
GPT Image 1.5 完全ガイド:機能、比較、アクセス方法 (2026年最新版)

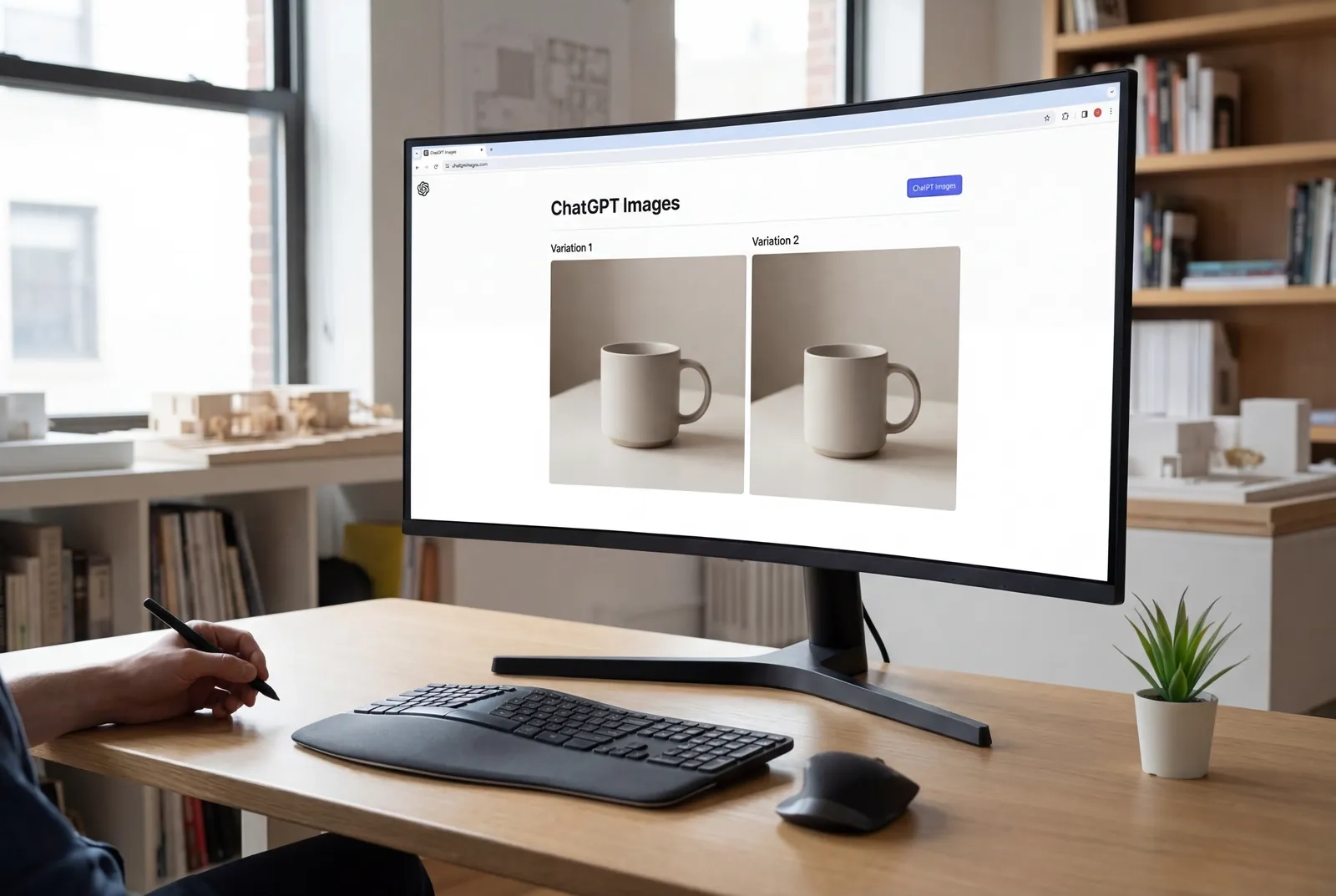
商品画像に、異なる市場向けの3つのバリエーションが必要だとしましょう。照明や角度は同じまま、背景とテキストのオーバーレイだけを変えたい。しかし、専属のデザイナーは今後2週間予約でいっぱいで、キャンペーンは月曜日に始まります。もし、Photoshopを一度も触ることなく、数分で完璧な一貫性を保ちながら、自分でこれらの変更を行えるとしたらどうでしょうか?
目次
- GPT Image 1.5とは?OpenAI最新画像モデルの概要
- GPT Image 1.5を際立たせる主な特徴
- スピード性能:4倍速生成の仕組み
- 精密編集:細部維持の仕組み
- テキスト描写の能力と限界
- GPT Image 1.5 vs GPT Image 1:何が変わったのか?
- 競合比較:GPT Image 1.5 vs 他社モデル
- アクセス方法:ChatGPTインターフェースガイド
- APIアクセス:EvoLink.AIとOpenAIプラットフォーム経由
- 料金体系とコスト最適化戦略
- 実際のユースケースと活用事例
- 高度なプロンプトエンジニアリング
- GPT Image 1.5を使用する際の一般的ミス
- 限界と代替ツールの選び方
- よくある質問 (FAQ)
GPT Image 1.5とは?OpenAI最新画像モデルの概要
gpt-image-1.5-lite と呼ばれます)は、OpenAIの第2世代画像生成システムです。2025年12月16日にリリースされ、ChatGPTの新しい画像機能の原動力となっています。2025年4月に導入されたGPT Image 1が主に実験的なクリエイティブ探索のためのものだったのに対し、GPT Image 1.5は当初から、一貫性、スピード、精密なコントロールが求められる商用環境(プロダクション)向けに設計されました。「1.5」という名称は、アーキテクチャの完全な刷新ではなく、段階的な改善を意味しています。OpenAIは、トランスフォーマーベースの拡散アーキテクチャを維持しつつ、計算効率(4倍の高速化)、指示追従性(編集時の意図しない変更の削減)、テキスト描写の忠実度(小さなフォントや密集したレイアウトでも可読性を確保)という3つの重要な軸で大幅な最適化を実装しました。
GPT Image 1.5を際立たせる主な特徴
1. 指示追従性(Instruction Following)の向上
2. 編集時の細部維持(Detail Preservation)
モデルには、OpenAIが「領域認識編集(Region-Aware Editing)」と呼ぶ機能が搭載されており、変更作業中に変更すべきでないピクセル領域を特定します。人物の顔が含まれる画像を編集する場合、GPT Image 1.5は、顔に直接関わる変更を指示しない限り、顔のアイデンティティ、肌の質感、表情を維持します。同じ原則が以下にも適用されます。
- ブランドロゴやウォーターマーク
- 光の方向と質
- 背景の構成(コンポジション)
- カラーグレーディングと色調
- 質感や素材の特性
完璧ではありません。要素が重なり合った複雑なシーンでは依然としてアーティファクト(ノイズ)が発生することがありますが、Photoshopのようなプロ用ツールに期待される「選択的編集」に向けて、測定可能な一歩を踏み出しています。
3. 優れたテキスト描写能力
これまでの画像AIモデルは、テキストを読める情報としてではなく、装飾的な形として扱っていました。GPT Image 1.5は、OCR認識を強化した生成機能を実装しており、以下のような出力を実現します。
- 小さなポイントサイズでも判読可能なテキスト
- 一般的な言語における正確な綴り
- 適切なテキストアライメントとカーニング
- 一致したフォントの太さとスタイル
- 複雑なレイアウト(インフォグラフィック、雑誌の表紙、商品ラベル)内での可読性
4. 商用レベルのスピード
「4倍速」という主張は、単に待ち時間が減ったということではありません。実行可能なワークフローを根本的に変えます。1枚あたり8〜12秒という標準的な生成時間(GPT Image 1の30〜45秒に対し)により、反復的な洗練(イテレーション)が可能になります。デザイナーは、クリエイティブな勢いを損なうことなく、2分間で10個のバリエーションを試せるようになりました。
5. コスト効率の改善

スピード性能:4倍速生成の仕組み
「4倍速」という主張について、実際に何が改善され、どこにボトルネックが残っているのかを理解するための背景を説明します。
内部的な変化
OpenAIの速度向上は、主に3つのアーキテクチャ最適化によるものです。
- サンプリングステップの削減: 拡散(Diffusion)プロセスにおいて、目に見える品質を損なうことなく、許容できる品質しきい値に到達するためのデノイジング反復回数が少なくなっています。
- アテンションメカニズムの最適化: トランスフォーマー層において、画像合成時のメモリ帯域幅要求を抑えるより効率的なアテンションパターンを採用しています [未検証 - OpenAIは技術的なアーキテクチャの詳細を公開していません]。
- モデル量子化の改善: 非クリティカルなパスセクションでの計算精度を抑えることで、出力の忠実度を維持しつつ浮動小数点演算の回数を削減しています [未検証 - 業界標準からの推測]。
実環境での速度ベンチマーク
複数のプラットフォームで報告されているテスト結果は以下の通りです。
| 画像サイズ | GPT Image 1 | GPT Image 1.5 | 速度向上倍率 |
