
Pourquoi les applications IA multi-modèles ont besoin d'une couche API unifiée
En bref
Les applications IA multi-modèles deviennent la norme. Un produit peut utiliser un modèle pour le chat, un autre pour l'assistance au code, un troisième pour l'extraction structurée, et des modèles image ou vidéo distincts pour les workflows média.
La difficulté ne se limite pas à appeler davantage d'API. La vraie difficulté consiste à garder le contrôle sur le choix de modèle, le suivi d'utilisation, la facturation, la politique de coûts, le comportement de fallback et les opérations en production à mesure que la combinaison de modèles évolue.
Une couche API unifiée offre aux équipes un point de contrôle unique entre le code applicatif et les modèles IA supportés. Elle ne rend pas tous les modèles identiques et n'élimine pas la nécessité d'évaluation. Sa valeur est architecturale : elle fournit aux équipes produit et infrastructure un espace stable pour gérer l'accès aux modèles, le changement de modèle, le routage, la visibilité et la politique opérationnelle.
La plupart des équipes n'adoptent pas une API unifiée parce qu'elles veulent moins de endpoints. Elles l'adoptent parce que les applications multi-modèles finissent inévitablement par avoir besoin d'une couche de contrôle.
Dès qu'une application dépend de plusieurs familles de modèles, les questions difficiles passent de « Peut-on appeler ce modèle ? » à « Peut-on piloter le choix de modèle, l'utilisation, les coûts, le fallback et la fiabilité sans réécrire le code produit chaque fois que la pile de modèles change ? »
Les applications multi-modèles deviennent la norme
Les premiers produits IA se limitaient souvent à un seul modèle et un seul fournisseur. C'était raisonnable quand la surface produit était restreinte : un chatbot, un outil de résumé, un assistant support ou un générateur de contenu basique.
Les applications IA modernes sont différentes. Un même produit peut inclure :
- un modèle rapide pour la classification ou la reformulation
- un modèle de raisonnement plus puissant pour les questions complexes
- un modèle de code pour les workflows développeur
- un modèle à contexte long pour l'analyse documentaire
- un modèle image pour la génération ou l'édition d'assets visuels
- un modèle vidéo pour la production créative
- un chemin de fallback lorsqu'un fournisseur est lent, indisponible ou trop coûteux pour une tâche donnée
Ce changement transforme l'architecture. La sélection de modèle n'est plus une décision d'intégration ponctuelle : elle devient une décision opérationnelle qui peut varier selon la fonctionnalité, le niveau d'abonnement utilisateur, le type de charge de travail, la cible de latence et le budget.
Pour les équipes qui construisent des agents, cette pression est encore plus forte. Un workflow agentique peut classifier l'intention, récupérer du contexte, planifier des étapes, appeler des outils, résumer les résultats et générer une réponse finale. Chaque étape n'a pas besoin du même modèle. Si chaque décision de modèle est codée en dur dans le code applicatif, le produit devient plus difficile à faire évoluer.
Le problème ne se résume pas à de multiples API
Il est tentant de formuler le problème ainsi : « nous devons intégrer OpenAI, Anthropic, Google, et peut-être quelques fournisseurs image ou vidéo. » Ce n'est que la partie visible de l'iceberg.
Le problème de fond, c'est la dérive opérationnelle.
Chaque fournisseur peut différer sur :
- l'authentification et la configuration de compte
- les identifiants de modèle
- la forme des requêtes et des réponses
- le comportement de streaming
- les limites de débit et les signaux de retry
- le reporting d'utilisation
- les unités de tarification
- la sémantique des erreurs
- les modalités et paramètres supportés
- la cadence de publication et le calendrier de dépréciation
Même si deux fournisseurs exposent un endpoint compatible OpenAI, les systèmes en production doivent gérer les comportements spécifiques à chaque modèle. La compatibilité OpenAI réduit souvent la friction d'intégration initiale, mais elle ne doit pas être considérée comme un contrat opérationnel complet.
Pour les décisions d'architecture, la question n'est pas seulement « Peut-on envoyer une requête ? ». La meilleure question est :
L'application peut-elle changer de modèle, suivre l'utilisation, contrôler les coûts, gérer les pannes et fonctionner de manière fiable sans éparpiller de la logique spécifique aux fournisseurs dans toute la base de code ?
