
LLM API が標準化されていない理由

LLM API の断片化問題 (そして「OpenAI 互換性」だけでは不十分な理由)
LLM API が標準化されていない理由を探しているなら、おそらくすでにその苦しみを経験しているでしょう。
いわゆる「OpenAI 互換」API が急速に台頭しているにもかかわらず、現実世界の LLM 統合は、特に単純なテキスト生成を超えた場合には、微妙だが高価な方法で依然として中断されます。
このガイドでは次について説明します。
- LLM API 断片化問題の実際の内容
- OpenAI 互換 API が本番環境では十分ではない理由
- そして、2026 年のチームは絶え間ないモデルの変更を乗り越えるシステムをどのように設計するか
TL;DR (長すぎて読めませんでした)
- プロバイダーは互換性ではなく、さまざまな機能を最適化するため、LLM API は標準化されていません。
- 「OpenAI 互換性」は通常、動作互換性ではなく、リクエスト形状互換性を意味します。
- 断片化は、ツール呼び出し、推論トークン アカウンティング、ストリーミング、およびエラー処理で最も明確に現れます。
- 標準を待つ代わりに、チームは専用ゲートウェイ層の背後で API の動作を正規化します。
LLM API の断片化問題とは何ですか?
LLM API の断片化は、異なる言語モデルのプロバイダーが、見た目は似ていても実際のワークロードでは異なる動作をする API を公開するときに発生します。
API が以下を共有する場合でも:
- 同様のエンドポイント
- 同様の JSON リクエスト スキーマ
- 類似したパラメータ名
多くの場合、次の点で分岐します。
- ツール呼び出しセマンティクス
- 推論/思考トークンアカウンティング
- ストリーミング動作
- エラーコードと再試行信号
- 構造化された出力の保証
時間の経過とともに、アプリケーション ロジックはプロバイダー固有の例外でいっぱいになります。
LLM API が標準化されていない理由
1. プロバイダーはさまざまなプリミティブに合わせて最適化します
最新の LLM は、もはや単純なテキスト入力/テキスト出力システムではありません。
異なるプロバイダーは異なるプリミティブを優先します。
- 推論の深さと遅延
- ロングコンテキストの取得とスループットの比較
- ネイティブ マルチモダリティ (画像、ビデオ、オーディオ)
- 安全性とポリシーの施行
単一の厳格な標準では、次のいずれかになります。
- 高度な機能を非表示にする
- または最小公倍数までのイノベーションが遅い
どちらの結果も、競争の激しい市場では現実的ではありません。
2. 「OpenAI 互換」は Happy Path のみをカバーします
ほとんどの「OpenAI 互換」API は、基本的なスモーク テストに合格するように設計されています。
client.chat.completions.create(
model="model-name",
