
guide
Claude Opus 4.6 エンタープライズ導入ガイド
EvoLink Team
Product Team
2026年2月5日
14 分
Claude Opus 4.6:本番環境対応のエンタープライズAI

2026年2月5日、AnthropicはClaude Opus 4.6をリリースしました。この世代は長時間実行タスク、複雑なマルチステップワークフロー、そしてエンタープライズグレードの「制御可能かつ監査可能な」エージェント機能に位置づけられています。
本記事では誇大広告を省き、一つのことに焦点を当てます:エンタープライズと開発者が実際にOpus 4.6を本番環境にどう導入するか。
TL;DR(多忙なCTO / テックリードの方へ)
Opus 4.6をB2B製品に統合する場合、「印象的なデモ応答」は本番環境対応とイコールではありません。導入基準は通常5つの要素を含みます:
- 信頼性:同一入力で出力がドリフトしないか?負荷時に品質が劣化しないか?
- 制御性:フォーマット、拒否、不確実性、引用、機密コンテンツを制約できるか?
- 可観測性:プロンプト、エビデンス、ツール呼び出し、レイテンシ、コストをトレース・再現できるか?
- ロールバック能力:モデル、プロンプト、検索戦略をワンクリックでダウングレードできるか?
- セキュリティとコンプライアンス:PII、インジェクション攻撃、不正なツール呼び出しをブロックできるか?
以下に公式ファクトカードと導入パスおよびコピー&ペーステンプレートを記載します。
1. ファクトカード(公式に検証可能)
1.1 モデルと提供状況
| 項目 | 詳細 |
|---|---|
| モデル名 | Claude Opus 4.6 |
| API Model ID | claude-opus-4-6 |
| 1Mコンテキストベータ対応プラットフォーム | Claude API, Microsoft Foundry, Amazon Bedrock, Google Vertex AI |
注:ベータ機能にはティアの資格が必要です—以下を参照してください。
1.2 コンテキストと出力
- 標準コンテキスト:200Kトークン
- 1Mトークンコンテキスト(ベータ):ベータヘッダー
context-1m-2025-08-07が必要、通常Usage Tier 4またはカスタム制限が必要 - 出力制限:128K出力トークン(大きな
max_tokensにはストリーミングを使用してHTTPタイムアウトを回避)
1.3 料金(要点:ロングコンテキストはプレミアム課金をトリガー)
| シナリオ | 入力価格 | 出力価格 |
|---|---|---|
| ≤ 200K入力 | $5 / MTok | $25 / MTok |
| > 200K入力(プレミアム) | $10 / MTok | $37.50 / MTok |
注意:入力が200Kを超えると、そのリクエストの全トークンがプレミアム料金で課金されます。コスト見積もりにこれを明示的に組み込んでください。
1.4 重要なAPI/動作変更(移行必読)
- Adaptive thinking推奨:
thinking: {type: "adaptive"} - Effort(4段階):
low / medium / high (default) / max - Compaction API(ベータ):サーバーサイド自動コンテキスト圧縮、ベータヘッダー
compact-2026-01-12 - 破壊的変更:Prefill無効化:Opus 4.6では最後のメッセージでのAssistant prefillが400を返す
output_formatがoutput_config.formatに移行- ツール呼び出しパラメータのJSONエスケープが旧モデルとわずかに異なる場合がある:手動文字列パースではなく標準JSONパーサー(
JSON.parse/json.loads)を使用すること
2. エンタープライズが4.6を「より本番対応」と感じる理由
