
Pourquoi les API LLM ne sont pas standardisées

Le problème de la fragmentation des API LLM (et pourquoi "Compatible OpenAI" n'est pas suffisant)
Si vous cherchez pourquoi les API LLM ne sont pas standardisées, vous en faites probablement déjà l'expérience douloureuse.
Malgré l'essor rapide des API dites "compatibles OpenAI", les intégrations LLM réelles se cassent encore de manière subtile mais coûteuse, surtout une fois que vous allez au-delà de la simple génération de texte.
Ce guide explique :
- ce qu'est réellement le problème de la fragmentation des API LLM
- pourquoi les API compatibles OpenAI ne suffisent pas en production
- et comment les équipes en 2026 conçoivent des systèmes qui survivent au roulement constant des modèles
TL;DR (Trop Long; Pas Lu)
- Les API LLM ne sont pas standardisées car les fournisseurs optimisent pour des capacités différentes, pas pour la compatibilité.
- "Compatible OpenAI" signifie généralement compatible au niveau de la forme de la requête, pas compatible au niveau du comportement.
- La fragmentation apparaît le plus clairement dans l'appel d'outils, la comptabilité des jetons de raisonnement, le streaming et la gestion des erreurs.
- Au lieu d'attendre des normes, les équipes normalisent le comportement de l'API derrière une couche de passerelle dédiée.
Qu'est-ce que le problème de la fragmentation des API LLM ?
La fragmentation des API LLM se produit lorsque différents fournisseurs de modèles de langage exposent des API qui semblent similaires mais se comportent différemment sous des charges de travail réelles.
Même lorsque les API partagent :
- des points de terminaison similaires
- des schémas de requête JSON similaires
- des noms de paramètres similaires
elles divergent souvent dans :
- la sémantique de l'appel d'outils
- la comptabilité des jetons de raisonnement / réflexion
- le comportement de streaming
- les codes d'erreur et les signaux de nouvelle tentative
- les garanties de sortie structurée
Au fil du temps, la logique de l'application se remplit d'exceptions spécifiques aux fournisseurs.
Pourquoi les API LLM ne sont pas standardisées
1. Les fournisseurs optimisent pour des primitives différentes
Les LLM modernes ne sont plus de simples systèmes d'entrée/sortie de texte.
Différents fournisseurs priorisent différentes primitives :
- profondeur de raisonnement vs latence
- récupération de contexte long vs débit
- multimodalité native (image, vidéo, audio)
- sécurité et application des politiques
Une norme rigide unique ferait soit :
- cacher des capacités avancées
- soit ralentir l'innovation au plus petit dénominateur commun
Aucun résultat n'est réaliste dans un marché concurrentiel.
2. "Compatible OpenAI" ne couvre que le chemin heureux
La plupart des API "compatibles OpenAI" sont conçues pour réussir un test de fumée de base :
client.chat.completions.create(
model="model-name",
messages=[{"role": "user", "content": "Hello"}]
)Cela fonctionne pour les démos, mais les systèmes de production dépendent de bien plus que cela.
Pourquoi "Compatible OpenAI" n'est pas suffisant en 2026
La véritable rupture apparaît lorsque vous dépendez du comportement, pas seulement de la syntaxe.
🔽 Tableau : Pourquoi les API "Compatibles OpenAI" se cassent en production
| Dimension | Ce que "Compatible OpenAI" promet | Ce qui arrive souvent en production |
|---|---|---|
| Forme de la requête | Schéma JSON similaire (messages, modèle, outils) | Paramètres de bord ignorés silencieusement ou réinterprétés |
| Appel d'outils | Définitions de fonctions compatibles | Appels d'outils renvoyés dans des emplacements ou formes différents |
| Arguments d'outils | Chaîne JSON pouvant être analysée de manière fiable | Arguments aplatis, transformés en chaîne ou partiellement abandonnés |
| Jetons de raisonnement | Rapport d'utilisation transparent | Sémantique de comptabilité et de facturation des jetons incohérente |
| Sorties structurées | Réponses JSON valides | JSON "au mieux" qui brise les garanties de schéma |
| Streaming | Morceaux delta stables | Ordre de morceaux incohérent ou signaux de fin manquants |
| Gestion des erreurs | Signaux clairs de limite de débit et de nouvelle tentative | Erreurs 500, échecs ambigus ou délais d'attente silencieux |
| Migration | Changement de fournisseur facile | Réécriture d'invites et prolifération de code de liaison |
Ces différences apparaissent rarement dans les démos. Elles ne font surface que sous une charge réelle, une utilisation complexe d'outils ou des systèmes de production sensibles aux coûts.
