
Quand un wrapper d’API LLM devient une infrastructure

Quand un wrapper d’API LLM devient une infrastructure
La plupart des équipes d’ingénierie ne se lancent pas pour construire un wrapper d’API LLM.
Il n’y a généralement ni document de lancement, ni feuille de route explicite, ni moment où quelqu’un dit : « Abstraisons tous nos fournisseurs de modèles. » À la place, les wrappers émergent discrètement — ligne par ligne — lorsque les équipes tentent de stabiliser des systèmes en production.
Cet article explique pourquoi les wrappers apparaissent souvent en production, comment reconnaître le moment où l’un d’eux bascule vers l’infrastructure, et quelles décisions les équipes doivent généralement prendre ensuite.
Ce qu’est un wrapper d’API LLM en pratique
En production, un wrapper est rarement un composant unique. C’est une couche logique en croissance entre votre application et un ou plusieurs fournisseurs de LLM.
Responsabilités courantes :
- Normaliser les schémas de requête et de réponse
- Gérer les retries, les timeouts et les erreurs spécifiques aux fournisseurs
- Piloter la sélection de modèles ou la logique de repli
- Injecter des prompts, messages système ou règles de sécurité
- Suivre l’usage pour l’attribution des coûts, le logging ou les audits
La plupart des wrappers commencent comme du code de commodité. Beaucoup finissent par devenir des chemins critiques.
Pourquoi les wrappers émergent (même sans intention)
Les équipes ne construisent pas des wrappers parce qu’elles veulent de l’abstraction. Elles le font parce que l’intégration directe cesse souvent d’être fiable sous la pression de la production.
Voici les forces les plus fréquentes qui poussent dans cette direction.
1. L’incohérence de comportement est plus difficile que l’incohérence d’interface
Les schémas d’API sont relativement faciles à normaliser. Le comportement à l’exécution ne l’est pas.
Les équipes rencontrent souvent des différences telles que :
- Des réponses en streaming qui se figent, se segmentent différemment ou échouent silencieusement
- Des erreurs qui se ressemblent mais nécessitent des traitements opérationnels différents
- Des timeouts imprévisibles sous charge
- Des différences subtiles d’interprétation ou de troncature des prompts
Quand ces problèmes apparaissent en production, une réponse courante à court terme consiste à ajouter une gestion locale, spécifique aux fournisseurs :
if provider == X:
retry differently
if streaming stalls:
fallback to non-streamAvec le temps, ces conditions s’accumulent. Un wrapper ne se forme pas pour « nettoyer l’API », mais pour contenir l’imprévisibilité des comportements.
2. Le contrôle des prompts commence comme une commodité et finit comme une politique
Au début, les prompts ne sont que des chaînes passées depuis le code applicatif.
Plus tard, ils deviennent :
- Des assets versionnés
- Partagés entre plusieurs services
- Couplés à des baselines d’évaluation
- Parfois relus pour la sécurité, la conformité ou les standards de qualité (selon le produit et le profil de risque)
À ce stade, les prompts cessent d’être des détails applicatifs et deviennent de la configuration.
Les wrappers émergent pour :
- Centraliser l’injection de prompts
- Faire respecter des instructions système
- Réduire la dérive accidentelle entre services
Ce qui ressemble à des « helpers de prompts » est souvent le premier signe de centralisation des politiques.
3. La visibilité des coûts se fragmente sans couche intermédiaire
L’usage direct des API disperse les signaux de coût entre fournisseurs :
- Unités de prix différentes
- Cadences de facturation différentes
- Sémantiques de rate-limit différentes
Les équipes d’ingénierie ressentent souvent cette douleur tôt — parfois avant la finance.
Les wrappers apparaissent pour :
- Suivre l’usage de manière cohérente
- Attribuer les coûts aux fonctionnalités ou aux équipes
- Poser des garde-fous avant que la facture n’explose
Ce n’est pas forcément de la maturité FinOps. C’est souvent de l’ingénierie défensive.
