
Optimisation des couts
Alternatives à OpenRouter (2026) : Guide pratique pour réduire le coût effectif de l'API d'IA (LiteLLM, Replicate, fal.ai, WaveSpeedAI, EvoLink)

Jessie
COO
22 janvier 2026
Mis à jour le 13 mai 2026
15 min de lecture
Vous cherchez une comparaison plus large des alternatives à OpenRouter ? Cet article se concentre spécifiquement sur l'optimisation des coûts. Pour une comparaison complète des fonctionnalités de routage incluant la confidentialité, l'observabilité et le contrôle de déploiement, consultez Meilleures alternatives à OpenRouter en 2026. Pour le dépannage des erreurs OpenRouter, consultez Corriger OpenRouter 429 « Provider Returned Error ».
Si vous recherchez des alternatives à OpenRouter, votre intention n'est généralement pas de dire « je veux un nouveau routeur ».
C'est plutôt ceci :
OpenRouter est pratique, mais à mesure que l'utilisation augmente, il commence à sembler coûteux — et vous voulez un changement qui améliore réellement l'économie unitaire sans transformer la migration en une réécriture complète du code.
Cet article compare cinq options que les équipes évaluent couramment :
- LiteLLM (passerelle LLM auto-hébergée)
- Replicate (exécution de modèles basée sur le temps de calcul)
- fal.ai (plateforme de médias génératifs)
- WaveSpeedAI (flux de travail de génération visuelle)
- EvoLink.ai (passerelle unifiée pour le chat, l'image et la vidéo avec routage intelligent)
Nous utiliserons également OpenRouter comme base de référence pour le contexte.
TL;DR : Quelle alternative devriez-vous évaluer en premier ?
- Si vous voulez une gouvernance d'auto-hébergement + un contrôle maximal → LiteLLM
- Si vos charges de travail sont de type calcul/tâche et que vous voulez des prix de matériel publiés → Replicate
- Si votre dépense principale est la génération d'images/vidéos → fal.ai ou WaveSpeedAI
- Si votre problème de coût est lié à la variance des canaux et que vous voulez unifier chat + image + vidéo derrière une seule API → EvoLink.ai
Si vous voulez essayer EvoLink rapidement plus tard dans ce guide :
→ Obtenir une clé API EvoLink
Explorer EvoLink Smart Router
Ce que signifie réellement « OpenRouter semble coûteux » (en production)
La plupart des équipes ne ressentent pas de pression sur les coûts lors du prototypage initial. Le coût devient douloureux quand :
- vous avez des utilisateurs réels (et une utilisation imprévisible)
- des tentatives de réessai commencent à se produire (pics de 429/délais d'attente)
- vous introduisez des fonctionnalités multimodales (texte + image + vidéo)
- vous commencez à optimiser la marge brute et l'économie unitaire
À ce stade, vous ne vous souciez plus seulement du « prix du jeton » (token price), mais du coût effectif par résultat :
- coût par résolution de support réussie
- coût par achèvement du flux de travail d'un agent
- coût par actif image (y compris les réessais et les échecs)
- coût par vidéo courte (y compris les échecs et le gaspillage dans la file d'attente)
La check-list de 15 minutes avant le changement
| Étape | Action | Résultat |
|---|---|---|
| 1 | Choisissez un KPI : coût effectif par résultat | Un chiffre unique sur lequel votre équipe peut se mobiliser |
| 2 | Mesurez le taux de réessai, le taux d'erreur, la latence p95 | Base pour le « gaspillage » + impact sur l'expérience utilisateur |
| 3 | Étiquetez votre charge de travail : texte seul vs multimodal | Détermine si un « routeur LLM » est suffisant |
| 4 | Décidez de la tolérance : géré vs auto-hébergé | Détermine le choix entre LiteLLM et des outils gérés |
| 5 | Planifiez le déploiement : shadow → canary → ramp | Prévient les migrations risquées de type « big-bang » |
La « pile des coûts effectifs » (là où l'argent disparaît)
| Couche | Facteur de coût | À quoi cela ressemble-t-il | Que mesurer |
|---|---|---|---|
| L1 | Coût d'utilisation | jetons / par résultat / par seconde | $ par session/tâche/actif |
| L2 | Variance des canaux | même capacité, prix effectifs différents selon les canaux | distribution des prix sur les routes |
| L3 | Gaspillage par échec | réessais, délais d'attente, tempêtes 429 | taux de réessai, erreurs pour 1 000 appels |
| L4 | Surcharge d'ingénierie | nombreux SDK, nombreux comptes de facturation, dérive | temps passé par intégration |
| L5 | Éparpillement des modalités | texte + image + vidéo sur plusieurs plateformes | nombre de fournisseurs sur le chemin critique |
Si OpenRouter semble coûteux, c'est souvent à cause des couches L2 à L5.
