
Optimización de costos
Alternativas a OpenRouter (2026): Guía práctica para reducir el coste efectivo de la API de IA (LiteLLM, Replicate, fal.ai, WaveSpeedAI, EvoLink)

Jessie
COO
22 de enero de 2026
Actualizado el 13 de mayo de 2026
14 min de lectura
Busca una comparación más amplia de alternativas a OpenRouter? Este artículo se centra específicamente en la optimización de costes. Para una comparación completa de funciones de enrutamiento incluyendo privacidad, observabilidad y control de despliegue, consulte Mejores alternativas a OpenRouter en 2026. Para resolver errores de OpenRouter, consulte Solucionar OpenRouter 429 "Provider Returned Error".
Si está buscando alternativas a OpenRouter, su intención normalmente no es "quiero un nuevo router".
Es esta:
OpenRouter es conveniente, pero a medida que el uso crece empieza a resultar caro, y usted quiere un cambio que realmente mejore la economía unitaria sin convertir la migración en una reescritura de código.
Este artículo compara cinco opciones que los equipos evalúan habitualmente:
- LiteLLM (pasarela LLM autohospedada)
- Replicate (ejecución de modelos por tiempo de computación)
- fal.ai (plataforma de medios generativos)
- WaveSpeedAI (flujos de trabajo de generación visual)
- EvoLink.ai (pasarela unificada para chat/imagen/vídeo con enrutamiento inteligente)
También utilizaremos OpenRouter como base de referencia para el contexto.
TL;DR: ¿Qué alternativa debería evaluar primero?
- Si desea gobernanza de autohospedaje + máximo control → LiteLLM
- Si sus cargas de trabajo tienen forma de trabajo/computación y desea precios de hardware publicados → Replicate
- Si su gasto principal es la generación de imagen/vídeo → fal.ai o WaveSpeedAI
- Si su problema de costes se debe a la varianza de canales y desea unir chat + imagen + vídeo tras una única API → EvoLink.ai
Si desea probar EvoLink rápidamente más adelante en esta guía:
→ Obtenga una clave de API de EvoLink
Explorar EvoLink Smart Router
Lo que significa "OpenRouter se siente caro" (en producción)
La mayoría de los equipos no sienten presión de costes durante el prototipado temprano. El coste se vuelve doloroso cuando:
- tiene usuarios reales (y un uso impredecible)
- empiezan a ocurrir reintentos (ráfagas de 429/tiempos de espera)
- introduce funciones multimodales (texto + imagen + vídeo)
- comienza a optimizar el margen bruto y la economía unitaria
En ese momento, deja de importarle solo el "precio del token" y empieza a importarle el coste efectivo por resultado:
- coste por resolución de soporte exitosa
- coste por finalización de flujo de trabajo de agente
- coste por activo de imagen (incluyendo reintentos y fallos)
- coste por vídeo corto (incluyendo fallos y desperdicio de cola)
Lista de verificación de 15 minutos previa al cambio
| Paso | Acción | Resultado |
|---|---|---|
| 1 | Elija un KPI: coste efectivo por resultado | Un número único en el que su equipo pueda unirse |
| 2 | Mida la tasa de reintentos, tasa de errores, latencia p95 | Base para el "desperdicio" + impacto en UX |
| 3 | Etiquete su carga de trabajo: solo texto vs multimodal | Determina si un "router LLM" es suficiente |
| 4 | Decida su tolerancia: gestionado vs autohospedado | Determina LiteLLM vs herramientas gestionadas |
| 5 | Planifique el despliegue: shadow → canary → ramp | Evita migración de riesgo tipo "big-bang" |
El "Stack de Coste Efectivo" (donde desaparece el dinero)
| Capa | Factor de coste | Qué aspecto tiene | Qué medir |
|---|---|---|---|
| L1 | Coste de uso | tokens / por resultado / por segundo | $ por sesión/trabajo/activo |
| L2 | Varianza de canal | misma capacidad, diferente precio efectivo entre canales | distribución de precios entre rutas |
| L3 | Desperdicio por fallo | reintentos, tiempos de espera, tormentas 429 | tasa de reintentos, errores por cada 1k llamadas |
| L4 | Sobrecarga de ingeniería | muchos SDK, muchas cuentas de facturación, desfase | tiempo dedicado por integración |
| L5 | Dispersión de modalidades | texto + imagen + vídeo en varias plataformas | número de proveedores en el camino crítico |
Si OpenRouter se siente caro, suele ser por los niveles L2–L5.