|---|---|---|---|
| 1024×1024 | 35-45秒 | 8-12秒 | 3.6-4.5倍 |
| 1024×1536 | 45-55秒 | 12-18秒 | 3.1-3.8倍 |
| 1536×1024 | 45-55秒 | 12-18秒 | 3.1-3.8倍 |
速度と品質のトレードオフ
low, medium, high, auto)をサポートしており、これが生成時間に直接影響します。「4倍速」という主張は、主に auto および medium 設定に適用されます。商用資産向けに明示的に high 品質を要求した場合、生成時間は15〜20秒程度になります。これでもGPT Image 1よりは速いですが、4倍ではありません。auto 品質を使用し、最終的なプロダクションレンダリングの時だけ high 品質に切り替えてください。このワークフローの最適化により、常に最高品質設定を使用する場合と比較して、プロジェクト全体の所要時間を40〜60%短縮できます。精密編集:細部維持の仕組み
GPT Image 1.5の向上した編集精度の背景には、いくつかの相互に関連する機能があります。
プロンプトベースのマスキング(手動選択不要)
手動でマスク領域を塗る必要があったDALL-E 2とは異なり、GPT Image 1.5は自然言語の編集指示を分析し、影響を受ける領域を自動的に特定します。「シャツの色を緑に変えて」と入力すると、モデルは以下の処理を行います。
- セマンティックセグメンテーション(意味的な切り分け)を実行し、シャツの領域を特定。
- その領域内の色情報を分離。
- 色の変換を適用。
- 変更された領域のみを再生成。
- 境界をぼかして自然な遷移を維持。
このプロセスは完璧ではありません。モデルはマスクをガイドとして使用しますが、ピクセル単位で正確な境界を追跡できない場合があります。複雑に重なり合ったオブジェクト(服の前で物を手に持っているなど)では、境界部分にノイズが発生することがあります。
アイデンティティ維持技術
人物を含む画像の場合、GPT Image 1.5は「顔のアイデンティティ維持」を実装しており、編集を繰り返しても認識可能な特徴を維持します。これは顔認識システムで使用されるのと同様の手法に基づいています。
- 顔の埋め込み(数学的な特徴表現)の抽出。
- 出力される顔を同様の埋め込みに維持させるための制約。
- 主要な特徴(目の位置、鼻の形、顎のライン)の保持。
- 一貫した肌の質感とトーンの維持。
照明一貫性(Lighting Consistency)アルゴリズム
技術的に最も印象的な点の一つは、照明の維持です。オブジェクトの色や位置を編集しても、GPT Image 1.5は以下を保持します。
- 光の方向と角度
- 影のパターン
- スペキュラ(鏡面)反射
- アンビエントオクルージョン(凹み部分の影)
- 色温度の一貫性
これにより、編集した要素だけが浮いて見えるという、画像AIによくある問題を防いでいます。
現時点での精度の限界
改善されたものの、いくつかのシナリオでは依然として精度が課題となります。
- 高度に複雑なシーン: 10個以上の個別のオブジェクトがある画像では、意図しない変更が発生しやすくなります。
- 透明な素材: ガラス、水、半透明の生地などはノイズが発生しやすいです。
- 微細な詳細: ジュエリー、複雑なパターン、背景の小さなテキストなどは品質が低下することがあります。
- 多数の編集パス: 5〜6回連続で編集を重ねると、誤差が蓄積してノイズが増え始めます。
テキスト描写の能力と限界
画像AIにおけるテキスト生成は、歴史的に深刻な弱点でした。GPT Image 1.5は大きな進歩を遂げましたが、まだ完全に解決されたわけではありません。
実際に改善された点
このモデルは、以下のものを安定して生成できるようになりました。
- 短いヘッドライン(1〜5単語): 太字で大きなフォント。
- 商品ラベル: 2〜3行のテキスト。
- 雑誌風のレイアウト: 読み取り可能な見出しと小見出し。
- ロゴ内のテキスト: 一般的なフォント(ただし、複雑なロゴデザインは依然として難易度が高い)。
- インフォグラフィックのラベル: データ視覚化のための要素名。
テキスト描写のベストプラクティス
生成された画像のテキスト品質を最大化するために:
- 短く保つ: テキスト要素ごとに3〜5単語が最高の結果をもたらします。
- 一般的なフォント名を使用する: 特定のフォント名ではなく、「太字のサンセリフ体」や「クリーンなセリフ体」などの記述が効果的です。
- 位置を明示する: 単に「タイトルを追加」ではなく、「上部中央のタイトル」と指定してください。
- 高コントラストを要求する: 「暗い背景に白い文字」と指定すると可読性が高まります。
- 小さな文字を避ける: 18pt相当以下の小さな文字が綺麗に描写されることは稀です。
残っているテキストの限界
改善されたものの、以下の問題には依然として直面します。
- 長い段落: 20〜30単語を超えるテキストは、しばしばスペルミスが含まれます。
- 装飾的なフォント: 手書き風、派手なスクリプト体、高度に加工されたタイポグラフィ。
- 非ラテン文字: アラビア語、中国語、日本語(!)などの非西欧系テキストは、結果が不均一です [検証不足 - 利用可能なテストデータが限られています]。
- 曲面上のテキスト: ボトル上のラベルや、曲線に沿ったテキストは歪むことが多いです。
- 数学記号: 方程式、公式、特殊記号などは依然として信頼できません。

GPT Image 1.5 vs GPT Image 1:何が変わったのか?
