
TCO des LLM en 2026 : Pourquoi les coûts des jetons ne sont qu'une partie du prix réel

TCO des LLM en 2026 : Pourquoi les coûts des jetons ne sont qu'une partie du prix réel
La plupart des équipes estiment le coût des fonctionnalités LLM en utilisant une seule métrique : le prix par 1M de jetons.
Cette métrique compte — mais seulement sur le papier.
Dans les systèmes de production réels, le coût total de possession (TCO) des LLM est souvent déterminé non seulement par les dépenses en jetons, mais par les frais généraux d'ingénierie : travail d'intégration, correctifs de fiabilité, maintenance des invites et lacunes d'évaluation qui érodent silencieusement le retour sur investissement (ROI) de l'IA au fil du temps.
Ce guide explique les coûts cachés de l'intégration des LLM et fournit un cadre pratique pour identifier où vont réellement l'argent et le temps d'ingénierie :
- Glue Code (Code de liaison) — la taxe d'intégration continue
- Eval Debt (Dette d'évaluation) — le coût de l'incertitude
- Prompt Drift (Dérive des invites) — la migration qui ne finit jamais
Un audit personnel du TCO des LLM en 10 minutes
Avant d'aller plus loin, répondez à ces cinq questions :
- Combien de modèles ou de fournisseurs votre système prend-il en charge aujourd'hui (y compris ceux prévus) ?
- Maintenez-vous des adaptateurs spécifiques aux fournisseurs ou des branches conditionnelles ?
- Exécutez-vous des évaluations automatisées à chaque changement de modèle ?
- Pouvez-vous rediriger le trafic vers un autre modèle sans réécrire les invites ou la logique métier ?
- Avez-vous une vue unique des coûts, de la latence et des taux d'échec ?
Coût caché n°1 — Glue Code : La taxe d'intégration
Le code de liaison est un travail d'ingénierie qui ne produit aucune valeur pour l'utilisateur final mais qui est nécessaire pour normaliser les différences entre les fournisseurs.
Il se développe dans trois domaines prévisibles.
1) Gestion de l'utilisation et du contexte
Une fois que plusieurs modèles sont impliqués, la comptabilité de l'utilisation cesse d'être uniforme.
Les sources courantes de code de liaison incluent :
- calcul et troncature de la fenêtre contextuelle
- protections « safe max output » (sortie maximale sûre)
- champs d'utilisation incohérents ou manquants
Le dépassement de contexte provoque souvent des tentatives répétées, des sorties partielles et des dépenses inattendues — pas seulement des erreurs.
2) Fiabilité et normalisation des échecs
Les différentes API échouent de manières fondamentalement différentes :
- erreurs structurées de l'API vs échecs au niveau du transport
- limitation (throttling) vs délais d'attente silencieux
- streaming partiel vs déconnexions brutales
Cela transforme le « ajoutez simplement des nouvelles tentatives » en un arbre de décision croissant.
# Exemple illustratif : normalisation des échecs agnostique au fournisseur
def should_retry(err) -> bool:
if getattr(err, "status", None) in (408, 429, 500, 502, 503, 504):
return True
if "timeout" in str(err).lower() or "connection" in str(err).lower():
return True
return FalseCe code maintient les systèmes en vie — mais n'ajoute rien à la différenciation du produit.
3) Appel d'outils et sorties structurées
Dès que vous comptez sur des outils ou des sorties JSON strictes, vous intégrez un protocole, pas une API de chat.
Même les API qui acceptent des formes de requête similaires peuvent différer dans :
- où les appels d'outils apparaissent dans les réponses
- comment les arguments sont encodés
- avec quelle rigueur la sortie structurée est appliquée
C'est une conséquence directe de la fragmentation de l'API LLM.
Test de l'odeur du Glue Code
Vous payez une taxe d'intégration si :
- les invites bifurquent par fournisseur
- les analyseurs de streaming diffèrent par modèle
- les adaptateurs se multiplient avec le temps
- l'observabilité est centrée sur le fournisseur plutôt que sur la fonctionnalité
Coût caché n°2 — Eval Debt : Le coût de l'incertitude
La dette d'évaluation s'accumule lorsque les équipes déploient des modèles sans évaluation automatisée liée aux flux de travail réels.
