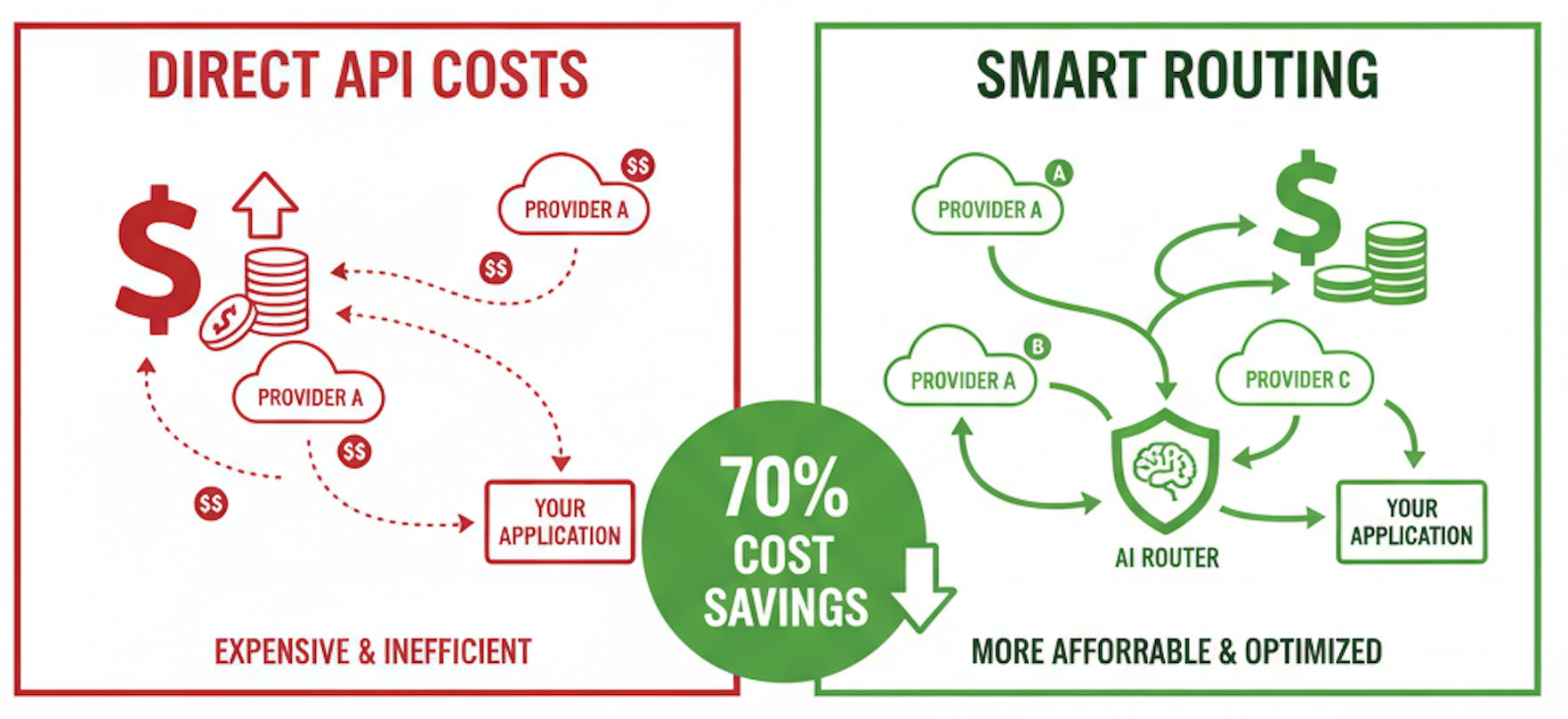
How We Cut Our AI API Costs by 70% (And You Can Too)
Jacey
Founder
September 22, 2025
14 min read
Author
Jacey
Founder
One API for Top AI Models Worldwide – Save 20-70% AI Costs with EvoLink
Category
Cost Optimization
It started with a Slack message from Mike, a founder friend.
