
GPT Image 1.5 : Guide Complet des Fonctionnalités, Comparaison et Accès (2026)

Vous regardez l'image d'un produit qui nécessite trois variations pour différents marchés – même éclairage, même angle, mais des arrière-plans et des superpositions de texte différents. Votre designer est complet pour les deux prochaines semaines et la campagne est lancée lundi. Et si vous pouviez effectuer ces changements vous-même en quelques minutes, en maintenant une cohérence parfaite à chaque itération, sans même toucher à Photoshop ?
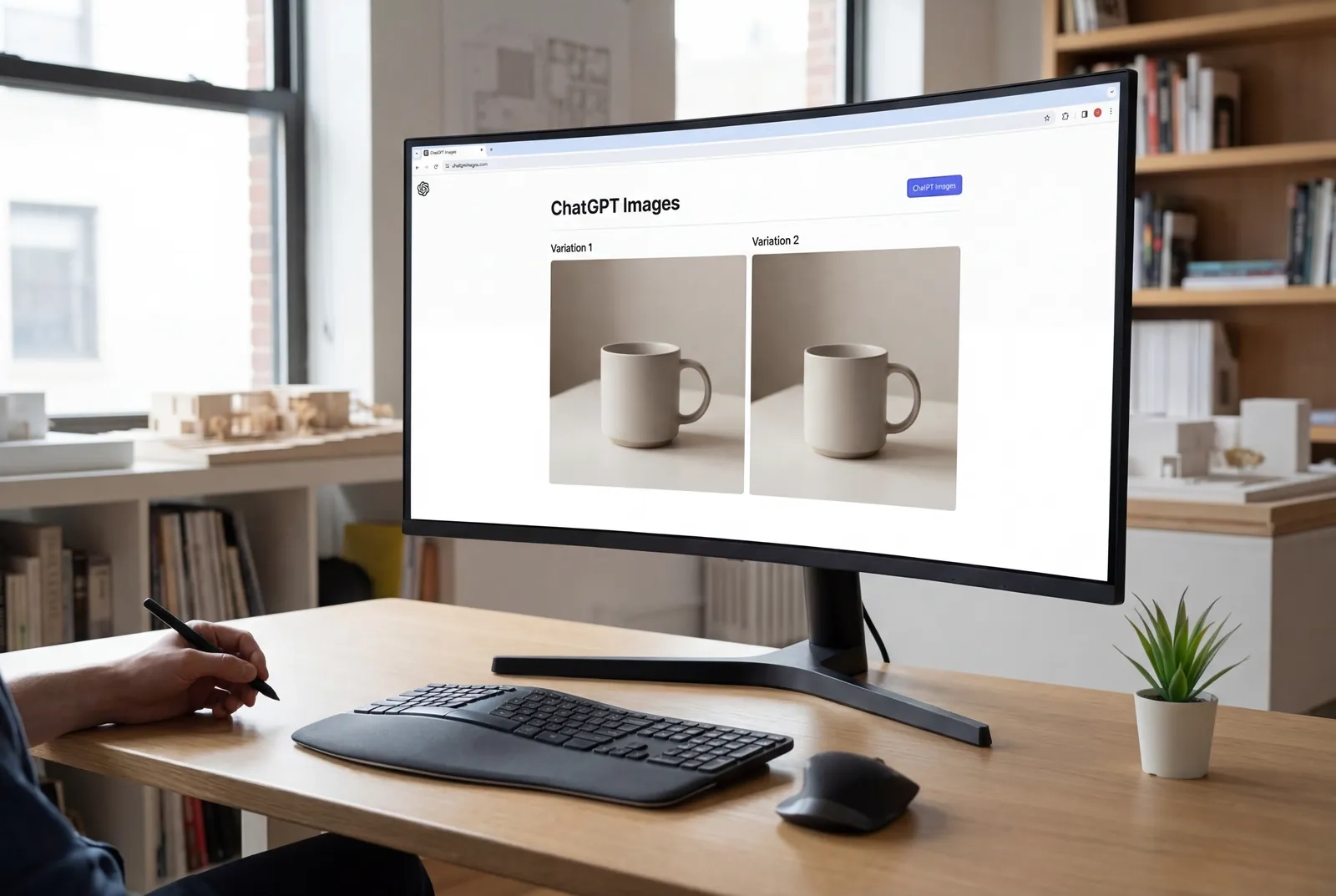
Table des matières
- Qu'est-ce que GPT Image 1.5 ? Comprendre le dernier modèle d'image d'OpenAI
- Caractéristiques clés qui distinguent GPT Image 1.5 des autres
- Performance de vitesse : explication de la génération 4x plus rapide
- Édition de précision : comment fonctionne réellement la préservation des détails
- Capacités et limites du rendu de texte
- GPT Image 1.5 vs GPT Image 1 : qu'est-ce qui a changé ?
