
Guide du développeur sur le routeur d'équilibrage de charge

Au lieu de laisser un serveur être submergé, le routeur distribue intelligemment les requêtes entrantes sur un pool de serveurs ou, dans le contexte des applications d'IA modernes, sur différents modèles d'IA. Le résultat est une application hautement disponible et performante qui offre une expérience fluide à vos utilisateurs.
Comment fonctionne un routeur d'équilibrage de charge ?
À la base, un routeur d'équilibrage de charge est conçu pour éliminer les points de défaillance uniques. Dans une architecture classique à serveur unique, si ce serveur est surchargé ou s'éteint, toute votre application s'arrête.
Un routeur d'équilibrage de charge se situe entre vos utilisateurs et votre pool de serveurs, interceptant chaque requête entrante et décidant quelle ressource en aval est la mieux équipée pour la traiter à ce moment-là. Ce concept a considérablement évolué, passant des premiers appareils matériels à la couche logicielle sophistiquée qui sous-tend les systèmes distribués modernes. Comprendre ce principe est la première étape vers la construction de systèmes résilients, en particulier face à la nature imprévisible du trafic API.
Pourquoi chaque application moderne en a besoin
Pour les développeurs, un équilibreur de charge bien implémenté offre des avantages critiques :
- Haute disponibilité : Si un serveur ou un endpoint API tombe en panne ou ne répond plus, le routeur le retire automatiquement du pool et redirige le trafic vers des instances saines. Votre application reste en ligne.
- Évolutivité (Scalability) : Pour gérer une charge accrue, il vous suffit d'ajouter des serveurs au pool. L'équilibreur de charge commencera immédiatement à acheminer le trafic vers ceux-ci, permettant une mise à l'échelle horizontale sans interruption de service.
- Performances améliorées : En répartissant la charge de travail, vous vous assurez que les requêtes des utilisateurs sont toujours traitées par un serveur réactif, réduisant ainsi la latence et améliorant l'expérience utilisateur globale.
Considérez un routeur d'équilibrage de charge comme la première ligne de défense de votre application contre les pannes. Il transforme une collection de serveurs indépendants en un système unique, puissant et résilient.
Maîtriser ce concept vous permet de concevoir la résilience dès le départ, plutôt que de la traiter comme une réflexion après coup.
Comprendre les algorithmes de base de l'équilibrage de charge
Ces algorithmes fournissent la logique de répartition de la charge de travail. L'infographie ci-dessous illustre comment différentes stratégies fonctionnent ensemble pour gérer efficacement le trafic réseau.
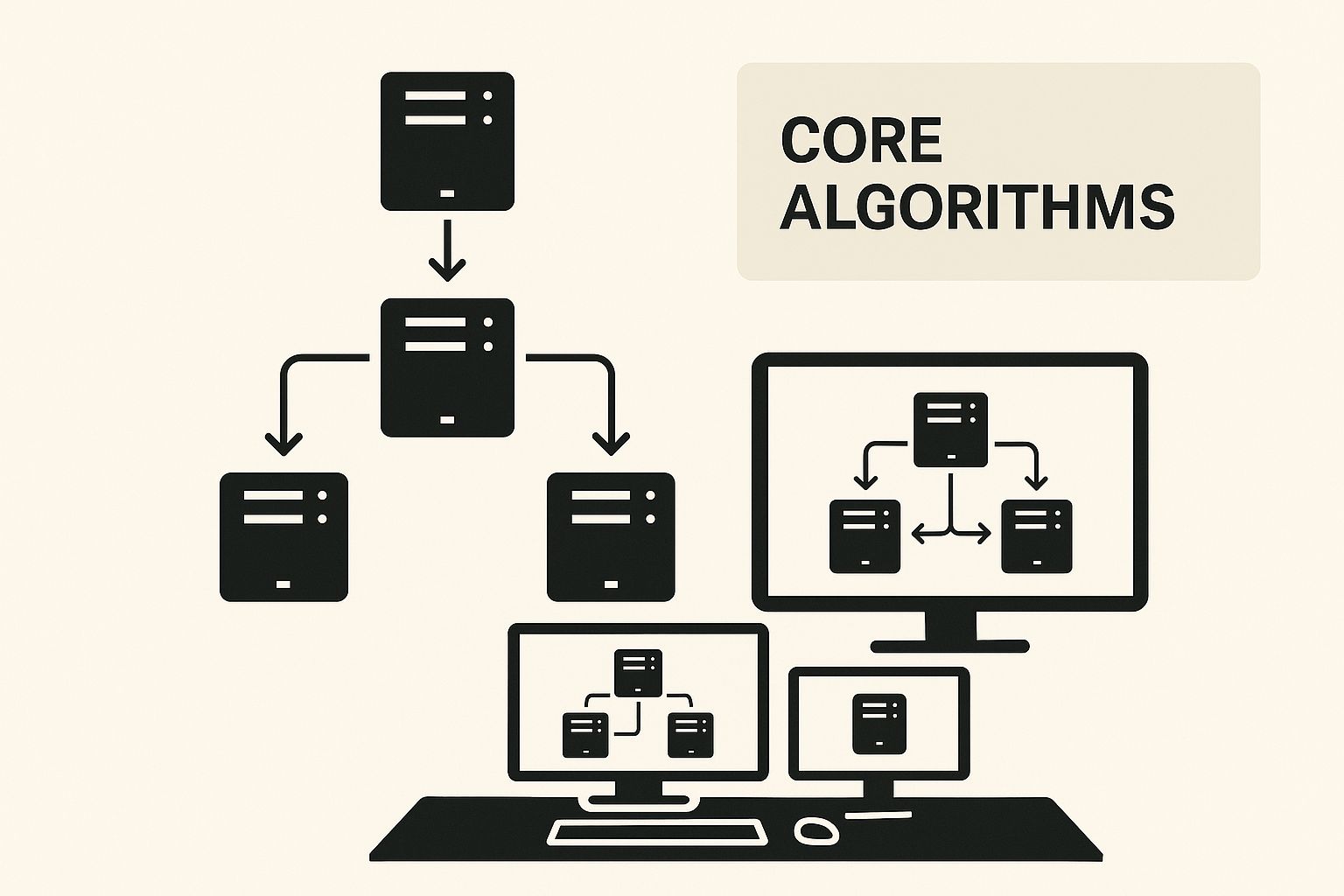
Comme vous pouvez le voir, ces méthodes fondamentales sont les briques de base pour des décisions de routage plus sophistiquées. L'objectif est d'empêcher un serveur unique d'être submergé et de provoquer une défaillance de l'ensemble du système.