2.1 1Mコンテキスト(ベータ):ギミックではなく、利用可能情報のブレークスルー

エンタープライズで最も価値の高いタスクは「きれいな文章を書く」ことではなく:
- 大量の資料(契約書、ポリシー、チケット、コード、レポート)を読むこと
- 重要なエビデンスを見つけること(引用付き)
- エビデンスを実行可能な結論に変えること(監査可能、取り消し可能)
ロングコンテキストにより「より多くの生の資料を一つのパイプラインに収める」ことが可能になります。ただし、以下も必要です:
- 権限によるフィルタリング(ACL):プロンプトではなく、検索時に行う
- エビデンスの引用:出力に
chunk_id/doc_idを含める必要がある - コストと制限の管理:>200Kはプレミアム課金+専用レート制限をトリガー(本番で驚かないように)
2.2 Compaction(ベータ):「中断必須」の長時間タスクを「継続可能」に
多くのエージェントワークフローは200K付近で「爆発」します。Compactionの価値:コンテキストがしきい値に近づくと、APIが自動的に圧縮サマリーを生成して続行し、持続可能な長時間実行タスクを可能にします。
注意:Compaction有効時は、usage.iterations(圧縮イテレーションを含む)でコストを追跡してください。そうしないと実際のトークン消費を過小評価します。
2.3 Agent Teams(Claude Code):ネイティブな並列探索

Agent TeamsはClaude Codeのリサーチプレビュー機能です:1つのリードセッションが分解と調整を担当し、複数のチームメイトがそれぞれのコンテキスト内で並列実行し、相互にメッセージを送ることができます。
最適な用途:分解可能、読み取り重視、低相互依存の作業(例:並列コードベースレビュー、デバッグの並列仮説検証)。
実践的アドバイス:本番環境前に、Agent Teamsを「完全自動化」ではなく「アクセラレーター」として扱い、権限と監査を組み合わせて影響範囲を抑えてください。
2.4 Adaptive Thinking + Effort:調整可能な「インテリジェンス/速度/コスト」ノブ
エンタープライズ環境では、多くのタスクは「全力の推論」を必要としません:
- 顧客ルーティング、軽い分類、フィールド抽出:low/mediumの方が安価で高速なことが多い
- 複雑な診断、長文書の統合、コード移行:high/maxの方が安定した品質を提供
Effortを統一された「コスト-品質」ダイアルとして扱い、スキーマバリデーションを重ね、より安定したSLAを実現してください。
3. エンタープライズ統合と提供状況
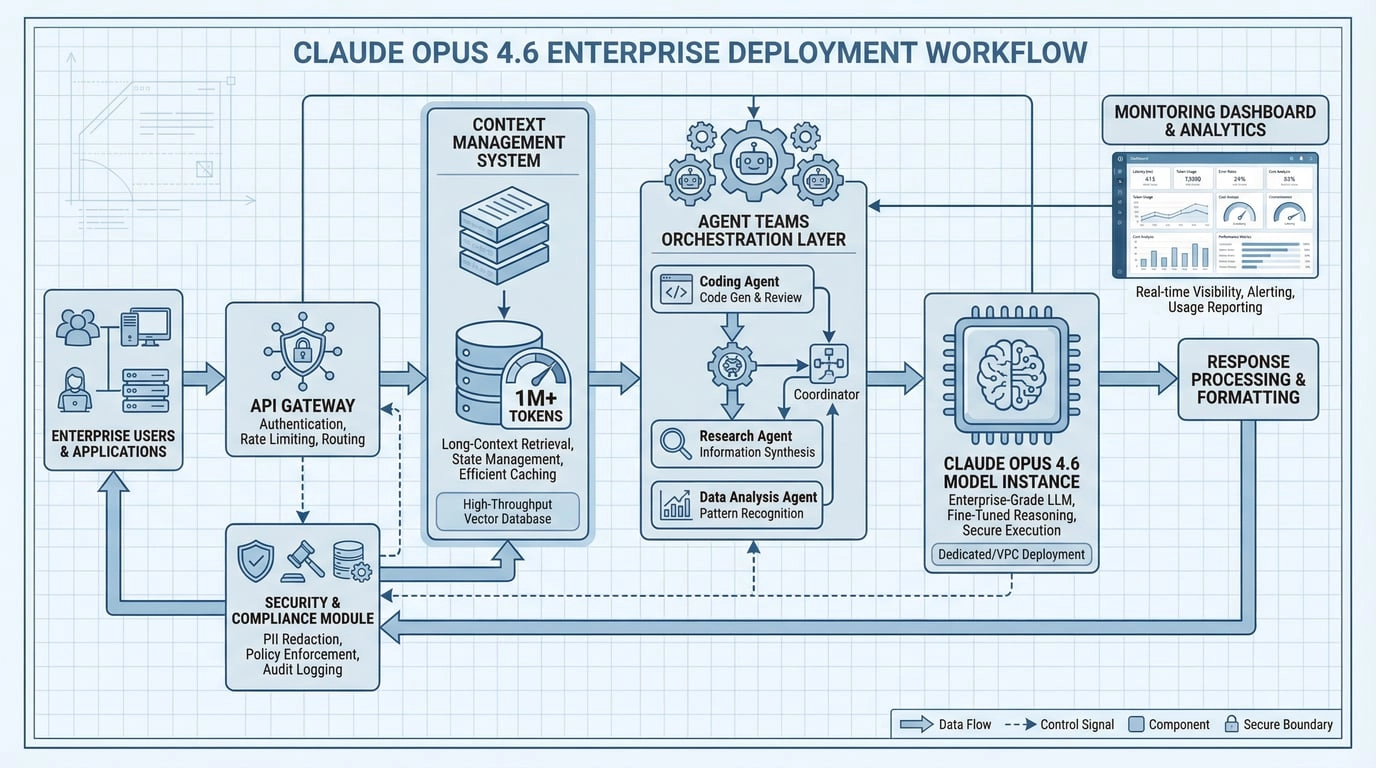
3.1 プラットフォーム側
- Claude API:製品組み込みおよびバックエンドワークフロー向け
- Microsoft Foundry / Bedrock / Vertex AI:エンタープライズクラウドガバナンスとコンプライアンス向け
- GitHub Copilot:Opus 4.6はCopilotエコシステムで展開中
3.2 オフィスツール(「エンタープライズの日常」により近い)
- Claude in Excel:現在のワークブックのセル、数式、タブ構造を読み取ってアシスト(データクリーニング、モデル検証、レポート解釈に最適)
- Claude in PowerPoint(リサーチプレビュー):既存テンプレート内でスライドを生成・編集(「エンタープライズテンプレートをよりエンタープライズらしく」するのに最適)
注意:Office機能は通常、特定のプランまたはプレビューアクセスが必要です。「効率向上」シナリオに適しており、重要な出力は引き続き人間によるレビューが必要です。
4. 移行と導入:4つの「クラッシュしない」ハードルール