- Comparaison complète des modèles : GPT Image 1.5 vs Concurrents
- Accéder à GPT Image 1.5 : Guide de l'interface ChatGPT
- Accès API via EvoLink.AI et la plateforme OpenAI
- Structure tarifaire et stratégies d'optimisation des coûts
- Études de cas réels et applications
- Ingénierie de prompt avancée pour de meilleurs résultats
- Erreurs courantes à éviter lors de l'utilisation de GPT Image 1.5
- Limites et quand choisir des outils alternatifs
- Questions fréquemment posées (FAQ)
Qu'est-ce que GPT Image 1.5 ? Comprendre le dernier modèle d'image d'OpenAI
gpt-image-1.5-lite dans la documentation de l'API) représente le système de génération d'images de deuxième génération d'OpenAI. Lancé le 16 décembre 2025, il sert de moteur à la nouvelle fonctionnalité d'image de ChatGPT. Contrairement à son prédécesseur GPT Image 1, introduit en avril 2025 principalement pour l'exploration créative expérimentale, GPT Image 1.5 a été conçu dès le départ pour des environnements de production où la cohérence, la vitesse et le contrôle précis sont primordiaux par rapport aux surprises artistiques.La désignation "1.5" signale une amélioration itérative plutôt qu'une refonte architecturale complète. OpenAI a conservé l'architecture de diffusion par transformer tout en implémentant des optimisations significatives sur trois axes critiques : l'efficacité de calcul (permettant l'amélioration de vitesse par 4), la fidélité aux instructions (réduisant les modifications non souhaitées lors de l'édition) et la fidélité du rendu de texte (rendant les petites polices et les mises en page denses réellement lisibles).
Caractéristiques clés qui distinguent GPT Image 1.5 des autres
1. Suivi des instructions amélioré
2. Préservation des détails pendant l'édition
Le modèle utilise ce qu'OpenAI décrit comme une "édition consciente des régions", qui identifie les pixels qui doivent rester inchangés pendant les modifications. Si vous éditez une image contenant le visage d'une personne, GPT Image 1.5 maintiendra l'identité faciale, la texture de la peau et l'expression, sauf si vous demandez explicitement des changements sur ces éléments. Le même principe s'applique aux :
- Logos de marque et filigranes
- Direction et qualité de la lumière
- Composition de l'arrière-plan
- Étalonnage des couleurs et ton
- Propriétés des textures et des matériaux
Ce n'est pas parfait – des scènes complexes avec des éléments superposés peuvent encore créer des artefacts – mais c'est un pas mesurable vers le type d'édition sélective que les professionnels attendent d'outils comme Photoshop.
3. Rendu de texte supérieur
Les modèles d'image IA précédents traitaient le texte comme des formes décoratives plutôt que comme des informations lisibles. GPT Image 1.5 implémente une génération améliorée consciente de l'OCR qui produit :
- Un texte lisible à des tailles de points plus petites
- Une orthographe correcte dans les langues courantes
- Un alignement et un crénage de texte appropriés
- Un poids de police et un style correspondants
- Un texte lisible dans des mises en page complexes (infographies, couvertures de magazines, étiquettes de produits)
4. Vitesse de niveau production
L'amélioration de vitesse par 4 n'est pas seulement une question d'impatience – elle change fondamentalement les flux de travail qui deviennent viables. Avec des temps de génération typiques de 8 à 12 secondes par image (contre 30 à 45 secondes pour GPT Image 1), l'affinement itératif devient possible. Un designer peut maintenant tester dix variations en deux minutes au lieu de sept, maintenant son élan créatif.
5. Amélioration de l'efficacité des coûts

Performance de vitesse : la génération 4x plus rapide expliquée
L'affirmation "4x plus rapide" nécessite un contexte pour comprendre ce qui s'est réellement amélioré et où les goulots d'étranglement subsistent.
Ce qui a changé sous le capot
Les gains de vitesse d'OpenAI proviennent de trois optimisations architecturales :
- Réduction des étapes d'échantillonnage : Le processus de diffusion nécessite désormais moins d'itérations de débruitage pour atteindre des seuils de qualité acceptables, réduisant la charge de calcul sans perte de qualité visible.
- Mécanismes d'attention optimisés : Les couches du transformer utilisent des modèles d'attention plus efficaces qui réduisent les exigences de bande passante mémoire lors de la synthèse d'image [Non vérifié – OpenAI n'a pas publié les détails de l'architecture technique].
- Meilleure quantification du modèle : Les calculs de précision moindre dans les sections de chemin non critiques réduisent le nombre d'opérateurs en virgule flottante tout en maintenant la fidélité de sortie [Non vérifié – déduit des standards de l'industrie].