C'est là qu'une couche API unifiée prend tout son sens.
Erreur fréquente : considérer l'API unifiée comme un simple raccourci d'intégration
Une erreur courante consiste à évaluer une API unifiée uniquement selon le nombre de fournisseurs qu'elle supporte. Cela passe à côté de la question architecturale essentielle.
La vraie question est de savoir si la couche API offre à votre équipe un espace stable pour gérer la sélection de modèle, la visibilité sur l'utilisation, la politique de coûts, le comportement de fallback et les opérations en production.
Si la couche se contente de masquer les URL des fournisseurs sans améliorer le contrôle, la visibilité ou la cohérence opérationnelle, elle réduit le travail d'intégration sans résoudre le problème multi-modèle de fond.
Une couche API unifiée crée un point de contrôle unique
Une couche API unifiée se positionne entre l'application et les fournisseurs de modèles ou les routes de modèles sous-jacents. Le code applicatif communique avec la couche unifiée. La couche prend en charge les préoccupations transversales qui ne devraient pas être dupliquées dans chaque équipe fonctionnelle.
Dans sa version la plus simple, cette couche fournit :
- une URL de base unique
- un schéma d'authentification unique
- un espace centralisé pour choisir les modèles supportés
- une surface unifiée d'utilisation et de facturation
- un point d'entrée pour introduire du routage, du fallback ou des politiques ultérieurement
Dans une version plus mature, elle peut s'intégrer à une couche de livraison IA plus large : l'accès aux modèles, les règles de routage pour les requêtes LLM supportées, la visibilité sur l'utilisation, les contrôles de coûts, la planification de fallback et les opérations en production gravitent autour du même point d'entrée API.
Cela ne signifie pas que tous les modèles deviennent interchangeables. Une couche API unifiée ne doit pas masquer les différences importantes de qualité, de latence, de modalité, de fenêtre de contexte, de comportement d'outils ou de tarification. Une bonne architecture rend ces différences suffisamment visibles pour permettre l'évaluation, tout en empêchant qu'elles se propagent partout dans le code applicatif.
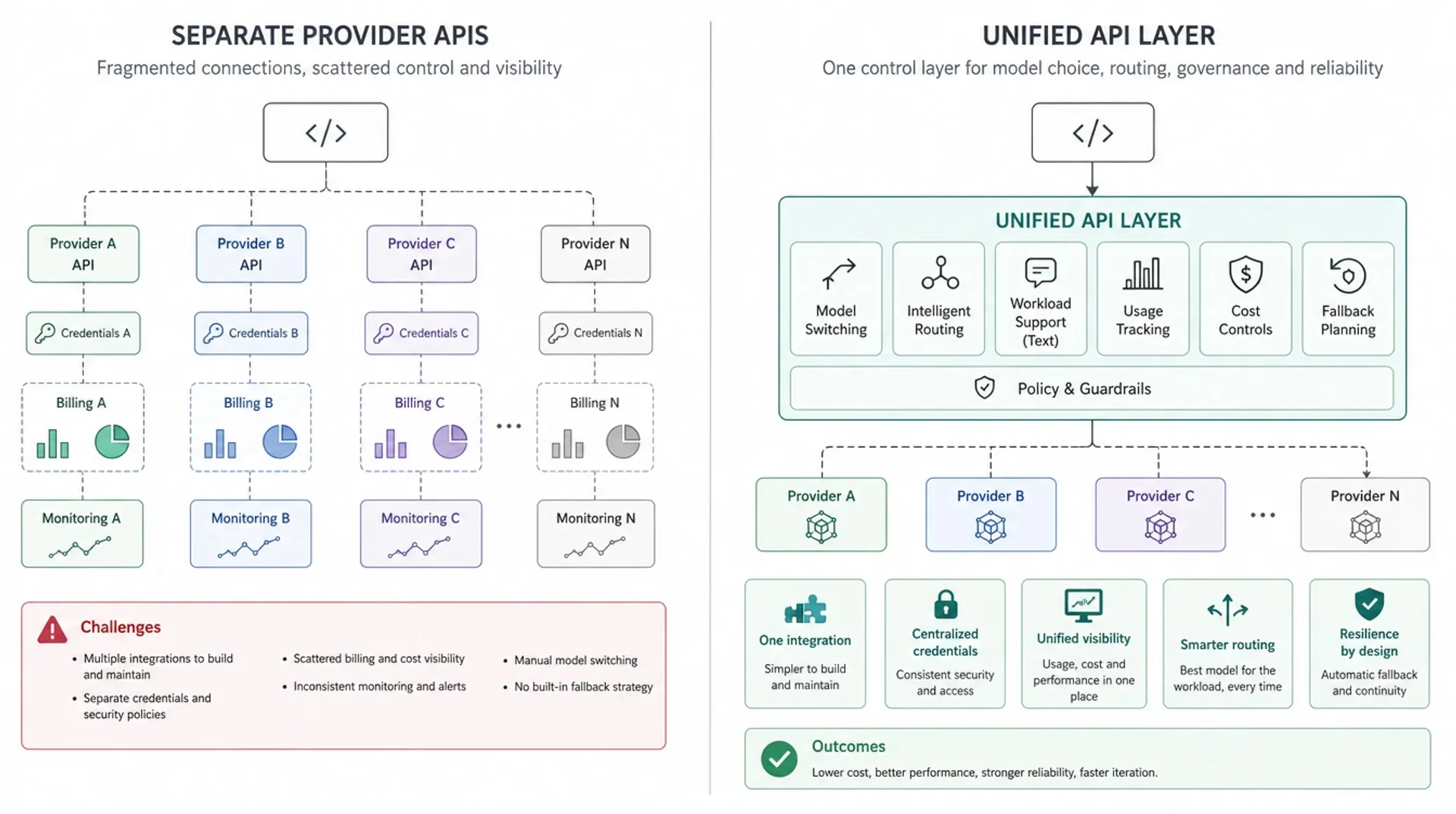
| Dimension | API fournisseurs séparées | Couche API unifiée |
