
コストの最適化
OpenRouter の代替案 (2026年版):AI API の実効コストを下げるための実践ガイド (LiteLLM, Replicate, fal.ai, WaveSpeedAI, EvoLink)

Jessie
COO
2026年1月22日
更新日 2026年5月13日
20 分
OpenRouter代替のより広範な比較をお探しですか? この記事はコスト最適化に特化しています。プライバシー、可観測性、デプロイメント制御を含むルーティング機能の全体比較は、2026年のベストOpenRouter代替をご覧ください。OpenRouterエラーのトラブルシューティングについては、OpenRouter 429「Provider Returned Error」の修正をご覧ください。
もしあなたが OpenRouter の代替案を探しているなら、その真の意図は通常「新しいルーターが欲しい」ということではないはずです。
おそらく、次のようなことではないでしょうか。
OpenRouter は便利だが、利用が増えるにつれて高価に感じ始めている。移行をコードの書き直しにすることなく、ユニットエコノミクスを実際に改善できる切り替え先が欲しい。
この記事では、チームが一般的に検討する5つの選択肢を比較します。
- LiteLLM (セルフホスト型 LLM ゲートウェイ)
- Replicate (計算時間ベースのモデル実行)
- fal.ai (生成メディアプラットフォーム)
- WaveSpeedAI (ビジュアル生成ワークフロー)
- EvoLink.ai (スマートルーティングを備えたチャット/画像/動画の統合ゲートウェイ)
また、文脈を把握するための基準として OpenRouter も参照します。
TL;DR: どの代替案を最初に評価すべきか?
- セルフホスト型のガバナンス + 最大限のコントロールが欲しい場合 → LiteLLM
- ワークロードが計算/ジョブ形式で、公開されているハードウェア価格を希望する場合 → Replicate
- 主な支出が画像/動画生成である場合 → fal.ai または WaveSpeedAI
- コストの問題がチャネルによる価格差に起因しており、チャット + 画像 + 動画を一つの API に統合したい場合 → EvoLink.ai
このガイドを読み進める前に EvoLink を試してみたい方はこちら:
→ EvoLink API キーを取得する
EvoLink Smart Router を見る
本番環境で「OpenRouter が高く感じる」ことの真の意味
ほとんどのチームは、初期のプロトタイピング段階ではコストのプレッシャーを感じません。コストが苦痛になるのは、次のような時です。
- 実際のユーザーがいる(そして利用状況が予測不能である)
- リトライが発生し始める(429 エラーやタイムアウトの頻発)
- マルチモーダル機能(テキスト + 画像 + 動画)を導入した
- 売上総利益率やユニットエコノミクスの最適化を始めた
その時点で、単なる「トークン単価」ではなく、**「成果あたりの実効コスト (effective cost per outcome)」**が重要になります。
- サポート解決あたりのコスト
- エージェントワークフロー完了あたりのコスト
- 画像アセットあたりのコスト(リトライや失敗を含む)
- 短尺動画あたりのコスト(失敗やキューの無駄を含む)
切り替え前の 15 分チェックリスト
| ステップ | アクション | アウトプット |
|---|---|---|
| 1 | 一つの KPI を選ぶ:成果あたりの実効コスト | チームが一致団結できる一つの数字 |
| 2 | リトライ率、エラー率、p95 レイテンシを測定する | 「無駄」と UX への影響の基準 |