Benchmarks de vitesse réels
Basé sur des tests rapportés publiquement sur plusieurs plateformes :
| Taille de l'image | GPT Image 1 | GPT Image 1.5 | Amélioration de la vitesse |
|---|---|---|---|
| 1024×1024 | 35-45 sec | 8-12 sec | 3,6-4,5× |
| 1024×1536 | 45-55 sec | 12-18 sec | 3,1-3,8× |
| 1536×1024 | 45-55 sec | 12-18 sec | 3,1-3,8× |
Arbitrage entre vitesse et qualité
low, medium, high, auto) qui impactent directement le temps de génération. L'affirmation "4x plus rapide" s'applique principalement aux paramètres de qualité auto et medium. Si vous demandez explicitement une qualité high pour des actifs de production, attendez-vous à des temps de génération de 15 à 20 secondes – toujours plus rapides que GPT Image 1, mais pas quatre fois.auto pour les itérations initiales et l'exploration de concepts, puis passez en qualité high uniquement pour les rendus de production finaux. Cette optimisation du flux de travail peut réduire la durée totale de votre projet de 40 à 60 % par rapport à l'utilisation constante des paramètres de qualité maximale.Édition de précision : comment fonctionne réellement la préservation des détails
Le mécanisme technique derrière la précision d'édition améliorée de GPT Image 1.5 implique plusieurs capacités interdépendantes :
Masquage basé sur le prompt (aucune sélection manuelle requise)
Contrairement à DALL-E 2 qui exigeait que les utilisateurs peignent manuellement les régions de masque, GPT Image 1.5 analyse les instructions d'édition en langage naturel pour identifier automatiquement les zones affectées. Lorsque vous écrivez : "Change la couleur de la chemise en vert", le modèle :
- Effectue une segmentation sémantique pour identifier la région de la chemise.
- Isole les informations de couleur dans cette région.
- Applique la transformation de couleur.
- Régénère uniquement la région modifiée.
- Estompe les bords pour maintenir des transitions naturelles.
Ce processus n'est pas parfait – le modèle utilise le masque comme guide mais peut ne pas suivre les limites exactes avec une précision au pixel près. Des objets superposés complexes (comme des mains tenant des objets devant les vêtements) peuvent encore créer des artefacts sur les bords.
Technologie de préservation de l'identité
Pour les images contenant des personnes, GPT Image 1.5 implémente une préservation de l'identité faciale qui maintient les traits reconnaissables à travers les éditions. Cela s'appuie sur des techniques similaires à celles utilisées dans les systèmes de reconnaissance faciale :
- Extraction d'embeddings faciaux (représentations mathématiques des traits distinctifs).
- Contrainte des sorties générées pour maintenir des embeddings similaires.
- Préservation des caractéristiques clés (position des yeux, forme du nez, structure de la mâchoire).
- Maintien d'une texture et d'un teint de peau cohérents.
Algorithmes de cohérence de l'éclairage
L'un des aspects techniquement les plus impressionnants est la préservation de l'éclairage. Lorsque vous éditez la couleur ou la position d'un objet, GPT Image 1.5 préserve :
- La direction et l'angle de la lumière
- Les motifs de projection d'ombres
- Les reflets spéculaires
- L'occlusion ambiante (ombres dans les zones en retrait)
- La cohérence de la température de couleur
Cela empêche le problème courant de l'image IA où les éléments édités semblent "collés" parce que leur éclairage ne correspond pas à la scène.
Limites de la précision actuelle
Malgré les améliorations, plusieurs scénarios défient encore la précision de GPT Image 1.5 :
- Scènes hautement complexes : Les images avec plus de 10 objets distincts peuvent subir des modifications involontaires.
- Matériaux transparents : Le verre, l'eau et les tissus semi-transparents peuvent créer des artefacts.
- Détails fins : Les bijoux, les motifs complexes et le petit texte en arrière-plan peuvent perdre en qualité.
- Passages d'édition multiples : Après 5 à 6 éditions successives, les erreurs accumulées peuvent commencer à se multiplier.
Capacités et limites du rendu de texte
La génération de texte dans les images IA a été historiquement une faiblesse notoire. GPT Image 1.5 fait des progrès significatifs mais n'a pas encore résolu complètement le problème.
Ce qui s'est réellement amélioré
Le modèle peut désormais générer de manière fiable :
- Des titres courts (1 à 5 mots) dans des polices de caractères grasses et grandes.
- Des étiquettes de produits avec 2 ou 3 lignes de texte.
- Des mises en page de style magazine avec des titres et des sous-titres lisibles.
- Le texte des logos dans des polices courantes (bien que les conceptions de logos complexes restent un défi).
- Des étiquettes d'infographie pour les éléments de visualisation de données.
Bonnes pratiques pour le rendu de texte
Pour maximiser la qualité du texte dans vos images générées :
- Soyez bref : 3 à 5 mots par élément de texte donnent les meilleurs résultats.
- Utilisez des polices courantes : Des descriptions comme "police sans-serif grasse" ou "police serif propre" fonctionnent mieux que des noms de polices spécifiques.