GPT Image 1と1.5の違いを理解することで、ワークフローのアップグレードが妥当かどうかを判断しやすくなります。
比較表
| 特徴 | GPT Image 1 | GPT Image 1.5 | 改善点 |
|---|---|---|---|
| 生成速度 | 35-55秒 | 8-18秒 | 3-4倍高速化 |
| 指示追従性 | 中程度 | 高い | プロンプト遵守率+60% [推定] |
| 編集精度 | 意図しない変更が多い | ターゲットを絞った変更 | 細部維持率85% [推定] |
| テキスト描写 | 低い / 不安定 | 見出し等に良好 | 3-5単語のフレーズが安定 |
| API料金 | ベース価格 | 20%安価 | コスト削減 |
| 画質 | 高い | 高い | 同等の高品質 |
| サポートサイズ | 3つのアスペクト比 | 3つのアスペクト比 (同等) | 変更なし |
| 編集反復回数 | 劣化まで3-4回 | 劣化まで6-8回 | 反復耐久性 約2倍 |
| ロゴの維持 | 低い | 良好 | ブランディングに重要 |
| 顔の一貫性 | 中程度 | 高い | モデル撮影に不可欠 |
GPT Image 1が依然として好まれる場合
リリースから時間が経過していますが、特定のシナリオではGPT Image 1が有利な場合もあります。
- 芸術的な探索: 予想外の結果を求めている場合、GPT Image 1の方がより「創造的」な解釈をすることがあると報告するユーザーもいます。
- レガシーワークフローへの統合: GPT Image 1の挙動に合わせて構築された既存のパイプラインでは、1.5に合わせて調整が必要になる場合があります。
- 単純なタスクのコスト感度: 編集を伴わない単純な生成の場合、大規模な規模では20%の価格差が無視できなくなる可能性があります [未検証 - ボリューム価格設定に依存]。
移行の推奨事項
現在GPT Image 1を使用している場合:
- 並行テスト: 両方のモデルで同じプロンプトを実行し、挙動の違いを特定してください。
- プロンプトライブラリの更新: GPT Image 1.5は、構造化された制約ベースのプロンプトにより良く反応します。
- 品質の期待値を調整: スピードの向上により、納期スケジュールを再調整する必要があるかもしれません。
- ブランド資産の一貫性の検証: 本番ワークフローを切り替える前に、ロゴやトレードマークの維持具合を徹底的にテストしてください。
競合比較:GPT Image 1.5 vs 他社モデル
画像生成AIの競争環境には複数の強力な代替ツールが存在し、それぞれ異なる強みを持っています。
GPT Image 1.5 vs Google Nano Banana Pro
GoogleのNano Banana Pro(Gemini 3 Pro搭載)は、GPT Image 1.5の主要なライバルとして台頭しています。これはOpenAIのCEOサム・アルトマンが社内で「コード・レッド」と呼んだ状況を引き起こし、GPT Image 1.5のリリースを加速させる要因となりました。
- 風景写真などのシナリオにおいて、よりフォトリアルな出力。
- 最新の美的トレンドをより捉えている。
- 複雑な自然シーン(風景、群衆)の処理に優れている。
- ユーザーベースの急速な拡大(Geminiユーザーは2025年7月から10月の間に4.5億人から6.5億人に増加)。
- 構造化されたプロンプトに対する指示追従性がより高い。
- レイアウトやデザインにおけるテキスト描写がより優れている。
- 反復的な編集作業において、細部の維持能力が高い。
- 商用ワークフローにおいて、より予測可能で決定論的な結果が得られる。
GPT Image 1.5 vs Midjourney
Midjourneyは、その独特の芸術的な質感から、デジタルアーティストやクリエイティブプロフェッショナルの間で依然として根強い人気があります。
- 芸術的な解釈と独創的な「ビジョン」。
- 強力なコミュニティと確立されたプロンプトエンジニアリングのリソース。
- 多様なスタイルにおける一貫した美的品質。
- 抽象的、概念的、芸術的な構図に最適。
- ChatGPTワークフローに統合されている(プラットフォーム移動が不要)。
- 商用アプリケーションにおいて反復速度が速い。
- 自動化ワークフローのためのAPIアクセス。
- ビジネスニーズに対して、より予測可能な出力。
GPT Image 1.5 vs DALL-E 3
GPT Imageシリーズ以前のOpenAIのフラッグシップモデルであったDALL-E 3は、現在では旧式となっており、2026年5月12日にサポートが終了します。
- 生成速度が大幅に向上。
- API統合能力の改善。
- 指示追従性の向上。
- 手動マスク不要の高度な編集精度。
- 運用コストの削減。
競合ポジショニング・サマリー
| モデル | 最適な用途 | 避けるべき用途 | 価格帯 |
|---|---|---|---|
| GPT Image 1.5 | 商用ワークフロー、ブランド資産、反復編集 | 純粋な芸術プロジェクト | ミドルレンジ |
| Nano Banana Pro | フォトリアルなSNS画像、現代的な美学 | 正確なテキスト描写、ロゴ制作 | ミドルレンジ |
| Midjourney | 芸術的解釈、コンセプチュアルな作業 | 自動化されたAPIワークフロー | プレミアム(予算重視) |
| Stable Diffusion | カスタムモデルのトレーニング、フルコントロール | そのまま使えるソリューション | 無料〜低価格 |

アクセス方法:ChatGPTインターフェースガイド
2025年12月16日に世界中で展開されたGPT Image 1.5は、Free、Plus、Team、Enterpriseのすべてのサブスクリプション層で利用可能です。
ChatGPT経由のステップ・バイ・ステップ
- ChatGPT画像機能へ移動