4. Les garanties de fiabilité ne passent pas à l’échelle dans le code produit
Quand les LLM passent d’expériences à des dépendances, les équipes ont besoin de :
- Fallbacks
- Rotation de fournisseurs
- Dégradation gracieuse
Insérer cette logique directement dans le code applicatif crée une forte couplage et des chemins fragiles.
Un wrapper devient alors l’endroit naturel pour exprimer l’intention de fiabilité :
- « Si ça échoue, essaie ceci. »
- « Si la latence dépasse le seuil, downgrade. »
- « Si le quota est atteint, change de modèle. »
À ce stade, le wrapper n’est plus un simple collage optionnel. Il peut commencer à imposer des attentes de niveau de service.
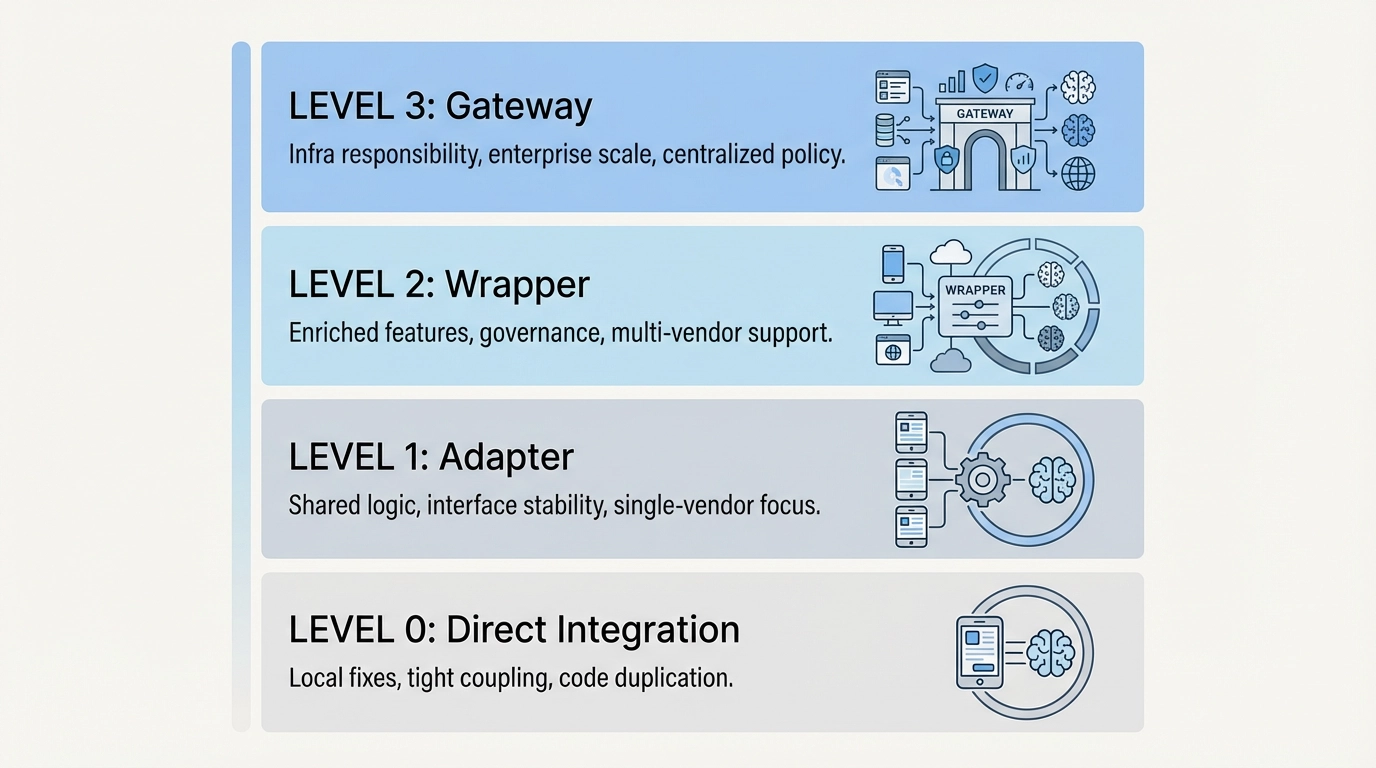
Le modèle de maturité des wrappers
Beaucoup d’équipes sous-estiment l’évolution de leur wrapper. Le tableau ci-dessous décrit une progression fréquente.