- Spécifiez explicitement la position du texte : "Titre centré en haut" plutôt que simplement "ajouter un titre".
- Demandez un contraste élevé : "Texte blanc sur fond sombre" assure la lisibilité.
- Évitez les petites tailles de police : Le texte plus petit que l'équivalent de 18 pt environ est rarement rendu proprement.
Limites persistantes du texte
Malgré les améliorations, vous rencontrerez toujours des problèmes avec :
- Les longs paragraphes : Tout texte dépassant 20 à 30 mots comporte souvent des fautes d'orthographe.
- Les polices stylisées : L'écriture manuscrite, les scripts décoratifs ou la typographie lourdement modifiée.
- Les scripts non latins : L'arabe, le chinois, le japonais et d'autres systèmes de texte non occidentaux montrent des résultats incohérents [Non vérifié – données de test limitées disponibles].
- Le texte sur des surfaces courbes : Les étiquettes sur des bouteilles ou le texte suivant des chemins courbes se déforment souvent.
- Notation mathématique : Les équations, les formules et les symboles spéciaux restent peu fiables.

GPT Image 1.5 vs GPT Image 1 : qu'est-ce qui a changé ?
Comprendre les différences entre GPT Image 1 et 1.5 aide à clarifier si la mise à jour de votre flux de travail est justifiée.
Tableau de comparaison côte à côte
| Caractéristique | GPT Image 1 | GPT Image 1.5 | Amélioration |
|---|---|---|---|
| Vitesse de génération | 35-55 secondes | 8-18 secondes | 3-4× plus rapide |
| Suivi des instructions | Précision modérée | Haute précision | +60 % d'adhésion au prompt [Estimé] |
| Précision d'édition | Changements involontaires fréquents | Modifications ciblées | 85 % de préservation des détails [Estimé] |
| Rendu de texte | Médiocre/Peu fiable | Bon pour les titres | Phrases de 3-5 mots lisibles de façon cohérente |
| Tarification API | Prix de base | 20 % moins cher | Réduction des coûts |
| Qualité d'image | Élevée | Élevée | Plafond de qualité comparable |
| Tailles supportées | 3 rapports d'aspect | 3 rapports d'aspect (identiques) | Aucun changement |
| Itérations d'édition | 3-4 avant dégradation | 6-8 avant dégradation | ~2× profondeur d'itération |
| Préservation du logo | Médiocre | Bonne | Critique pour le travail de marque |
| Cohérence du visage | Modérée | Élevée | Vital pour les photos de modèles |
Quand GPT Image 1 peut encore être préféré
Malgré son âge, GPT Image 1 conserve des avantages dans des scénarios spécifiques :
- Exploration artistique : Certains utilisateurs rapportent que GPT Image 1 donne des interprétations plus "créatives" lorsque vous voulez des résultats inattendus.
- Intégration dans des flux de travail hérités : Les pipelines de production existants construits autour du comportement de GPT Image 1 peuvent nécessiter des ajustements pour la 1.5.
- Sensibilité au coût pour les tâches simples : Pour une génération simple de texte en image sans édition, la différence de prix de 20 % s'accumule à grande échelle [Non vérifié – dépend des paliers de prix au volume].
Recommandations de migration
Si vous utilisez actuellement GPT Image 1 :
- Testez en parallèle : Exécutez les mêmes prompts sur les deux modèles pour identifier les différences de comportement.
- Mettez à jour votre bibliothèque de prompts : GPT Image 1.5 répond mieux aux prompts structurés basés sur des contraintes.
- Ajustez vos attentes de qualité : Les améliorations de vitesse peuvent nécessiter un recalibrage de vos calendriers de livraison.
- Vérifiez la cohérence des actifs de marque : Testez soigneusement la préservation des logos et des marques déposées avant de basculer les flux de travail de production.
