
LLM API ラッパーが「インフラ」に変わる時

LLM API ラッパーが「インフラ」に変わる時
ほとんどのエンジニアリングチームは、最初から「LLM API ラッパー」を作ろうと考えて動き出すわけではありません。
キックオフ資料も、明確なロードマップも、誰かが「すべてのモデルプロバイダーを抽象化しよう」と言う瞬間も、普通はありません。その代わりに、プロダクションシステムを安定させようとする中で、ラッパーは静かに、一行ずつ形作られていきます。
この記事では、なぜプロダクションシステムにラッパーが頻繁に現れるのか、それがいつインフラの境界線を越えたと言えるのか、そしてチームが次に直面する典型的な意思決定について解説します。
LLM API ラッパーの正体(実務において)
プロダクションシステムにおいて、ラッパーが単一のコンポーネントであることは稀です。それは、アプリケーションと1つ以上のLLMプロバイダーの間に位置する、成長し続けるロジックの層です。
一般的な役割には以下が含まれます:
- リクエストとレスポンスのスキーマの正規化
- リトライ、タイムアウト、プロバイダー固有のエラーの処理
- モデル選択やフォールバックロジックの管理
- プロンプト、システムメッセージ、安全ルールの注入
- コスト配分、ロギング、監査のための使用状況の追跡
ほとんどのラッパーは、便利なヘルパーコードとして始まります。しかし、その多くが最終的にはミッションクリティカルな経路となります。
なぜラッパーが生まれるのか(誰も計画していなくても)
チームがラッパーを作るのは、抽象化を求めているからではありません。プロダクション環境のプレッシャーの下で、直接的な統合だけでは信頼性を維持できなくなるからです。
チームをこの方向に突き動かす、最も一般的な要因を挙げます。
1. インターフェースの不一致より、挙動の不一致の方が厄介
API スキーマを正規化するのは比較的簡単ですが、実行時の挙動(ランタイムビヘイビア)はそうではありません。
チームはしばしば次のような違いに直面します:
- ストリーミングレスポンスが失速したり、チャンクの区切りが違ったり、静かに失敗したりする
- 外見は似ていても、運用上の対処が異なるエラー群
- 負荷がかかった際に予測不能な動きをするタイムアウト
- プロンプトの解釈や切り捨て(truncation)における微妙な差異
これらの問題がプロダクション環境で表面化したとき、一般的な短期的な対処法は、プロバイダー固有の処理をローカルに追加することです:
if provider == X:
retry differently # 異なるリトライ処理
if streaming stalls:
fallback to non-stream # 非ストリーミングへのフォールバック時間が経つにつれ、これらの条件分岐が蓄積していきます。ラッパーは「API を綺麗にする」ためではなく、「挙動の予測不能さ」を封じ込めるために形成されるのです。
2. プロンプト管理は「便利ツール」として始まり、「ポリシー」として終わる
初期段階では、プロンプトは単にアプリケーションコードから渡される文字列に過ぎません。
しかし、次第に以下のような存在になります:
- バージョン管理されるアセット
- 複数のサービス間で共有されるリソース
- 評価ベンチマーク(Evaluation Baselines)と密接に関連するもの
- (製品やリスクプロファイルに応じて)安全性、コンプライアンス、品質基準の審査対象
この時点で、プロンプトは「アプリケーションの詳細」ではなく「設定(コンフィギュレーション)」として振る舞い始めます。
ラッパーは以下のために導入されます:
- プロンプト注入(Injection)の集約
- システムレベルの指示の強制
- サービス間での偶発的な乖離(Drift)の抑制
一見「プロンプトヘルパー」に見えるものは、多くの場合、ポリシー集約の最初の兆候です。
3. 中間層がないとコストの可視性が断片化する
直接 API を使用すると、コストの信号がプロバイダーごとに散らばってしまいます:
- 異なる課金単位(Pricing Units)
- 異なる請求サイクル
- 異なるレート制限のセマンティクス
エンジニアリングチームは、財務部門が気づくよりも早く、この痛みを感じることがよくあります。
ラッパーは以下の目的で現れます:
- 一貫した使用状況の追跡
- 機能やチームへのコスト配分
- 請求額が急騰する前のガードレールの適用
これは必ずしも FinOps の成熟度を示すものではなく、多くの場合、防御的なエンジニアリングの結果です。
4. 信頼性の保証はプロダクトコード内ではスケールしない
LLM が単なる実験から依存関係へと変わるにつれ、チームは以下のような機能を必要とし始めます:
- フォールバック
- プロバイダーのローテーション
- グレースフル・デグラデーション(段階的な機能縮小)
これらのロジックをアプリケーションコードに直接埋め込むと、密結合(Tight Coupling)が生じ、経路が脆弱になります。
ラッパーは、信頼性の意図を表現する自然な場所となります:
- 「これが失敗したら、あれを試す」
- 「レイテンシが閾値を超えたら、グレードを下げる」
- 「クォータ(割当)に達したら、モデルを切り替える」
