
ロードバランサールーター開発者ガイド

1つのサーバーが過負荷になるのを許すのではなく、ルーターは入ってくるリクエストをサーバーのプール、または現代のAIアプリケーションの文脈では異なるAIモデルの間でインテリジェントに分散させます。その結果、ユーザーにシームレスな体験を提供する、高可用かつ高性能なアプリケーションが実現します。
ロードバランサールーターはどのように機能するのか?
ロードバランサールーターの本質は、単一障害点(SPOF)を排除するように設計されていることです。典型的なシングルサーバー構成では、そのサーバーが過負荷になったりオフラインになったりすると、アプリケーション全体が停止してしまいます。
ロードバランサールーターはユーザーとサーバープールの間に位置し、入ってくるすべてのリクエストを傍受し、その時点でどのダウンストリームリソースが処理に最適かを決定します。この概念は、初期のハードウェアアプライアンスから、現代の分散システムを支える洗練されたソフトウェアレイヤーへと大きく進化しました。この原理を理解することは、特に予測不可能なAPIトラフィックを扱う際に、レジリエントなシステムを構築するための第一歩となります。
なぜすべての現代的アプリケーションに必要なのか
開発者にとって、適切に実装されたロードバランサーには次のような重要な利点があります。
- 高可用性: サーバーやAPIエンドポイントが故障したり応答しなくなったりした場合、ルーターは自動的にそれをプールから除外し、トラフィックを正常なインスタンスにリダイレクトします。アプリケーションはオンラインのまま維持されます。
- スケーラビリティ: 負荷の増加に対応するには、プールにサーバーを追加するだけです。ロードバランサーは即座にそれらへのトラフィックのルーティングを開始し、ダウンタイムなしでの水平スケーリングを可能にします。
- パフォーマンスの向上: ワークロードを分散させることで、ユーザーのリクエストが常にレスポンスの良いサーバーによって処理されるようになり、レイテンシが短縮され、全体的なユーザー体験が向上します。
ロードバランサールーターを、停止に対するアプリケーションの第一防衛線と考えてください。それは、独立したサーバーの集まりを、単一の強力でレジリエントなシステムへと変貌させます。
この概念をマスターすることで、レジリエンスを後付けで考えるのではなく、最初からレジリエンスを考慮した設計が可能になります。
コアとなるロードバランシングアルゴリズムの理解
これらのアルゴリズムは、ワークロードを分散するためのロジックを提供します。以下のインフォグラフィックは、ネットワークトラフィックを効果的に管理するために、さまざまな戦略がどのように連携するかを示しています。
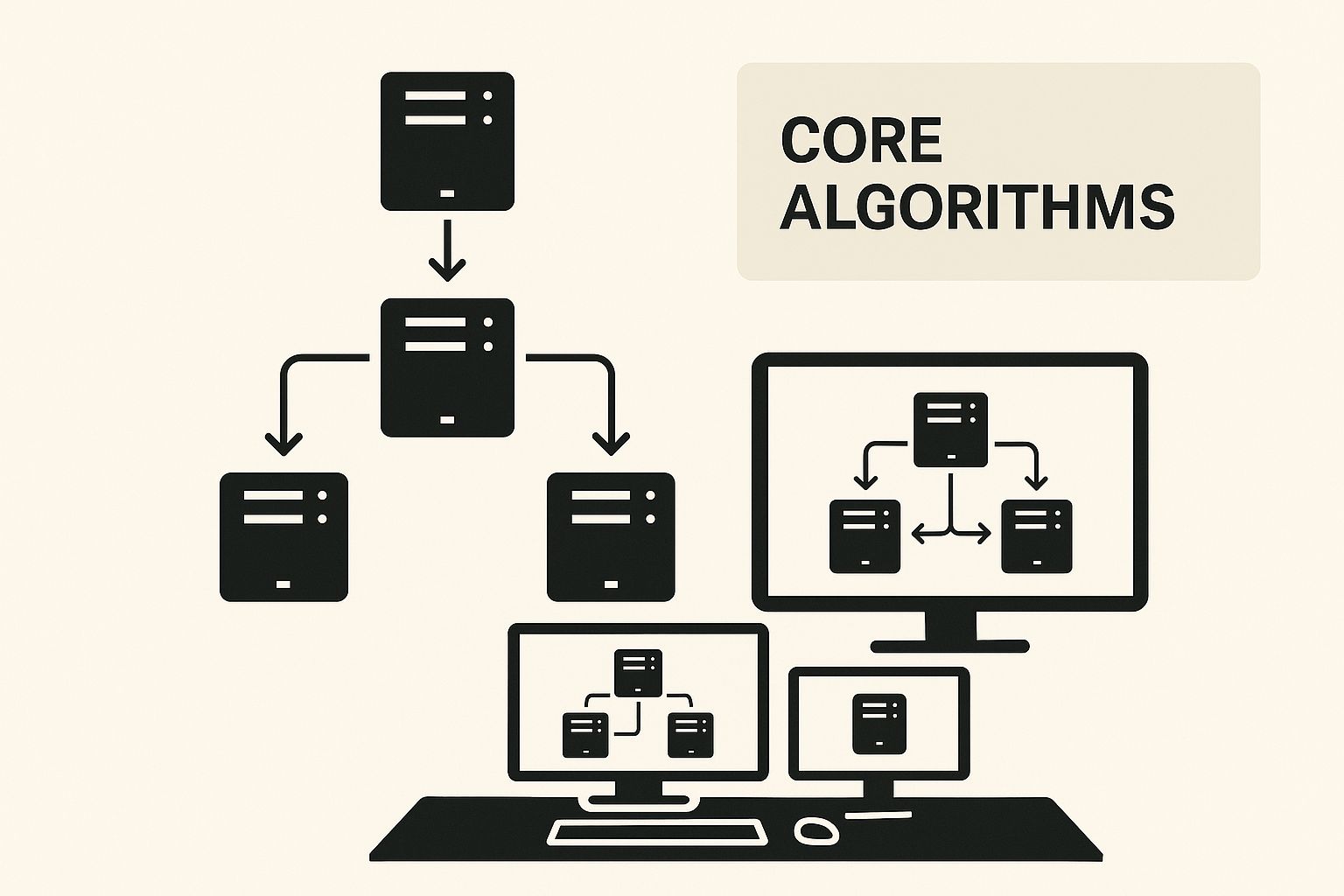
ご覧のように、これらの基本的な手法は、より洗練されたルーティング決定を下すための構成要素です。目標は、特定のサーバーが過負荷になり、システム全体の障害を引き起こすのを防ぐことです。
一般的な分散手法
では、ロードバランサーはトラフィックをどこに送信するかをどのように決定するのでしょうか。通常、いくつかの標準的なアルゴリズムのいずれかを使用します。
-
ラウンドロビン (Round Robin): これは最もシンプルで一般的な方法です。ロードバランサーはサーバーのリストを順番に巡り、新しいリクエストをシーケンス内の次のサーバーに送信します。予測可能ですが、すべてのサーバーが同じ能力を持ち、すべてのリクエストが同様の処理コストであることを前提としています。
-
最小接続 (Least Connections): これはよりダイナミックな戦略です。アクティブな接続数が最も少ないサーバーに新しいリクエストをルーティングします。これは、接続時間が変動する環境で特に効果的であり、他のサーバーがアイドル状態である間に、1つのサーバーが長時間実行されるタスクで占有されるのを防ぎます。
-