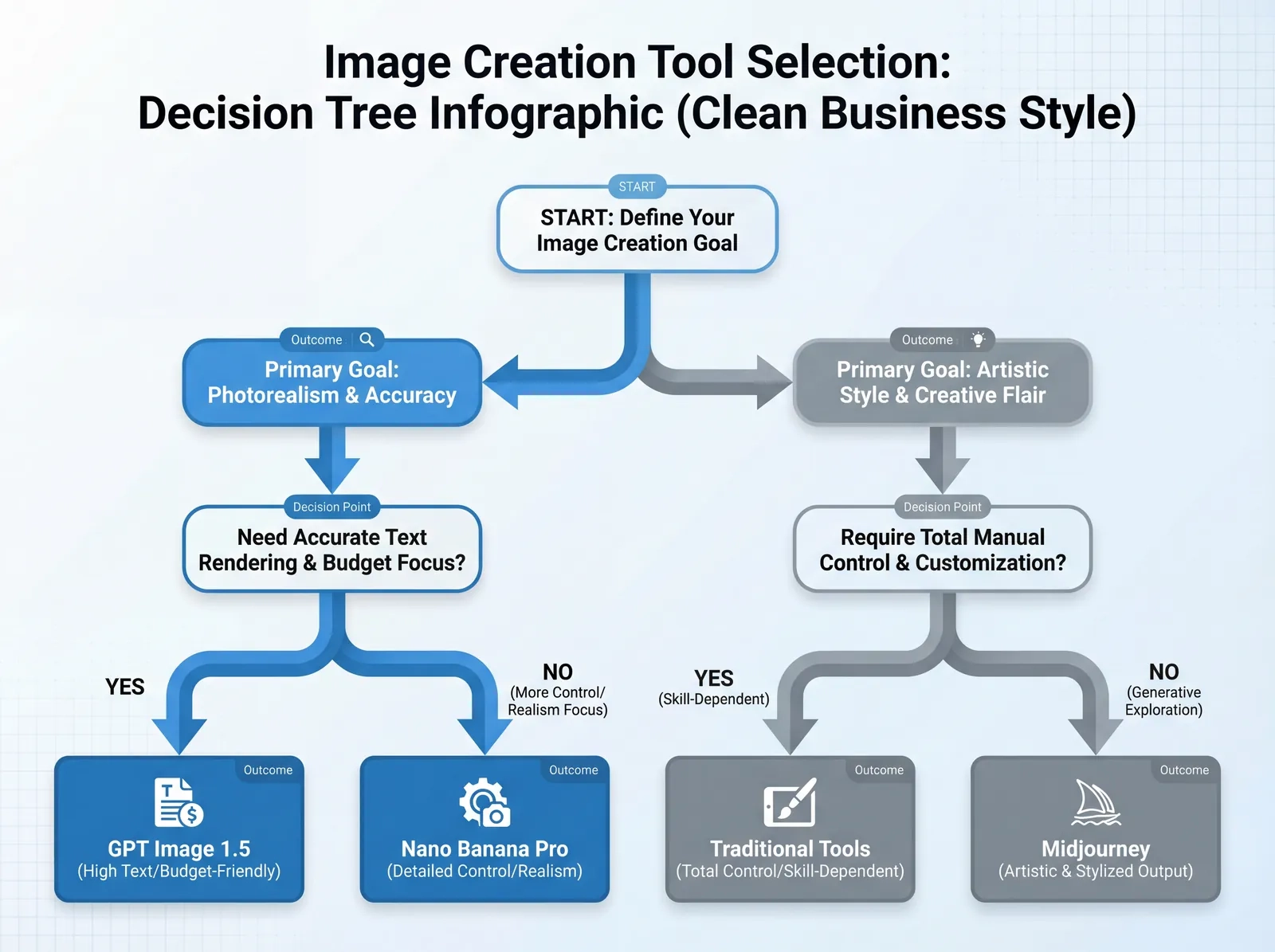
Comparaison complète des modèles : GPT Image 1.5 vs Concurrents
Le paysage concurrentiel de la génération d'images par IA comprend plusieurs alternatives puissantes, chacune ayant des forces distinctes.
GPT Image 1.5 vs Google Nano Banana Pro
Le Nano Banana Pro de Google (propulsé par Gemini 3 Pro) a émergé comme le principal concurrent de GPT Image 1.5, menant à ce que le PDG Sam Altman a appelé en interne une situation "Code Rouge", accélérant le calendrier de sortie de GPT Image 1.5.
- Sorties plus photoréalistes dans les scénarios de photographie de nature.
- Meilleure capture des tendances esthétiques actuelles.
- Gestion supérieure des scènes naturelles complexes (paysages, foules).
- Croissance de l'adoption plus rapide (contribuant à la montée des utilisateurs de Gemini de 450M à 650M entre juillet et octobre 2025).
- Suivi des instructions plus fiable pour les prompts structurés.
- Meilleur rendu de texte dans les mises en page et les designs.
- Préservation supérieure des détails pendant les éditions itératives.
- Résultats plus prévisibles et déterministes pour les flux de travail de production.
GPT Image 1.5 vs Midjourney
Midjourney reste un favori pour les artistes numériques et les professionnels de la création en raison de ses qualités esthétiques distinctives.
- Interprétation artistique et "vision" créative.
- Communauté forte et ressources d'ingénierie de prompts établies.
- Qualité esthétique cohérente à travers divers styles.
- Meilleur pour les compositions abstraites, conceptuelles et artistiques.
- Intégré au flux de travail ChatGPT (pas de changement de plateforme).
- Itération plus rapide pour les applications commerciales.
- Accès API pour les flux de travail automatisés.
- Sorties plus prévisibles pour les besoins de l'entreprise.
GPT Image 1.5 vs DALL-E 3
DALL-E 3, l'ancien modèle phare d'OpenAI avant la série GPT Image, est désormais obsolète et perdra son support le 12 mai 2026.
- Génération significativement plus rapide.