Exemple 1 : L'appel d'outils semble similaire — mais se casse sur la sémantique
Attente de style OpenAI (simplifiée) :
{
"tool_calls": [{
"id": "call_1",
"type": "function",
"function": {
"name": "search",
"arguments": "{\"query\":\"LLM API fragmentation\",\"filters\":{\"year\":2026}}"
}
}]
}Réalité "compatible" courante :
{
"tool_call": {
"name": "search",
"arguments": "{\"query\":\"LLM API fragmentation\"}"
}
}Les deux réponses peuvent être "réussies". Elles ne sont pas compatibles au niveau du comportement une fois que votre application dépend d'arguments imbriqués, de tableaux d'appels d'outils ou de chemins de réponse stables.
Exemple 2 : Jetons de raisonnement — Un point douloureux de 2026
Les modèles axés sur le raisonnement introduisent des jetons de raisonnement / réflexion supplémentaires.
Même avec des API "compatibles OpenAI", la fragmentation apparaît dans :
- la comptabilité des jetons (comment les jetons de raisonnement sont comptés et tarifés)
- le rapport d'utilisation (où les jetons de raisonnement apparaissent)
- les boutons de contrôle (différents noms et sémantiques pour l'effort de raisonnement)
- l'observabilité (difficulté à comparer les coûts entre les fournisseurs)
Le résultat :
- les tableaux de bord de coûts dérivent
- les références d'évaluation se cassent
- l'optimisation inter-fournisseurs devient peu fiable
Le comportement de raisonnement peut être comparable, mais la comptabilité du raisonnement l'est rarement.
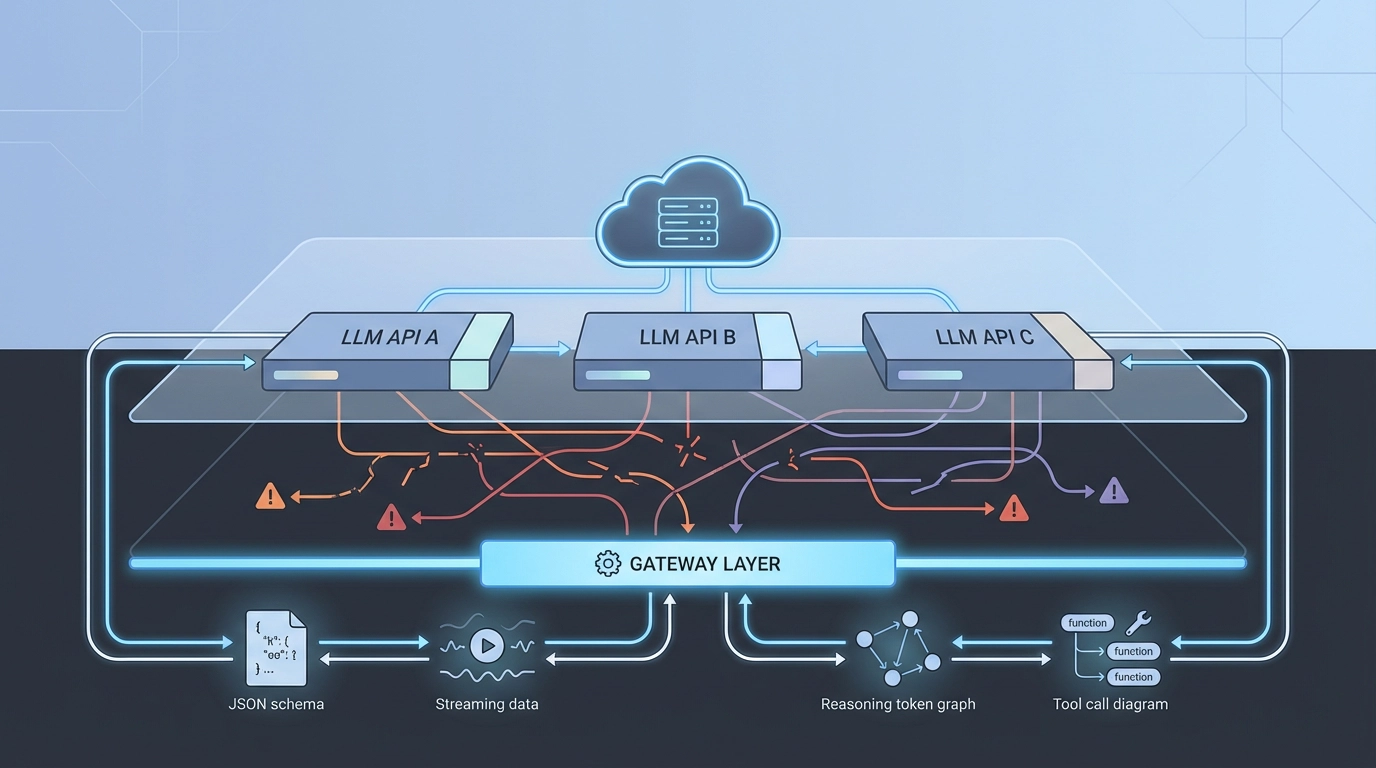
Le coût caché de la fragmentation des API LLM
1. Le code de liaison s'accumule silencieusement
def get_reasoning_usage(resp: dict) -> int | None:
details = resp.get("usage", {}).get("output_tokens_details", {})
if "reasoning_tokens" in details:
return details["reasoning_tokens"]