IPハッシュ (IP Hash): この方法は、クライアントのIPアドレスのハッシュを使用して、そのクライアントを常に同じサーバーにマッピングします。主な利点は セッションの永続性(または「スティッキー性」)です。これは、ユーザーのセッションデータが特定のサーバーに維持される必要があるオンラインショッピングカートなどのステートフルなアプリケーションにとって重要です。
一般的なロードバランシングアルゴリズムの比較
適切なアルゴリズムの選択は、アプリケーションの特定の要件によって異なります。この表では、最も一般的な手法を比較しやすく分類しています。
| アルゴリズム | 仕組み | 最適な用途 | 潜在的な欠点 |
|---|---|---|---|
| ラウンドロビン | リスト内の各サーバーに順次リクエストを分散。 | サーバーが同一で、リクエストが均一な環境。 | サーバーの負荷や処理時間の変動を考慮しない。 |
| 最小接続 | 接続が最も少ないサーバーに新規リクエストを送信。 | 接続時間が長い場合や、リクエストの負荷が不均一な場合。 | 接続の追跡に計算リソースをより多く消費する可能性がある。 |
| IPハッシュ | ソースIPアドレス基づき、特定サーバーにリクエストを割り当て。 | セッションの永続性を必要とするアプリ(例:ショッピングカート)。 | 特定のIPから大量のリクエストがあると、分散が偏る可能性がある。 |
| 重み付きラウンドロビン | 能力に応じてサーバーに「重み」を割り当てるラウンドロビンの変形。 | 処理能力の異なるサーバーが混在する環境。 | 重みの手動設定と定期的な調整が必要。 |
結局のところ、唯一の「最善」のアルゴリズムというものは存在しません。目標は、アプリケーションの動作とインフラのアーキテクチャに分散ロジックを合わせることです。
重み付きおよびインテリジェントルーティング
これらの古典的なアルゴリズムは従来のWebトラフィックには効果的ですが、複数のプロバイダーにわたるAIリクエストのルーティングにおいては不十分です。単純なラウンドロビンアルゴリズムにはコストや可用性の概念がありません。高価な、あるいは利用不可能なプロバイダーに盲目的にリクエストを送信してしまう可能性があります。これはまさに、EvoLink のような高度なロードバランサールーターが解決する問題です。選択したモデルを、最もコスト効率が高く信頼できるプロバイダーにリアルタイムでインテリジェントにルーティングします。
AIモデルルーティングにおける現代の課題
従来のロードバランシングは、同一のサーバー群にトラフィックを分散させることを前提としています。このモデルはステートレスなWebリクエストには適していますが、多様なAIモデルのエコシステムに適用すると完全に破綻します。
GPT-4、Llama 3、Claude Haikuなどのモデルは、代替可能なものではありません。推論能力、レスポンスのレイテンシ、そして極めて重要なトークンあたりのコストが大きく異なります。これにより、問題は単純なトラフィック分散から、複雑な多目的最適化パズルへと変わります。
ここで基本的なラウンドロビン方式を使用するのは非効率的で高コストです。単純な要約タスクを最も強力(かつ高価)なモデルに振り分けてしまったり、複雑な分析クエリを高速だが能力の低いモデルに送信してしまい、最適な結果が得られなかったりする可能性があるからです。

均一なサーバーから複数のAIプロバイダーへ
希望のAIモデルを選択した後は、AIネイティブなルーターがすべてのリクエストに対していくつかの要素を評価する必要があります。
- プロバイダーのコスト: 同じGPT-4モデルでも、プロバイダーによってコストが 10倍 異なる場合があります。選択したモデルに対して最も安価な利用可能なプロバイダーを見つけることで、即座に節約が可能になります。
- プロバイダーの可用性: そのプロバイダーは現在オンラインで応答可能ですか?リアルタイムのヘルスチェックにより、リクエストが常に正常なエンドポイントに到達することを保証します。
- プロバイダーのレイテンシ: 今この瞬間、どのプロバイダーが最も高速なレスポンスタイムを提供していますか?動的なパフォーマンスモニタリングにより、その時々で最もレスポンスの良いプロバイダーにルーティングします。