- Meilleures capacités d'intégration API.
- Suivi des instructions amélioré.
- Précision d'édition avancée sans masquage manuel.
- Coûts opérationnels réduits.
Résumé du positionnement concurrentiel
| Modèle | Idéal pour | À éviter pour | Niveau de prix |
|---|---|---|---|
| GPT Image 1.5 | Flux de travail de production, actifs de marque, édition itérative | Projets purement artistiques | Milieu de gamme |
| Nano Banana Pro | Images de réseaux sociaux photoréalistes, esthétique contemporaine | Rendu de texte précis, travail de logo | Milieu de gamme |
| Midjourney | Interprétation artistique, travail conceptuel | Flux de travail API automatisés | Budget Premium |
| Stable Diffusion | Entraînement de modèles personnalisés, contrôle total | Solutions clés en main | Gratuit-Budget |

Comment accéder à GPT Image 1.5 : Guide de l'interface ChatGPT
Déployé mondialement le 16 décembre 2025, GPT Image 1.5 est désormais disponible pour tous les utilisateurs de ChatGPT, quel que soit leur niveau d'abonnement (Free, Plus, Team ou Enterprise).
Accès étape par étape via ChatGPT
- Naviguer vers les images ChatGPT
- Connectez-vous à votre compte ChatGPT sur chat.openai.com.
- Cliquez sur l'onglet "Images" dans la barre latérale gauche (nouveau depuis la mise à jour de décembre 2025).
- Cela ouvre l'interface dédiée à la génération d'images.
- Créer votre première image
- Saisissez un prompt descriptif dans le champ de texte (jusqu'à 2000 caractères).
- Cliquez sur "Générer" ou appuyez sur Entrée.
- Attendez 8 à 18 secondes pour la génération.
- Le modèle utilisera automatiquement GPT Image 1.5 – aucune sélection manuelle n'est nécessaire.
- Utilisation des fonctionnalités du Studio Créatif
- Après la génération, la barre latérale droite affiche des styles et des filtres prédéfinis.
- Cliquez sur n'importe quel préréglage pour appliquer des transformations sans écrire de prompts.
- Les options incluent : "Rendre photoréaliste", "Changer pour un éclairage de coucher de soleil", "Ajouter des ombres dramatiques", "Style photo produit professionnel".
- Ces préréglages sont particulièrement utiles pour les utilisateurs non techniques.
- Flux de travail d'édition itérative
- Sélectionnez une image générée existante.
- Écrivez des instructions d'édition en langage naturel : "change l'arrière-plan en une scène de plage".
- Le modèle préservera les éléments non mentionnés tout en apportant les changements demandés.
- Vous pouvez enchaîner 6 à 8 éditions avant qu'une dégradation de la qualité ne devienne perceptible.
- Téléchargement et exportation
- Cliquez sur l'icône de téléchargement sur n'importe quelle image générée.
- Les images sont exportées dans leur résolution native (1024×1024, 1024×1536, ou 1536×1024).
- Les liens restent valides pendant 24 heures (téléchargez rapidement les images importantes).
- Les images incluent des métadonnées C2PA pour l'authentification du contenu.
Caractéristiques et limites de l'interface
- Génération de texte en image.
- Transformation d'image en image (téléchargement d'images de référence).
- Édition en langage naturel.
- Application de styles prédéfinis.
- Sélection du rapport d'aspect (1:1, 3:4, 4:3).
- Sélection du niveau de qualité (ChatGPT utilise la qualité
auto). - Génération par lots de plusieurs variantes.
- Téléchargement direct de fichiers à partir d'URL externes.
- Paramètres de modèle personnalisés.
- Callbacks Webhook pour le traitement asynchrone.
Conseils de pro pour les utilisateurs de l'interface ChatGPT
- Exploiter le contexte de la conversation : GPT Image 1.5 dans ChatGPT se souvient des images et des prompts précédents au sein de la même conversation, ce qui vous permet de vous référer à "l'image précédente" ou à "la version avec la veste bleue".
- Combiner le chat textuel avec la génération d'images : Demandez à ChatGPT de brainstormer des idées de prompts ou d'affiner votre description avant la génération, en utilisant les capacités textuelles de l'IA pour améliorer vos prompts visuels.
- Enregistrer les prompts réussis : Tenez un document avec les prompts qui ont donné de bons résultats, car une structure de prompt cohérente mène à une qualité cohérente.
- Utiliser la fonctionnalité d'annulation : Si une édition ne se passe pas comme prévu, vous pouvez revenir aux versions précédentes et essayer des instructions alternatives.