messages=[{"role": "user", "content": "Hello"}]
)これはデモでは機能しますが、実稼働システムはこれ以上のものに依存します。
2026 年に「OpenAI 互換」では不十分な理由
本当の破損は、構文だけでなく動作に依存するときに現れます。
🔽 表: 「OpenAI 互換」API が本番環境で使用できなくなる理由
| 寸法 | 「OpenAI 互換」が約束するもの | 本番環境でよく起こること |
|---|---|---|
| リクエストの形状 | 類似の JSON スキーマ (メッセージ、モデル、ツール) | エッジパラメータはサイレントに無視または再解釈されます |
| ツール呼び出し | 互換性のある関数定義 | ツール呼び出しが異なる場所または形状で返される |
| ツールの引数 | 確実に解析できる JSON 文字列 | フラット化、文字列化、または部分的に削除された引数 |
| 推論トークン | 透明性のある使用状況レポート | 一貫性のないトークン アカウンティングと請求セマンティクス |
| 構造化された出力 | 有効な JSON 応答 | スキーマの保証を破る「ベストエフォート型」JSON |
| ストリーミング | 安定したデルタチャンク | 一貫性のないチャンク順序または終了シグナルの欠落 |
| エラー処理 | レート制限と再試行信号をクリア | 500 エラー、あいまいな失敗、またはサイレント タイムアウト |
| 移行 | 簡単なプロバイダー切り替え | 即時の書き換えとグルーコードの急増 |
これらの違いがデモに現れることはほとんどありません。
これらは、実際の負荷、複雑なツールの使用、またはコスト重視の運用システムの場合にのみ表面化します。
例 1: ツール呼び出しは似ていますが、セマンティクスが異なります
OpenAI スタイルの期待値(簡略化):
{
"tool_calls": [{
"id": "call_1",
"type": "function",
"function": {
"name": "search",
"arguments": "{\"query\":\"LLM API fragmentation\",\"filters\":{\"year\":2026}}"
}
}]
}一般的な「互換」の現実:
{
"tool_call": {
"name": "search",
"arguments": "{\"query\":\"LLM API fragmentation\"}"
}
}両方の応答は「成功」する可能性があります。 アプリケーションがネストされた引数、ツール呼び出しの配列、または安定した応答パスに依存している場合、それらは動作的に互換性がありません。
例 2: 推論トークン — 2026 年の問題点
推論に焦点を当てたモデルでは、追加の推論/思考トークンが導入されます。
「OpenAI 互換」API を使用しても、次の場合に断片化が発生します。
