
Guide du développeur pour l'API d'inférence Hugging Face

Qu'est-ce que l'API d'inférence Hugging Face ?

Essentiellement, l'API d'inférence Hugging Face est un service qui vous permet d'exécuter des modèles d'apprentissage automatique hébergés sur le Hugging Face Hub via des appels API simples. Elle élimine complètement les complexités liées au déploiement de modèles, comme la gestion des GPU, la configuration des serveurs et la mise à l'échelle. Au lieu de provisionner vos propres serveurs, vous envoyez des données au point de terminaison (endpoint) d'un modèle et recevez des prédictions en retour.
Pour vous donner une image plus claire, voici un bref aperçu de ce que l'API propose.
Aperçu de l'API d'inférence Hugging Face
Ce tableau résume les fonctionnalités clés et les avantages de l'utilisation de l'API d'inférence Hugging Face pour divers besoins de développement.
| Fonctionnalité | Description | Avantage principal |
|---|---|---|
| Inférence sans serveur | Exécutez des modèles via des appels API sans gérer de serveurs, de GPU ou d'infrastructure. | Zéro surcharge d'infrastructure : Libère du temps d'ingénierie pour se concentrer sur les fonctionnalités. |
| Accès à un vaste Hub de modèles | Utilisez instantanément n'importe lequel des plus de 1 000 000 de modèles du Hub pour diverses tâches. | Flexibilité inégalée : Changez facilement de modèle pour trouver le meilleur pour votre cas d'utilisation. |
| Interface HTTP simple | Interagissez avec des modèles d'IA complexes à l'aide de requêtes HTTP standards et documentées. | Prototypage rapide : Créez et testez des preuves de concept basées sur l'IA en quelques minutes. |
| Tarification à l'usage | Vous ne payez que pour le temps de calcul utilisé, ce qui est rentable pour l'expérimentation. | Efficacité des coûts : Évite les coûts fixes élevés de maintenance d'une infrastructure ML dédiée. |
En fin de compte, l'API est conçue pour vous faire passer du concept à une fonctionnalité d'IA fonctionnelle avec le moins de friction possible.
Avantages clés pour les développeurs
L'API est clairement conçue pour l'efficacité des développeurs, offrant quelques avantages clés qui en font une solution de choix pour de nombreux projets.
- Zéro gestion d'infrastructure : Oubliez le provisionnement de GPU, les problèmes de pilotes CUDA ou l'évolutivité des serveurs. L'API gère toute la lourdeur du backend.
- Sélection massive de modèles : Avec un accès direct au Hub, vous pouvez basculer instantanément entre des modèles pour des tâches telles que l'analyse de sentiment, la génération de texte ou le traitement d'images simplement en changeant un paramètre dans votre appel API.