- chat.openai.com でアカウントにログインします。
- 左側のサイドバーにある「Images」タブをクリックします(2025年12月のアップデートで追加)。
- これにより、画像生成専用のインターフェースが開きます。
- 最初の画像を生成する
- 記述的なプロンプト(最大2000文字)を入力フィールドに入力します。
- 「生成」をクリックするか、Enterキーを押します。
- 生成されるまで8〜18秒待ちます。
- モデルは自動的に GPT Image 1.5 を使用します。手動で選択する必要はありません。
- Creative Studio(クリエイティブ・スタジオ)機能の使用
- 生成後、右側のサイドバーにプリセットのスタイルとフィルターが表示されます。
- プロンプトを書かずにプリセットをクリックするだけで変換を適用できます。
- オプションには以下が含まれます:「フォトリアルにする」、「夕日の照明に変える」、「ドラマチックな影を追加」、「プロの商品写真スタイル」。
- これらのプリセットは、特に非技術系のユーザーにとって便利です。
- 反復的な編集ワークフロー
- 以前に生成された画像を選択します。
- 自然言語で編集指示を入力します:「背景をビーチの風景に変えて」。
- モデルは指定されていない要素を維持しつつ、要求された変更のみを適用します。
- 品質の劣化が目に見えて現れるまで、6〜8回の編集を重ねることができます。
- ダウンロードとエクスポート
- 生成された画像のダウンロードアイコンをクリックします。
- 画像はネイティブ解像度(1024×1024、1024×1536、1536×1024)でエクスポートされます。
- リンクは24時間有効です(重要な画像はすぐに保存してください)。
- 画像にはコンテンツ認証用のC2PAメタデータが含まれます。
インターフェースの機能と制限
- テキストから画像への生成(Text-to-Image)。
- 画像から画像への変換(参照画像のアップロード)。
- 自然言語による編集(エディティング)。
- プリセットスタイルの適用。
- アスペクト比の選択(1:1, 3:4, 4:3)。
- 品質レベルの選択(ChatGPTは常に
autoを使用)。 - 複数バリエーションの一括生成(Batch Generation)。
- 外部URLからの画像ファイルの直接アップロード。
- カスタムモデルパラメータの調整。
- 非同期処理のためのWebhookコールバック。
ChatGPTインターフェースユーザーへのプロアドバイス
- 会話のコンテキスト活用: ChatGPT内のGPT Image 1.5は、同じ会話内の以前の画像やプロンプトを記憶しています。「前の画像」や「青いジャケットのバージョン」といった指定が可能です。
- テキストチャットと画像生成の組み合わせ: 生成前にChatGPTにプロンプトのアイデア出しを依頼したり、記述を洗練させたりしてもらうことで、AIのテキスト能力を活かして視覚的なプロンプトを向上させることができます。
- 成功したプロンプトの保存: 成功したプロンプトをドキュメントにまとめておきましょう。一貫したプロンプト構造は、一貫した品質につながります。
- 元に戻す(Undo)機能の活用: 編集がうまくいかない場合は、前のバージョンに戻って別の指示を試すことができます。
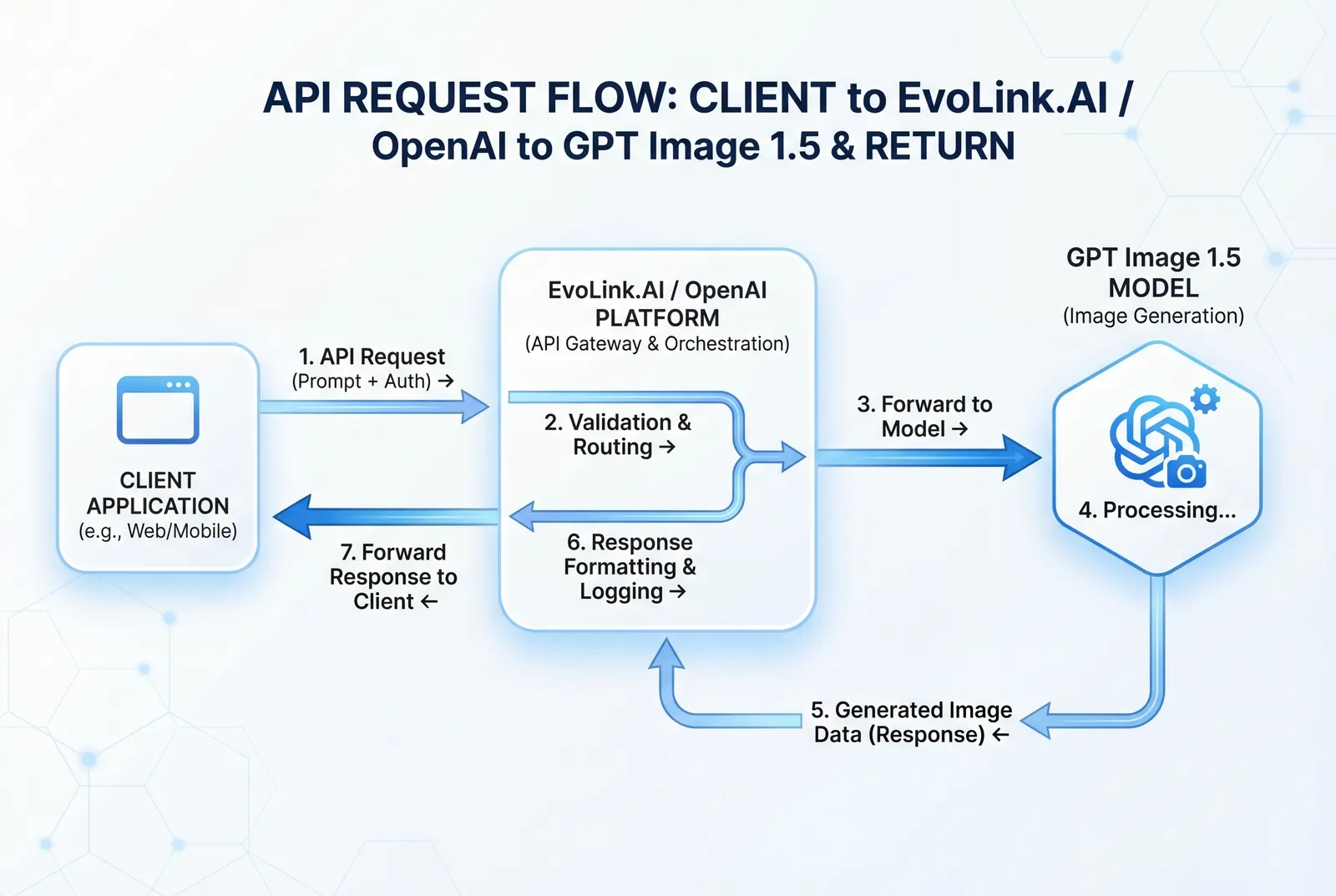
APIアクセス:EvoLink.AIとOpenAIプラットフォーム経由
開発者、自動化ワークフロー、および大量の画像を生成する場合、APIアクセスによる GPT Image 1.5 のプログラム制御が有効です。
EvoLink.AI APIの統合
gpt-image-1.5-lite エンドポイントを介して GPT Image 1.5 へのAPIアクセスを提供しています。基本的なAPIリクエスト構造 (EvoLink.AI)
{
"model": "gpt-image-1.5-lite",
"prompt": "清潔な白背景の上に置かれたスマートフォンのプロ級の商品写真、柔らかなスタジオ照明",
"size": "1024x1024",
"quality": "high",
"n": 1
}必須パラメータ
- model: GPT Image 1.5の場合は
"gpt-image-1.5-lite"を指定。 - prompt: テキストによる記述(最大2000トークン)。
- size: 画像の寸法(オプション:
1:1,3:4,4:3,1024x1024,1024x1536,1536x1024)。
オプションパラメータ
- quality:
low,medium,high, またはauto(デフォルトはauto)。 - image_urls: 画像から画像(Image-to-Image)や編集モード用の参照画像URLの配列(1〜16枚、1枚あたり最大50MB、フォーマット:.jpeg, .jpg, .png, .webp)。
- n: 生成枚数(現在は
1のみサポート)。
非同期処理
- 生成リクエストを送信 → タスクIDを受け取る。
- タスクステータスエンドポイントをタスクIDでポーリング。
- ステータスが "completed" になったら生成された画像URLを取得。
- 画像URLは24時間有効です。
OpenAIプラットフォーム経由の直接APIアクセス
/v1/images/generations エンドポイントを介してアクセスを提供します。認証設定
- platform.openai.com でアカウントを作成します。
- API組織の確認を完了します(GPT Imageモデルに必要)。
- ダッシュボードでAPIキーを生成します。
- リクエストヘッダーにキーを含めます:
Authorization: Bearer YOUR_API_KEY。
リクエスト例 (OpenAI Python SDK)
from openai import OpenAI