-
トークンアカウンティング (推論トークンのカウント方法と価格設定方法)
-
使用状況レポート (推論トークンが表示される場所)
-
コントロールノブ (推論作業のための異なる名前とセマンティクス)
-
可観測性 (プロバイダー間でコストを比較するのが難しい) 結果:
-
コストダッシュボードのドリフト
-
評価ベースラインが崩れる
-
プロバイダー間の最適化の信頼性が低くなります 推論行動は類似しているかもしれませんが、推論会計が類似していることはほとんどありません。
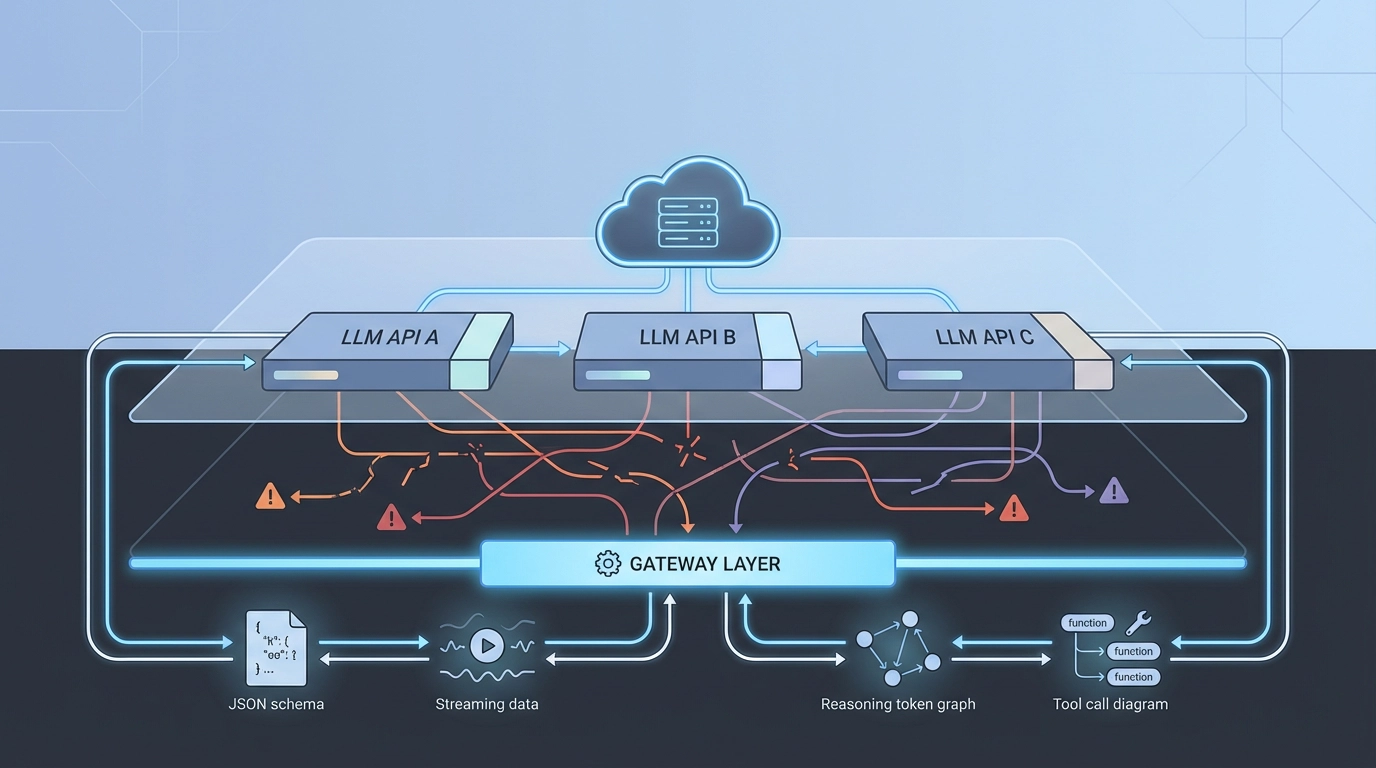
LLM API 断片化の隠れたコスト
1. グルーコードは静かに蓄積します
def get_reasoning_usage(resp: dict) -> int | None:
details = resp.get("usage", {}).get("output_tokens_details", {})
if "reasoning_tokens" in details:
return details["reasoning_tokens"]
if "reasoning_tokens" in resp.get("usage", {}):
return resp["usage"]["reasoning_tokens"]
return Noneこのパターンは、ツール、再試行、ストリーミング、使用状況の追跡にわたって繰り返されます。
グルーコードには機能が付属しません。 破損を防ぐだけです。
2. LLM プロバイダー間の移行は予想より難しい
チームが期待していること:
「後で機種変更するだけです。」
実際に何が起こるか:
-
プロンプトドリフト
-
互換性のないツール スキーマ
-
異なるレート制限セマンティクス
-
使用状況メトリクスの不一致
3. マルチモーダル API による断片化の増加
テキストを超えて:
-
ビデオ API は長さの単位と安全ルールが異なります
-
画像 API はマスク形式と参照が異なります
現在、共有型複合契約は存在しません。
チームが独自のラッパーを構築しようとする (そして苦労する) 理由
最初は、カスタム抽象化が合理的であるように感じられます。
時間が経つと、次のようになります。
-
2番目の製品
-
メンテナンスの負担
-
実験のボトルネック
多くのチームが独立して同じ結論を再発見します。
実践的な標準化チェックリスト
「互換性のある」API または内部ラッパーを信頼する前に、次のことを確認してください。
- ツール呼び出しは動作互換ですか、それともスキーマのみですか?
-
推論トークンは一貫して公開されていますか?
-
プロバイダー間で使用状況を比較できますか?
- エラーコードは正規化されていますか?
- 負荷がかかってもストリーミングは安定していますか?
- プロンプトを書き換えずにプロバイダーを切り替えることはできますか?
- トラフィックを動的に再ルーティングできますか?