| 3 | ワークロードを分類する:テキストのみ vs マルチモーダル | 「LLM ルーター」だけで十分かを判断 |
| 4 | 許容度を決める:マネージド vs セルフホスト | LiteLLM かマネージドツールの選択を支援 |
| 5 | リリースの計画を立てる:シャドウ → カナリア → 段階的拡大 | リスクの高い一斉移行を防ぐ |
「実効コストスタック」(お金が消えていく場所)
| レイヤー | コストドライバー | 具体的な事象 | 測定項目 |
|---|---|---|---|
| L1 | 使用コスト | トークン / 成果物あたり / 秒あたり | セッション/ジョブ/アセットあたりの単価 |
| L2 | チャネルによる価格差 | 同じ能力なのに、チャネルによって実効価格が異なる | ルートごとの価格分布 |
| L3 | 失敗による無駄 | リトライ、タイムアウト、429 の多発 | リトライ率、1000 回あたりのエラー数 |
| L4 | エンジニアリングのオーバーヘッド | 多数の SDK、多数の請求アカウント、コードの乖離 | 統合にかかるエンジニアの時間 |
| L5 | モダリティの分散 | 複数プラットフォームにまたがるテキスト+画像+動画 | クリティカルパス上のベンダー数 |
OpenRouter が高く感じる場合、多くは L2~L5 の問題です。
表 1 — プラットフォーム適合マトリックス(「OpenRouter が高い」意図に対応)
| プラットフォーム | OpenRouter の有力な代替案となる場合 | 典型的な課金形式(概要) | 移行の摩擦 | 検討すべきトレードオフ |
|---|---|---|---|---|
| LiteLLM | セルフホストによる管理(予算、ルーティング、ガバナンス)を希望し、インフラを運用できる場合 | OSS ゲートウェイ/プロキシ + 自社インフラコスト | 中〜高 | 運用(可用性、アップグレード、プロバイダーの変更、監視)を自社で担う |
| Replicate | ワークロードが計算/ジョブ形式で、明確なハードウェア価格を希望する場合 | 計算時間 / ハードウェア秒数(モデルにより異なる) | 中 | 実行時間の変動により予測可能性が下がる可能性がある。実際の入力でテストが必要。 |
| fal.ai | メディア重視(画像/動画/音声)で、幅広いモデルギャラリーとスケーラビリティを求める場合 | 従量課金制の生成メディアプラットフォーム | 中 | 実効コストは選択したモデルとワークフロー設計に大きく依存する |
| WaveSpeedAI | ビジュアル生成ワークフロー(画像/動画)、メディアファーストで構築している場合 | 従量課金制のメディアプラットフォーム | 中 | 多くの場合、LLM ルーターを置き換えるのではなく補完するものとして機能する |
| EvoLink.ai | チャネル間のスマートルーティングで実効コストを下げ、チャット+画像+動画を統合したい場合 | 従量課金制ゲートウェイ。ルーティング主導のコスト最適化 | 低〜中 | 厳格なセルフホストや特定のコンプライアンス要件がある場合は適合性を確認 |
| OpenRouter (基準) | 一つの API で LLM モデルを迅速に切り替えたい場合 | トークン形式の LLM アクセス | N/A | 実効コスト(無駄+オーバーヘッド+分散)が上昇すると高く感じることがある |
ワークロードの類型:プロダクトに合わせて代替案を選ぶ
| ワークロードの類型 | 最適化の目標 | 最適な選択肢 | 理由 |
|---|---|---|---|