|---|---|---|
| Intégration | Chaque fournisseur nécessite une configuration, des identifiants, un choix de SDK et une maintenance distincts | Une seule surface d'intégration pour les modèles supportés |
| Changement de modèle | Implique souvent des modifications de code, de nouveaux chemins SDK ou des adaptateurs spécifiques | Devient généralement une décision de sélection de modèle ou de route |
| Suivi d'utilisation | Les données d'utilisation sont dispersées entre fournisseurs et logs internes | L'utilisation peut être normalisée dans une surface de reporting unique |
| Contrôle des coûts | Les équipes comparent les dépenses dans différents portails de facturation et unités de tarification | La politique de coûts peut être gérée au plus près de la couche API |
| Fallback | Chaque service peut implémenter sa propre logique de retry ou de secours | La planification de fallback peut être centralisée lorsque c'est pertinent |
| Opérations | Les incidents, les limites et les changements de modèle se propagent dans le code produit | Les contrôles opérationnels sont plus proches de la couche de livraison des modèles |
Ce qu'une couche API unifiée rend possible
Changer de modèle sans réécrire votre application
Le premier bénéfice est évident : le changement de modèle devient moins invasif.
Sans couche unifiée, passer d'un fournisseur ou d'une famille de modèles à un autre peut nécessiter de nouveaux identifiants, des modifications de SDK, un mapping des requêtes, un parsing différent des réponses, des changements dans le suivi d'utilisation et de nouveaux runbooks opérationnels.
Avec une couche API unifiée, l'application peut conserver un contrat d'intégration plus stable tandis que le choix de modèle change derrière ce contrat. Cela ne signifie pas que la qualité des sorties sera identique. Cela signifie que le chemin d'intégration a moins de chances de devenir le point de blocage.
Exemple :
- Un workflow de support démarre avec un modèle équilibré.
- Plus tard, la classification à haut volume migre vers un modèle moins cher ou plus rapide.
- Les cas d'escalade complexes sont redirigés vers un modèle de raisonnement plus puissant.
- L'application n'a pas besoin de reconstruire toute son intégration IA à chaque changement de combinaison de modèles.