| Étape | À quoi cela ressemble | Douleur courante | Ce qui vient ensuite |
|---|---|---|---|
| Intégration directe | L’app appelle les fournisseurs directement | Exceptions dispersées | Adaptateur minimal |
| Adaptateur | Schéma unifié, helpers légers | Dérive de comportement | Retries centralisés |
| Wrapper | Prompts, routage, suivi des coûts | Goulots d’étranglement d’ownership | Pensée infra |
| Gateway | Contrats explicites & observabilité | Les arbitrages deviennent visibles | Alignement organisationnel |
Si votre système opère à l’étape 2 ou au-delà, le wrapper cesse souvent d’être temporaire et commence à prendre des responsabilités d’infrastructure.
Quand un wrapper devient discrètement une infrastructure
Les équipes s’en rendent souvent compte trop tard.
Signaux typiques :
- Plusieurs équipes dépendent du même wrapper
- Les changements exigent coordination et plans de déploiement
- Les pannes touchent des services non liés
- La couche nécessite documentation, ownership et monitoring
À ce stade, le wrapper peut fonctionner comme une couche de gateway — même s’il n’est pas nommé ni opéré ainsi.
La différence n’est pas seulement la capacité, mais l’intention et l’exploitation.
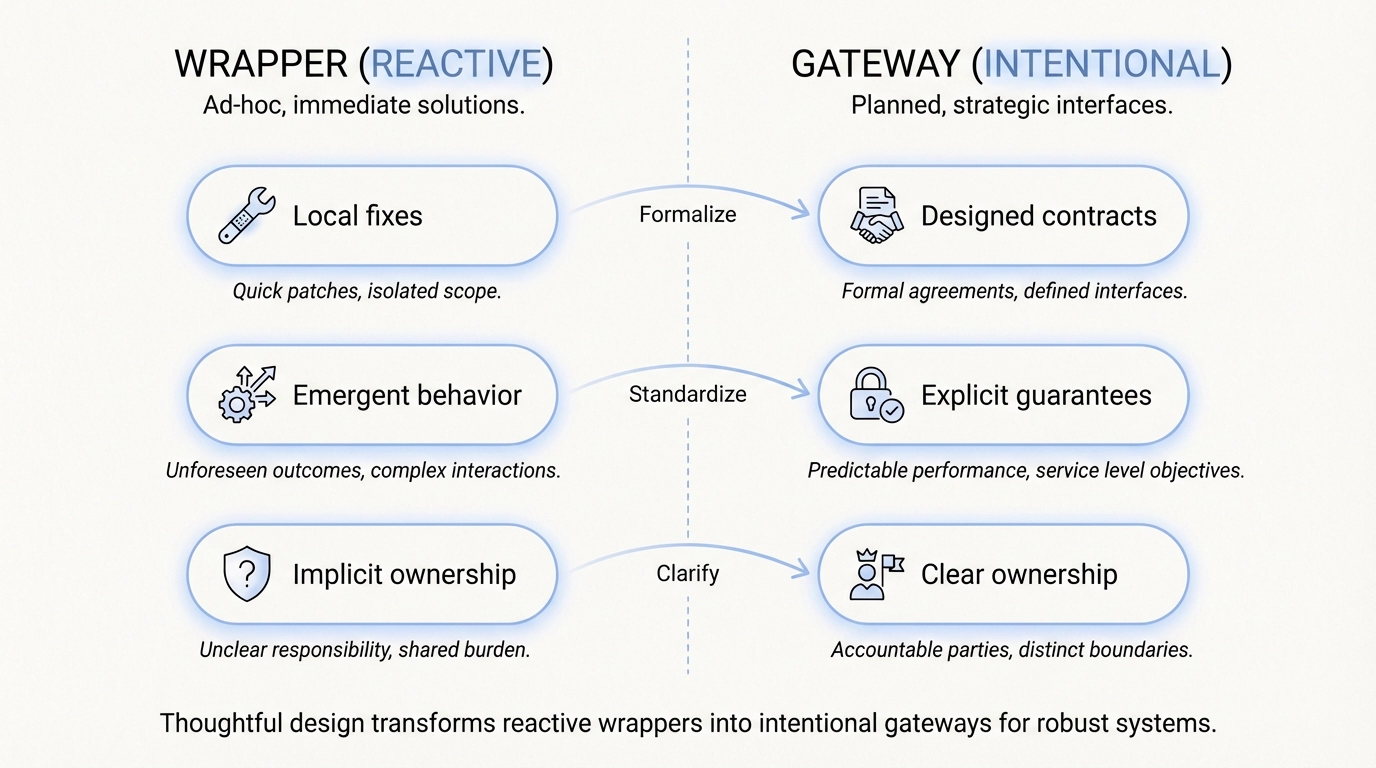
Les wrappers sont souvent réactifs. Les gateways sont conçus.