| SaaS チャット / サポート | セッションあたりコスト、p95 レイテンシ、無駄なリトライ | LiteLLM, EvoLink | LiteLLM はガバナンスのため、EvoLink はルーティングによる経済性と統合スタックのため |
| コーディングツール / DevTools | バースト処理、組織内予算/キー管理、モデルの俊敏性 | LiteLLM, EvoLink | LiteLLM はプラットフォーム管理のため、EvoLink は低摩擦かつコスト意識の高いルーティングのため |
| 事務/マーケティング画像 | アセットあたりのコスト、スループット、非同期処理 | fal.ai, WaveSpeedAI, EvoLink | fal/WaveSpeed はメディアファースト。EvoLink は複数モダリティを一つのインターフェース。 |
| 短尺動画生成 | 動画あたりのコスト、キューの挙動、失敗の無駄 | fal.ai, WaveSpeedAI, EvoLink | メディア向けプラットフォームが専門。EvoLink は統合マルチモーダルとルーティング経済性。 |
| 研究 / 実験 | 網羅性、高速プロトタイピング、インフラ価格の透明性 | Replicate, OpenRouter | Replicate は計算ジョブとの相性が良い。OpenRouter は LLM の試行錯誤に便利。 |
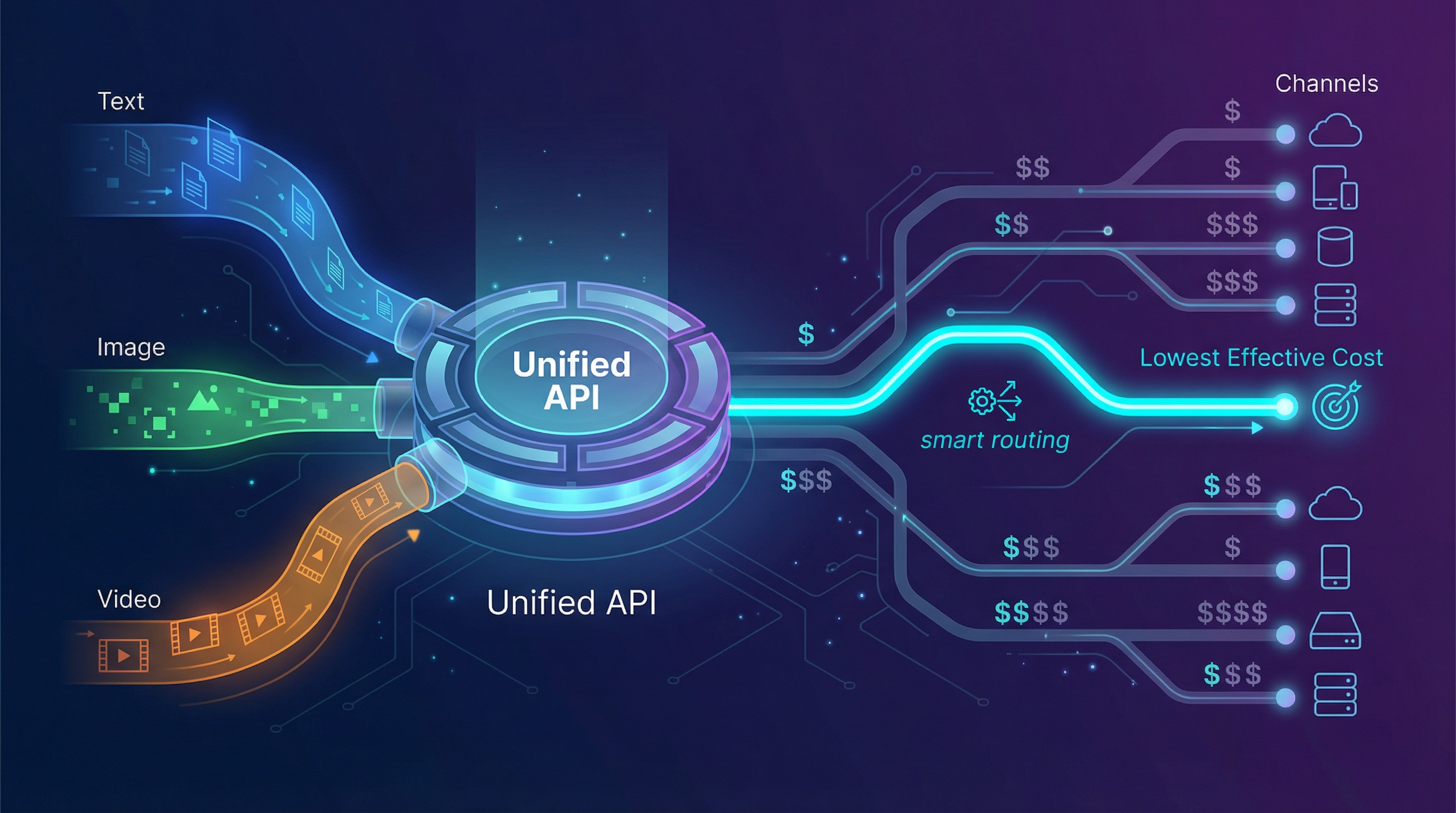
代替案の評価:何をどのように評価するか
1) LiteLLM — セルフホスト型ゲートウェイコントロール (OpenAI 形式)
LiteLLM は、チームが以下を求める際に一般的に検討されます。
- プロバイダー間での共通の OpenAI 形式インターフェース
- 予算、レート制限、ガバナンスの一元管理
- セルフホスト / オンプレミスのオプション
LiteLLM が選ばれる理由
- 自身の環境内でポリシーレイヤー(予算、認証、ルーティング規則)を所有したい。
- ベンダー管理のオーバーヘッドを、エンジニアリング時間と運用の所有権にトレードオフしても構わない。
注意点
- 「ルーター」自体が自社の責任になります:
- 高可用性、スケーリング、インシデント対応
- プロバイダー側の変更への対応(API 仕様変更など)
- ログ/メトリクスパイプラインの構築
- 無駄を避けるため、リトライやフォールバックを能動的に管理する必要があります。
過度なコミットをせずに LiteLLM をテストする方法
- ステージング環境から開始する
- シャドウトラフィック(ユーザーに影響を与えず、リクエストを複製して送信)を使用する
- 早段階で利用制限を設定する
- 出力結果の同等性を確認した後にのみカナリアリリースに移行する
2) Replicate — 明確なハードウェア価格に基づいたモデル実行
Replicate は、ワークロードがチャット形式よりも「ジョブ(タスク)」に近い場合に検討されます。
- モデルの予測を計算タスクとして実行する
- 透明性のあるハードウェア価格帯 (GPU $単価/秒) を希望する
Replicate が選ばれる理由
- 実験や計算型のワークロードとの相性が非常に良い
- ハードウェア価格が明確なため、実行時間が安定していれば予測が立てやすい
注意点
- 実行時間のばらつきがそのままコストのばらつきになります。
- プロダクション級の信頼性は、モデルやワークロードによって異なる場合があります。
Replicate のテスト方法
- 実際の入力データでベンチマークを行う
- 実行時間の分布 (p50/p95/p99) を記録する
- 秒単価だけでなく、成果物あたりのコストに換算する
3) fal.ai — 生成メディアプラットフォーム (幅広いカタログ + スケーラビリティ)