La valeur métier n'est pas de « changer de modèle pour le plaisir ». La valeur est de réduire le coût d'adaptation lorsque les modèles, les prix et les besoins de charge de travail évoluent.
Routage en fonction des besoins de la charge de travail
Les applications multi-modèles contiennent souvent des charges de travail LLM variées. Une tâche de formatage courte, une analyse à contexte long et une étape de planification agentique n'ont pas besoin du même profil de modèle.
Une couche API unifiée offre aux équipes un espace naturel pour introduire une logique de routage sur les charges de travail texte supportées :
- diriger les tâches simples vers des modèles à plus faible latence ou moindre coût
- diriger les tâches nécessitant du raisonnement vers des modèles plus puissants
- conserver des modèles fixes pour les workflows benchmarkés ou réglementés
- renvoyer le modèle effectivement sélectionné lorsque le routage est utilisé, afin que les équipes puissent journaliser et évaluer le comportement
Visibilité sur l'utilisation et cohérence de la facturation
Dès qu'une application utilise plusieurs modèles, la visibilité sur l'utilisation devient un enjeu produit et financier, pas seulement un détail technique.
Les équipes doivent pouvoir répondre à ces questions :
- Quelle fonctionnalité utilise quel modèle ?
- Quel segment client génère la dépense ?
- Des modèles coûteux sont-ils utilisés pour des tâches simples ?
- Un changement de modèle a-t-il augmenté la latence, la consommation de tokens ou le taux d'erreur ?
- L'utilisation peut-elle être attribuée par fonctionnalité, équipe, environnement ou clé API ?
Les tableaux de bord séparés de chaque fournisseur rendent ces questions plus difficiles, car chacun reporte l'utilisation différemment. Une couche API unifiée peut créer une vue plus cohérente des requêtes, des tokens, du volume de tâches et des dépenses sur l'ensemble des modèles supportés.
Cette visibilité est le fondement du contrôle des coûts. Vous ne pouvez pas maîtriser l'économie de vos modèles si les données d'utilisation sont fragmentées.
Contrôle des coûts multi-modèles
Le contrôle des coûts n'est pas synonyme d'économies garanties. Une couche API unifiée ne doit pas promettre que chaque requête deviendra moins chère.
La valeur pratique réside dans le contrôle :
- comparer les modèles par type de tâche
- éviter la surconsommation de modèles premium pour des travaux simples
- définir des budgets ou des limites par clé API, équipe ou produit
- évaluer les changements de modèle à l'aune des données d'utilisation et de qualité
- rapprocher la politique de coûts de la couche plateforme plutôt que de la disperser dans le code applicatif
En production, le principal problème de coût n'est souvent pas une requête coûteuse isolée. C'est un paramètre par défaut coûteux qui sert silencieusement des millions de requêtes simples parce que personne ne dispose d'un endroit propre pour le modifier.
Planification du fallback et de la fiabilité
Les systèmes IA en production ont besoin d'un plan en cas de défaillance :
- panne d'un fournisseur
- épuisement du quota
- limitation de débit (rate limiting)
- dégradation de la latence
- erreurs spécifiques à un modèle
- régression de qualité inattendue après une mise à jour de modèle
Avec des intégrations fournisseurs séparées, la logique de fallback apparaît souvent au sein des services métier. Une équipe gère les retries d'une façon. Une autre utilise un timeout différent. Une troisième n'a aucun chemin de secours.
Une couche API unifiée offre aux équipes un meilleur endroit pour définir le comportement de fallback et la politique opérationnelle. Elle permet de séparer la logique applicative des décisions liées à la disponibilité des fournisseurs.
Le fallback exige toutefois de la prudence. Un modèle de secours peut avoir un comportement de sortie différent, des limites de contexte différentes, un support d'outils différent ou un prix différent. L'objectif n'est pas une substitution aveugle. L'objectif est de disposer d'un espace contrôlé pour planifier et tester la substitution.
Des opérations en production plus propres
À mesure que l'utilisation de l'IA croît, la couche modèle commence à nécessiter la même discipline opérationnelle que les autres briques d'infrastructure :
- journalisation
- attribution de l'utilisation
- suivi de la latence
- classification des erreurs
- contrôles d'accès
- revue des changements de modèle
- réponse aux incidents
- séparation des environnements
- documentation pour les développeurs
Si chaque équipe fonctionnelle gère sa propre intégration fournisseur, ces pratiques deviennent incohérentes. Une couche API unifiée facilite la définition de standards partagés pour la manière dont les appels aux modèles sont effectués, observés et modifiés.