"Our AI bills are killing us," he wrote. "We just paid $3,200 last month for image generation."
Three weeks later, his bill for the exact same usage was $960.
70% Cost Reduction
Same AI model • Same quality • Same code
$3,200
Before
→
$960
After
We didn't switch their AI model. We didn't reduce the output quality. We didn't ask his team to rewrite a single line of code. All we did was change how their application called the API.
Now, let's break down the exact playbook we used.
Part 1: The Dirty Secret of AI Pricing
The Numbers That Made Me Do a Double-Take
I nearly spit out my coffee when I first saw these price differences:
Same Model, Different Channels, Mind-Blowing Price Gaps
Nano Banana (Gemini 2.5 Flash Image)
• Google direct: $0.039 per image
• Aggregator platforms: Up to 50% cheaper
Seedream 4.0
• BytePlus direct: $0.03 per image
• Aggregator platforms: Up to 60% cheaper
VEO3 Fast
• Google direct: $0.15 per second
• Aggregator platforms: Up to 30% cheaper
Why These Insane Price Differences Exist
After digging deep (and talking to a lot of insiders), here's what I learned:
Factor 1: Volume is King
This is the most straightforward economic principle: the more you buy, the cheaper the unit price. An individual developer has almost zero negotiating power. A platform committing to billions of tokens per month gets an entirely different price list.
Solo Developer: Pays the full list price.
Mid-Size Company: Might negotiate a 10-15% discount.
Not all sellers are created equal. You can get the same AI model through different channels, each with different pricing:
Official APIs: Direct from the source (OpenAI, Google). You pay full list price.
Cloud Providers: Tech giants (Azure, AWS, GCP) bundle AI models with cloud services. Convenient but often more expensive with vendor lock-in.
Aggregators: Buy in massive bulk to get wholesale rates, then pass savings to you. Lower cost but dependent on their platform reliability.
Factor 3: The Service Level (SLA) Shuffle
Most users overpay for uptime guarantees they don't need. Small SLA differences create huge price gaps:
Enterprise SLA (99.99%): Highest price, less than 5 minutes downtime/month
Standard (99.9%): Default tier, ~43 minutes downtime/month
Bulk channels (~99%): Most economical, ~7 hours downtime/month
For most applications (dev, staging, non-critical production), the difference is negligible. This trade-off is often the biggest cost-cutting lever.
Factor 4: Geographic Arbitrage
The same API call costs different amounts in different regions due to varying operational costs (electricity, taxes, competition).
Smart routing platforms automatically send requests to the cheapest available region, creating consistent savings that compound over time.
Part 2: How to Start Optimizing Your AI Costs Today
Bottom Line: You don't need a PhD in computer science to start saving money. This section provides a practical, three-phase roadmap that any development team can follow.
Phase 1: Audit, Research, and Test
Before making any changes, the first step is to gather data. A smart decision is always a data-driven one.
Step 1: Audit Your Spending
Find out where your money is going.
Export your last 3 months of API usage
Find your top 3-5 most expensive operations
Step 2: Map Alternatives
For each high-cost operation, research other channels.
Direct Providers: OpenAI, Google, Anthropic, etc.
Cloud Integrations: Azure OpenAI, AWS Bedrock, etc.
Smart Aggregators: Platforms that specialize in routing
Step 3: Run Small-Scale Tests
Never switch without testing.