Tabla 1 — Matriz de ajuste de plataforma (alineada con la intención "OpenRouter es caro")
| Plataforma | Cuándo es una alternativa sólida a OpenRouter | Forma típica de facturación (nivel alto) | Fricción de migración | Compensación a considerar |
|---|---|---|---|---|
| LiteLLM | Quiere control de autohospedaje (presupuestos, enrutamiento, gobernanza) y puede ejecutar infra | Pasarela OSS/proxy + sus costes de infra | Media–Alta | Usted es dueño de la op: HA, actualizaciones, desfase de proveedores, monitorización |
| Replicate | Su carga de trabajo tiene forma de trabajo/computación y quiere precios de hardware publicados | Tiempo de computación / segundos de hardware (varía por modelo) | Media | La varianza del tiempo de ejecución puede reducir la previsibilidad; pruebe entradas reales |
| fal.ai | Es intensivo en medios (imagen/vídeo/audio) y busca una amplia galería de modelos + escala | Plataforma de medios generativos basada en uso | Media | El coste efectivo depende de los modelos elegidos + diseño del flujo de trabajo |
| WaveSpeedAI | Está construyendo flujos de trabajo de generación visual (imagen/vídeo), primero los medios | Plataforma de medios basada en uso | Media | A menudo complementa a un router LLM en lugar de reemplazarlo |
| EvoLink.ai | Quiere reducir el coste efectivo mediante enrutamiento inteligente entre canales y unificar chat + imagen + vídeo | Pasarela basada en uso; optimización de costes impulsada por enrutamiento | Baja–Media | Verifique si requiere autohospedaje estricto/on-prem o necesidades de cumplimiento específicas |
| OpenRouter (base) | Cambio rápido de modelos LLM tras una sola API | Acceso LLM tipo token | N/A | Puede sentirse caro cuando el coste efectivo sube (desperdicio + sobrecarga + dispersión) |
Arquetipos de carga de trabajo: elija una alternativa que coincida con su producto
| Arquetipo de carga de trabajo | Para qué optimiza | Opciones con mejor ajuste | Por qué |
|---|---|---|---|