Le résultat est prévisible :
- les migrations semblent risquées
- les modèles moins chers ou plus rapides restent inutilisés
- les équipes s'en tiennent aux valeurs par défaut coûteuses
- le ROI de l'IA diminue avec le temps
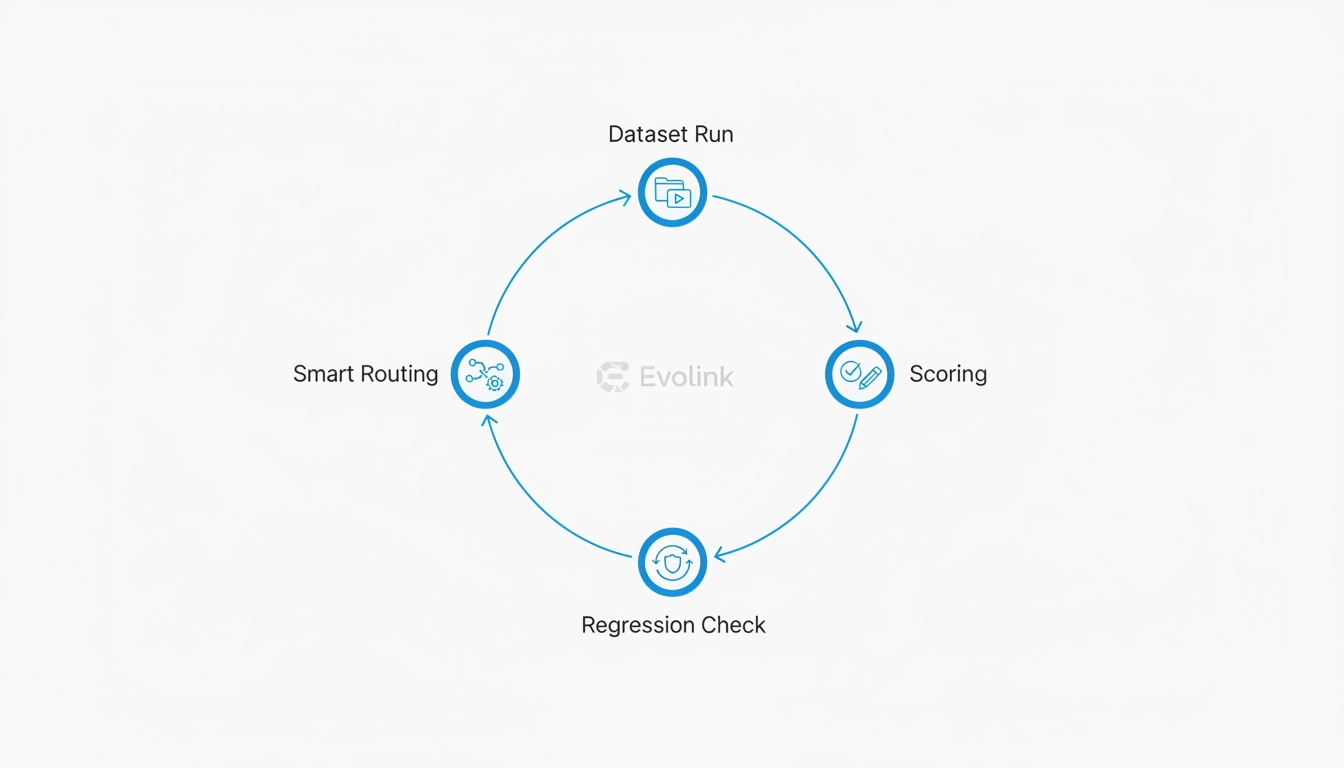
La boucle d'évaluation minimale viable (MVEL)
Vous n'avez pas besoin d'une plateforme MLOps complète pour réduire la dette d'évaluation.
Vous avez besoin d'une boucle qui répond à une question :
Si nous changeons de modèle, les utilisateurs le remarqueront-ils ?