- Assistant Prefillの使用を停止:Opus 4.6は400を返します。代わりにSystem instructions、Structured Outputs、または
output_config.formatを使用してください - すべてのoutput_formatをoutput_config.formatに移行:将来のAPIバージョンでは旧フォーマットが廃止されます
- ツール呼び出しパラメータには標準JSONパーサーのみを使用:手動文字列パースは不可
- 大きな出力には必ずストリーミングを使用:ストリーミングなしの大きな
max_tokensはタイムアウトしやすい
5. コピー&ペーステンプレート
5.1 1Mコンテキスト(ベータ)呼び出し例
curl https://api.anthropic.com/v1/messages \
-H "x-api-key: $ANTHROPIC_API_KEY" \
-H "anthropic-version: 2023-06-01" \
-H "anthropic-beta: context-1m-2025-08-07" \
-H "content-type: application/json" \
-d '{
"model": "claude-opus-4-6",
"max_tokens": 1024,
"messages": [{"role":"user","content":"Process this large document..."}]
}'5.2 Adaptive Thinking + Effort(Python)
import anthropic
client = anthropic.Anthropic()
resp = client.messages.create(
model="claude-opus-4-6",
max_tokens=4096,
thinking={"type": "adaptive"},
output_config={"effort": "medium"},
messages=[{
"role": "user",
"content": "Summarize the risks in this contract clause..."
}],
)
print(resp.content[0].text)5.3 Structured Outputs(JSON Schema)+ エビデンスゲート
resp = client.messages.create(
model="claude-opus-4-6",
max_tokens=2048,
thinking={"type": "adaptive"},
output_config={
"effort": "medium",
"format": {
"type": "json_schema",
"schema": {
"name": "kb_answer",
"schema": {
"type": "object",
"properties": {
"answer": {"type": "string"},
"evidence": {"type": "array", "items": {"type": "string"}},
"uncertainties": {"type": "array", "items": {"type": "string"}}
},
"required": ["answer", "evidence"]
}
}
}
},
messages=[{
"role": "user",
"content": """Only answer based on EVIDENCE blocks. Cite evidence IDs.
<evidence>
[#a1] Revenue grew 15% YoY in Q3 2025...
[#b7] Customer churn rate increased to 8.2%...
</evidence>
Question: What are the key business risks?"""