C'est pourquoi l'expression « une seule API » peut être trompeuse. La vraie valeur architecturale n'est pas simplement un endpoint unique. C'est un endroit unique pour opérer la livraison des modèles.
Quand une API unifiée simple suffit
Une API unifiée simple peut suffire lorsque votre besoin principal est la stabilité d'intégration.
Utilisez une couche API unifiée simple lorsque :
- vous utilisez un petit nombre de modèles
- vous souhaitez une seule clé API et un seul format de requête
- le choix de modèle est essentiellement explicite
- le volume de trafic est gérable
- les exigences de fallback sont limitées
- votre équipe cherche principalement à réduire la charge d'intégration
Par exemple, une startup peut utiliser un modèle pour le chat utilisateur, un autre pour le résumé interne, et un modèle image pour la génération de contenu. Si le produit n'a pas encore besoin de routage dynamique ou de gouvernance avancée, le premier bénéfice est une couche d'intégration partagée et stable.
Cette étape reste précieuse. Elle empêche le produit de développer trois piles d'intégration distinctes avant que l'équipe ne comprenne ses véritables charges de travail.
Quand vous avez besoin d'une passerelle ou d'une couche de routage plus avancée
Le besoin d'une passerelle plus avancée apparaît lorsque la couche API unifiée doit faire plus que fournir un accès.
Vous aurez probablement besoin de routage, de contrôles de passerelle ou d'une couche de livraison de modèles managée lorsque :
- le volume de requêtes est suffisamment élevé pour que le choix de modèle impacte la marge
- les charges de travail varient fortement en complexité
- les exigences de fiabilité sont explicites
- plusieurs équipes ou services dépendent des appels aux modèles
- l'utilisation doit être attribuée par produit, client ou équipe
- le comportement de fallback doit être testé et documenté
- les changements de modèle nécessitent une revue plutôt que des modifications ad hoc
| Scénario | Ce dont vous avez probablement besoin | Pourquoi |
|---|---|---|
| Tester un modèle dans un prototype | API directe ou API unifiée simple | La rapidité d'exécution prime sur le contrôle plateforme |
| Utiliser 2 à 3 modèles dans un produit | Couche API unifiée simple | Une seule surface d'intégration réduit le code de glue spécifique aux fournisseurs |
| Exécuter des charges de travail en production à haut volume | API unifiée avec contrôles de coûts et d'utilisation | Les dépenses, la latence et l'attribution de l'utilisation commencent à compter |
| Construire des agents avec des tâches variables | API unifiée avec routage pour les charges de travail texte supportées | Différentes étapes agentiques peuvent nécessiter des profils de modèle différents |
| Gérer la fiabilité entre fournisseurs | Passerelle ou couche de routage avec planification de fallback | La gestion des pannes ne doit pas être dupliquée dans chaque service |
Comment cela se traduit chez EvoLink
EvoLink est conçu autour de ce modèle de livraison de modèles : un point d'entrée API unique pour les modèles supportés, avec des capacités de plateforme superposées autour de l'accès, de la visibilité des coûts, du routage des charges de travail texte et du contrôle opérationnel.
Au lieu de traiter chaque intégration de modèle comme un projet distinct, les équipes peuvent utiliser EvoLink comme une couche partagée de livraison de modèles à travers les familles de modèles supportées.
Ce positionnement est important parce qu'EvoLink n'est pas une simple liste de modèles. L'architecture à long terme se rapproche davantage d'une infrastructure de livraison de modèles IA :
- Accès unifié : utilisez un seul chemin d'intégration pour les modèles supportés au lieu de reconstruire l'accès pour chaque fournisseur ou famille de modèles.
- Contrôle des coûts : comparez les choix de modèles, inspectez la tarification et évitez de reléguer la politique de coûts au second plan dans le code applicatif.