Méthodes de distribution courantes
Alors, comment un équilibreur de charge décide-t-il où envoyer le trafic ? Il utilise généralement l'un des algorithmes standards suivants.
-
Round Robin : C'est la méthode la plus simple et la plus courante. L'équilibreur de charge parcourt une liste de serveurs, envoyant chaque nouvelle requête au serveur suivant dans la séquence. C'est prévisible, mais cela suppose que tous les serveurs ont la même capacité et que toutes les requêtes ont des coûts de traitement similaires.
-
Moins de connexions (Least Connections) : C'est une stratégie plus dynamique. L'algorithme achemine les nouvelles requêtes vers le serveur ayant le moins de connexions actives. C'est particulièrement efficace dans les environnements où la durée des connexions varie, empêchant un serveur d'être accaparé par des tâches de longue durée alors que d'autres sont inactifs.
-
IP Hash : Cette méthode utilise un hachage de l'adresse IP du client pour mapper systématiquement ce client au même serveur. Le principal avantage est la persistance de session (ou « stickiness »), qui est cruciale pour les applications avec état (stateful) comme les paniers d'achat en ligne où les données de session utilisateur doivent être maintenues sur un serveur spécifique.
Comparaison des algorithmes d'équilibrage de charge courants
Choisir le bon algorithme dépend des exigences spécifiques de votre application. Ce tableau détaille les méthodes les plus courantes pour vous aider à les comparer.
| Algorithme | Fonctionnement | Idéal pour | Inconvénient potentiel |
|---|---|---|---|
| Round Robin | Distribue les requêtes de manière séquentielle à chaque serveur d'une liste. | Environnements où les serveurs sont identiques et les requêtes uniformes. | Ne tient pas compte de la charge du serveur ou des temps de traitement variables. |
| Least Connections | Envoie les nouvelles requêtes au serveur ayant le moins de connexions actives. | Situations avec des connexions longue durée ou des charges de requêtes inégales. | Peut être plus gourmand en ressources pour suivre les connexions. |
| IP Hash | Assigne une requête à un serveur spécifique sur la base de l'adresse IP source. | Applications nécessitant une persistance de session (ex. paniers d'achat). | Peut entraîner une répartition inégale si certaines adresses IP envoient beaucoup de requêtes. |
| Weighted Round Robin | Une variante du Round Robin où les serveurs se voient attribuer un « poids » en fonction de leur capacité. | Environnements avec des serveurs ayant des capacités de traitement différentes. | Nécessite une configuration manuelle des poids et des ajustements au fil du temps. |
En fin de compte, il n'existe pas d'algorithme « idéal » unique. L'objectif est d'aligner la logique de répartition avec le comportement de votre application et l'architecture de votre infrastructure.
