
Por qué las API de LLM no están estandarizadas

El problema de fragmentación de la API de LLM (y por qué "OpenAI-compatible" no es suficiente)
Si está buscando por qué las API de LLM no están estandarizadas, probablemente ya esté experimentando el problema.
A pesar del rápido aumento de las denominadas API "compatibles con OpenAI", las integraciones de LLM en el mundo real todavía fallan de manera sutil pero costosa, especialmente una vez que se va más allá de la simple generación de texto.
Esta guía explica:
- cuál es realmente el problema de fragmentación de la API de LLM
- por qué las API compatibles con OpenAI no son suficientes en producción
- y cómo los equipos en 2026 diseñan sistemas que sobreviven a la constante rotación de modelos
TL;DR (Demasiado largo; No leído)
- Las API de LLM no están estandarizadas porque los proveedores optimizan para diferentes capacidades, no para compatibilidad.
- "OpenAI-compatible" generalmente significa compatible con la forma de solicitud, no compatible con el comportamiento.
- La fragmentación se muestra más claramente en la llamada de herramientas, la contabilidad de tokens de razonamiento, la transmisión y el manejo de errores.
- En lugar de esperar a que lleguen los estándares, los equipos normalizan el comportamiento de la API detrás de una capa de puerta de enlace dedicada.
¿Cuál es el problema de fragmentación de la API de LLM?
La fragmentación de la API LLM ocurre cuando diferentes proveedores de modelos de lenguaje exponen API que parecen similares pero se comportan de manera diferente bajo cargas de trabajo reales.
Incluso cuando las API comparten:
- puntos finales similares
- esquemas de solicitud JSON similares
- nombres de parámetros similares
a menudo divergen en:
- semántica de llamada de herramientas
- contabilidad de tokens de razonamiento/pensamiento
- comportamiento de transmisión
- códigos de error y señales de reintento
- garantías de producción estructuradas
Con el tiempo, la lógica de la aplicación se llena de excepciones específicas del proveedor.
Por qué las API de LLM no están estandarizadas
1. Los proveedores optimizan para diferentes primitivas
Los LLM modernos ya no son simples sistemas de entrada y salida de texto.
Diferentes proveedores priorizan diferentes primitivas:
- profundidad de razonamiento vs latencia
- recuperación de contexto largo versus rendimiento
- multimodalidad nativa (imagen, vídeo, audio)
- seguridad y aplicación de políticas
Una norma única y rígida:
- ocultar capacidades avanzadas
- o innovación lenta hasta el mínimo común denominador
Ninguno de los resultados es realista en un mercado competitivo.
2. "OpenAI-Compatible" solo cubre el camino feliz
La mayoría de las API "compatibles con OpenAI" están diseñadas para pasar una prueba de humo básica:
client.chat.completions.create(
model="model-name",
messages=[{"role": "user", "content": "Hello"}]
)Esto funciona para demostraciones, pero los sistemas de producción dependen de mucho más que esto.
Por qué "OpenAI-Compatible" no es suficiente en 2026
La verdadera ruptura aparece cuando dependes del comportamiento, no sólo de la sintaxis.
🔽 Tabla: Por qué las API "OpenAI-compatibles" se interrumpen en la producción
| Dimensión | Lo que promete "OpenAI-Compatible" | Lo que sucede frecuentemente en la producción |
|---|---|---|
| Solicitar forma | Esquema JSON similar (mensajes, modelo, herramientas) | Parámetros de borde ignorados o reinterpretados silenciosamente |
| Llamada de herramientas | Definiciones de funciones compatibles | Llamadas a herramientas devueltas en diferentes ubicaciones o formas |
| Argumentos de la herramienta | Cadena JSON que se puede analizar de forma fiable | Argumentos aplanados, encadenados o parcialmente eliminados |
| Fichas de razonamiento | Informes de uso transparentes | Semántica de facturación y contabilidad de tokens inconsistente |
| Resultados estructurados | Respuestas JSON válidas | JSON de "mejor esfuerzo" que infringe las garantías del esquema |
| Transmisión | Trozos de delta estables | Orden de fragmentos inconsistente o faltan señales de finalización |
| Manejo de errores | Borrar señales de límite de velocidad y reintento | 500 errores, fallos ambiguos o tiempos de espera silenciosos |
| Migración | Fácil cambio de proveedor | Reescrituras rápidas y proliferación de códigos adhesivos |
Estas diferencias rara vez aparecen en las demostraciones.