- Contrôle d'invocation : maintenez la sélection de modèle, les décisions de routage pour les requêtes LLM supportées, les clés API et les limites d'utilisation au plus près de la couche plateforme.
- Prêt pour la production : traitez les appels aux modèles comme du trafic opérationnel qui nécessite de la visibilité, une planification de fallback et des pratiques d'intégration stables.
La frontière importante est la suivante : une couche API unifiée peut faciliter l'exploitation de la livraison des modèles, mais elle ne doit pas prétendre que tous les modèles ont un comportement identique. Les équipes ont toujours besoin d'évaluation, de journalisation, de revue des coûts et d'assurance qualité spécifique à chaque workflow.
Checklist de décision
Utilisez cette checklist avant de décider si votre application a besoin d'une couche API unifiée, d'une passerelle ou d'appels directs aux fournisseurs.
- Utilisez-vous plus d'une famille de modèles aujourd'hui ?
- Ajouterez-vous des modèles image, vidéo, audio, code ou à contexte long plus tard ?
- Pouvez-vous changer de modèle sans modifier le code applicatif à plusieurs endroits ?
- Pouvez-vous visualiser l'utilisation par fonctionnalité, équipe, client ou clé API ?
- Pouvez-vous comparer les coûts entre modèles au sein d'un même workflow ?
- Savez-vous quel modèle a servi chaque requête en production ?
- Disposez-vous d'un plan de fallback en cas de rate limiting, de panne fournisseur ou de dégradation de latence ?
- Le comportement de retry et de timeout est-il cohérent entre les services ?
- Les développeurs peuvent-ils utiliser un seul modèle d'accès documenté ?
- Le choix de modèle fait-il l'objet d'une revue opérationnelle, et pas seulement d'un changement de code ?
Si la plupart des réponses sont « non », le problème ne se limite pas à la commodité d'intégration. Votre couche de modèles est en train de devenir une brique d'infrastructure de production.
FAQ
Qu'est-ce qu'une API unifiée pour les modèles IA ?
Une API unifiée pour les modèles IA est une couche d'intégration unique qui permet à une application d'appeler les modèles supportés via un point d'entrée API cohérent. Elle peut réduire la duplication des configurations fournisseurs et créer un espace partagé pour l'accès aux modèles, la visibilité sur l'utilisation, la facturation, les contrôles de coûts, le routage et la politique opérationnelle.
Une API unifiée, est-ce la même chose qu'une passerelle LLM ?
Pas toujours. Une API unifiée simple peut ne fournir qu'une surface d'accès unique pour plusieurs modèles. Une passerelle LLM ajoute généralement davantage de capacités d'infrastructure : routage, fallback, observabilité, contrôles de politiques, limites de débit ou gouvernance. En pratique, de nombreuses équipes démarrent avec un accès unifié et évoluent vers une passerelle à mesure que les exigences de production augmentent.
Ai-je besoin d'une API unifiée si je n'utilise qu'un seul modèle ?
En général, non. Si votre produit utilise un seul modèle, a un trafic faible et n'a pas besoin de fallback ni de visibilité multi-fournisseurs, l'accès direct à l'API peut être plus simple. Une API unifiée devient plus utile lorsque le choix de modèle, le contrôle des coûts ou la planification de la fiabilité deviennent des tâches récurrentes.
Comment une API unifiée facilite-t-elle le routage des modèles ?
Le routage a besoin d'un espace stable pour prendre les décisions de sélection de modèle. Une couche API unifiée fournit à l'application un chemin de requête unique tandis que la logique de routage choisit un modèle en fonction du type de tâche, des contraintes de latence, du profil de coût ou d'autres signaux. En production, le routage doit aussi exposer quel modèle a été sélectionné afin que les équipes puissent journaliser, évaluer et déboguer le comportement.
Est-ce qu'une API unifiée rend tous les modèles identiques ?
Non. Une API unifiée peut normaliser certains aspects de l'accès, de l'authentification, de la forme des requêtes, du reporting d'utilisation ou de la politique de routage, mais elle ne rend pas la qualité, la latence, les limites de contexte, le comportement d'outils, le support des modalités ou la tarification identiques d'un modèle à l'autre. Les équipes doivent continuer à tester chaque modèle sur leurs propres workflows.