Routage pondéré et intelligent
Bien que ces algorithmes classiques soient efficaces pour le trafic web traditionnel, ils montrent leurs limites lorsqu'il s'agit d'acheminer des requêtes d'IA vers plusieurs fournisseurs. Un simple algorithme Round Robin n'a aucune notion de coût ou de disponibilité ; il pourrait envoyer aveuglément votre requête à un fournisseur coûteux ou indisponible. C'est précisément le problème qu'un routeur d'équilibrage de charge avancé comme EvoLink résout, en acheminant intelligemment le modèle de votre choix vers le fournisseur le plus rentable et le plus fiable en temps réel.
Le défi moderne du routage des modèles d'IA
L'équilibrage de charge traditionnel suppose que vous répartissez le trafic sur une flotte de serveurs identiques. Ce modèle fonctionne bien pour les requêtes web sans état, mais s'effondre complètement lorsqu'il est appliqué à l'écosystème diversifié des modèles d'IA.
Des modèles comme GPT-4, Llama 3 et Claude Haiku ne sont pas interchangeables. Ils diffèrent considérablement par leurs capacités de raisonnement, leur latence de réponse et, surtout, leur coût par jeton (token). Cela transforme le problème d'une simple répartition du trafic en un puzzle complexe d'optimisation multi-objectifs.
Utiliser une approche Round Robin basique ici est inefficace et coûteux. Vous pourriez acheminer une simple tâche de résumé vers votre modèle le plus puissant (et le plus coûteux), tandis qu'une requête analytique complexe pourrait être envoyée à un modèle plus rapide mais moins performant, ce qui entraînerait une réponse sous-optimale.

Des serveurs uniformes aux multiples fournisseurs d'IA
Une fois que vous avez sélectionné le modèle d'IA de votre choix, un routeur natif de l'IA doit évaluer plusieurs facteurs pour chaque requête :
- Coût du fournisseur : Le même modèle GPT-4 peut coûter 10 fois plus cher chez un fournisseur par rapport à un autre. Trouver le fournisseur disponible le moins cher pour votre modèle choisi offre des économies immédiates.
- Disponibilité du fournisseur : Le fournisseur est-il actuellement en ligne et réactif ? Des contrôles de santé en temps réel garantissent que vos requêtes atteignent toujours un point de terminaison fonctionnel.
- Latence du fournisseur : Quel fournisseur offre le temps de réponse le plus rapide en ce moment ? Un suivi dynamique des performances achemine vers le fournisseur le plus réactif à l'instant T.
Un routeur d'IA intelligent ne se contente pas d'équilibrer la charge ; il optimise les résultats commerciaux. Pour le modèle sélectionné, il prend une décision dynamique et éclairée pour chaque appel API afin d'offrir la meilleure performance au coût le plus bas possible en choisissant le fournisseur optimal.
Un exemple de code pour le routage intelligent des fournisseurs
Cette fonction conceptuelle JavaScript démontre la logique de sélection du fournisseur optimal pour un modèle choisi. Elle vérifie la disponibilité et le coût du fournisseur pour acheminer vers le meilleur endpoint.