client = OpenAI(api_key="your-api-key")
response = client.images.generate(
model="gpt-image-1.5",
prompt="大きな窓から自然光が差し込む、ミニマリストなモダンリビングルーム",
size="1536x1024",
quality="high",
n=1
)
image_url = response.data[0].url画像編集モード
既存の画像を編集する場合:
response = client.images.edit(
model="gpt-image-1.5",
image=open("input_image.png", "rb"),
prompt="壁の色をセージグリーンに変更して",
size="1024x1024"
)API比較:EvoLink.AI vs OpenAI公式サイト
| 特徴 | EvoLink.AI | OpenAI Direct |
|---|---|---|
| モデル名 | gpt-image-1.5-lite | gpt-image-1.5 |
| 処理方式 | 非同期 (タスクベース) | 同期 + 非同期の選択肢 |
| 画像入力 | URLベースのみ | ファイルアップロード + URL |
| 料金の透明性 | EvoLink.AI ダッシュボードを確認 | 公開されているOpenAI価格 |
| 付加サービス | 他のAI APIとのセット | 画像生成単体 |
| ドキュメント | evolink.ai ドキュメント | platform.openai.com/docs |
| レート制限 | プランにより変動 | ティア (Tier) ベース |
API活用のベストプラクティス
- リトライロジックの実装: 負荷のピーク時には一時的なエラーが発生することがあります。
- 成功した生成結果のキャッシュ: 画像URLと関連するプロンプトを後で参照できるように保存してください。
- レート制限の監視: 両プラットフォームとも、サブスクリプション層に基づいたリクエスト制限があります。
- プロンプトテンプレートの最適化: 一貫した結果を得るために、再利用可能なプロンプト構造を作成してください。
- 画像の有効期限管理: 24時間の有効期間内に画像をダウンロードして保存してください。
- 品質レベルの戦略的活用: コストを抑えるため、最終的な本番用レンダリング以外では
high品質の使用を控えてください。
料金体系とコスト最適化戦略
コスト構造を理解することで、効果的な予算計画と最適化が可能になります。
OpenAI公式価格 (2025年12月時点)
- 画像生成: サイズと品質レベルに基づきます。
- 画像入力(編集用): GPT Image 1と比較して20%安価。
- 画像出力: GPT Image 1と比較して20%安価。
EvoLink.AI の価格
- サブスクリプションティア(含まれるAPIコール数により変動)。
- 含まれるクォータを超えた場合のリクエストごとの料金。
- 法人顧客向けのボリュームディスカウント(応相談)。
コスト最適化戦略
1. 品質レベルの選択
quality パラメータは生成時間とコストに大きく影響します。Low (低品質): 高速、安価(コンセプトの試作に最適)
Medium (中品質): バランス型(ほとんどの用途に適している)
High (高品質): 低速、高価(本番用アセットに)
Auto (自動): プロンプトの複雑さに基づいてモデルが決定2. アスペクト比の最適化
大きな画像ほど生成コストが高くなります。コストの階層は以下の通りです。
1024×1024 (1:1) < 1024×1536 (3:4) = 1536×1024 (4:3)3. バッチ処理 vs リアルタイム
非緊急のワークフローの場合:
- 複数の生成リクエストをキューに入れます。
- オフピークの時間帯にまとめて処理します。
- タイムアウトによる再実行を避けるために非同期処理を使用してください。
4. プロンプトの効率化
長いプロンプトほど多くのトークンを消費します。最適化のテクニック:
- 不要な形容詞を省く。
- 箇条書きのような構造化フォーマットを使用する(カンマ区切りの属性指定)。
- 冗長な説明を避ける。
- 最小実行可能なプロンプトをテストする。
変換例:
非効率 (87トークン): 「清潔で汚れのない純白の背景に置かれた、現代的なスマートフォンの、
美しく、素晴らしく、驚くべきプロフェッショナルな写真を、
上部からの優雅で柔らかなスタジオ照明で作成してください。」
効率的 (25トークン): 「プロの商品写真:スマートフォンの白背景、上部からの柔らかなスタジオ照明」5. キャッシュと再利用
- 成功した生成結果(プロンプト、パラメータ、タイムスタンプ)を保存します。
- ゼロから生成する代わりに、将来の編集のためにベース画像のライブラリを作成します。
- 画像キャッシュに対してセマンティック検索を実装し、新しく生成する前に既存の資産がないか確認してください。
6. ハイブリッドワークフロー
AI生成と従来のツールを組み合わせます。
- AIでベースとなる画像を生成。
- Figma/Photoshopで複雑なテキストやロゴを追加(AIのテキスト制限を回避するため)。
- ゼロから作るのではなく、実績のあるデザインのバリエーション制作にAIを活用する。
- すべてAIワークフロー: 10回の反復 × /usr/bin/bash.XX (1枚あたり) = ,XX (合計)
- ハイブリッドワークフロー: 3回のAI反復 + 手動修正 = ,XX + デザイン時間
- デザイン時間がAI反復7回分より短ければ、ハイブリッドアプローチの方がコストを抑えられます。
法人向けボリュームディスカウント
- 月間10,000枚以上の画像生成。
- 月間,000以上のAPI支出。
- 数年間の契約コミットメント。
実際のユースケースと活用事例
様々な業界がどのように GPT Image 1.5 を適用しているかを理解することで、その実用的な価値が明確になります。