- Prototypage rapide : La facilité d'utilisation vous permet de construire une preuve de concept pour une fonctionnalité d'IA en un seul après-midi.
Authentification et premier appel API
Authorization de chaque requête. Cela indique aux serveurs de Hugging Face que vous êtes un utilisateur légitime avec la permission d'exécuter le modèle que vous appelez. Le processus est simple mais crucial : obtenir le jeton, le placer dans l'en-tête et effectuer l'appel.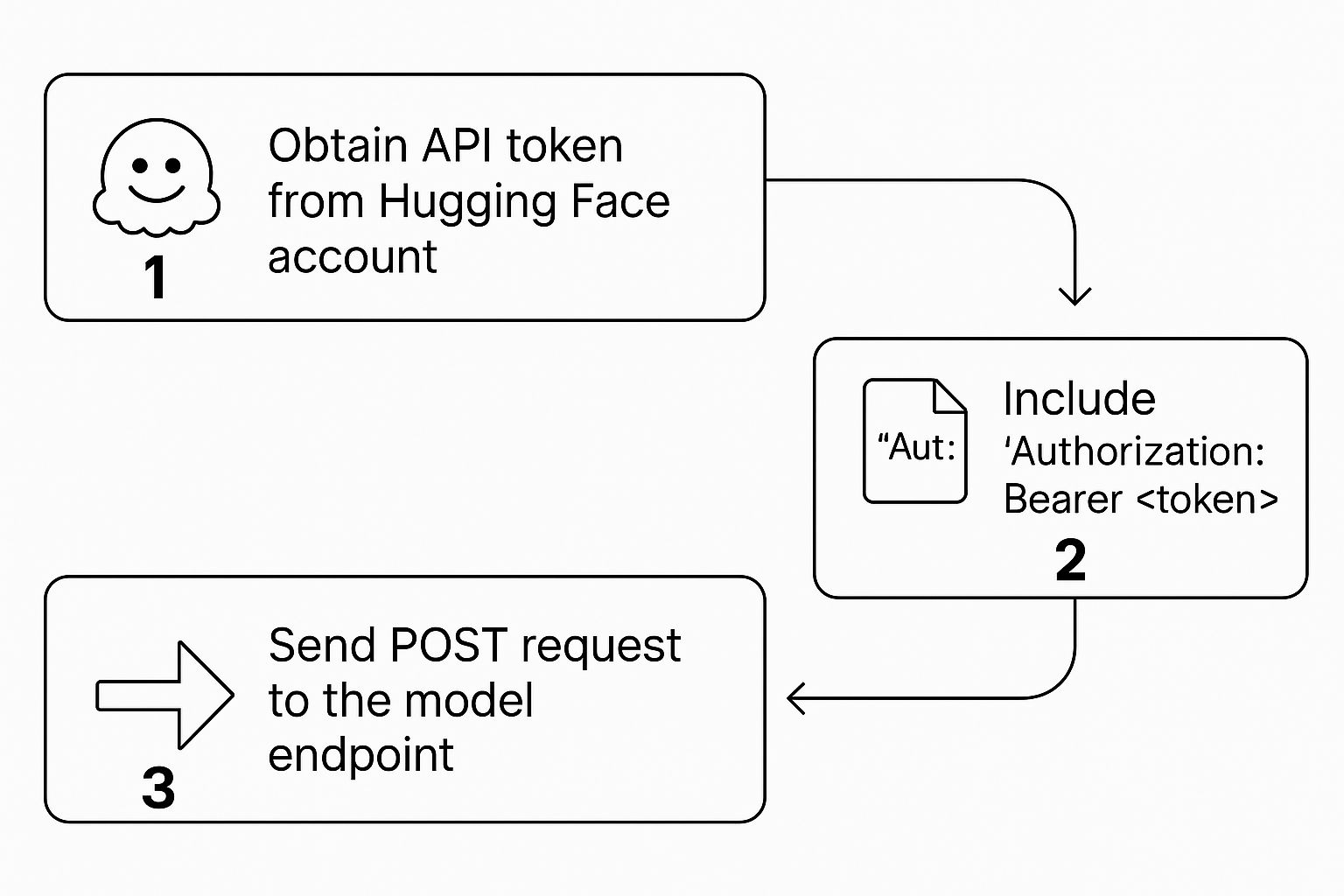
Une fois votre jeton généré, il s'agit de structurer correctement la requête pour s'assurer que tout se déroule de manière fluide et sécurisée.
Votre premier appel API en Python
requests. Les composants clés sont l'URL de l'API spécifique au modèle et un corps JSON correctement formaté avec votre texte d'entrée. L'en-tête Authorization doit utiliser le schéma "Bearer", standard pour les API modernes. Préfixez simplement votre jeton par Bearer — n'oubliez pas l'espace."VOTRE_JETON_API" par votre jeton actuel.import requests
import os
# Meilleure pratique : stockez votre jeton dans une variable d'environnement
# Pour cet exemple, nous le définissons directement.
API_TOKEN = "VOTRE_JETON_API"
API_URL = "https://api-inference.huggingface.co/models/distilbert/distilbert-base-uncased-finetuned-sst-2-english"
def query_model(payload):
headers = {"Authorization": f"Bearer {API_TOKEN}"}
response = requests.post(API_URL, headers=headers, json=payload)
response.raise_for_status() # Lever une exception pour les codes d'erreur
return response.json()
# Classons une phrase
data_payload = {
"inputs": "I love the new features in this software, it's amazing!"
}
try:
output = query_model(data_payload)
print(output)
# Exemple de sortie : [[{'label': 'POSITIVE', 'score': 0.9998...}]]
except requests.exceptions.RequestException as e:
print(f"Une erreur s'est produite : {e}")POSITIVE ou NEGATIVE, avec un score de confiance. Ce modèle fondamental s'applique à toutes sortes de tâches ; seule la structure du payload change. Bien sûr, pour des modèles plus avancés comme les générateurs vidéo, les interactions peuvent être plus complexes, comme on peut le voir dans ce guide complet de l'API Sora 2 pour 2025.Encoder votre jeton en dur est acceptable pour un test rapide, mais c'est un risque de sécurité majeur dans un projet réel. Ne commettez jamais de clés API dans un dépôt Git. Utilisez des variables d'environnement ou un outil de gestion des secrets.