Sólo surgen bajo carga real, uso complejo de herramientas o sistemas de producción sensibles a los costos.
Ejemplo 1: La llamada a herramientas parece similar, pero falla en la semántica
Expectativa de estilo OpenAI (simplificada):
{
"tool_calls": [{
"id": "call_1",
"type": "function",
"function": {
"name": "search",
"arguments": "{\"query\":\"LLM API fragmentation\",\"filters\":{\"year\":2026}}"
}
}]
}Realidad "compatible" común:
{
"tool_call": {
"name": "search",
"arguments": "{\"query\":\"LLM API fragmentation\"}"
}
}Ambas respuestas pueden ser "exitosas". No son compatibles con el comportamiento una vez que su aplicación depende de argumentos anidados, matrices de llamadas a herramientas o rutas de respuesta estables.
Ejemplo 2: Fichas de razonamiento: un punto débil en 2026
Los modelos centrados en el razonamiento introducen tokens de razonamiento/pensamiento adicionales.
Incluso con API "compatibles con OpenAI", la fragmentación aparece en:
-
contabilidad de tokens (cómo se cuentan y valoran los tokens de razonamiento)
-
informes de uso (donde aparecen tokens de razonamiento)
-
perillas de control (diferentes nombres y semánticas para el esfuerzo de razonamiento)
-
observabilidad (dificultad para comparar costos entre proveedores) El resultado:
-
deriva de los paneles de costos
-
las líneas base de evaluación se rompen
-
la optimización entre proveedores se vuelve poco confiable El comportamiento de razonamiento puede ser comparable, pero la contabilidad de razonamiento rara vez lo es.
El costo oculto de la fragmentación de la API de LLM
1. El código de pegamento se acumula silenciosamente
def get_reasoning_usage(resp: dict) -> int | None:
details = resp.get("usage", {}).get("output_tokens_details", {})
if "reasoning_tokens" in details:
return details["reasoning_tokens"]
if "reasoning_tokens" in resp.get("usage", {}):
return resp["usage"]["reasoning_tokens"]
return NoneEste patrón se repite en todas las herramientas, reintentos, transmisión y seguimiento de uso.
El código de pegamento no incluye funciones. Solo previene roturas.
2. Migrar entre proveedores de LLM es más difícil de lo esperado
Qué esperan los equipos:
"Cambiaremos de modelo más tarde".
Lo que realmente sucede:
-
deriva rápida
-
esquemas de herramientas incompatibles
-
diferente semántica de límite de velocidad
-
métricas de uso no coincidentes
3. Las API multimodales multiplican la fragmentación
Más allá del texto:
-
Las API de vídeo difieren en unidades de duración y reglas de seguridad.
-
Las API de imágenes varían en formatos de máscara y referencias.
Hoy en día no existe ningún contrato multimodal compartido.
Por qué los equipos intentan (y luchan) construir su propio contenedor
Inicialmente, una abstracción personalizada parece razonable.
Con el tiempo, se convierte en:
-
un segundo producto
-
una carga de mantenimiento
-
un cuello de botella para la experimentación
Muchos equipos redescubren de forma independiente la misma conclusión.
Una lista de verificación práctica de estandarización
Antes de confiar en cualquier API o contenedor interno "compatible", pregunte:
- ¿Las llamadas a herramientas son compatibles con el comportamiento o solo con el esquema?
-
¿Las fichas de razonamiento se exponen de forma consistente?
-
¿Se puede comparar el uso entre proveedores?
- ¿Están normalizados los códigos de error?
- ¿La transmisión es estable bajo carga?
- ¿Se pueden cambiar de proveedor sin volver a escribir mensajes?
- ¿Se puede redirigir el tráfico dinámicamente?