fal.ai は、メディア重視のプロダクトでよく選ばれます。
- 画像/動画/音声の生成
- 幅広いモデルライブラリ
- パフォーマンスとスケーリングに特化したポジショニング
fal.ai が選ばれる理由
- 一つのプラットフォームで幅広いメディア生成をカバーしたい。
- メディア API の速度と拡張性を重視する。
注意点
- 実効コストは選択するモデルやワークフロー設計に大きく依存します。
- 非同期(Webhook)設計の選択が、失敗による無駄なコストに大きく影響することがあります。
fal.ai のテスト方法
- プロダクトに合った 2~3 個のエンドポイント/モデルを選ぶ
- 以下の項目をテストする:
- 単発実行のレイテンシ
- バッチ処理のスループット
- 失敗による無駄なコストとアセットあたりのコストを追跡する
4) WaveSpeedAI — メディアファーストなビジュアルワークフロー
WaveSpeedAI は、画像/動画生成ワークフローにおいて一般的に検討されます。
WaveSpeedAI が選ばれる理由
- ビジュアル生成機能に特化したメディアファーストなプラットフォームを求めている。
- プロダクトが「チャットアシスタント」よりも「アセット生成」に近い。
注意点
- LLM ルーターを置き換えるというよりは、補完するものとして機能することが多いです。
- 「安さ」はワークフロー構造(非同期ジョブ、リトライなど)に依存します。
WaveSpeedAI のテスト方法
- アセットあたりのコストを測定する
- 生成完了までの時間の分布を測定する
- バッチ負荷がかかった際の安定性を検証する
5) EvoLink.ai — ルーティング経済性と統合マルチモーダル API による実効コスト削減
もし不満が「OpenRouter は高い」ということであれば、重要な問いは 「何が高いのか?」 です。
もし答えが以下のようなものなら:
- チャネル間の価格差によって実効コストが膨らんでいる
- リトライや失敗が無駄を生んでいる
- アプリがマルチモーダル(テキスト + 画像 + 動画)になりつつある
- 5つの異なるベンダー統合を管理したくない
…その場合、EvoLink が有力な候補になります。
EvoLink が提供するもの:
- チャット、画像、動画をカバーする一つの API
- 40 以上のモデル
- コスト削減のために設計されたスマートルーティング(「最大 70% 削減」を謳っています)
- 99.9% の稼働率と自動フェイルオーバーを含む信頼性
EvoLink の評価方法(経理とエンジニアの両方が信頼できるように)
- 代表的な一つのワークフローを選ぶ(単純なプロンプトではなく)。
- 1
5% のカナリアリリースを 2448 時間実施する。 - 成果あたりの実効コスト、リトライ率、p95 レイテンシを比較する。
- 切り戻し(ロールバック)手段を確保しておく。
ここから始める
- メインのアクション:API キーを取得する
- モデルカタログ:EvoLink モデル
- 実装:EvoLink API ドキュメント
- エンジニアリングガイド:GPT Image 1.5 本番活用ガイド
判断に迷ったら(考えすぎないためのシンプルなフロー)
-
セルフホスト / オンプレミス / 深い内部ガバナンスが必要か? → LiteLLM から検討する。
-
ワークロードの大部分がメディア生成(画像/動画)か? → fal.ai または WaveSpeedAI から検討する。
-
ワークロードが計算/ジョブ形式で、実行経済性を重視するか? → Replicate から検討する。
-
チャット/画像/動画のインターフェースを統合し、実効コスト(価格差と無駄)が課題か? → EvoLink をテストする:無料で始める