インテリジェントなAIルーターは、単に負荷をバランスさせるだけではありません。ビジネスの成果を最適化します。選択したモデルに対して、APIコールごとに動的で情報に基づいた決定を下し、最適なプロバイダーを選択することで、可能な限り低いコストで最高のパフォーマンスを提供します。
スマートなプロバイダールーティングのコード例
この概念的なJavaScript関数は、選択したモデルに対して最適なプロバイダーを選択するためのロジックを示しています。プロバイダーの可用性とコストを確認し、最適なエンドポイントにルーティングします。
// 選択したモデルに対して最適なプロバイダーを選択する概念的な関数
async function routeToProvider(selectedModel) {
// ユーザーはすでにモデルとしてGPT-4を選択している
const providers = [
{ name: 'OpenAI', endpoint: 'https://api.openai.com/v1/chat/completions', cost: 0.03, available: true },
{ name: 'Azure', endpoint: 'https://azure.openai.com/v1/chat/completions', cost: 0.035, available: true },
{ name: 'Provider-A', endpoint: 'https://api.provider-a.com/v1/gpt-4', cost: 0.015, available: true },
{ name: 'Provider-B', endpoint: 'https://api.provider-b.com/v1/gpt-4', cost: 0.012, available: false }
];
// 利用可能なプロバイダーのみにフィルタリング
const availableProviders = providers.filter(p => p.available);
// コスト順(安い順)にソート
availableProviders.sort((a, b) => a.cost - b.cost);
// 最も安価な利用可能なプロバイダーを選択
const selectedProvider = availableProviders[0];
console.log(`Routing ${selectedModel} to ${selectedProvider.name} at $${selectedProvider.cost} per request`);
// 実際のアプリケーションでは、ここでAPIコールを行う
// const response = await fetch(selectedProvider.endpoint, { ... });
// return response.json();
return {
model: selectedModel,
provider: selectedProvider.name,
endpoint: selectedProvider.endpoint,
cost: selectedProvider.cost
};
}
// 使用例 - ユーザーがGPT-4を選択
routeToProvider('GPT-4').then(result => console.log(result));このコードはコアとなる概念を示していますが、実用的なシステムを構築するには、さらに多くのことが必要です。数十のプロバイダーのAPIキーの管理、リアルタイムの価格と可用性の追跡、プロバイダーがダウンした際の自動フェイルオーバーの実装、そして継続的なパフォーマンスのモニタリングです。
EvoLinkによる高度なAIルーティングの実践