| SaaS chat / copilot de soporte | coste por sesión, latencia p95, desperdicio de reintentos | LiteLLM, EvoLink | LiteLLM para gobernanza de autohospedaje; EvoLink para economía de enrutamiento + stack unificado |
| Agentes de código / devtools | gestión de ráfagas, presupuestos/claves de org, agilidad de modelos | LiteLLM, EvoLink | LiteLLM para control de plataforma; EvoLink para enrutamiento de baja fricción + consciencia de costes |
| Imágenes de marketing (alto volumen) | coste por activo, rendimiento, async/webhooks | fal.ai, WaveSpeedAI, EvoLink | fal/WaveSpeed son primero los medios; EvoLink si quiere una sola interfaz para todas las modalidades |
| Generación de vídeo corto | coste por vídeo, comportamiento de cola, desperdicio de fallos | fal.ai, WaveSpeedAI, EvoLink | las plataformas de medios se especializan; EvoLink si quiere multimodality unificada + economía de enrutamiento |
| Investigación / experimentación | cobertura, prototipado rápido, claridad de precios de infra | Replicate, OpenRouter | Replicate se ajusta bien a la computación; OpenRouter es conveniente para iteración LLM |
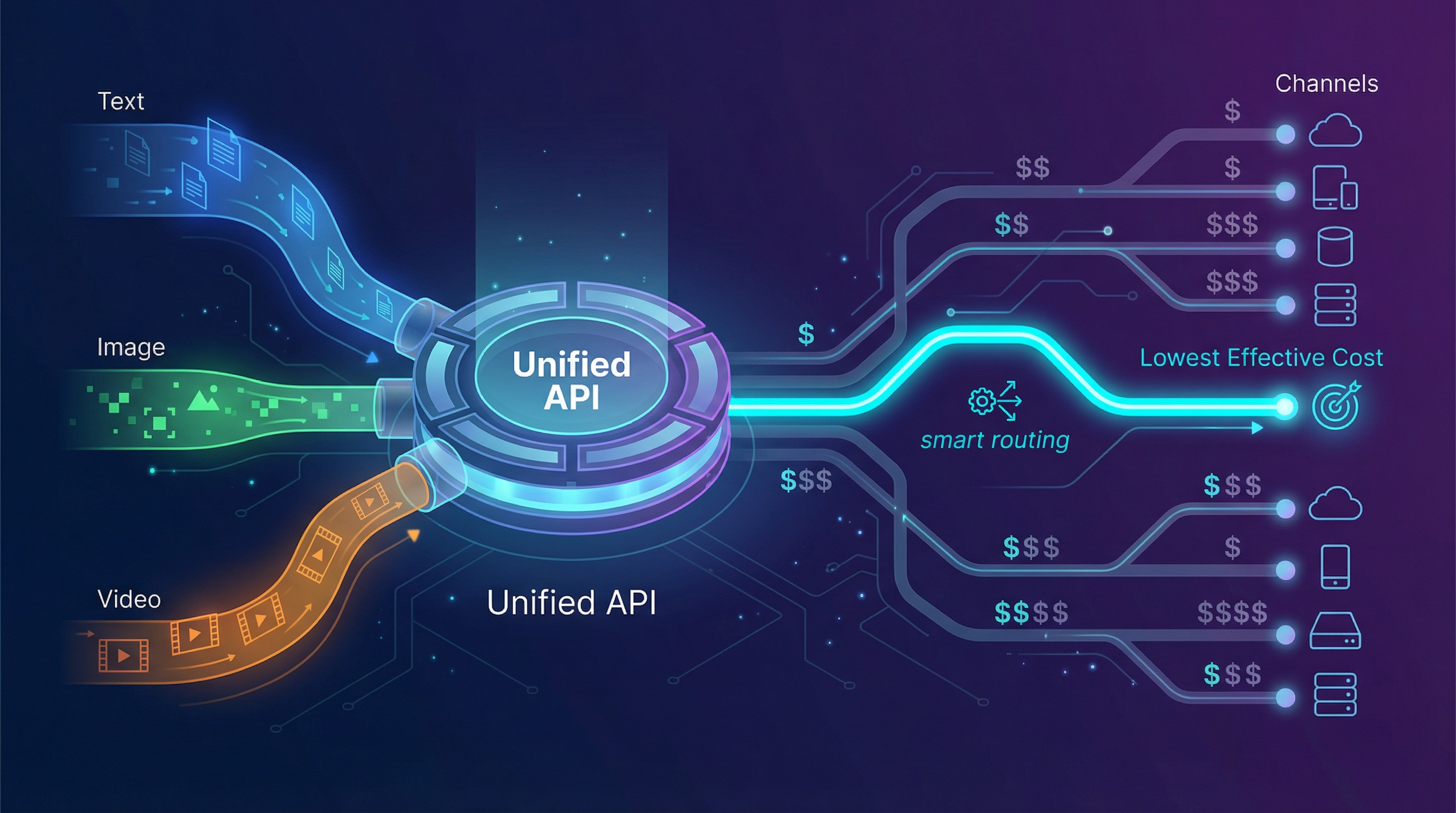
Las alternativas: qué evaluar (y cómo evaluarlas)
1) LiteLLM — control de pasarela autohospedada (formato OpenAI)
LiteLLM se evalúa habitualmente cuando los equipos quieren:
- Interfaz en formato OpenAI entre proveedores
- Presupuestos centralizados, límites de frecuencia y gobernanza
- Opciones de autohospedaje / on-prem
Cómo suele ganar LiteLLM
- Quiere ser dueño de la capa de políticas (presupuestos, autenticación, reglas de enrutamiento) dentro de su entorno.
- Está de acuerdo en cambiar la sobrecarga de proveedores por tiempo de ingeniería y propiedad operativa.
Donde los equipos se sorprenden
- El "router" se convierte en su responsabilidad:
- Alta disponibilidad (HA), escalado, respuesta a incidentes
- Desfase de proveedores (las API cambian)
- Pasarelas de registros/métricas
- Debe gestionar activamente los reintentos/fallbacks para evitar el desperdicio.