Eコマースの商品カタログ
- ニュートラルな背景で商品を一度だけ撮影する。
- 画像から画像への(Image-to-Image)モードを使用して、様々な環境でのバリエーションを生成。
- 細部維持機能により、商品の外観の一貫性が保たれる。
- すべてのバリエーションにおいて、ブランドロゴとアイデンティティが維持される。
マーケティングおよびブランド資産
- ブランドカラーとスタイルを使用したベースデザインを生成。
- ロゴと視覚的アイデンティティを維持しながら編集を繰り返す。
- A/Bテスト用のバリエーションを迅速に作成。
- 異なる市場に合わせてローカライズされたバージョンを制作。
SNSコンテンツ制作
- 必要な最大サイズでマスター画像を生成。
- 各プラットフォーム固有のクロップ(切り抜き)またはバリエーションを作成。
- 各チャネルに適した美学に合わせてスタイルフィルターを適用。
- テキストオーバーレイを追加(またはAIによるテキスト描写で見出しを生成)。
- Instagram (1:1): 1024×1024
- Instagram Stories (3:4): 1024×1536
- Twitter/X (4:3): 1536×1024
- すべて1つのプロンプトからサイズパラメータを変更するだけで生成。
デザインコンセプトの可視化
- 視覚的なコンセプトを次々とプロトタイプ制作。
- 複数のスタイル方向性をテスト。
- オプションに対するフィードバックを収集。
- 選ばれた方向性をプロダクション品質まで洗練させる。
編集および出版
- 抽象的なトピックに対する概念的なイラストを生成。
- 読みやすいテキストラベルを含むデータビジュアライゼーションを作成。
- 見出しを含む雑誌スタイルのレイアウトを制作。
- 一連の記事を通じて一貫した視覚テーマを構築。
トレーニングおよび教育資料
- シナリオベースのイラスト(職場での状況、安全デモンストレーションなど)を生成。
- 簡略化された図やフローチャートを作成。
- トレーニング資料における多様な表現を確保。
- 特定の学習コンテキストに合わせたカスタムビジュアルを開発。
不動産および建築
- 空室の写真から家具配置後の内装を生成。
- リノベーションのコンセプトを可視化。
- 不動産マーケティング用のライフスタイル画像を制作。
- クライアントが選択できる複数のデザインスタイルオプションを提示。
高度なプロンプトエンジニアリング
プロンプト構造をマスターすることで、出力品質が劇的に向上し、反復回数を減らすことができます。
効果的なプロンプトの解剖学
パフォーマンスの高いプロンプトは以下の構造に従います。
[主語(Subject)] + [アクション/ポーズ] + [設定/文脈] + [スタイル/美学] +
[技術仕様] + [構図ルール]主語: 紺色のスーツを着たプロフェッショナルなビジネスウーマン
アクション: 腕を組んで自信を持って立っている
設定: 窓から都市のスカイラインが見えるモダンなガラス張りのオフィス
スタイル: プロフェッショナルな企業写真の美学
技術仕様: 浅い被写界深度、左側からの自然な窓の光
構図: 主語を画像の右1/3に配置、左側にネガティブスペース一般的なシナリオのプロンプト形式
商品写真
「[商品名] のプロフェッショナルな商品写真、背景は [背景の説明]、
[照明スタイル]、[カメラアングル]、[雰囲気]、高級な広告品質」例: 「高級時計のプロフェッショナルな商品写真、背景は黒の大理石、柔らかな影を伴うドラマチックなサイドライティング、45度の角度、エレガントで高級な雰囲気、プレミアムな広告品質」
ポートレート写真
「[ショットの種類] [被写体の詳細な説明] のポートレート、[表情]、
[服装]、[背景]、[照明]、[カメラ設定スタイル]」例: 「短いグレーヘアの50代女性のクローズアップ・ポートレート、自然な笑顔、カジュアルなデニムジャケットを着用、背景は屋外のボケ、ゴールデンアワーの自然光、浅い被写界深度」
ライフスタイルシーン
「[時間帯] [場所] で [活動] をしている様子を捉えたシーン、
[気分/雰囲気]、[人物の説明]、[スタイルリファレンス]」例: 「現代的なスカンジナビアスタイルのキッチンで家族が朝食を食べている朝のシーン、暖かく居心地の良い雰囲気、多様な4人家族、自然なライフスタイル写真スタイル」
インフォグラフィック/データ可視化
「[データ/コンセプト] を示す明確なインフォグラフィック、[レイアウト]、
[配色]、[テキスト要素]、プロフェッショナルなデザイン品質」例: 「四半期の売上成長を示す明確なインフォグラフィック、垂直棒グラフのレイアウト、青と白の配色、上部に太字の見出しで『2025 Q4 結果』と記載、成長率のラベル付き、プロフェッショナルなビジネスデザイン品質」
ネガティブプロンプトの戦略
GPT Image 1.5 は Stable Diffusion のように公式にはネガティブプロンプトをサポートしていませんが、肯定的な表現を使用することで不要な要素を避けることができます。
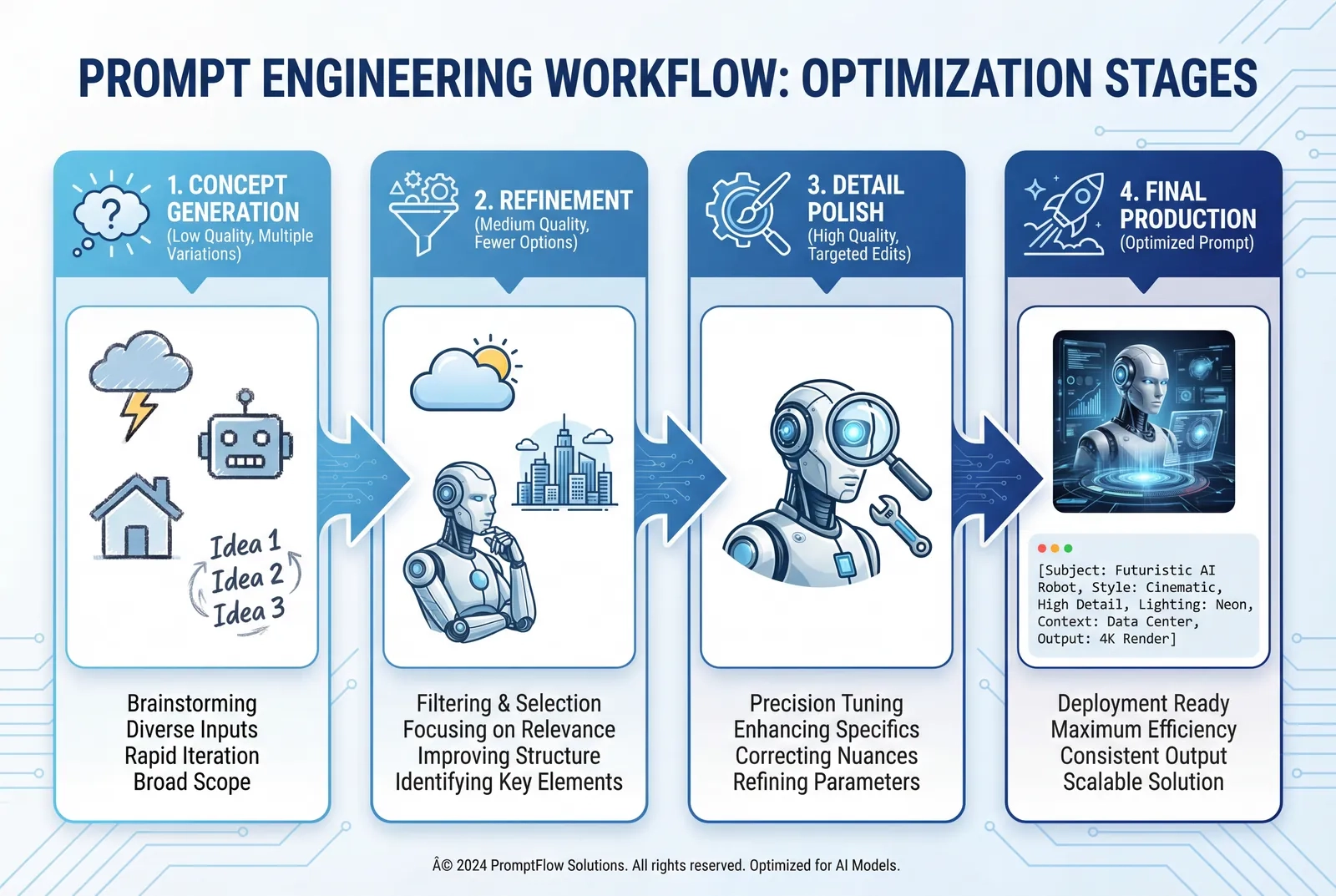
多段階リファインメント(洗練)のワークフロー
高い品質が求められる複雑なプロジェクトの場合:
- 初期コンセプト生成 (Low品質、大まかなプロンプト)
- 3〜5つのバリエーションを生成。
- 有望な方向性を特定。
- リファインメント・イテレーション (Medium品質、詳細なプロンプト)
- 選ばれたコンセプトに具体的な制約を追加。
- 構図、照明、要素を調整。
- 2〜3つのバリエーションをテスト。
- ディテールの磨き上げ (High品質、精密な編集プロンプト)
- 最終形に近いバージョンに対して、ターゲットを絞った編集を適用。
- 特定の要素を一つずつ調整。
- 変更箇所部以外のすべてを維持。
- 最終制作 (High品質)
- すべての知見を統合した最適化プロンプトで画像を再生成。
