
LLM API 래퍼가 '인프라'가 되는 시점

LLM API 래퍼가 '인프라'가 되는 시점
대부분의 엔지니어링 팀은 처음부터 'LLM API 래퍼'를 만들겠다고 시작하지 않습니다.
보통 킥오프 문서도 없고, 명시적인 로드맵도 없으며, 누군가 "모든 모델 제공업체를 추상화하자"라고 말하는 순간도 없습니다. 대신, 프로덕션 시스템을 안정적으로 유지하려고 노력하는 과정에서 래퍼는 한 줄 한 줄 조용히 생겨납니다.
이 글에서는 왜 프로덕션 시스템에서 래퍼가 자주 나타나는지, 어떻게 래퍼가 인프라의 경계를 넘었는지 인식할 수 있는지, 그리고 팀이 다음에 직면하게 되는 전형적인 결정들은 무엇인지 설명합니다.
LLM API 래퍼의 실제 모습 (현장에서)
프로덕션 시스템에서 래퍼가 단일 컴포넌트인 경우는 드뭅니다. 이는 애플리케이션과 하나 이상의 LLM 제공업체 사이에 위치하며 지속적으로 성장하는 로직 계층입니다.
일반적인 역할은 다음과 같습니다:
- 요청 및 응답 스키마 정규화
- 재시도(Retry), 타임아웃, 제공업체별 오류 처리
- 모델 선택 또는 폴백(Fallback) 로직 관리
- 프롬프트, 시스템 메시지 또는 안전 규칙 주입
- 비용 배분, 로깅 또는 감사를 위한 사용량 추적
대부분의 래퍼는 편의를 위한 코드로 시작하지만, 많은 경우 결국 비즈니스에 필수적인(mission-critical) 경로가 됩니다.
왜 래퍼가 생겨나는가 (아무도 계획하지 않았더라도)
팀이 래퍼를 만드는 이유는 추상화를 원해서가 아닙니다. 프로덕션 환경의 압박 속에서 직접적인 통합이 더 이상 신뢰할 수 없게 되기 때문에 만듭니다.
팀을 이 방향으로 밀어붙이는 가장 일반적인 요인들은 다음과 같습니다.
1. 인터페이스 불일치보다 동작의 불일치가 더 해결하기 어렵다
API 스키마를 정규화하는 것은 비교적 쉽습니다. 하지만 런타임 동작(Runtime behavior)은 그렇지 않습니다.
팀은 종종 다음과 같은 차이점에 직면합니다:
- 스트리밍 응답이 멈추거나, 청크(chunk) 단위가 다르거나, 소리 없이 실패하는 경우
- 오류 메시지는 비슷해 보이지만 운영상 대응 방식이 다른 경우
- 부하가 걸렸을 때 예상치 못하게 동작하는 타임아웃
- 프롬프트 해석 또는 텍스트 생략(truncation)에서의 미묘한 차이
이러한 문제들이 프로덕션에서 발생할 때, 흔히 취하는 단기적인 대응은 로컬에 제공업체별 처리 로직을 추가하는 것입니다:
if provider == X:
retry differently # 다르게 재시도
if streaming stalls:
fallback to non-stream # 비스트리밍으로 전환시간이 지남에 따라 이러한 조건문들이 쌓입니다. 래퍼는 "API를 깔끔하게 만들기 위해서"가 아니라, "예측할 수 없는 동작"을 가두기 위해 형성됩니다.
2. 프롬프트 제어는 편의로 시작해서 정책으로 끝난다
초기에는 프롬프트가 단순히 애플리케이션 코드에서 전달되는 문자열에 불과합니다.
하지만 시간이 지나면 다음과 같은 성격을 띠게 됩니다:
- 버전 관리되는 자산
- 여러 서비스 간에 공유되는 리소스
- 평가 벤치마크(Evaluation Baselines)와 결합됨
- 제품 및 리스크 프로필에 따라 안전성, 규정 준수 또는 품질 표준 검토 대상
이 시점에서 프롬프트는 애플리케이션의 세부 사항이 아니라 설정(Configuration)처럼 동작하기 시작합니다.
래퍼는 다음과 같은 목적으로 등장합니다:
- 프롬프트 주입(Injection) 중앙화
- 시스템 수준의 지침 강제
- 서비스 간의 우발적인 차이(Drift) 감소
단순히 "프롬프트 헬퍼"처럼 보이는 것이 실제로는 정책 중앙화의 첫 번째 신호인 경우가 많습니다.
3. 중간 계층 없이는 비용 가시성이 파편화된다
직접 API를 사용하면 비용 신호가 여러 제공업체에 흩어집니다:
- 서로 다른 가격 단위(Pricing units)
- 서로 다른 결제 주기
- 서로 다른 속도 제한(Rate-limit) 체계
엔지니어링 팀은 재무 팀보다 먼저 이 고통을 느끼는 경우가 많습니다.