Establish a Baseline: Measure your current provider's performance first
Track Key Metrics: Cost, latency, reliability, and output quality
Phase 2: The Core Decision: Build vs. Buy
After testing various providers, you have two main options:
Factor
Build Your Own
Use Aggregator Platform
Time to Implementation
6-8 weeks typically
Minutes to hours
Development Cost
$50,000-100,000
$0
Ongoing Maintenance
4-8 hours/week
Minimal
Control Level
Full customization
Platform-defined features
Bulk Pricing Access
Depends on volume
Pre-negotiated rates
Technical Risk
Higher (custom development)
Lower (established solution)
Phase 3: The 5-Minute Platform Integration
If you've decided on the aggregator route, here's the complete setup process (we'll use evolink.ai as an example):
Quick Setup: 3 Simple Steps
1
Sign up & get API key
30 seconds. No credit card. Free credits to start testing.
2
Integrate with EvoLink API
Follow EvoLink's integration standards. See integration guide for detailed implementation.
3
Start saving immediately
Same models, 30-70% lower costs, better reliability.
Try It Now: 2-Minute Test
Want to see the difference immediately? Here's a minimal test you can run right now:
Get your free API key from evolink.ai (30 seconds), then test with your preferred language:
curl --request POST \
--url https://api.evolink.ai/v1/images/generations \
--header 'Authorization: Bearer <token>' \
--header 'Content-Type: application/json' \
--data '{
"model": "doubao-seedream-4.0",
"prompt": "A serene lake reflecting the beautiful sunset scenery",
"n": 1,
"size": "1024x1024",
"image_urls": [
"https://example.com/image1.png",
"https://example.com/image2.png"
]
}'
Here's the exact difference between direct integration vs smart aggregator platform:
Factor
Direct BytePlus
EvoLink Platform
Setup Time
2-3 days + approval wait
5 minutes, instant access
Cost per Image
$0.030 (list price)
$0.012 (60% savings)
Error Handling
Custom implementation needed
Built-in retry & fallback
Monitoring
Separate dashboard setup
Unified analytics included
Bottom Line: The platform eliminates technical complexity while delivering better economics and reliability.
Part 3: Real Case Study - From $3,200 to $960
The Implementation That Changed Everything
Remember Mike's e-commerce platform? Here's exactly what happened when we applied the Build vs. Buy framework.
Their situation fit Scenario 1 perfectly:
10-person engineering team
$3,200/month AI spend (painful but not massive)
CEO demanding immediate results
Zero bandwidth for 6-week infrastructure projects
The decision took 15 minutes.
Implementation and Rollout
After deciding on the platform route, implementation was ridiculously simple. The team started with a gradual migration approach to ensure zero downtime and monitor performance at each step.
Migration timeline:
Day 1: 5% of traffic → monitoring closely
Day 3: 25% of traffic → looking good
Day 7: 100% of traffic → full send
The Results That Speak Loudly
The Final Numbers
Before
$3,200
per month
After
$960
per month (-70%)
Implementation time:15 minutes
Engineering hours spent:2 hours total
Annual savings:$26,880
The bonus benefits we didn't expect:
15% faster response times (better routing = better performance)
99.95% uptime vs their previous 99.5%
Zero maintenance overhead (their team focuses on features)
Why This Approach Worked
Mike's team made the right call because they matched the solution to their situation:
✓Needed immediate results (platform delivers day 1)
✓Limited engineering bandwidth (2-line change vs 6-week project)
✓Cost-sensitive but not cost-engineering-focused (platform handles optimization)
✓Wanted to focus on their product, not infrastructure
The math was simple: even with platform fees, they saved more money and engineering time than any DIY solution could provide.
Ready to Start Saving?
If you're using AI APIs and want to cut costs, you're in the right place.
Whether you decide to build your own solution or use a platform like EvoLink, the important thing is to start optimizing. Every month you wait is money that could be going toward growing your business instead.
Want to see the savings for yourself? EvoLink offers free credits to test their platform - no credit card required, 5-minute setup. You can try it with a small portion of your traffic and see the cost reduction firsthand.
Start Saving on AI Costs Today
Free credits • No credit card • 5-minute setup
Test with mainstream AI models • Join VIP for even lower prices
Questions about implementation? Drop me a line at [email protected] - I'm always happy to chat about API optimization strategies.