Construire ou faire évoluer : la vraie décision
La question n’est presque jamais « Doit-on construire un wrapper ? » Cette décision a souvent déjà été prise implicitement.
La vraie question devient :
L’évolution ad hoc mène souvent à :
- Couplage caché
- Garanties incohérentes
- Connaissance concentrée chez quelques ingénieurs
Une approche infra intentionnelle apporte souvent :
- Des contrats clairs
- Un comportement observable
- Des arbitrages explicites
Aucune voie n’est universellement correcte. Mais ne pas choisir reste un choix.
Anti‑patterns à surveiller
Les équipes qui peinent avec des wrappers tombent souvent dans des pièges similaires :
- Logique spécifique aux fournisseurs qui fuit dans le code produit
- Plusieurs wrappers maintenus par des équipes différentes
- Routage sans baselines d’évaluation
- Suivi des coûts sans attribution d’usage
- Chemins critiques sans télémétrie ni alertes
Ces patterns signalent souvent que le système a dépassé l’abstraction informelle.
Une auto‑évaluation simple
Si vous répondez « oui » à trois questions ou plus, le wrapper fait probablement déjà partie de votre architecture :
- Des conditions spécifiques aux fournisseurs apparaissent‑elles dans plusieurs services ?
- Des prompts sont‑ils injectés ou modifiés en dehors du code produit ?
- N’y a‑t‑il pas de source unique de vérité pour l’usage ou les coûts LLM ?
- La logique de retry ou de fallback est‑elle dupliquée à plusieurs endroits ?
- Une panne fournisseur nécessiterait‑elle des changements de code coordonnés ?
Si oui, le wrapper n’est plus optionnel.
👉 Prochaine étape
la prochaine question est de savoir si les API directes restent la bonne abstraction — ou si un gateway vaut maintenant le compromis.
Pensée finale
Les wrappers ne sont pas une erreur.
Ils sont un symptôme d’échelle, de complexité et de pression de production.
Le vrai risque est de traiter une couche d’abstraction critique comme de « simples helpers » bien après qu’elle soit devenue de l’infrastructure.
Comprendre quand un wrapper a franchi cette limite est la première étape pour décider de ce qu’il doit devenir ensuite.
FAQ
Qu’est‑ce qu’un wrapper d’API LLM ?
Un wrapper est une couche intermédiaire qui peut normaliser les comportements, faire respecter des politiques et gérer la fiabilité auprès d’un ou plusieurs fournisseurs LLM.
Quand une équipe doit‑elle construire un wrapper LLM ?
Beaucoup d’équipes en construisent un implicitement dès que la fiabilité en production, le contrôle des coûts ou la gouvernance des prompts deviennent récurrents.
Quelle est la différence entre wrapper et gateway ?
En pratique, les wrappers sont souvent des ensembles réactifs de correctifs, tandis que les gateways sont intentionnellement conçus avec des contrats explicites.
Comment savoir quand dépasser le wrapper ?
Quand plusieurs équipes en dépendent, que les pannes se propagent largement et que les garanties opérationnelles comptent, le wrapper est probablement devenu de l’infrastructure et doit être traité comme tel.