Tableau 1 — Matrice d'adéquation des plateformes (alignée sur l'intention « OpenRouter est coûteux »)
| Plateforme | Quand est-ce une alternative solide à OpenRouter | Type de facturation typique (haut niveau) | Friction de migration | Compromis à considérer |
|---|---|---|---|---|
| LiteLLM | Vous voulez le contrôle de l'auto-hébergement (budgets, routage, gouvernance) et pouvez gérer l'infra | Passerelle OSS/proxy + vos coûts d'infra | Moyenne à élevée | Vous gérez l'opérationnel : HA, mises à jour, dérive des fournisseurs, monitoring |
| Replicate | Votre charge de travail est de type calcul/tâche et vous voulez des prix de matériel publiés | Temps de calcul / secondes de matériel (varie selon le modèle) | Moyenne | La variance du temps d'exécution peut réduire la prévisibilité ; testez avec des entrées réelles |
| fal.ai | Vous utilisez beaucoup de médias (image/vidéo/audio) et voulez une large galerie de modèles | Plateforme de médias génératifs basée sur l'utilisation | Moyenne | Le coût effectif dépend des modèles choisis + de la conception du flux de travail |
| WaveSpeedAI | Vous construisez des flux de travail de génération visuelle (image/vidéo), orientés médias | Plateforme de médias basée sur l'utilisation | Moyenne | Complète souvent un routeur LLM au lieu de le remplacer |
| EvoLink.ai | Vous voulez réduire le coût effectif via le routage intelligent entre canaux et unifier chat + image + vidéo | Passerelle basée sur l'utilisation ; optimisation des coûts par le routage | Faible à moyenne | Vérifiez l'adéquation si vous exigez un auto-hébergement strict/on-prem ou des besoins de conformité spécifiques |
| OpenRouter (référence) | Changement rapide de modèle LLM derrière une seule API | Accès LLM de type jeton | N/A | Peut sembler coûteux quand le coût effectif augmente (gaspillage + surcharge + éparpillement) |
Archétypes de charge de travail : choisissez une alternative qui correspond à votre produit
| Archétype de charge de travail | Ce que vous optimisez | Meilleures options | Pourquoi |
|---|---|---|---|