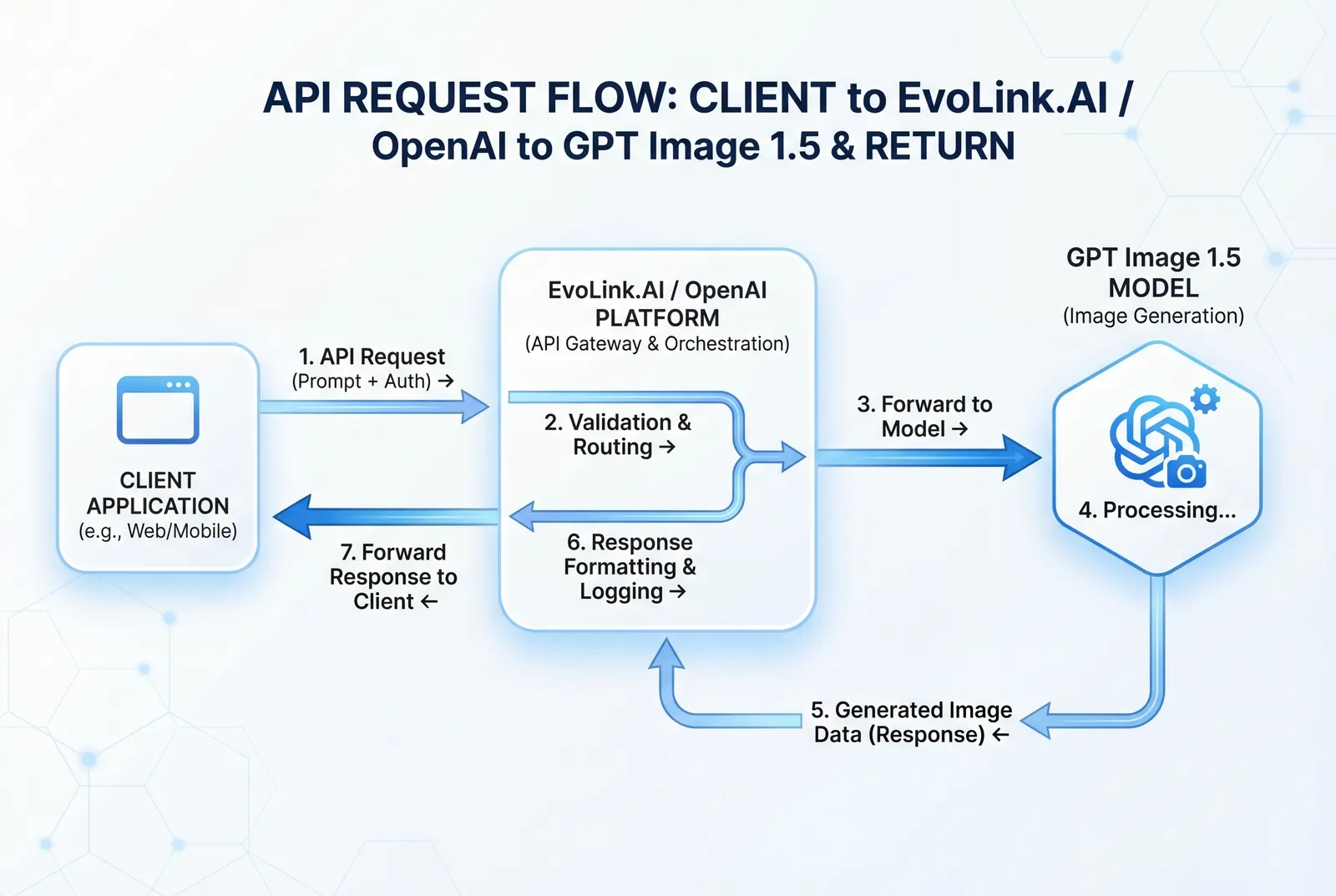
Accès API via EvoLink.AI et la plateforme OpenAI
Intégration de l'API EvoLink.AI
gpt-image-1.5-lite, documenté dans son portail développeur.Structure de base d'une requête API (EvoLink.AI)
{
"model": "gpt-image-1.5-lite",
"prompt": "Une photo de produit professionnelle d'un smartphone sur un fond blanc propre avec un éclairage de studio doux",
"size": "1024x1024",
"quality": "high",
"n": 1
}Paramètres requis
- model : Doit être
"gpt-image-1.5-lite"pour GPT Image 1.5. - prompt : Description textuelle (max 2000 jetons).
- size : Dimensions de l'image (options :
1:1,3:4,4:3,1024x1024,1024x1536,1536x1024).
Paramètres optionnels
- quality :
low,medium,high, ouauto(par défaut :auto). - image_urls : Tableau d'URL d'images de référence pour les modes image-en-image ou édition (supporte 1-16 images, max 50 Mo par image, formats : .jpeg, .jpg, .png, .webp).
- n : Nombre d'images (actuellement supporte uniquement
1).
Traitement asynchrone
- Soumettez votre demande de génération → Vous recevez un ID de tâche.
- Interrogez le point de terminaison de statut de tâche avec l'ID de tâche.
- Récupérez les URL d'images générées lorsque le statut = "completed".