Une base pratique que de nombreuses équipes peuvent mettre en œuvre en 1 à 2 jours :
1) Petits ensembles de données versionnés (50–300 cas)
Utilisez de vrais exemples de production :
- flux d'utilisateurs courants
- cas limites
- échecs historiques
eval/
├── datasets/
│ ├── v1_core.jsonl
│ ├── v1_edges.jsonl
│ └── v1_failures.jsonl
2) Exécuteur de lots répétable
Un script qui :
- exécute le même ensemble de données sur plusieurs modèles
- enregistre les sorties, la latence et le coût
- s'exécute localement ou en CI
3) Notation légère (axée sur la régression)
Au minimum, suivez :
- la validité du format
- la présence des champs requis
- les seuils de latence et de coût
4) Configuration d'évaluation simple
dataset: datasets/v1_core.jsonl
model_targets:
- primary
- candidate
metrics:
- format_validity
- required_fields
thresholds:
format_validity: 0.98
latency_p95_ms: 1200
report:
output: reports/diff.htmlCette structure seule réduit considérablement le risque de migration.
Coût caché n°3 — Prompt Drift : La migration qui ne finit jamais
L'idée fausse la plus courante en ingénierie LLM est :
« Nous changerons simplement l'ID du modèle plus tard. »
En pratique, les invites dérivent parce que les modèles diffèrent dans :
- la discipline de formatage
- le comportement d'utilisation des outils
- les seuils de refus
- le style de suivi des instructions
Un modèle d'échec courant (agnostique au fournisseur)
- L'invite nécessite une sortie JSON stricte
- Le modèle A se conforme systématiquement
- Le modèle B ajoute une courte explication ou une phrase de refus
- L'analyse en aval échoue
- Les ingénieurs corrigent les invites, les analyseurs ou les deux
L'iceberg du TCO des LLM : D'où viennent réellement les coûts
- Coût visible : Tarification des jetons
- Coûts cachés :
- Maintenance du code de liaison
- Remédiation de la dérive des invites
- Infrastructure d'évaluation
- Débogage, nouvelles tentatives et retours en arrière
Note sur les systèmes multimodaux (Image et Vidéo)
Bien que cet article se concentre sur l'intégration des LLM, le même cadre de TCO s'applique encore plus fortement aux systèmes multimodaux tels que la génération d'images et de vidéos.
Une fois que vous allez au-delà du texte, les frais généraux d'ingénierie s'étendent pour inclure l'orchestration asynchrone des tâches, les webhooks ou le polling, le stockage temporaire des actifs, les coûts de bande passante, la gestion des délais d'attente et l'évaluation de la qualité pour les sorties non déterministes. En pratique, ces facteurs l'emportent souvent sur la tarification à l'unité — que l'unité soit des jetons, des images ou des secondes de vidéo.
C'est pourquoi les équipes qui créent des flux de travail d'images ou de vidéos de qualité production subissent souvent des coûts de code de liaison et d'évaluation plus élevés que les systèmes purement textuels, même lorsque le prix du modèle semble moins cher sur le papier.