래퍼는 다음과 같은 목적으로 사용됩니다:
- 일관된 사용량 추적
- 기능 또는 팀별 비용 배분
- 청구서가 급증하기 전에 가드레일 적용
이것은 반드시 FinOps의 성숙도를 의미하는 것은 아닙니다. 많은 경우 방어적인 엔지니어링의 결과입니다.
4. 제품 코드 안에서 신뢰성 보장은 확장되지 않는다
LLM이 실험 단계에서 의존성(Dependency) 단계로 넘어가면 팀은 다음과 같은 기능을 필요로 하기 시작합니다:
- 폴백(Fallbacks)
- 제공업체 로테이션
- 단계적 기능 축소(Graceful degradation)
이러한 로직을 애플리케이션 코드에 직접 포함하면 밀결합(Tight coupling)이 생기고 경로가 취약해집니다.
래퍼는 신뢰성에 대한 의도(Intent)를 표현하는 자연스러운 장소가 됩니다:
- "이것이 실패하면 저것을 시도하라."
- "지연 시간이 임계값을 넘으면 성능을 낮춰라."
- "할당량(Quota)이 다 차면 모델을 전환하라."
이 단계에서 래퍼는 더 이상 선택 사항인 '접착제'가 아닙니다. 서비스 수준의 기대치를 강제하기 시작하는 계층입니다.
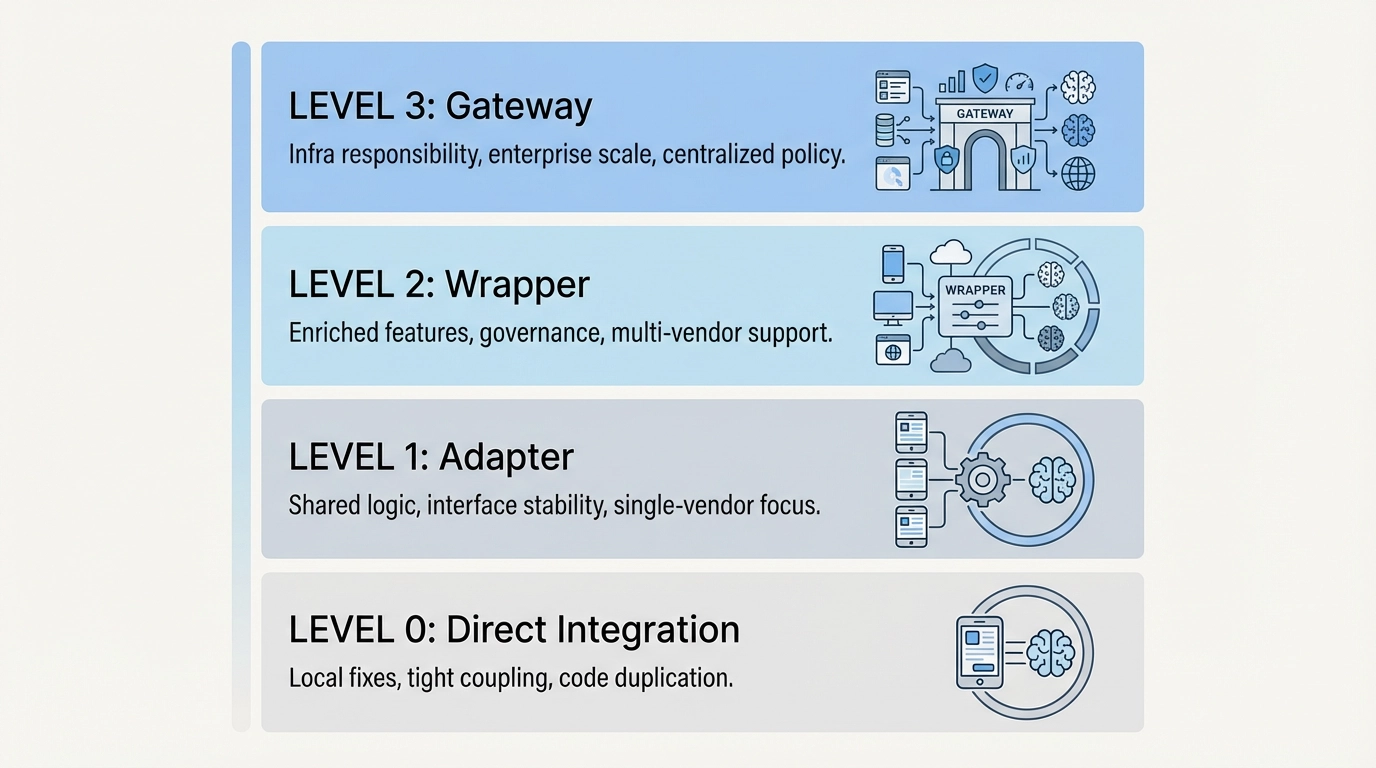
래퍼 성숙도 모델
많은 팀이 자신들의 래퍼가 이미 얼마나 발전했는지 과소평가하곤 합니다. 아래 표는 일반적인 발전 과정을 보여줍니다.