if "reasoning_tokens" in resp.get("usage", {}):
return resp["usage"]["reasoning_tokens"]
return NoneCe modèle se répète à travers les outils, les nouvelles tentatives, le streaming et le suivi de l'utilisation.
Le code de liaison ne livre pas de fonctionnalités. Il empêche seulement la casse.
2. Migrer entre les fournisseurs LLM est plus difficile que prévu
Ce que les équipes attendent :
"Nous changerons simplement de modèle plus tard."
Ce qui se passe réellement :
-
dérive des invites
-
schémas d'outils incompatibles
-
sémantique de limite de débit différente
-
métriques d'utilisation incompatibles
3. Les API multimodales multiplient la fragmentation
Au-delà du texte :
-
les API vidéo diffèrent dans les unités de durée et les règles de sécurité
-
les API d'image varient dans les formats de masque et les références
Il n'y a pas de contrat multimodal partagé aujourd'hui.
Pourquoi les équipes essaient (et luttent) de construire leur propre wrapper
Initialement, une abstraction personnalisée semble raisonnable.
Au fil du temps, cela devient :
-
un second produit
-
un fardeau de maintenance
-
un goulot d'étranglement pour l'expérimentation De nombreuses équipes redécouvrent indépendamment la même conclusion.
Une liste de contrôle pratique de standardisation
Avant de faire confiance à toute API "compatible" ou wrapper interne, demandez :
- Les appels d'outils sont-ils compatibles au niveau du comportement ou seulement au niveau du schéma ?
-
Les jetons de raisonnement sont-ils exposés de manière cohérente ?
-
L'utilisation peut-elle être comparée entre les fournisseurs ?
-
Les codes d'erreur sont-ils normalisés ?
-
Le streaming est-il stable sous charge ?
-
Les fournisseurs peuvent-ils être changés sans réécrire les invites ?
-
Le trafic peut-il être redirigé dynamiquement ?