この段階になると、ラッパーはもはや「あってもなくてもいい接着剤」ではありません。サービスレベルの期待値を強制し始める存在となります。
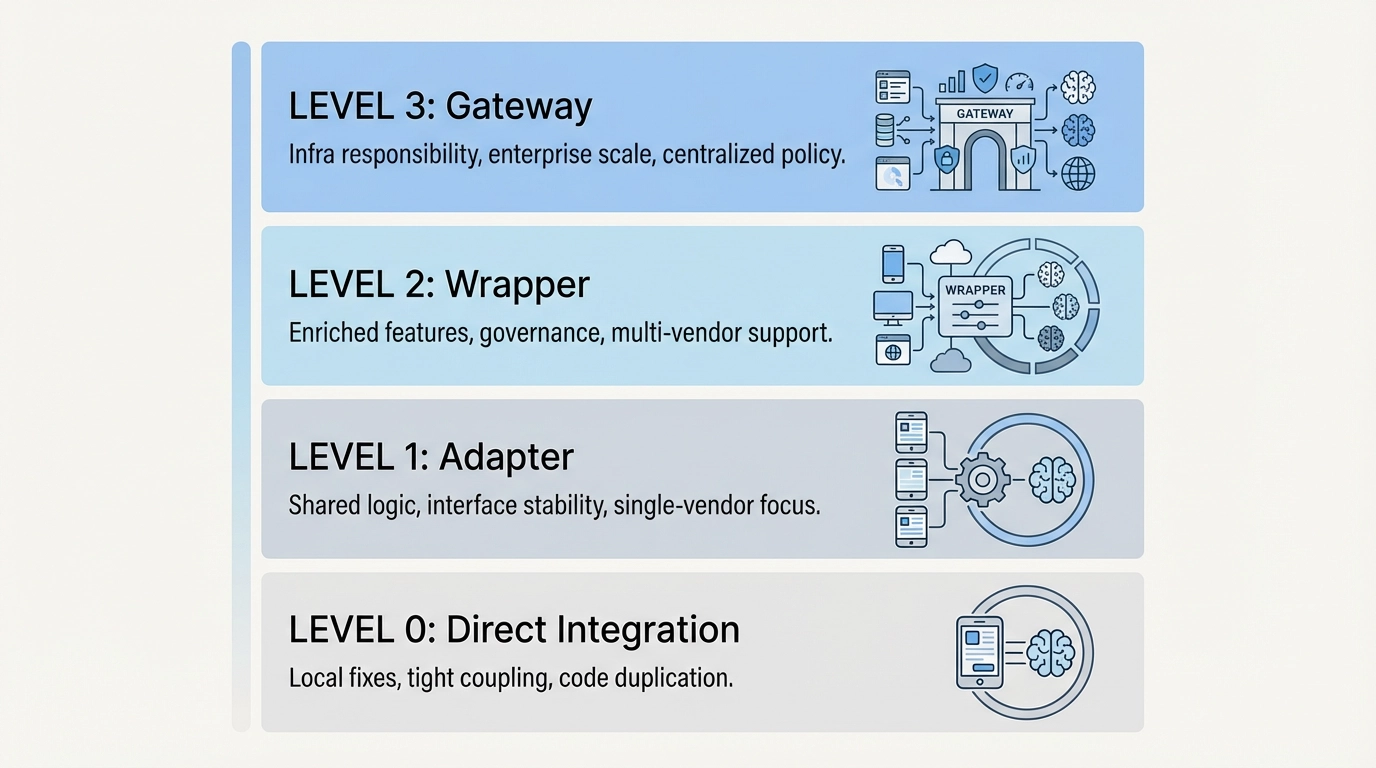
ラッパーの成熟度モデル
多くのチームは、自分たちのラッパーがすでにどれほど進化しているかを過小評価しています。以下の表は、一般的な進展を示しています。
| ステージ | 状態 | 一般的な課題 | 次に起こること |
|---|---|---|---|
| 直接統合 | アプリがプロバイダーを直接呼ぶ | 例外処理の散散 | 最小限のアダプター |
| アダプター | 統一スキーマ、軽量ヘルパー | 挙動の乖離 | リトライの集約化 |
| ラッパー | プロンプト、ルーティング、コスト追跡 | 所有権のボトルネック | インフラ的思考 |
| ゲートウェイ | 明示的なコントラクトと観測性 | トレードオフの表面化 | 組織的な整合性 |
システムがステージ2以上に達している場合、ラッパーはもはや一時的なものではなく、インフラのような責任を負い始めています。
ラッパーが静かに「インフラ」になる時
チームは、境界線を越えたことに気づくのが遅すぎることがよくあります。
一般的な兆候には以下のものがあります:
- 複数のチームが同じラッパーに依存している
- 変更を加える際に調整やロールアウト計画が必要になる
- 障害が発生すると、無関係なサービスまで影響を受ける
- ドキュメント、明確な所有権、モニタリングが必要なレイヤーとなっている
この時点で、ラッパーは「ゲートウェイ層」として機能し始めています。たとえまだそのように命名されたり、運用されたりしていなくてもです。
違いは単なる機能の多寡ではありません。それは「意図」と「運用」の違いです。
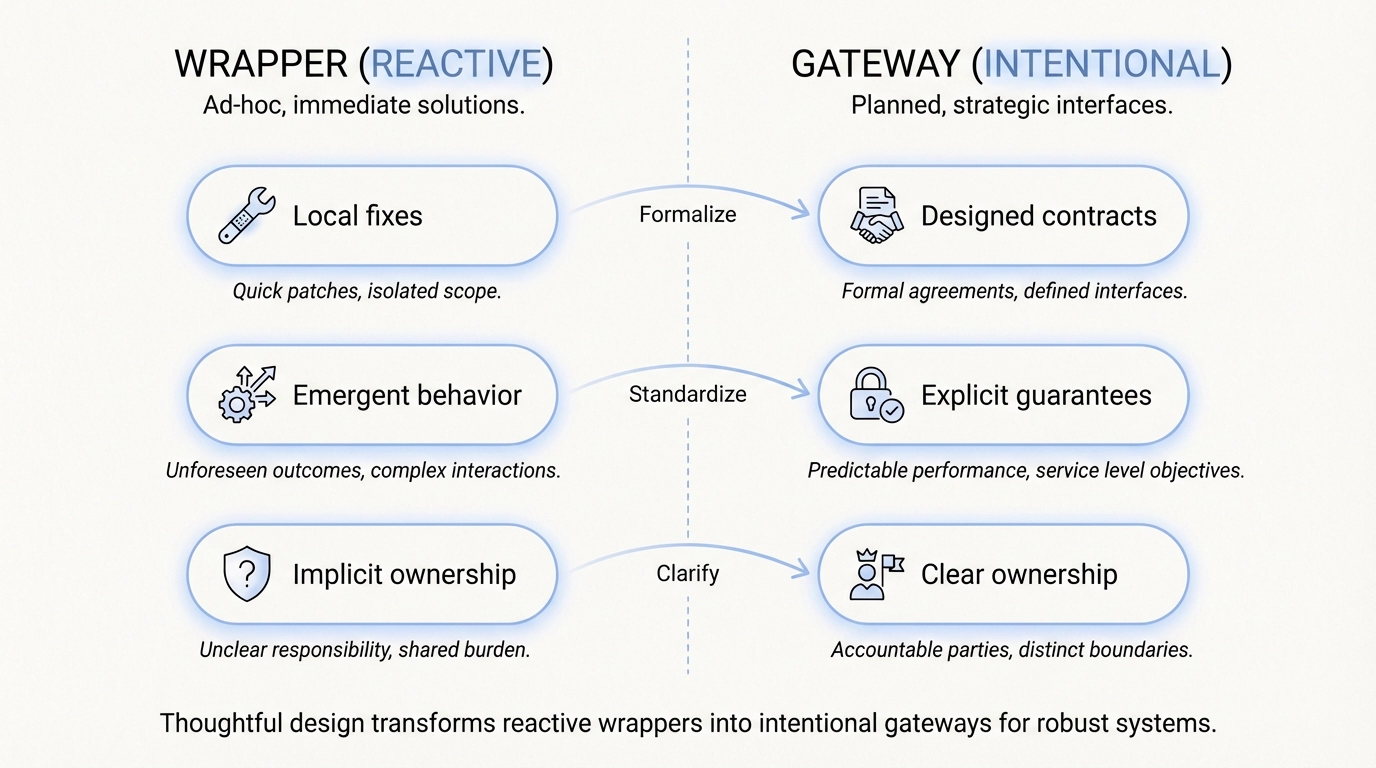
ラッパーはしばしば「受動的」です。ゲートウェイは「設計」されるものです。
構築か進化か:チームが直面する真の決断
「ラッパーを構築すべきか?」という問いは、もはや意味をなしません。その決断はすでに暗黙のうちに行われていることが多いからです。
真の問いはこうです:
アドホックな進化はしばしば以下を招きます:
- 隠れた密結合
- 不一致な保証内容
- 一部のエンジニアに偏ったナレッジ
意図的なインフラ化は、通常以下のメリットをもたらします:
- 明確なコントラクト
- 観測可能な挙動
- 明示的なトレードオフ
どちらの道が普遍的に正しいということはありません。しかし、「選ばない」ということもまた、一つの選択なのです。
注意すべきアンチパターン
ラッパーに苦労しているチームは、似たような罠に陥りがちです:
- プロバイダー固有のロジックがプロダクトコードに漏れ出している
- 異なるチームによって複数のラッパーが維持されている
- 評価ベンチマークがないルーティングロジック
- 使用状況の紐付け(Attribution)がないコスト追跡
- テレメトリやアラートがないクリティカルな経路
これらのパターンは、システムが非公式な抽象化の枠を超えて成長してしまったことを示唆しています。
簡単な自己評価チェックリスト
以下のうち3つ以上に「はい」と答える場合、そのラッパーはおそらくすでにアーキテクチャの一部となっています:
- プロバイダー固有の条件分岐が、複数のサービスにまたがって現れている
- プロンプトがプロダクトコードの外で注入または変更されている
- LLM の使用状況やコストに関する単一の真実(Single Source of Truth)がない
- リトライやフォールバックのロジックが、複数の場所で重複している
- プロバイダーの障害発生時に、コードの調整を伴う変更が必要になる
もしそうなら、そのラッパーはもはやオプション(選択肢)ではありません。
👉 次のステップ
次の問いは、直接的な API を使い続けることが依然として正しい抽象化なのか、それともゲートウェイを導入するだけの価値があるのか、ということです。
最後に
ラッパーを構築することは間違いではありません。
それはスケール、複雑性、そしてプロダクション環境のプレッシャーの結果として現れる「兆候」です。
本当のリスクは、重要な抽象化レイヤーがすでにインフラとなっているにもかかわらず、いつまでも「単なるヘルパー」として扱い続けることにあります。
ラッパーがいつその境界線を越えたのかを理解することが、そのレイヤーを次に何に進化させるべきかを決定する第一歩となります。
よくある質問 (FAQ)
LLM API ラッパーとは何ですか?
ラッパーとは、挙動の正規化、ポリシーの適用、および複数の LLM プロバイダーにわたる信頼性の管理を行う中間層のことです。
チームはいつ LLM ラッパーを構築すべきですか?
多くの場合、プロダクション環境での信頼性、コスト管理、またはプロンプトガバナンスが繰り返しの課題になった時点で、暗黙のうちに構築が進められます。
ラッパーとゲートウェイの違いは何ですか?
実務上、ラッパーはしばしばその場しのぎの修正の集まりですが、ゲートウェイは明示的なコントラクトを持つ、意図的に設計されたインフラです。
ラッパーの枠を超えるべきタイミングはいつですか?
複数のチームがそれに依存し、障害の影響が広く波及し、運用上の保証が重要になったとき、そのラッパーは実質的にインフラとなっており、相応の扱いが必要になります。