標準化から正規化へ
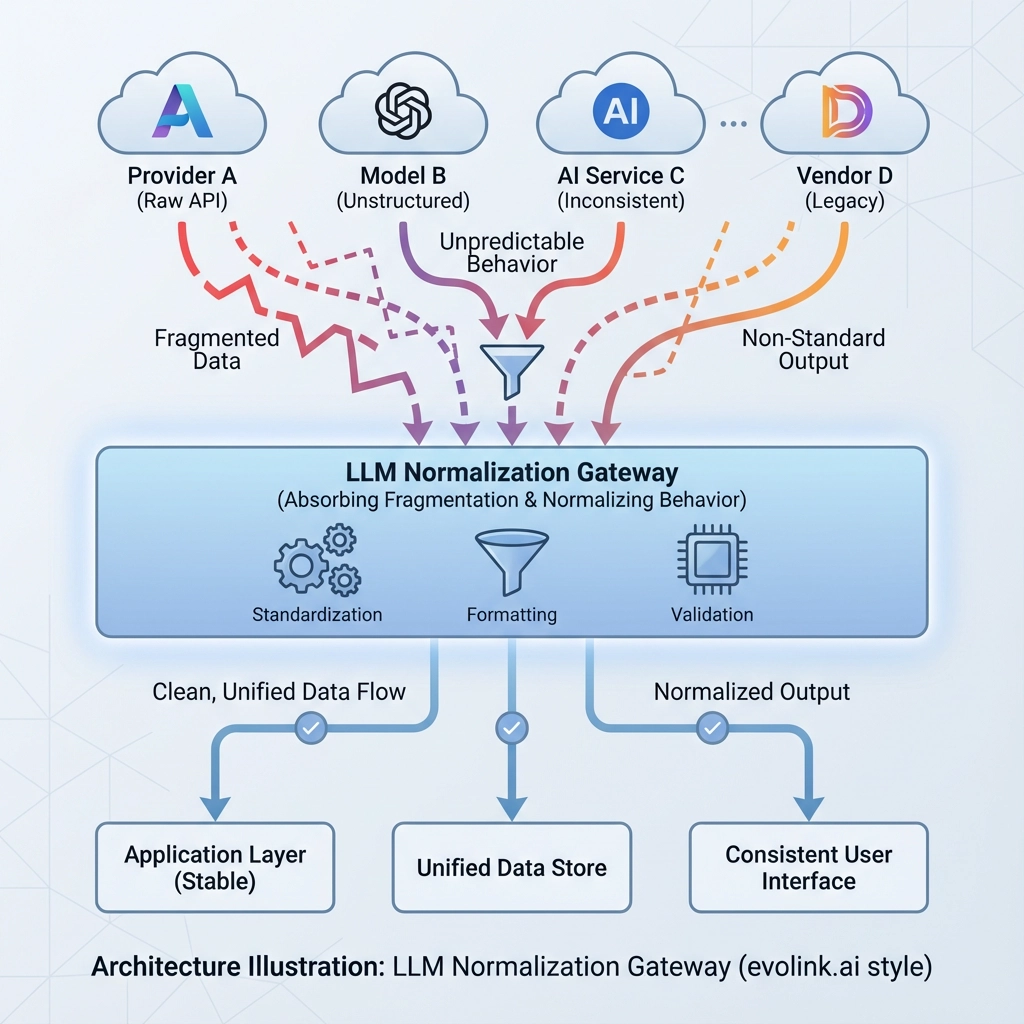

LLM API は、エコシステムの動きが速すぎて収束できないため、標準化されていません。 成熟したチームは待つのではなく、アーキテクチャを進化させます。
-
ビジネス ロジックはモデルに依存しない
-
API の癖は正規化されたゲートウェイ層によって吸収されます
最終的なポイント
LLM API は標準化されていません。また、すぐには標準化されません。
「OpenAI 互換」API はオンボーディングの手間を軽減しますが、本番環境のリスクが排除されるわけではありません。
断片化を考慮して設計されたシステムは長持ちします。
よくある質問 (AI の概要と注目のスニペットについて)
LLM API が標準化されていないのはなぜですか?
LLM API は、プロバイダーが推論の深さ、遅延、マルチモーダリティ、安全性などのさまざまな機能に合わせて最適化しているため、標準化されていません。厳格な標準はイノベーションを遅らせたり、高度な機能を隠したりします。
OpenAI 互換 API だけでは十分ではないのはなぜですか?
「-compatibility」は通常、リクエスト形状の類似性のみを保証します。運用環境では、ツール呼び出し、推論トークン アカウンティング、ストリーミング、およびエラー処理の違いにより、互換性が失われます。
LLM API の断片化問題とは何ですか?
LLM API の断片化問題とは、見た目が似ている API が実際のワークロードでは異なる動作をすることを指し、開発者はグルー コードを記述する必要があり、移行が複雑になります。
チームは LLM API の断片化にどのように対処しますか?
ほとんどの成熟したチームは、プロバイダーの違いを吸収するゲートウェイ層の背後で API の動作を正規化し、ビジネス ロジックの安定性を維持します。