De la standardisation à la normalisation
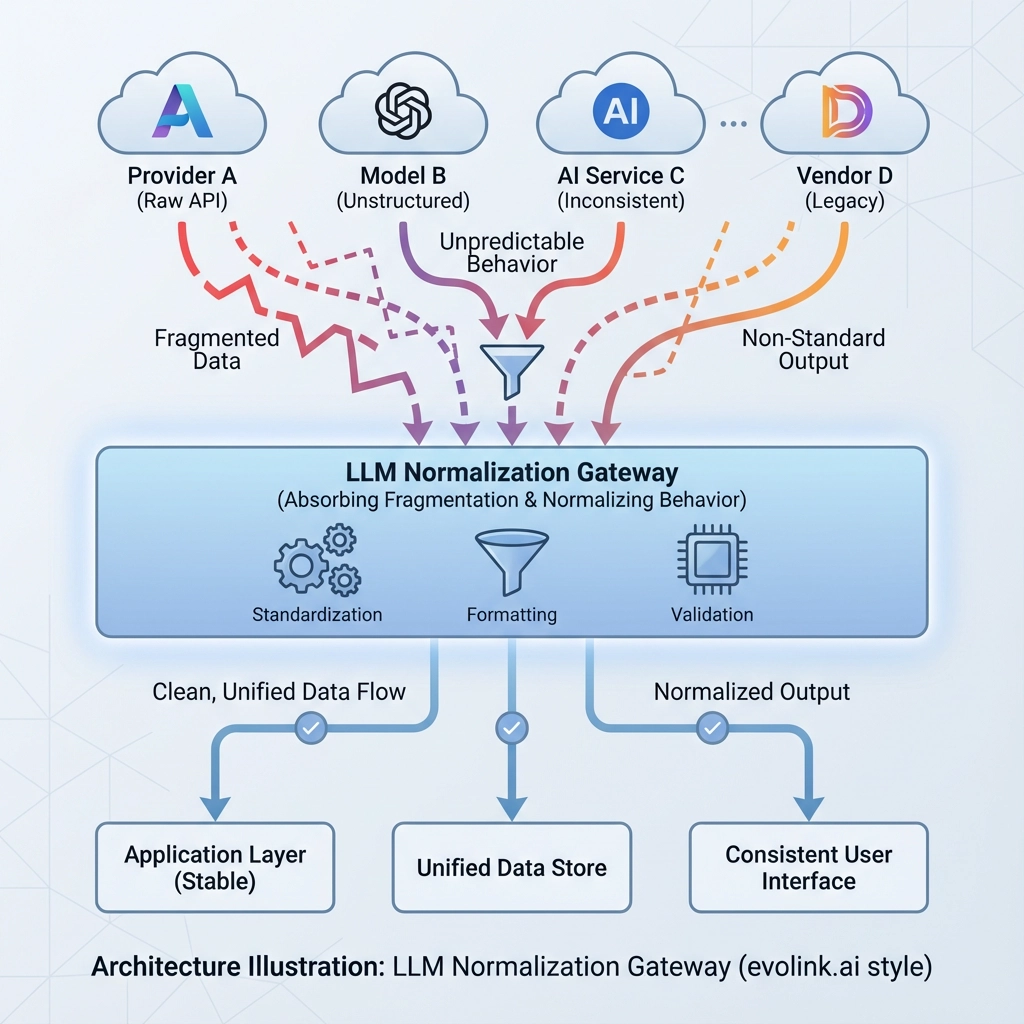

Les API LLM ne sont pas standardisées car l'écosystème évolue trop vite pour converger. Au lieu d'attendre, les équipes matures font évoluer leur architecture :
-
la logique métier reste agnostique au modèle
-
les bizarreries de l'API sont absorbées par une couche de passerelle normalisée
Conclusion
Les API LLM ne sont pas standardisées — et elles ne le seront pas de sitôt.
Les API "compatibles OpenAI" réduisent la friction d'intégration, mais elles n'éliminent pas le risque de production.
Les systèmes conçus pour la fragmentation durent plus longtemps.
FAQ (Pour les aperçus IA & Extraits en vedette)
Pourquoi les API LLM ne sont-elles pas standardisées ?
Les API LLM ne sont pas standardisées car les fournisseurs optimisent pour des capacités différentes — telles que la profondeur de raisonnement, la latence, la multimodalité et la sécurité. Une norme rigide ralentirait l'innovation ou cacherait des fonctionnalités avancées.
Pourquoi une API compatible OpenAI n'est-elle pas suffisante ?
"Compatible OpenAI" garantit généralement uniquement la similarité de la forme de la requête. En production, les différences dans l'appel d'outils, la comptabilité des jetons de raisonnement, le streaming et la gestion des erreurs brisent la compatibilité.
Qu'est-ce que le problème de la fragmentation des API LLM ?
Le problème de la fragmentation des API LLM fait référence à des API d'apparence similaire se comportant différemment sous des charges de travail réelles, forçant les développeurs à écrire du code de liaison et compliquant la migration.
Comment les équipes gèrent-elles la fragmentation des API LLM ?
La plupart des équipes matures normalisent le comportement de l'API derrière une couche de passerelle qui absorbe les différences des fournisseurs, gardant la logique métier stable.