- フル解像度でエクスポート。
プロンプトライブラリとバージョン管理
構造化されたプロンプトライブラリを維持しましょう。
プロジェクト: 2025年ホリデーキャンペーン
バージョン: 1.0
日付: 2025年12月
基本プロンプト・テンプレート:
「[主語] を描いたお祝いのホリデーシーン、暖かく居心地の良い雰囲気、
ゴールデンライティング、プロフェッショナルな写真、[特定の要素]」
バリエーション:
V1.0: 初期コンセプト → 「浅い被写界深度」を追加
V1.1: クライアントフィードバック → 「暖かい居心地の良い」から「明るく楽しい」へ変更
V1.2: 最終バージョン → 「赤と金のアクセントカラー」を追加
採用プロンプト: [最適化された最終バージョン]
生成画像: [保存された結果へのリンク]このドキュメント化により、成功した構成を再発明する手間を省き、チームでの共同作業を可能にします。
GPT Image 1.5 を使用する際の一般的ミス
典型的な落とし穴から学ぶことで、ツールの習得を早め、無駄な労力を防ぐことができます。
1. 曖昧で構造化されていないプロンプト
2. 最初から完璧なテキスト描写を期待する
3. 品質レベルの影響を無視する
4. モデルの限界を超えた過度な編集
5. 成功したプロンプトを保存しない
6. 参照画像の準備不足
- 高解像度(長辺が1024px以上)。
- 照明が良く、被写体にピントが合っている。
- 余計な要素のないクリーンな構図。
- 正しい形式(.jpg, .png, .webp)。
7. 建築的・技術的な正確さを期待する
8. 画像の有効期限を軽視する
9. プロジェクト間でプロンプト構造に一貫性がない
10. 競合モデルをテストしない
限界と代替ツールの選び方
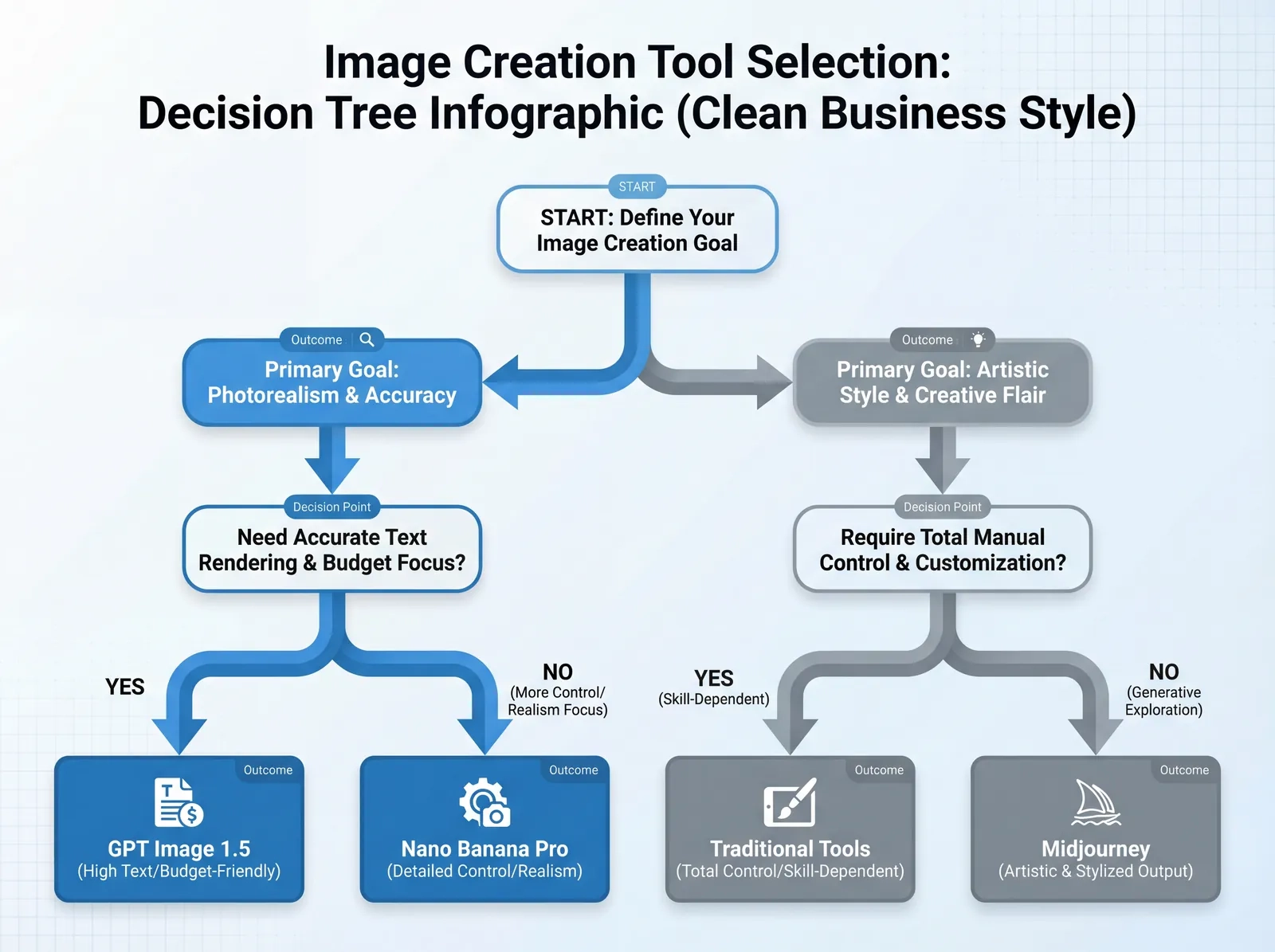
GPT Image 1.5 は大きな飛躍ですが、あらゆる状況で最適というわけではありません。限界を理解することが、適切な選択につながります。
技術的な制限
- 複雑なシーンの整合性
- 10個以上の個別のオブジェクトがある画像では、空間的な不整合が生じることがあります。
- 重なり合った透明要素(ガラス、水)はノイズを生じさせます。
- 多くの人が写るシーンでは、群衆の中での解剖学的な正確さに苦労します。
- 影響を受ける用途: 大人数の集合写真、複雑な商品の配置、詳細なイラスト。
- 写真のリアリズムの天井
- 一部の出力には依然として「AI特有の質感」(過度な滑らかさ、不自然な完璧さ)が残ります。
- 肌の質感や毛穴の詳細が不自然に見えることがあります。
- 過酷な直射日光や複雑な反射を伴う特定の照明シナリオは、依然として課題です。
- 影響を受ける用途: ハイエンドなファッション写真、ドキュメンタリー作品、写実的な肖像画。
- テキスト描写の壁
- 20〜30単語を超えるテキストにはエラーが含まれます。
- 非ラテン文字は信頼性が低いです。
- 装飾的または手書きのフォントは不整合が生じます。
- 曲面上のテキストは歪みます。
- 影響を受ける用途: 大量のテキストを含むインフォグラフィック、多言語コンテンツ、装飾的タイポグラフィ。
- 文化的・地理的な特異性
- トレーニングデータが欧米の文脈に偏っているようです [未検証 - 結果分析からの推測]。
- 地域の建築、服装、文化的な詳細に真正性が欠ける場合があります。
- ニッチなサブカルチャーや専門的なコンテキストの表現が不十分な場合があります。
- 影響を受ける用途: 特定の文化向けのマーケティング、地域限定キャンペーン、本物の表現が必要な場面。
- 反復耐久性の限界
- 6〜8回連続で編集を重ねると、品質が低下します。
- 蓄積されたノイズが反復ごとに増幅されます。
- 過度な反復により、顔やロゴの一貫性が失われます。
- 影響を受ける用途: 10回以上の洗練サイクルや広範な共同編集が必要なプロジェクト。
代替ツールの選び方
Google Nano Banana Pro を選ぶべき場合:
- 写真のような写実性(フォトリアリズム)が最優先事項である場合。
- 現代的な美的トレンドを反映させる必要があるSNSコンテンツの場合。
- 自然なシーン(風景、群衆、イベント)が主なニーズである場合。
- チームの導入のしやすさにおいて、急速なエコシステムの拡大を重視する場合。
Midjourney を選ぶべき場合:
- 事実に基づいた正確さよりも、芸術的な解釈が価値を生む場合。
- 概念的、抽象的、または様式化された作品がブランドに合致する場合。
- コミュニティ主導のプロンプトライブラリやスタイルをワークフローに活かしたい場合。
- 制作管理よりもクリエイティブなビジョンが重要な場合。
Stable Diffusion を選ぶべき場合:
- モデルのトレーニングやカスタマイズを完全にコントロールする必要がある場合。
- 予算の制約から、無料またはオープンソースのソリューションを求める場合。
- 技術チームが自社運用(セルフホスティング)と最適化を管理できる場合。
- ニッチな用途のために特定の微調整(Fine-tuning)が必要な場合。
既存の写真・デザインサービスを選ぶべき場合:
- 技術的な正確さが不可欠な場合(建築、エンジニアリング、医療)。
- 人間が作成した真正なコンテンツであることを法的に証明する必要がある場合。
- AI支援よりも人間の手による技術をブランド価値として重視する場合。
- 予算に余裕があり、品質がコストを正当化できる場合。
ハイブリッドワークフローを選ぶべき場合:
- AIの効率性と人間の品質管理の両方が必要なプロジェクト。
- テキスト要素がAIの能力を超えている場合。
- ブランドガイドラインにより、絶対的な一貫性が求められる場合。
- コンプライアンスや真正性の検証が重要な場合。
倫理的および法的な考慮事項
よくある質問 (FAQ)
1. デザイナーを雇うのと比べて、GPT Image 1.5 のコストはどのくらいですか?