}],
)
print(resp.content[0].text) # JSON string (validate before downstream use)5.4 Compaction(ベータ)有効化の例
curl https://api.anthropic.com/v1/messages \
--header "x-api-key: $ANTHROPIC_API_KEY" \
--header "anthropic-version: 2023-06-01" \
--header "anthropic-beta: compact-2026-01-12" \
--header "content-type: application/json" \
--data '{
"model": "claude-opus-4-6",
"max_tokens": 4096,
"messages": [{"role":"user","content":"Help me build a website"}],
"context_management": {
"edits": [{"type":"compact_20260112"}]
}
}'5.5 Agent Teams(Claude Code)セットアップ
settings.jsonで有効化
{
"env": {
"CLAUDE_CODE_EXPERIMENTAL_AGENT_TEAMS": "1"
}
}有効化後、Claude Codeで自然言語を使用します:
- "Create an agent team with roles A/B/C to review this codebase…"
- "Lead agent synthesizes findings; teammates focus on security/perf/tests…"
6. コスト見積もりと制限ガバナンス
6.1 典型的シナリオのコスト比較
| シナリオ | 入力トークン | 出力トークン | コスト(標準) | コスト(プレミアム >200K) |
|---|---|---|---|---|
| 短い文書の要約 | 5K | 500 | $0.04 | - |
| 中規模のコードレビュー | 50K | 2K | $0.30 | - |
| 長文書の分析 | 150K | 3K | $0.83 | - |
| 拡張コンテキスト | 500K | 5K | - | $5.19 |
| Agent Teams(3ラウンド) | 200K × 3 | 10K | $3.25 | - |
注意:Agent Teamsは複数の並列セッションを生成します。総トークン消費量 = リード + チームメイトの合計。単一ラウンドの入力が200Kを超えると、プレミアム課金がトリガーされる場合があります。
6.2 制限ガバナンスの推奨事項
- Effortレベルごとに独立したレート制限を設定:high/maxはボリュームが低いがコストが高い—個別に監視
- >200K入力には明示的な承認を要求:意図しないプレミアム課金を回避
- Compactionシナリオでは2〜3倍のバッファを確保:圧縮イテレーションが実際の消費を増加させる
- Agent Teamsはまずサンドボックスでテスト:並列性×コンテキストが予想を超える場合がある
7. セキュリティとコンプライアンス
7.1 セキュリティ設定の例
security_config = {
"content_filtering": {
"hate_speech": "strict",
"violence": "strict",
"sexual_content": "strict",
"self_harm": "strict"
},
"output_validation": {
"check_for_pii": True,
"check_for_credentials": True,
"check_for_malicious_code": True
},
"audit_logging": {
"enabled": True,
"log_level": "detailed",
"retention_days": 90
}
}7.2 エンタープライズチェックリスト
- PIIフィルタリング:入力と出力の両方で機密情報をスキャン
- ツール呼び出しホワイトリスト:事前定義された関数呼び出しのみを許可
- 出力フォーマット検証:JSON Schemaで制約を強制
- エビデンスのトレーサビリティ:すべての結論がソース文書に遡れること
- 監査ログ:すべてのAPI呼び出し、入力サマリー、出力サマリーを記録
- ダウングレードスイッチ:古いモデルまたは低いEffortへのワンクリックロールバック
- コストサーキットブレーカー:ユーザーごと/タスクごとの制限超過時に自動停止
8. パフォーマンスベンチマーク(公式データ)
| ベンチマーク | Claude Opus 4.6 スコア | 説明 |
|---|---|---|
| Terminal-Bench 2.0 | 65.4% | エージェントプログラミング評価(過去最高) |
| GDPval-AA | 1606 Elo | 金融・法律の専門タスク |
| BigLaw Bench | 90.2% | 法的推論能力 |
| BrowseComp | 業界1位 | Web情報検索 |
出典:Anthropic公式リリース
9. 結論:Opus 4.6を「魔法の入力ボックス」ではなく「システムコンポーネント」として扱う
Opus 4.6の真の価値は「チャットが上手くなった」ことではなく、よりエンジニアリングに適していることです:
- ロングコンテキスト + Compactionで長時間タスクを持続可能に
- Agent Teamsで並列コラボレーションをネイティブに
- Adaptive Thinking + Effortでコスト/品質を制御可能に
Schema、エビデンスゲート、監査、ロールバックを重ねる—それがエンタープライズ本番への道です。
クイックスタート
Claude Opus 4.6とそのユースケースの包括的な紹介をお探しですか?
→ Claude Opus 4.6 ディープダイブをお読みください
Claude Opus 4.6を試してみたいですか?
→ EvoLinkモデルページでサポートされているモデルとクイックインテグレーションをご確認ください
参考文献(公式/一次ソース)
- Anthropic: Introducing Claude Opus 4.6
- Claude API Docs: What's new in Claude 4.6
- Claude API Docs: Context windows
- Claude API Docs: Pricing
- Claude API Docs: Compaction
- Claude Code Docs: Agent Teams
- Microsoft Azure Blog: Claude Opus 4.6 on Foundry
この記事はevolink.aiチームが執筆しました。私たちはエンタープライズがAI機能を安全かつ制御可能に本番環境へ導入することを支援しています。
エンタープライズAI導入のサポートが必要ですか? お問い合わせ