Utiliser l'API d'inférence pour différentes tâches d'IA

inputs pour chaque modèle.Génération de texte créatif
max_length.import requests
API_URL = "https://api-inference.huggingface.co/models/gpt2"
headers = {"Authorization": "Bearer VOTRE_JETON_API"}
def query_text_generation(payload):
response = requests.post(API_URL, headers=headers, json=payload)
return response.json()
output = query_text_generation({
"inputs": "The future of AI in software development will be",
"parameters": {"max_length": 50, "temperature": 0.7}
})
print(output)
# Sortie attendue : [{'generated_text': 'The future of AI in software development will be...'}]La réponse renvoie un objet JSON propre avec le texte généré, facile à analyser et à intégrer.
Classifier le contenu d'une image
'rb') et passez ces données dans le paramètre data de votre requête.import requests
API_URL = "https://api-inference.huggingface.co/models/google/vit-base-patch16-224"
headers = {"Authorization": "Bearer VOTRE_JETON_API"}
def query_image_classification(filename):
with open(filename, "rb") as f:
data = f.read()
response = requests.post(API_URL, headers=headers, data=data)
return response.json()
try:
output = query_image_classification("cat.jpg")
print(output)
except FileNotFoundError:
print("Erreur : 'cat.jpg' non trouvé.")Classification de texte "Zero-Shot"
inputs (votre texte) et un objet parameters contenant une liste de candidate_labels.// Exemple en JavaScript utilisant fetch
async function queryZeroShot(data) {
const response = await fetch(
"https://api-inference.huggingface.co/models/facebook/bart-large-mnli",
{
headers: { Authorization: "Bearer VOTRE_JETON_API" },
method: "POST",
body: JSON.stringify(data),
}
);
const result = await response.json();
return result;
}
queryZeroShot({
"inputs": "Our new feature launch was a massive success!",
"parameters": {"candidate_labels": ["marketing", "customer feedback", "technical issue"]}
}).then((response) => {
console.log(JSON.stringify(response));
});Comprendre les coûts et les paliers d'utilisation
Le système s'articule autour de niveaux d'utilisateurs (Gratuit, Pro, Équipe, Entreprise), chacun disposant d'un certain montant de crédits mensuels. Une fois ces crédits épuisés, vous passez à un modèle de paiement à l'usage. Bien que cela soit idéal pour débuter, la gestion de coûts séparés pour plusieurs modèles et fournisseurs peut devenir un casse-tête opérationnel.
Simplifier la gestion de vos coûts
Des appels directs au routage intelligent
Optimiser les performances pour la production

Renforcer la résilience au-delà d'un point de terminaison unique
Cette architecture offre deux avantages critiques :
- Basculement automatique (Failover) : Si un fournisseur est lent ou ne répond pas, EvoLink redirige instantanément la requête vers une alternative saine.
- Équilibrage de charge (Load Balancing) : Pendant les pics de trafic, les requêtes sont réparties entre plusieurs fournisseurs.
De l'appel direct à la passerelle unifiée
# Avant : Appel direct à Hugging Face
import requests
HF_API_URL = "https://api-inference.huggingface.co/models/gpt2"
HF_TOKEN = "VOTRE_TOKEN_HF"
def direct_hf_call(payload):
headers = {"Authorization": f"Bearer {HF_TOKEN}"}
response = requests.post(HF_API_URL, headers=headers, json=payload)
return response.json()# Après : Appel via l'API unifiée EvoLink (compatible OpenAI)
import requests
EVOLINK_API_URL = "https://api.evolink.ai/v1"
EVOLINK_TOKEN = "VOTRE_TOKEN_EVOLINK"
def evolink_image_generation(prompt):
headers = {"Authorization": f"Bearer {EVOLINK_TOKEN}"}
payload = {
'model': 'doubao-seedream-4.0',
'prompt': prompt,
'size': '1024x1024'
}
response = requests.post(f"{EVOLINK_API_URL}/images/generations",
headers=headers, json=payload)
return response.json()Questions courantes et réponses pratiques
Comment gérer les limites de débit (rate limits) ?
Plusieurs tactiques peuvent aider :
- Regroupez vos requêtes (Batching) : Envoyez plusieurs entrées en un seul appel.
- Implémentez un "Exponential Backoff" : Réessayez en attendant de plus en plus longtemps.
Puis-je exécuter mes modèles privés sur l'API d'inférence ?
Oui, c'est une fonctionnalité clé. Le processus est identique : passez votre jeton API dans l'en-tête. Assurez-vous simplement que le compte associé au jeton a les permissions nécessaires.