しかし、デザイナーはクリエイティブなディレクション、ブランドへの理解、およびAIでは及ばない技術的な精度を提供します。多くの企業にとって最適なアプローチは、ハイブリッドモデルです。リスクの低い大量のコンテンツ(SNS投稿、コンセプトテスト、ストックフォト風の画像)にはAIを使用し、デザイナーの時間はフラッグシップキャンペーンやブランドを象徴する作品、人間のクリエイティブなビジョンを必要とするプロジェクトのために確保しましょう。
2. GPT Image 1.5 は、複数の画像間でキャラクターの容姿を一定に保つことができますか?
- 詳細な説明を使って初期のキャラクター画像を生成する。
- その画像をキャラクターのリファレンスとして保存する。
- 以降の生成では、そのリファレンスを使用して画像から画像(Image-to-Image)モードを利用する。
- キャラクターを説明する一貫したプロンプト構造を維持する。
- 多少の変動は発生することを受け入れる: 全く新しい生成における完璧な一貫性は、まだ完全に信頼できるものではありません。
絶対的なキャラクターの一貫性が求められるプロジェクト(アニメシリーズ、ブランドマスコット、現在進行中のキャンペーンなど)では、AIを初期コンセプトの作成に使用し、その後、将来のすべての作業の基準となる定義済みのモデルシートをイラストレーターに作成してもらうことを検討してください。
3. GPT Image 1.5 は英語以外の言語で作動しますか?
- スペイン語、フランス語、ドイツ語、イタリア語: 一般的に動作しますが、英語に比べると精度が多少低下する場合があります。
- CJK言語(中国語、日本語、韓国語): プロンプトの理解は可能ですが、画像内のテキスト描写は依然として信頼性が低いです。
- その他の言語: 限られたテストデータのみが利用可能です [未検証]。
4. GPT Image 1.5 は、生成された画像の著作権と知的財産権をどのように扱いますか?
- 第三者の知的財産: 著作権のあるキャラクター、登録商標されたロゴ、または特定の著名人の容姿に基づくコンテンツの生成を拒否するように設計されています。
- トレーニングデータ: モデルは公開されている画像でトレーニングされており、そこには教育目的のフェアユース(公正利用)の法理に基づいて使用された著作物が含まれている可能性があります。
- 商用利用: 一般的に商用利用が可能ですが、OpenAI の最新の規約と、自身の具体的なユースケースを確認してください。
- 帰属(クレジット表示): OpenAI は AI 生成画像に対するクレジット表示を義務付けていませんが、一部のプラットフォームや文脈では、AI生成物であることを開示する必要がある場合があります。
5. 自身が所有する既存の写真を編集するために GPT Image 1.5 を使えますか?
- 自身の写真をアップロードする。
- 自然言語のプロンプトで特定の修正を依頼する。
- 指定した特徴を変更しつつ、元の要素を維持する。
- 既存の画像のバリエーションを生成する。
- 元の写真が高品質(1024px以上)である。
- 照明が良く、被写体がはっきりしている。
- 背景が過度に複雑でない。
- 編集依頼が具体的で限定的である。
6. GPT Image 1.5 と GPT Image 1.5 Lite の違いは何ですか?
gpt-image-1.5-lite) は、evolink.ai などのプラットフォームで使用されている API モデルの呼称です。利用可能なドキュメントによれば、"Lite" は機能が制限されたバージョンを指すのではなく、API エンドポイントの名前を指しているようです。このエンドポイントからアクセスできるモデルは、ChatGPT で利用可能なフラッグシップモデル GPT Image 1.5 と同一であると考えられます。一部のプラットフォームでは、追加の品質レベルやパラメータオプションを「Lite」対「Full」として提供している場合がありますが、OpenAI の公式名称はシンプルに「GPT Image 1.5」です。プラットフォームの実装によるコストや機能の差異については、各 API プロバイダーのドキュメントを確認してください。
7. 生成された画像 URL の有効期限はどのくらいですか?どのように保存すべきですか?
- 即時ダウンロード: 生成直後に画像を取得できるように、ワークフロー内で自動ダウンロードを設定してください。
- クラウドストレージ: 永続的に保存するために、自身の S3 や Google Cloud Storage などへアップロードしてください。
- メタデータの保持: 将来の参照のために、各画像に関連するプロンプト、パラメータ、および生成日時を保存しておきましょう。
- 命名規則: プロジェクトIDやバージョン番号を含む、検索可能な説明的なファイル名を使用してください。
- バックアップ戦略: 重要なビジネス資産については、冗長なコピーを保持してください。
1. 画像を生成 → 一時的な URL を受け取る
2. 1時間以内に画像をローカルまたはクラウドストレージにダウンロードする
3. 自身のデータベースに永続的な URL を保存する
4. 自身のリポジトリから OpenAI の一時 URL を削除する
5. 将来は自身の永続ストレージ URL を参照する8. GPT Image 1.5 は印刷に適した画像を生成できますか?それともデジタル専用ですか?
- 1024×1024 ピクセル (正方形)
- 1024×1536 ピクセル (ポートレート)
- 1536×1024 ピクセル (ランドスケープ)
| 印刷サイズ | 必要 DPI | 理想の解像度 | GPT Image 1.5 でOK? |
|---|---|---|---|
| SNS投稿 | 72 DPI | 1200×1200 | ✓ はい |
| ウェブサイトヒーロー | 72-96 DPI | 1920×1080 | ✓ はい |
| プレゼン資料 | 96-150 DPI | 1920×1080 | ✓ はい |
| 名刺 | 300 DPI | 1050×600 | ⚠️ 限界 |
| 8x10インチ写真 | 300 DPI | 2400×3000 | ✗ いいえ |
| 雑誌1ページ | 300 DPI | 2550×3300 | ✗ いいえ |
| 屋外ビルボード | 150 DPI+ | 14400×4800+ | ✗ いいえ |
- AIアップスケール: 生成後に解像度を上げるための専用アップスケーリングツール(Topaz Gigapixel, Real-ESRGANなど)を使用してください。
- 印刷サイズの制限: AI生成画像は、ページ全体ではなく、小さな要素(アイコン、スポットイラスト)としてのみ使用しましょう。
- デジタルファースト戦略: デジタルチャネルにはAI生成を優先し、印刷キャンペーンには従来の写真やイラストを起用してください。
- ベクター変換: ロゴやシンプルなグラフィックは、解像度に依存せずに使用できるようにベクター形式に変換してください。
9. プロのデザイン作業において GPT Image 1.5 は Midjourney よりも優れていますか?
- 反復的な編集において精密なコントロールが必要な場合。
- ChatGPT との共同ワークフローがチームにとって有意義な場合。
- 画像内のテキスト描写が重要である場合。
- API による自動化が必要な場合。
- ロゴやブランド要素の維持が不可欠である場合。
- 芸術的な品質を多少妥協しても、スピード(4倍速)を優先する場合。
- 法人向け機能やサポートが重要である場合。
- 芸術的な解釈が作品の質を高める場合。
- 美的品質が最優先事項である場合。
- コミュニティのプロンプトライブラリやスタイルがブランドに合う場合。
- コンセプトアート、イラスト、または独創的なキャンペーンを作成する場合。
- Discord ベースのワークフローがチーム体制に馴染む場合。
- 予算に応じたソリューションが必要な場合。
- ヒーロー画像、バナー、目玉となるクリエイティブには Midjourney を使用。
- 商品バリエーション、SNSコンテンツ、反復的なクライアント確認用には GPT Image 1.5 を使用。
- 最終的な仕上げや技術的な要件には従来のデザイン手法を適用。
10. 1.5 が利用可能になった今、GPT Image 1 はどうなりますか?
- 優れたパフォーマンス(4倍速の生成)。
- 指示追従性の向上。
- 高度な編集精度。
- 入出力コストの20%削減。
- 継続的な開発と改善。