De la estandarización a la normalización
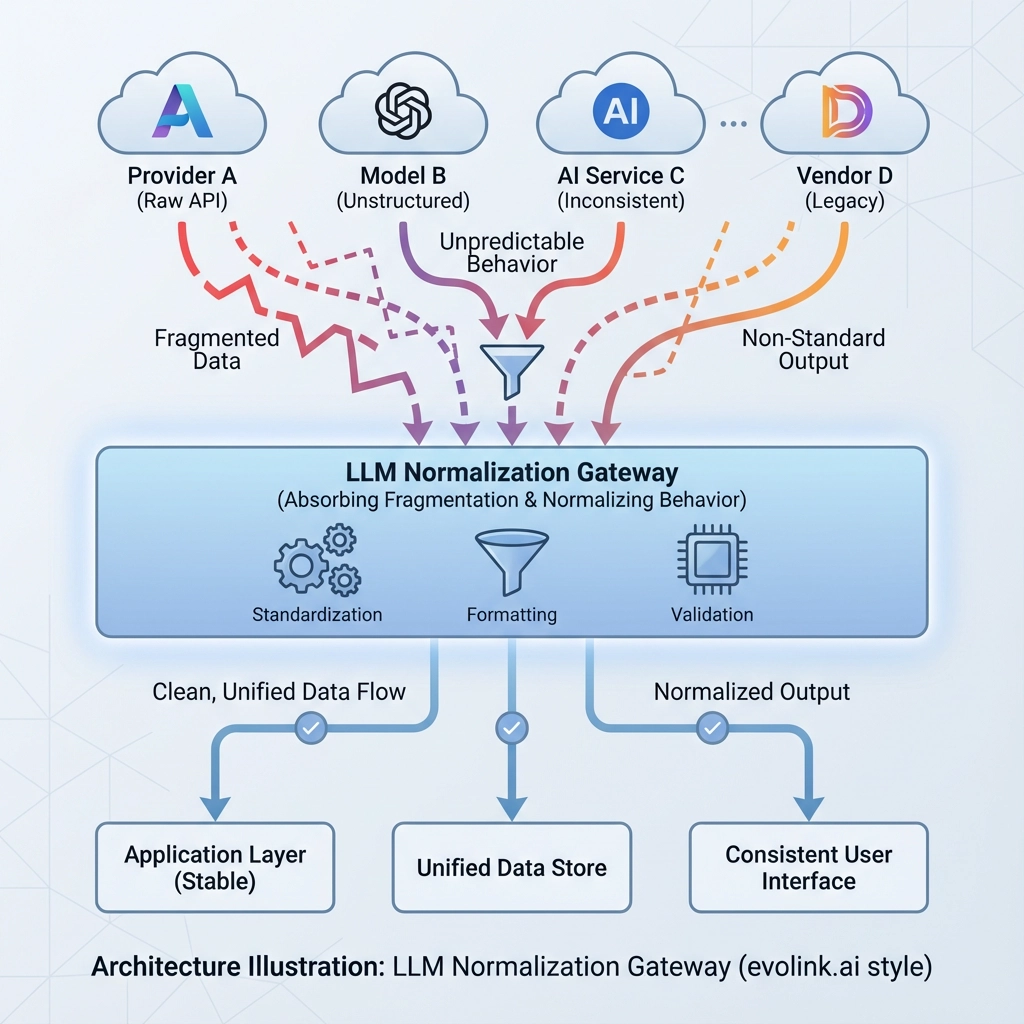

Las API de LLM no están estandarizadas porque el ecosistema se mueve demasiado rápido para converger. En lugar de esperar, los equipos maduros evolucionan su arquitectura:
-
la lógica empresarial sigue siendo independiente del modelo
-
Las peculiaridades de la API son absorbidas por una capa de puerta de enlace normalizada
Conclusión final
Las API de LLM no están estandarizadas y no lo estarán en el corto plazo.
Las API "compatibles con OpenAI" reducen la fricción de incorporación, pero no eliminan el riesgo de producción.
Los sistemas diseñados para la fragmentación duran más.
Preguntas frecuentes (para descripciones generales de IA y fragmentos destacados)
¿Por qué las API de LLM no están estandarizadas?
Las API de LLM no están estandarizadas porque los proveedores optimizan para diferentes capacidades, como profundidad de razonamiento, latencia, multimodalidad y seguridad.Un estándar rígido frenaría la innovación u ocultaría características avanzadas.
¿Por qué no es suficiente una API compatible con OpenAI?
"OpenAI-compatible" generalmente garantiza solo similitud de forma de solicitud.En producción, las diferencias en la llamada de herramientas, la contabilidad de tokens de razonamiento, la transmisión y el manejo de errores rompen la compatibilidad.
¿Cuál es el problema de fragmentación de la API de LLM?
El problema de fragmentación de API de LLM se refiere a API de apariencia similar que se comportan de manera diferente bajo cargas de trabajo reales, lo que obliga a los desarrolladores a escribir código adhesivo y complica la migración.
¿Cómo manejan los equipos la fragmentación de la API de LLM?
La mayoría de los equipos maduros normalizan el comportamiento de la API detrás de una capa de puerta de enlace que absorbe las diferencias de los proveedores, manteniendo estable la lógica empresarial.