Cómo probar LiteLLM sin comprometerse demasiado
- Empiece en staging
- Use tráfico shadow (duplique llamadas; no afecte a los usuarios)
- Añada límites de gasto pronto
- Promueva a canary solo después de comprobaciones de paridad de salida
2) Replicate — ejecución de modelos por tiempo de computación con precios de hardware publicados
Replicate se evalúa a menudo cuando su carga de trabajo se parece más a "trabajos" que a turnos de chat:
- ejecuta predicciones de modelos como tareas de computación
- quiere niveles transparentes de precios de hardware (GPU $/seg)
Cómo suele ganar Replicate
- Gran ajuste para experimentación y cargas de trabajo con forma de computación
- La claridad de los precios de hardware ayuda a la previsión (cuando el tiempo de ejecución es estable)
Donde los equipos se sorprenden
- La variabilidad del tiempo de ejecución se convierte en variabilidad de coste.
- La fiabilidad de grado de producción puede variar según el modelo y la carga de trabajo.
Cómo probar Replicate
- Realice pruebas comparativas con entradas reales
- Registre la distribución del tiempo de ejecución (p50/p95/p99)
- Convierta a coste por resultado (activo/trabajo), no solo coste por segundo
3) fal.ai — plataforma de medios generativos (catálogo amplio + historia de escala)
fal.ai se elige a menudo para productos con muchos medios:
- generación de imagen/vídeo/audio
- amplia galería de modelos
- posicionamiento de rendimiento y escalado
Cómo suele ganar fal.ai
- Quiere una amplia cobertura de medios bajo una sola plataforma.
- Valora la historia de velocidad/escala para las API de medios.
Donde los equipos se sorprenden
- El coste efectivo depende extremadamente del modelo y el flujo de trabajo elegido.
- Las decisiones de diseño de async/webhook pueden afectar fuertemente al desperdicio por fallos.
Cómo probar fal.ai
- Elija 2–3 endpoints/modelos que coincidan con su producto
- Pruebe:
- latencia de una sola ejecución
- rendimiento por lotes
- Rastree: desperdicio por fallos y coste por activo
4) WaveSpeedAI — flujos de trabajo visuales primero los medios
WaveSpeedAI se evalúa habitualmente para flujos de trabajo de generación de imagen/vídeo.
Cómo suele ganar WaveSpeedAI
- Quiere una plataforma primero los medios para funciones de generación visual.
- Su producto es más "generar activos" que "asistente de chat".
Donde los equipos se sorprenden
- Puede complementar a un router LLM en lugar de reemplazarlo.
- "Más barato" depende de la estructura del flujo de trabajo (trabajos asíncronos, reintentos, etc.).
Cómo probar WaveSpeedAI
- Mida el coste por activo
- Mida la distribución del tiempo hasta el resultado
- Valide la estabilidad bajo cargas de lotes
5) EvoLink.ai — menor coste efectivo mediante economía de enrutamiento + API multimodal unificada
Si su queja es "OpenRouter es caro", la pregunta clave es: ¿caro debido a qué?
Si la respuesta es:
- su coste efectivo está inflado por la varianza de canal
- los reintentos y fallos crean desperdicio
- su aplicación se está volviendo multimodal (texto + imagen + vídeo)
- no quiere gestionar cinco integraciones de proveedores diferentes
…entonces EvoLink está posicionado para esa situación.
EvoLink se posiciona públicamente en torno a:
- Una sola API para chat, imagen y vídeo
- Más de 40 modelos
- enrutamiento inteligente diseñado para reducir el coste (afirma "ahorrar hasta un 70%")
- afirmaciones de fiabilidad que incluyen 99,9% de tiempo de actividad y failover automático
Cómo evaluar EvoLink (para que tanto finanzas como ingeniería confíen)
- Elija 1 flujo de trabajo representativo (no un prompt de juguete).
- Ejecute un canario del 1–5% durante 24–48 horas.
- Compare el coste efectivo por resultado, tasa de reintentos, latencia p95.
- Mantenga el rollback en su lugar.
Empiece aquí
- CTA principal: Obtenga una clave de API
- Catálogo de modelos: Modelos de EvoLink
- Implementación: Documentación de la API de EvoLink
- Ingeniería de estilo prueba: Guía de producción de GPT Image 1.5
Cómo decidir (sin pensarlo demasiado): un flujo de decisión simple
-
¿Necesita autohospedaje / on-prem / gobernanza interna profunda? → Empiece con LiteLLM.