| Chat SaaS / copilote de support | coût par session, latence p95, gaspillage par réessai | LiteLLM, EvoLink | LiteLLM pour la gouvernance auto-hébergée ; EvoLink pour l'économie de routage + pile unifiée |
| Agents de codage / devtools | gestion des pics, budgets/clés d'org, agilité des modèles | LiteLLM, EvoLink | LiteLLM pour le contrôle de la plateforme ; EvoLink pour un routage à faible friction + souci des coûts |
| Images marketing (gros volumes) | coût par actif, débit, asynchrone/webhooks | fal.ai, WaveSpeedAI, EvoLink | fal/WaveSpeed sont orientés médias ; EvoLink si vous voulez une seule interface pour toutes les modalités |
| Génération de vidéos courtes | coût par vidéo, comportement des files d'attente, échecs | fal.ai, WaveSpeedAI, EvoLink | Les plateformes de médias sont spécialisées ; EvoLink pour la multimodalité unifiée + économie de routage |
| Recherche / expérimentation | couverture, prototypage rapide, clarté des prix infra | Replicate, OpenRouter | Replicate s'adapte bien au calcul ; OpenRouter est pratique pour l'itération LLM |
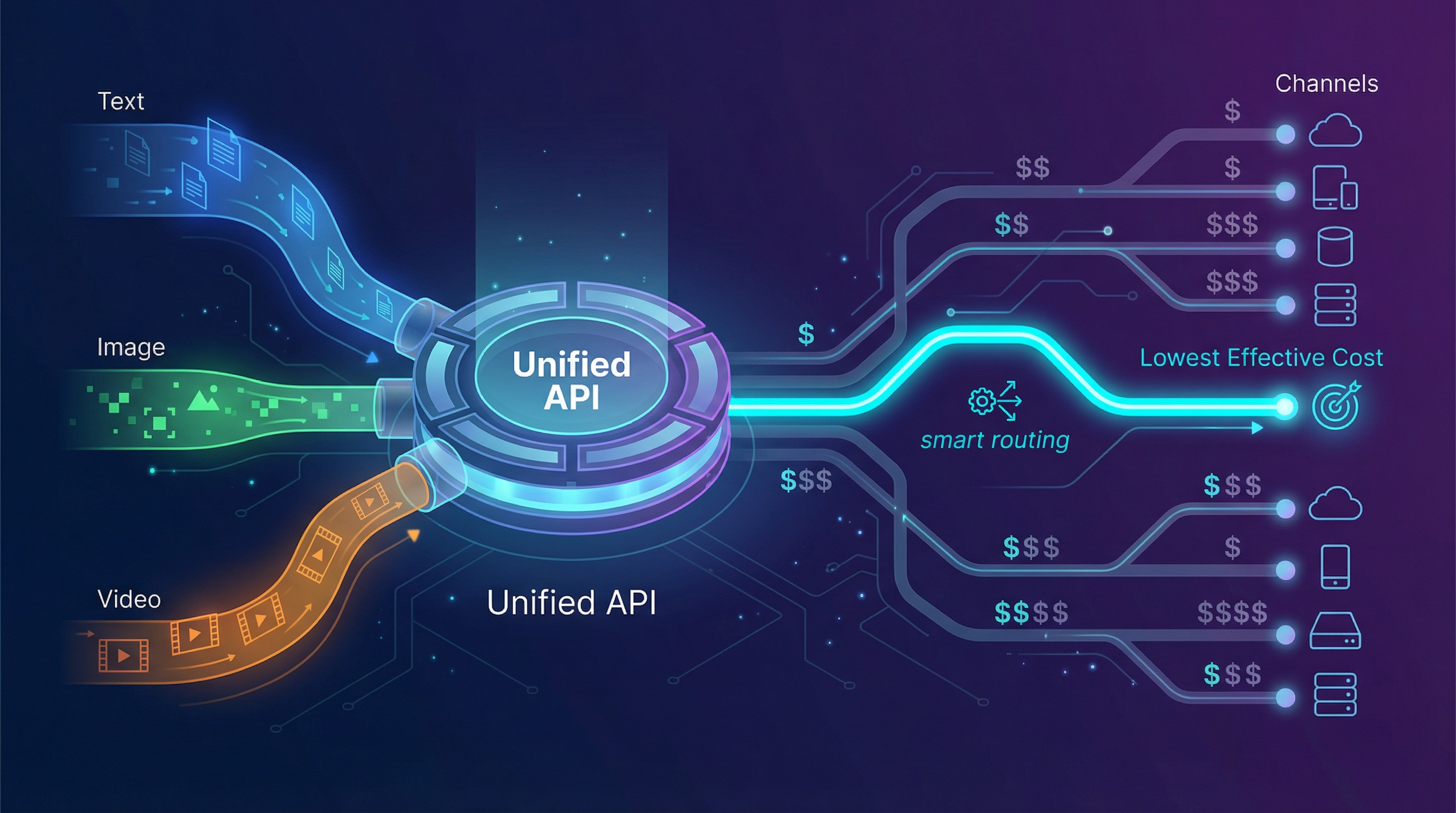
Les alternatives : que évaluer (et comment)
1) LiteLLM — contrôle de passerelle auto-hébergée (format OpenAI)
LiteLLM est couramment évalué quand les équipes veulent :
- Une interface au format OpenAI pour tous les fournisseurs
- Des budgets centralisés, des limites de débit et une gouvernance
- Des options d'auto-hébergement / on-prem
Comment LiteLLM gagne généralement
- Vous voulez posséder la couche de politique (budgets, authentification, règles de routage) dans votre environnement.
- Vous acceptez d'échanger la surcharge liée aux fournisseurs contre du temps d'ingénierie et une responsabilité opérationnelle.
Où les équipes sont surprises
- Le « routeur » devient votre responsabilité :
- Haute disponibilité (HA), mise à l'échelle, réponse aux incidents
- Dérive des fournisseurs (les API changent)
- Pipelines de logs/métriques
- Vous devez gérer activement les réessais/solutions de secours pour éviter le gaspillage.