表 2 — 実効コスト削減チェックリスト(どのプラットフォームでも実施すべきこと)
| 問題 | 兆候 | 解決策 |
|---|---|---|
| リトライの嵐 | プロバイダーの一時的な不調時に支出が急増 | リトライ上限の設定 + キューイング + バックオフ |
| 二重課金 | ユーザーの連打による重複呼び出し | べき等性キー (Idempotency Key) + UI での制限 |
| 高価なルートの使いすぎ | 全トラフィックがプレミアムオプションを利用 | ルーティングポリシー + 予算管理 |
| ログコストの肥大化 | すべてを永久に保存している | サンプリング + 保存期間の制限 |
| コスト配分の困難 | 「AI コスト」が一つの予算枠になっている | 機能/チーム/ユーザーごとにリクエストにタグ付け |
移行プレイブック:リスクを抑えた切り替え方法
表 3 — 低リスクなリリース計画 (コピー&ペースト用)
| フェーズ | アクション | 完了の定義 |
|---|---|---|
| 基準測定 | 成果あたりの実効コスト、リトライ率、p95 レイテンシを測定 | コストの内訳を説明できる |
| シャドウ | 新プラットフォームへリクエストを複製(ユーザー影響なし) | 出力が同等であり、致命的な失敗がない |
| カナリア | 実際のトラフィックの 1~5% をルーティング | KPI が改善または維持され、切り戻しが機能する |
| 拡大 | 10% → 25% → 50% → 100% | ピーク負荷時でも安定している |
| 最適化 | ルーティングと予算を微調整 | ボリューム増加に伴いコスト曲線が改善する |
「安いツールによる高くつく結果」を防ぐためのガードレール
- ユーザーのアクションに対するべき等性の確保
- リトライ上限 + キューイング
- キー/チーム/プロジェクトごとの予算上限
- 失敗タイプに基づいたフォールバック(タイムアウト/429/5xx)
- ログのサンプリング(すべてを永久に記録しない)
チームへの共有用:実効コスト評価ワークシート
| メトリクス | 基準 (OpenRouter) | 候補 A | 候補 B |
|---|---|---|---|
| 成果あたりの実効コスト | |||
| リトライ率 (%) | |||
| エラー率 (1000回あたり) | |||
| p95 レイテンシ (ms) | |||
| クリティカルパス上のベンダー数 (#) | |||
| 移行工数 (人日) |
推奨事項のまとめ
- セルフホストでのガバナンス + 最大限のコントロールが必要 → LiteLLM
- ワークロードが計算ジョブ形式で、明確な分配価格を希望 → Replicate
- 主に画像/動画生成を行っている → fal.ai または WaveSpeedAI
- ルーティングによる経済性で実効コストを下げ、チャット/画像/動画を統合したい → EvoLink.ai 試してみる:EvoLink API キーを取得する
次のステップ
- 最初の候補を選ぶ(ワークロード類型に基づく)
- 1
5% のカナリアリリースを 2448 時間実施する - 比較する:成果あたりの実効コスト + リトライ率 + p95 レイテンシ
- ロールバックが実証された後にのみトラフィックを拡大する
- EvoLink をテストする場合:
注記
- 料金、カタログ、機能セットは頻繁に変更されます。予算の決定前に各ベンダーの公式サイトで詳細を確認してください。
- この記事は検索意図のために OpenRouter に言及していますが、OpenRouter と提携しているものではありません。