インテリジェントなAIルーターを一から構築することは、エンジニアリング上の大きな挑戦です。複数のAPIキーの管理、リアルタイムのモデルパフォーマンスの監視、堅牢なフェイルオーバーロジックの実装、そして新しいモデルがリリースされるたびにシステムを更新し続ける必要があります。これが、EvoLinkのようなマネージドソリューションが開発チームにとってゲームチェンジャーである理由です。
この統合されたアプローチは、運用のオーバーヘッドを劇的に削減し、エンジニアリングチームがAIインフラの管理ではなく、コア製品の開発に専念できるようにします。
インテリジェントルーティングが現実世界でどのように機能するか
EvoLinkの主要機能がどのよう具体的メリットをもたらすかは以下の通りです。
- 自動モデルフェイルオーバー: OpenAIのようなプライマリプロバイダーが停止したりパフォーマンスが低下したりした場合、EvoLinkは自動的にAPIコールを同じモデルを提供する正常な代替プロバイダーにリルーティングします。アプリケーションはシームレスに機能し続けます。
- 動的パフォーマンスルーティング: システムは、選択したモデルに対して利用可能なすべてのプロバイダーのレイテンシとスループットを継続的に監視し、その瞬間に最も速いレスポンスを提供できるプロバイダーに各リクエストを送信します。
- インテリジェントなコスト最適化: EvoLinkは、選択したモデルに対して最もコスト効率の高いプロバイダーへ自動的にルーティングを行い、常に数十のプロバイダーの価格を比較して、常に最良のレートを保証します。
トラフィックをインテリジェントに指揮することで、EvoLinkを使用する開発者はしばしば 20〜70% のコスト削減を達成します。これは単に最も安いプロバイダーを選ぶことではなく、好みのモデルを使用しながらパフォーマンスと予算のバランスを取るために、リクエストごとに「最も賢い」プロバイダーの選択を行うということです。
EvoLinkを使用した実践的なコード例
このPythonの例を考えてみましょう。優先順位を付けたモデルのリストを提供すれば、EvoLinkがすべてのルーティング、最適化、フェイルオーバーを自動的に管理します。
import os
import requests
# 環境変数からEvoLink APIキーを設定
api_key = os.getenv("EVOLINK_API_KEY")
api_url = "https://api.evolink.ai/v1/chat/completions"
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}
# fallbackオプションを含めた優先モデルを定義
# EvoLinkは各モデルを最も安価な利用可能なプロバイダーにルーティングします
# 第一候補が利用不可の場合、リスト内の次のモデルに自動的にフェイルオーバーします
payload = {
"model": ["openai/gpt-4o", "anthropic/claude-3.5-sonnet", "google/gemini-1.5-pro"],
"messages": [
{"role": "user", "content": "Analyze the sentiment of this customer review: 'The product is good, but the shipping was slow.'"}
]
}
try:
response = requests.post(api_url, headers=headers, json=payload)
response.raise_for_status() # エラーレスポンス(4xx または 5xx)に対してHTTPErrorを発生させる
print(response.json())
except requests.exceptions.RequestException as e:
print(f"An API error occurred: {e}")このスニペットは抽象化の力を示しています。アプリケーションコードはクリーンでビジネスロジックに集中したまま、強力なロードバランサールーターがバックグラウンドで動作し、アプリケーションのレジリエンスとコスト効率を高めます。