// Une fonction conceptuelle pour sélectionner le meilleur fournisseur pour un modèle choisi
async function routeToProvider(selectedModel) {
// L'utilisateur a déjà sélectionné GPT-4 comme modèle
const providers = [
{ name: 'OpenAI', endpoint: 'https://api.openai.com/v1/chat/completions', cost: 0.03, available: true },
{ name: 'Azure', endpoint: 'https://azure.openai.com/v1/chat/completions', cost: 0.035, available: true },
{ name: 'Provider-A', endpoint: 'https://api.provider-a.com/v1/gpt-4', cost: 0.015, available: true },
{ name: 'Provider-B', endpoint: 'https://api.provider-b.com/v1/gpt-4', cost: 0.012, available: false }
];
// Filtrer pour ne garder que les fournisseurs disponibles
const availableProviders = providers.filter(p => p.available);
// Trier par coût, le moins cher en premier
availableProviders.sort((a, b) => a.cost - b.cost);
// Sélectionner le fournisseur disponible le moins cher
const selectedProvider = availableProviders[0];
console.log(`Routage de ${selectedModel} vers ${selectedProvider.name} à ${selectedProvider.cost} $ par requête`);
// Dans une application réelle, vous feriez l'appel API ici
// const response = await fetch(selectedProvider.endpoint, { ... });
// return response.json();
return {
model: selectedModel,
provider: selectedProvider.name,
endpoint: selectedProvider.endpoint,
cost: selectedProvider.cost
};
}
// Exemple d'utilisation - l'utilisateur a sélectionné GPT-4
routeToProvider('GPT-4').then(result => console.log(result));Bien que ce code illustre le concept de base, la construction d'un système prêt pour la production implique bien plus : gérer les clés API de dizaines de fournisseurs, suivre les prix et la disponibilité en temps réel, implémenter un basculement automatique (failover) lorsque les fournisseurs tombent en panne, et surveiller les performances en permanence.
Mise en œuvre du routage d'IA avancé avec EvoLink
Construire un routeur d'IA intelligent à partir de zéro est un défi d'ingénierie important. Cela nécessite la gestion de plusieurs clés API, le suivi des performances des modèles en temps réel, le codage d'une logique de failover robuste et la mise à jour continue du système à mesure que de nouveaux modèles sont publiés. C'est pourquoi une solution managée comme EvoLink change la donne pour les équipes de développement.
Cette approche unifiée réduit considérablement la charge opérationnelle et libère votre équipe d'ingénierie pour qu'elle se concentre sur votre produit principal, et non sur la gestion de l'infrastructure d'IA.
Comment fonctionne le routage intelligent dans le monde réel
Voici comment les fonctionnalités clés d'EvoLink apportent des avantages concrets :
- Basculement automatique du modèle (Failover) : Si un fournisseur principal comme OpenAI subit une panne ou une dégradation des performances, EvoLink redirige automatiquement les appels API vers un autre fournisseur sain proposant le même modèle. Votre application continue de fonctionner de manière transparente.
- Routage dynamique des performances : Le système surveille en permanence la latence et le débit de tous les fournisseurs disponibles pour le modèle choisi, envoyant chaque requête au fournisseur capable de fournir la réponse la plus rapide à ce moment-là.
- Optimisation intelligente des coûts : EvoLink achemine automatiquement votre requête vers le fournisseur le plus rentable pour votre modèle choisi, comparant constamment les prix entre des dizaines de fournisseurs pour vous garantir de toujours bénéficier du meilleur tarif.
En dirigeant intelligemment le trafic, les développeurs utilisant EvoLink réalisent souvent des économies de coûts comprises entre 20 et 70 %. Il ne s'agit pas seulement de choisir le fournisseur le moins cher ; il s'agit de faire le choix de fournisseur le plus judicieux pour chaque requête afin d'équilibrer performances et budget tout en utilisant vos modèles préférés.
Un exemple de code pratique avec EvoLink
Considérez cet exemple Python. Vous fournissez une liste priorisée de modèles, et EvoLink gère automatiquement tout le routage, l'optimisation et le failover.
import os
import requests
# Définissez votre clé API EvoLink à partir des variables d'environnement
api_key = os.getenv("EVOLINK_API_KEY")
api_url = "https://api.evolink.ai/v1/chat/completions"
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}
# Définissez votre modèle préféré avec des options de repli (fallback)
# EvoLink achemine chaque modèle vers le fournisseur disponible le moins cher
# Si votre premier choix n'est pas disponible, il bascule sur le modèle suivant de votre liste
payload = {
"model": ["openai/gpt-4o", "anthropic/claude-3.5-sonnet", "google/gemini-1.5-pro"],
"messages": [
{"role": "user", "content": "Analyze the sentiment of this customer review: 'The product is good, but the shipping was slow.'"}
]
}
try:
response = requests.post(api_url, headers=headers, json=payload)
response.raise_for_status() # Lever une erreur HTTP pour les mauvaises réponses (4xx ou 5xx)
print(response.json())
except requests.exceptions.RequestException as e:
print(f"Une erreur API s'est produite : {e}")Cet extrait démontre le pouvoir de l'abstraction. Le code de votre application reste propre et concentré sur la logique métier, tandis qu'un puissant routeur d'équilibrage de charge travaille en arrière-plan pour rendre votre application plus résiliente et rentable.
