶段 | 你的行动 | 完成标志 |
|---|---|---|
| 基准 | 衡量每个结果的实际成本、重试率、p95 延迟 | 你能解释成本驱动因素 |
| 影子测试 | 将请求复制到新平台(不影响用户) | 输出可比;无严重失败 |
| 金丝雀发布 | 路由 1–5% 的真实流量 | KPI 改善或持平;回滚机制有效 |
| 逐步放量 | 10% → 25% → 50% → 100% | 在峰值负载下保持稳定 |
| 优化 | 微调路由 + 预算 | 成本曲线随规模增长而改善 |
防止“工具便宜,结果昂贵”的护栏
- 用户操作的幂等性
- 重试上限 + 队列
- 每个密钥/团队/项目的预算上限
- 基于失败类型的降级规则 (超时/429/5xx)
- 采样日志(避免永久记录所有内容)
加赠:你可以分发给团队的实际成本工作表
| 指标 | 基准 (OpenRouter) | 候选者 A | 候选者 B |
|---|---|---|---|
| 每个结果的实际成本 | |||
| 重试率 (%) | |||
| 错误率 (每 1k 次) | |||
| p95 延迟 (ms) | |||
| 关键路径中的供应商数量 (#) | |||
| 迁移工作量 (人天) |
建议总结(针对“OpenRouter 贵”的诉求)
- 如果你需要自托管治理 + 最大控制权 → LiteLLM
- 如果你的工作负载是计算型的任务,且想要公开的硬件定价 → Replicate
- 如果你主要是图像/视频生成 → fal.ai 或 WaveSpeedAI
- 如果你想通过路由经济性降低实际成本,并将聊天/图像/视频统一在一个界面后 → EvoLink.ai 尝试一下:获取 EvoLink API 密钥
后续步骤(实操、转化导向)
- 选择你的第一个候选方案(基于工作负载类型)
- 运行 1–5% 的金丝雀发布,持续 24–48 小时
- 对比:每个结果的实际成本 + 重试率 + p95 延迟
- 仅在回滚能力得到验证后才扩大流量
- 如果你在测试 EvoLink:
备注 (避免事实性错误)
- 定价、目录和功能集可能会频繁更改。在做出预算决策前,请务必核实每个供应商的官方页面。
- 本文引用 OpenRouter 仅为对应搜索意图;本文不隶属于 OpenRouter。