EvoLinkは、複雑な自社システムの構築と維持の必要性を排除し、即座に結果をもたらす製品レベルのソリューションを提供します。これにより、チームは世界クラスのAI機能をより迅速かつ効率的に統合できるようになります。
実装可能な実践的ルーティング戦略
実装可能な4つの実践的な戦略を見てみましょう。

コストベースルーティング
この戦略は予算を優先します。コストベースルーティングは、選択したモデルに対して最も手頃な価格のプロバイダーにリクエストを自動的に送信します。
レイテンシベースルーティング
ユーザー体験が最も重要な場合、レイテンシベースルーティングが最適な選択肢です。これは、ミリ秒単位の差が重要となるカスタマーサービス用チャットボットやインタラクティブなAIツールなどのリアルタイムアプリケーションにとって不可欠です。
ルーターは、選択したモデルに対して利用可能なすべてのプロバイダーのリアルタイムのパフォーマンスを継続的に監視します。リクエストが届くと、即座に現在のレスポンスタイムが最も短いプロバイダーに転送され、使用するモデルを変更することなく、ユーザーに可能な限り迅速な回答を届けることができます。
フェイルオーバールーティング
フェイルオーバールーティングは、アプリケーションのセーフティネットです。APIプロバイダーの停止やパフォーマンスの低下は避けられません。これが発生した際、ルーターはあらかじめ定義された優先リストに従って、次の正常なモデルにリクエストを自動的にリルーティングします。
この戦略は、プロバイダーの障害を、エンドユーザー体験に影響を与えることなく優雅に(gracefully)処理できる高可用性システムを構築するために不可欠です。
よくある質問
ロードバランサーとルーターの違いは何ですか?
これらはしばしば一緒に使用されますが、ネットワーク内で異なる機能を果たします。
自前でAIモデルロードバランサーを構築できますか?
技術的には可能ですが、製品レベルのAIルーターの複雑さは相当なものです。
堅牢なソリューションには、単なるリクエストの分散以上のものが必要です。数十のAPIキーの安全な管理、各モデルのリアルタイムのコストとレイテンシの追跡、信頼性の高いヘルスチェックの実装、そして効果的なフェイルオーバーロジックの構築に責任を持つ必要があります。さらに、このシステムは、新しいモデルを取り込み、APIの変更に適応するために継続的なメンテナンスを必要とします。
これこそが、EvoLink のようなマネージドソリューションが大きな価値を提供する点です。私たちは、これらの複雑なすべてを処理する、製品レベルで鍛えられたシステムをすでに構築しています。インテリジェントなルーティングが組み込まれた単一の統合APIを利用できるため、チームはインフラではなくコア製品に集中できます。このアプローチにより、即座に 20〜70% のコスト削減 を実現し、初日から高い信頼性を確保できます。
ロードバランサールーターは、実際にどのようにアプリの信頼性を高めるのですか?
信頼性は主に、冗長性と自動ヘルスチェックという2つのメカニズムによって達成されます。
リクエストを複数のモデルやサーバーに分散させることで、ロードバランサーは単一障害点を排除します。あるモデルのAPIが利用不可になったり、サーバーがクラッシュしたりしても、トラフィックが自動的に正常な代替先に誘導されるため、アプリケーションは稼働し続けます。
また、システムは各エンドポイントに対して、バイタルサインを監視するように継続的なヘルスチェックを行います。定期的にリクエストを送信し、各エンドポイントが応答可能であることを確認します。エンドポイントがこれらのチェックに失敗したりエラーを返したりした場合、ルーターは即座にそれをアクティブなプールから除外し、新しいリクエストをシームレスに残りの正常なエンドポイントにリダイレクトします。この自動フェイルオーバーこそが、システムの一部に障害が発生している間でも高い可用性を保証する仕組みです。