| 단계 | 모습 | 일반적인 고통 | 보통 다음에 오는 것 |
|---|---|---|---|
| 직접 통합 | 앱이 제공업체를 직접 호출 | 여기저기 흩어진 예외 처리 | 최소한의 어댑터 |
| 어댑터 | 통일된 스키마, 가벼운 헬퍼 | 동작의 불일치(Behavioral drift) | 중앙화된 재시도 로직 |
| 래퍼 | 프롬프트, 라우팅, 비용 추적 | 소유권 병목 현상 | 인프라 수준의 사고 |
| 게이트웨이 | 명시적 계약 및 관측성 | 트레이드오프의 표면화 | 조직 차원의 정렬 |
시스템이 2단계 이상으로 운영되고 있다면, 래퍼는 더 이상 일시적인 것이 아니라 인프라와 같은 책임을 지기 시작한 것입니다.
래퍼가 조용히 인프라가 되는 시점
팀들은 선을 넘었다는 사실을 너무 늦게 깨닫곤 합니다.
일반적인 신호는 다음과 같습니다:
- 여러 팀이 동일한 래퍼에 의존함
- 변경 시 조율 및 롤아웃 계획이 필요함
- 장애가 관련 없는 서비스에까지 영향을 미침
- 해당 계층에 문서화, 소유권 및 모니터링이 필요함
이 시점에서 래퍼는 '게이트웨이 계층'처럼 작동하기 시작합니다. 비록 아직 그렇게 이름 붙여지거나 운영되지 않더라도 말이죠.
차이는 단순히 기능의 유무가 아닙니다. 그것은 의도와 운영의 차이입니다.
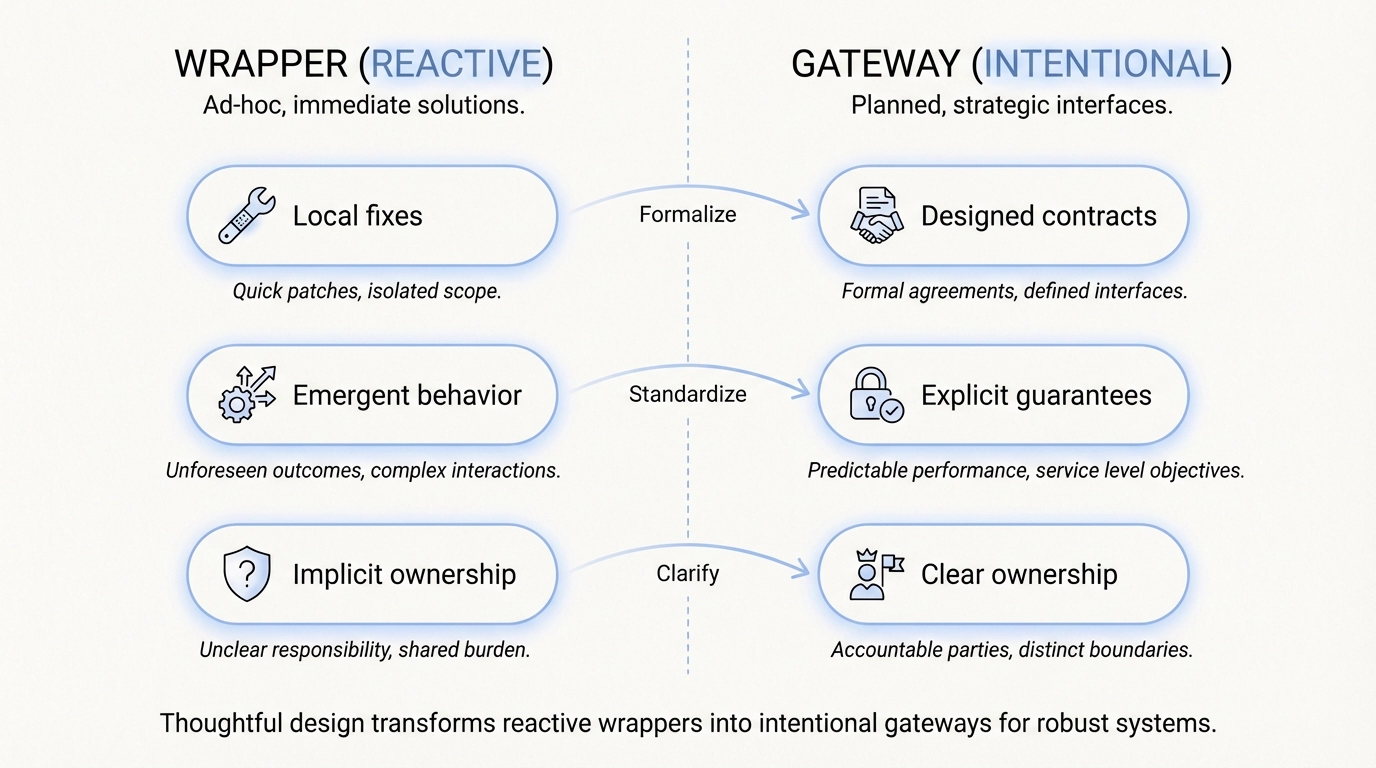
래퍼는 대개 사후 대응적입니다. 게이트웨이는 설계됩니다.