EvoLink élimine le besoin de construire et de maintenir un système interne complexe, en fournissant une solution prête pour la production qui donne des résultats immédiats. Cela permet à votre équipe d'intégrer des capacités d'IA de classe mondiale plus rapidement et plus efficacement.
Stratégies de routage pratiques que vous pouvez mettre en œuvre
Explorons quatre stratégies pratiques que vous pouvez mettre en œuvre.

Routage basé sur les coûts
Cette stratégie donne la priorité à votre budget. Le routage basé sur les coûts envoie automatiquement votre requête au fournisseur le plus abordable pour votre modèle choisi.
Routage basé sur la latence
Lorsque l'expérience utilisateur est primordiale, le routage basé sur la latence est le choix optimal. Il est essentiel pour les applications en temps réel telles que les chatbots de service client ou les outils d'IA interactifs où chaque milliseconde compte.
Le routeur surveille en permanence les performances en temps réel de tous les fournisseurs disponibles pour le modèle choisi. Lorsqu'une requête arrive, elle est instantanément transmise au fournisseur affichant le temps de réponse actuel le plus bas, garantissant à vos utilisateurs la réponse la plus rapide possible sans changer de modèle.
Routage de basculement (Failover)
Le routage de failover est le filet de sécurité de votre application. Inévitablement, les fournisseurs d'API subissent des pannes ou des dégradations de performances. Lorsque cela se produit, le routeur redirige automatiquement les requêtes vers le modèle sain suivant dans une liste de priorités prédéfinie.
Cette stratégie est fondamentale pour construire des systèmes à haute disponibilité capables de gérer en douceur les défaillances des fournisseurs sans aucun impact sur l'expérience de l'utilisateur final.
Foire aux questions
Quelle est la différence entre un équilibreur de charge et un routeur ?
Bien que souvent utilisés ensemble, ces composants remplissent des fonctions distinctes dans un réseau.
Puis-je construire mon propre équilibreur de charge de modèles d'IA ?
Techniquement, oui, vous pouvez construire une solution personnalisée. Cependant, la complexité d'un routeur d'IA de qualité production est substantielle.
Une solution robuste nécessite plus qu'une simple distribution de requêtes. Vous seriez responsable de la gestion sécurisée de dizaines de clés API, du suivi en temps réel du coût et de la latence pour chaque modèle, de la mise en place de contrôles de santé fiables et de l'ingénierie d'une logique de failover efficace. De plus, ce système nécessiterait une maintenance constante pour intégrer de nouveaux modèles et s'adapter aux changements des API.
C'est là qu'une solution managée comme EvoLink apporte une valeur significative. Nous avons déjà conçu un système durci pour la production qui gère toute cette complexité. Vous bénéficiez d'une API unique et unifiée avec un routage intelligent intégré, ce qui permet à votre équipe de se concentrer sur votre produit principal plutôt que sur l'infrastructure. Cette approche peut générer des économies de coûts immédiates de 20 à 70 % et garantir une haute fiabilité dès le premier jour.
Comment un routeur d'équilibrage de charge rend-il mon application plus fiable ?
La fiabilité est obtenue grâce à deux mécanismes principaux : la redondance et les contrôles de santé automatisés.
En répartissant les requêtes sur plusieurs modèles ou serveurs, un équilibreur de charge élimine les points de défaillance uniques. Si l'API d'un modèle devient indisponible ou si un serveur tombe en panne, l'application reste opérationnelle car le trafic est automatiquement dirigé vers les alternatives saines.
Le système effectue également des contrôles de santé continus sur chaque endpoint, un peu comme la surveillance des signes vitaux. Il envoie régulièrement des requêtes pour vérifier que chaque endpoint est réactif. Si un endpoint échoue à ces contrôles ou renvoie des erreurs, le routeur le retire instantanément du pool actif et redirige de manière transparente les nouvelles requêtes vers les points de terminaison sains restants. Ce basculement automatique est ce qui garantit la haute disponibilité, même en cas de défaillance partielle du système.