Comment tester LiteLLM sans trop s'engager
- Commencez en staging
- Utilisez le trafic shadow (dupliquez les appels ; sans impact pour les utilisateurs)
- Ajoutez des limites de dépenses tôt
- Passez en canari seulement après des vérifications de parité des sorties
2) Replicate — exécution de modèles au temps de calcul avec prix du matériel publiés
Replicate est souvent évalué quand votre charge de travail ressemble plus à des « tâches » qu'à des tours de chat :
- vous exécutez des prédictions de modèles comme des tâches de calcul
- vous voulez des niveaux de prix du matériel transparents (GPU $/sec)
Comment Replicate gagne généralement
- Très adapté à l'expérimentation et aux charges de travail de type calcul
- La clarté des prix du matériel aide à la prévision (quand le temps d'exécution est stable)
Où les équipes sont surprises
- La variabilité du temps d'exécution devient une variabilité du coût.
- La fiabilité de niveau production peut varier selon le modèle et la charge de travail.
Comment tester Replicate
- Faites des benchmarks avec des entrées réelles
- Enregistrez la distribution du temps d'exécution (p50/p95/p99)
- Convertissez en coût par résultat (actif/tâche), pas seulement en coût par seconde
3) fal.ai — plateforme de médias génératifs (large catalogue + passage à l'échelle)
fal.ai est souvent choisi pour les produits gourmands en médias :
- génération d'images/vidéos/audio
- large galerie de modèles
- positionnement sur la performance et le passage à l'échelle
Comment fal.ai gagne généralement
- Vous voulez une large couverture de médias sous une seule plateforme.
- Vous privilégiez la vitesse et l'échelle pour les API de médias.
Où les équipes sont surprises
- Le coût effectif dépend extrêmement du modèle et du flux de travail choisis.
- Les choix de conception asynchrone/webhook peuvent fortement affecter le gaspillage lié aux échecs.
Comment tester fal.ai
- Choisissez 2 ou 3 points de terminaison/modèles correspondant à votre produit
- Testez :
- la latence d'une seule exécution
- le débit par lots
- Suivez : le gaspillage par échec et le coût par actif
4) WaveSpeedAI — flux de travail visuels orientés médias
WaveSpeedAI est couramment évalué pour les flux de travail de génération d'images/vidéos.
Comment WaveSpeedAI gagne généralement
- Vous voulez une plateforme orientée médias pour les fonctions de génération visuelle.
- Votre produit est plus « génération d'actifs » que « assistant de chat ».
Où les équipes sont surprises
- Il peut compléter un routeur LLM plutôt que de le remplacer.
- Le côté « moins cher » dépend de la structure du flux de travail (tâches asynchrones, réessais, etc.).
Comment tester WaveSpeedAI
- Mesurez le coût par actif
- Mesurez la distribution du temps pour obtenir un résultat
- Validez la stabilité sous des charges par lots
5) EvoLink.ai — coût effectif réduit via l'économie de routage + API multimodal unifiée
Si votre plainte est « OpenRouter est coûteux », la question clé est : coûteux à cause de quoi ?
Si la réponse est :
- votre coût effectif est gonflé par la variance des canaux
- les réessais et les échecs créent du gaspillage
- votre application devient multimodale (texte + image + vidéo)
- vous ne voulez pas gérer cinq intégrations de fournisseurs différentes
…alors EvoLink est positionné pour cette situation.
EvoLink se positionne publiquement sur :
- Une seule API pour le chat, l'image et la vidéo
- Plus de 40 modèles
- un routage intelligent conçu pour réduire les coûts (annonce « jusqu'à 70 % d'économie »)
- des garanties de fiabilité incluant un temps de fonctionnement de 99,9 % et un basculement automatique (failover)
Comment évaluer EvoLink (pour que la finance et l'ingénierie aient confiance)
- Choisissez 1 flux de travail représentatif (pas un prompt basique).
- Exécutez un test canari de 1 à 5 % pendant 24 à 48 heures.
- Comparez le coût effectif par résultat, le taux de réessai, la latence p95.
- Gardez la possibilité de retour en arrière (rollback).
Commencez ici
- Appel à l'action principal : Obtenir une clé API
- Catalogue de modèles : Modèles EvoLink
- Implémentation : Documentation API EvoLink
- Pratique de l'ingénierie : Guide de production GPT Image 1.5
Comment décider (sans trop réfléchir) : un flux de décision simple
-
Avez-vous besoin d'un auto-hébergement / d'une installation sur site / d'une gouvernance interne forte ? → Commencez par LiteLLM.