구축인가 진화인가: 팀이 직면한 진짜 결정
"래퍼를 만들어야 할까?"라는 질문은 의미가 없습니다. 그 결정은 이미 암묵적으로 내려진 경우가 많기 때문입니다.
진짜 질문은 이것입니다:
임시방편(Ad-hoc) 식의 진화는 다음과 같은 결과를 초래하곤 합니다:
- 숨겨진 밀결합
- 일관성 없는 보장
- 소수의 엔지니어에게 집중된 지식
의도적인 인프라화는 다음과 같은 이점을 가져옵니다:
- 명확한 계약(Contracts)
- 관측 가능한 동작
- 명시적인 트레이드오프
어느 한쪽 길이 무조건 옳은 것은 아닙니다. 하지만 선택하지 않는 것 또한 하나의 선택입니다.
주의해야 할 안티 패턴
래퍼로 인해 어려움을 겪는 팀들은 흔히 비슷한 함정에 빠지곤 합니다:
- 제공업체별 로직이 제품 코드로 유출됨
- 여러 팀에서 각기 다른 래퍼를 유지 관리함
- 평가 벤치마크가 없는 라우팅 로직
- 사용량 할당(Attribution)이 없는 비용 추적
- 원격 측정(Telemetry)이나 알림이 없는 핵심 경로
이러한 패턴들은 시스템이 비공식적인 추상화 단계를 넘어섰음을 알리는 신호입니다.
간단한 자가 진단 체크리스트
다음 중 3개 이상에 "예"라고 답한다면, 래퍼는 이미 아키텍처의 일부가 된 것입니다:
- 제공업체별 조건문이 여러 서비스에 걸쳐 나타나는가?
- 프롬프트가 제품 코드 외부에서 주입되거나 수정되는가?
- LLM 사용량 또는 비용에 대한 단일 진실 공급원(Single Source of Truth)이 없는가?
- 재시도 또는 폴백 로직이 여러 곳에서 중복되는가?
- 제공업체 장애 시 여러 곳의 코드를 동시에 수정해야 하는가?
그렇다면 래퍼는 더 이상 선택 사항이 아닙니다.
👉 다음 단계
다음 질문은 직접 API를 사용하는 것이 여전히 올바른 추상화인지, 아니면 이제 게이트웨이를 도입할 가치가 있는지입니다.
맺음말
래퍼를 만드는 것은 실수가 아닙니다.
그것은 규모, 복잡성, 그리고 프로덕션 환경의 압박으로 인해 나타나는 현상입니다.
진짜 위험은 핵심 추상화 계층이 이미 인프라가 되었음에도 불구하고 오랫동안 "단순한 헬퍼"로 취급하는 것입니다.
래퍼가 언제 그 경계를 넘었는지 이해하는 것이, 앞으로 그 계층이 무엇이 되어야 할지 결정하는 첫걸음입니다.
FAQ
LLM API 래퍼란 무엇인가요?
래퍼는 동작을 정규화하고, 정책을 강제하며, 하나 이상의 LLM 제공업체에 걸쳐 신뢰성을 관리할 수 있는 중간 계층입니다.
팀에서 언제 LLM 래퍼를 구축해야 하나요?
대부분의 팀은 프로덕션 신뢰성, 비용 제어 또는 프롬프트 거버넌스가 반복적인 관심사가 되는 즉시 암묵적으로 구축하게 됩니다.
래퍼와 게이트웨이의 차이점은 무엇인가요?
실제로 래퍼는 사후 대응적인 수정 사항의 모음인 경우가 많지만, 게이트웨이는 명시적인 계약을 가진 의도적으로 설계된 인프라입니다.
래퍼 이상의 단계로 넘어가야 할 시점은 언제인가요?
여러 팀이 그 래퍼에 의존하고, 장애가 널리 전파되며, 운영상의 보장이 중요해질 때, 그 래퍼는 이미 인프라가 된 것이므로 그에 맞게 대우해야 합니다.