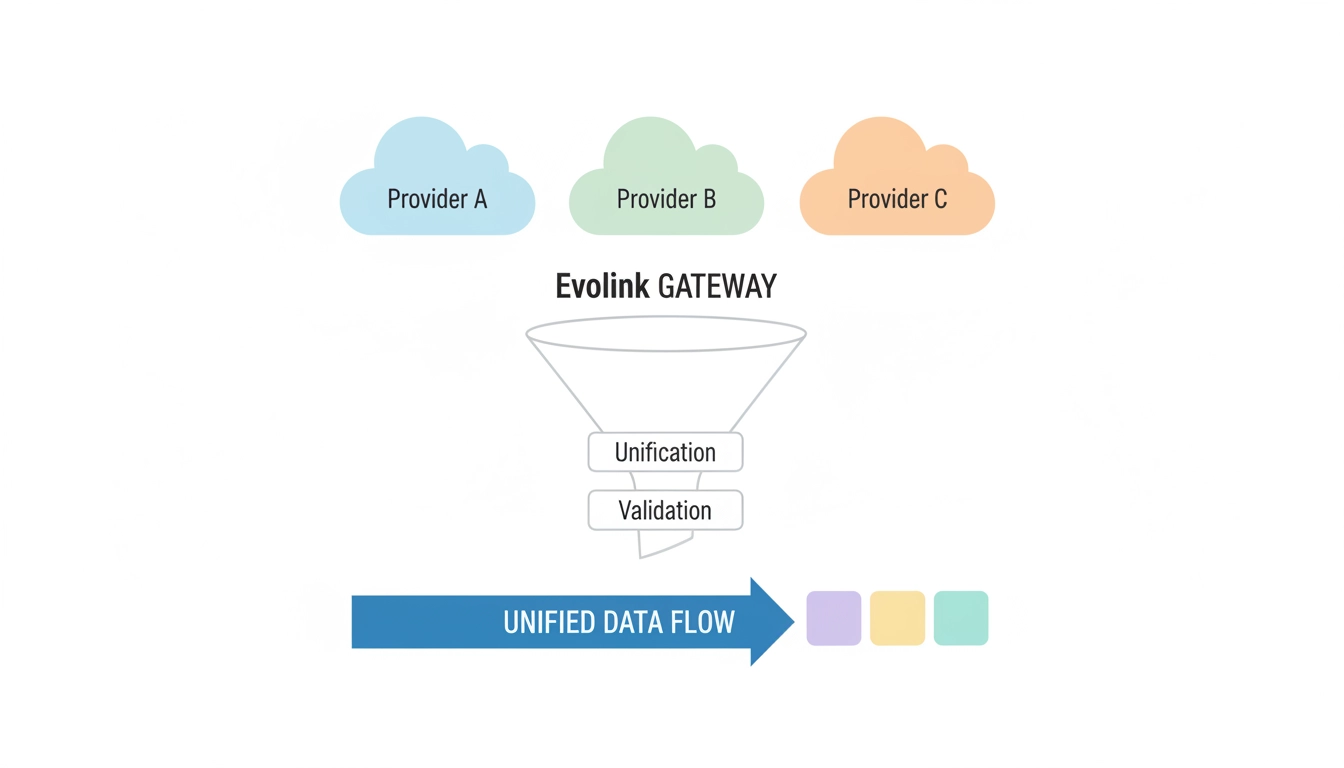
Intégration directe vs Passerelle normalisée
| Domaine de coût | Intégration directe | Passerelle normalisée |
|---|---|---|
| Coût des jetons | Faible–variable | Faible–variable |
| Effort d'intégration | Élevé | Plus faible |
| Maintenance | Continue | Centralisée |
| Vitesse de migration | Lente | Plus rapide |
| Observabilité | Fragmentée | Unifiée |
| Frais généraux d'ingénierie | Répétés | Consolidés |
À ce stade, la vraie décision n'est pas quel modèle utiliser — c'est où vous voulez que cette complexité vive.
Les équipes de premier plan déplacent la fragmentation, le routage et l'observabilité hors du code de l'application et vers une couche de passerelle dédiée.
Ce changement architectural est exactement la raison pour laquelle Evolink.ai existe.
FAQ (Optimisé pour la recherche)
Comment calculez-vous les coûts cachés de l'intégration LLM ?
En comptabilisant le temps d'ingénierie consacré à l'intégration, à l'évaluation, à la maintenance des invites, aux correctifs de fiabilité et aux migrations — pas seulement aux dépenses en jetons.
Quels sont les frais généraux d'ingénierie des stratégies multi-LLM ?
Ils comprennent le code de liaison, la gestion de la dérive des invites, l'infrastructure d'évaluation et l'observabilité inter-fournisseurs.
Qu'est-ce que la dette d'évaluation dans les systèmes LLM ?
La dette d'évaluation est le risque accumulé causé par le déploiement de modèles sans évaluation automatisée, rendant les changements futurs plus lents et plus coûteux.
Comment une passerelle LLM améliore-t-elle le ROI de l'IA ?
En centralisant la normalisation, le routage et l'observabilité, permettant aux équipes d'optimiser ou de changer de modèle sans réécrire le code d'intégration au niveau des fonctionnalités.