-
Votre charge de travail est-elle principalement axée sur la génération de médias (image/vidéo) ? → Commencez par fal.ai ou WaveSpeedAI.
-
Votre charge de travail est-elle de type calcul/tâche et vous souciez-vous de l'économie du temps d'exécution ? → Commencez par Replicate.
-
Voulez-vous une interface unique pour le chat/image/vidéo et votre problème de coût est le coût effectif (variance des canaux + gaspillage) ? → Testez EvoLink : Commencez gratuitement
Tableau 2 — Check-list d'atténuation du coût effectif (à mettre en œuvre quelle que soit la plateforme)
| Problème | Symptôme | Solution |
|---|---|---|
| Tempêtes de réessais | pics de dépenses lors des pannes de fournisseurs | plafonnement des réessais + mise en file d'attente + backoff |
| Double facturation suite aux actions utilisateur | clics répétés = appels répétés | clés d'idempotence + limitation de l'interface utilisateur |
| Chemins coûteux utilisés trop souvent | tout le trafic utilise l'option premium | politiques de routage + budgets |
| Le logging devient un centre de coûts | stockage permanent de tout | échantillonnage + limites de rétention |
| Difficile d'allouer les dépenses | le « coût de l'IA » est un bloc unique | étiquetez les requêtes par fonctionnalité/équipe/utilisateur |
Playbook de migration : changer sans transformer l'économie en risque
Tableau 3 — Plan de déploiement à faible risque (copier-coller)
| Phase | Ce que vous faites | Terminé quand |
|---|---|---|
| Référence | mesurez le coût effectif par résultat, le taux de réessai, la latence p95 | vous pouvez expliquer les facteurs de coût |
| Shadow | dupliquez les requêtes vers la nouvelle plateforme (sans impact utilisateur) | les sorties sont comparables ; pas d'échecs bloquants |
| Canary | routez 1 à 5 % du trafic réel | le KPI est amélioré ou neutre ; le rollback fonctionne |
| Ramp | 10 % → 25 % → 50 % → 100 % | stable sous charge de pointe |
| Optimisation | ajustez le routage + les budgets | la courbe des coûts s'améliore à mesure que le volume augmente |
Des garde-fous pour éviter l'effet « outil moins cher, résultat plus cher »
- Idempotence pour les actions des utilisateurs
- Plafonnement des réessais + mise en file d'attente
- Plafonnement des budgets par clé/équipe/projet
- Règles de secours basées sur le type d'échec (timeout/429/5xx)
- Échantillonnage des logs (évitez de tout loguer pour toujours)
Bonus : une fiche de travail sur le coût effectif à remettre à votre équipe
| Métrique | Référence (OpenRouter) | Candidat A | Candidat B |
|---|---|---|---|
| Coût effectif / résultat | |||
| Taux de réessai (%) | |||
| Taux d'erreur (pour 1 000) | |||
| Latence p95 (ms) | |||
| Nombre de fournisseurs sur le chemin critique (#) | |||
| Effort de migration (jours-homme) |
Résumé des recommandations (basé sur l'intention « OpenRouter semble coûteux »)
- Si vous avez besoin de la gouvernance de l'auto-hébergement + d'un contrôle maximal → LiteLLM
- Si vos charges de travail sont des tâches de type calcul et que vous voulez des prix de matériel publiés → Replicate
- Si vous faites principalement de la génération d'images/vidéos → fal.ai ou WaveSpeedAI
- Si vous voulez réduire le coût effectif via l'économie de routage et unifier chat/image/video derrière une seule surface → EvoLink.ai Essayez-le : Obtenir une clé API EvoLink
Prochaines étapes (pratiques, centrées sur la conversion)
- Choisissez votre premier candidat (basé sur l'archétype de charge de travail)
- Exécutez un canari de 1 à 5 % pendant 24 à 48 heures
- Comparez : coût effectif par résultat + taux de réessai + latence p95
- N'augmentez le trafic qu'après avoir prouvé la capacité de rollback
- Si vous testez EvoLink :
Notes (pour éviter les erreurs factuelles)
- Les prix, les catalogues et les ensembles de fonctionnalités changent fréquemment. Vérifiez les détails sur les pages officielles de chaque fournisseur avant de prendre des décisions budgétaires.
- Cet article référence OpenRouter pour répondre à l'intention de recherche ; il n'est pas affilié à OpenRouter.