-
¿Es su carga de trabajo principalmente generación de medios (imagen/vídeo)? → Empiece con fal.ai o WaveSpeedAI.
-
¿Su carga de trabajo tiene forma de trabajo/computación y le importa la economía del tiempo de ejecución? → Empiece con Replicate.
-
¿Quiere una sola interfaz para chat/imagen/vídeo y su problema de costes es el coste efectivo (varianza de canal + desperdicio)? → Pruebe EvoLink: Empiece gratis
Tabla 2 — Lista de verificación de mitigación de coste efectivo (implementar independientemente de la plataforma)
| Problema | Síntoma | Solución |
|---|---|---|
| Tormentas de reintentos | picos de gasto durante fallos de proveedores | límites de reintentos + colas + backoff |
| Facturación doble por acciones de usuario | clics repetidos = llamadas repetidas | claves de idempotencia + limitación de UI |
| Rutas caras usadas con demasiada frecuencia | todo el tráfico usa la opción premium | políticas de enrutamiento + presupuestos |
| El registro se convierte en centro de costes | almacenar todo para siempre | muestreo + límites de retención |
| Difícil de asignar el gasto | el "coste de IA" es un solo cubo | etiquete peticiones por función/equipo/usuario |
Manual de migración: cambie sin convertir lo "más barato" en "más arriesgado"
Tabla 3 — Plan de despliegue de bajo riesgo (copiar/pegar)
| Fase | Qué hace | Terminado cuando |
|---|---|---|
| Base | mide coste efectivo por resultado, tasa de reintentos, latencia p95 | puede explicar los factores de coste |
| Shadow | duplica peticiones a la nueva plataforma (sin impacto al usuario) | resultados comparables; sin fallos críticos |
| Canary | enruta 1–5% del tráfico real | KPI mejorado o neutral; el rollback funciona |
| Ramp | 10% → 25% → 50% → 100% | estable bajo carga máxima |
| Optimización | ajusta enrutamiento + presupuestos | la curva de costes mejora a medida que crece el volumen |
Guardrails que evitan "herramienta barata, resultado caro"
- Idempotencia para acciones de usuario
- Límites de reintentos + colas
- Límites de presupuesto por clave/equipo/proyecto
- Reglas de fallback basadas en tipo de fallo (timeout/429/5xx)
- Muestreo de registros (evite registrar todo para siempre)
Bonus: una hoja de trabajo de coste efectivo que puede entregar a su equipo
| Métrica | Base (OpenRouter) | Candidato A | Candidato B |
|---|---|---|---|
| Coste efectivo / resultado | |||
| Tasa de reintentos (%) | |||
| Tasa de errores (por cada 1k) | |||
| Latencia p95 (ms) | |||
| Superficies de proveedores en camino crítico (#) | |||
| Esfuerzo de migración (persona-días) |
Resumen de recomendaciones (basado en la intención "OpenRouter se siente caro")
- Si necesita gobernanza de autohospedaje + máximo control → LiteLLM
- Si sus cargas de trabajo son trabajos con forma de computación y quiere precios de hardware publicados → Replicate
- Si es principalmente generación de imagen/vídeo → fal.ai o WaveSpeedAI
- Si quiere reducir el coste efectivo mediante economía de enrutamiento y unificar chat/imagen/vídeo tras una sola interfaz → EvoLink.ai Pruébelo: Obtenga una clave de API de EvoLink
Próximos pasos (prácticos, enfocados a la conversión)
- Elija su primer candidato (basado en el arquetipo de carga de trabajo)
- Ejecute un canario del 1–5% durante 24–48 horas
- Compare: coste efectivo por resultado + tasa de reintentos + latencia p95
- Amplíe el tráfico solo después de que el rollback esté probado
- Si está probando EvoLink:
Notas (para evitar errores fácticos)
- Los precios, catálogos y conjuntos de funciones cambian con frecuencia. Verifique los detalles en las páginas oficiales de cada proveedor antes de tomar decisiones presupuestarias.
- Este artículo hace referencia a OpenRouter por intención de búsqueda; no está afiliado a OpenRouter.