- Les URL d'images restent valides pendant 24 heures.
Accès API direct via la plateforme OpenAI
/v1/images/generations.Configuration de l'authentification
- Créez un compte sur platform.openai.com.
- Effectuez la vérification de l'organisation API (requise pour les modèles GPT Image).
- Générez une clé API dans votre tableau de bord.
- Incluez la clé dans les en-têtes de requête :
Authorization: Bearer VOTRE_CLÉ_API.
Exemple de requête (SDK Python OpenAI)
from openai import OpenAI
client = OpenAI(api_key="votre-clé-api")
response = client.images.generate(
model="gpt-image-1.5",
prompt="Un salon minimaliste moderne avec de grandes fenêtres et une lumière naturelle",
size="1536x1024",
quality="high",
n=1
)
image_url = response.data[0].urlMode d'édition d'image
Pour éditer des images existantes :
response = client.images.edit(
model="gpt-image-1.5",
image=open("input_image.png", "rb"),
prompt="Change la couleur des murs en vert sauge",
size="1024x1024"
)Comparaison API : EvoLink.AI vs OpenAI Direct
| Caractéristique | EvoLink.AI | OpenAI Direct |
|---|---|---|
| Accès au modèle | gpt-image-1.5-lite | gpt-image-1.5 |
| Traitement | Asynchrone (basé sur les tâches) | Options synchrone + asynchrone |
| Entrée d'image | Basé sur URL uniquement | Téléchargement de fichier + URL |
| Transparence des prix | Consulter le tableau de bord EvoLink.AI | Prix OpenAI publiés |
| Services additionnels | Regroupé avec d'autres API IA | Uniquement génération d'images |
| Documentation | Documentation evolink.ai | platform.openai.com/docs |
| Limites de débit | Variable selon le forfait | Basé sur les paliers (consulter la documentation OpenAI) |
Bonnes pratiques pour l'API
- Implémenter une logique de réessai : Des erreurs temporaires peuvent survenir pendant les pics de charge.
- Mettre en cache les générations réussies : Enregistrez les URL d'images et les prompts associés pour référence ultérieure.
- Surveiller les limites de débit : Les deux plateformes imposent des limites de requêtes basées sur votre niveau d'abonnement.
- Optimiser les modèles de prompts : Créez des structures de prompts réutilisables pour des résultats cohérents.
- Gérer l'expiration des images : Téléchargez et stockez les images dans la fenêtre de 24 heures.
- Utiliser les niveaux de qualité de manière stratégique : Réservez la qualité
highpour les rendus de production finaux afin de réduire les coûts.
Structure tarifaire et stratégies d'optimisation des coûts
Comprendre la structure des coûts vous aide à budgétiser efficacement et à identifier les opportunités d'optimisation.
Tarifs officiels OpenAI (en date de décembre 2025)
- Génération d'images : Basé sur la taille et le niveau de qualité.
- Entrées d'images (pour l'édition) : 20 % moins cher que GPT Image 1.
- Sorties d'images : 20 % moins cher que GPT Image 1.
Tarifs EvoLink.AI
- Le niveau d'abonnement (varie selon le volume d'appels API inclus).
- Les frais par requête au-delà du quota inclus.
- Des remises potentielles sur le volume pour les clients entreprises.
Stratégies d'optimisation des coûts
1. Sélection du niveau de qualité
quality a un impact significatif sur le temps de génération et le coût :Qualité basse : Plus rapide, moins cher (idéal pour les essais de concept)
Qualité moyenne : Équilibré (adapté à la plupart des utilisations)
Qualité haute : Plus lent, plus cher (actifs prêts pour la production)
Qualité Auto : Le modèle décide en fonction de la complexité du prompt2. Optimisation du rapport d'aspect
Les images plus grandes sont plus coûteuses à générer. Hiérarchie des coûts :
1024×1024 (1:1) < 1024×1536 (3:4) = 1536×1024 (4:3)3. Traitement par lots vs temps réel
Pour les flux de travail non urgents :
- Mettez plusieurs demandes de génération en file d'attente.
- Traitez-les pendant les heures creuses (si les tarifs varient selon l'heure).
- Utilisez le traitement asynchrone pour éviter les reprises suite à des délais d'attente.
4. Efficacité des prompts
Les prompts plus longs consomment plus de jetons. Techniques d'optimisation :
- Supprimer les adjectifs inutiles.
- Utiliser des formats structurés (attributs séparés par des virgules plutôt que des paragraphes).
- Éviter les descriptions redondantes.
- Tester des prompts minimaux viables.
Exemple de transformation :
Inefficace (87 jetons) : "Je voudrais que vous créiez une magnifique, impressionnante,
étonnante photo professionnelle d'un smartphone moderne posé sur un arrière-plan blanc,
propre et immaculé, avec un éclairage de studio doux et gracieux venant du haut."
Efficace (25 jetons) : "Photo de produit professionnelle : smartphone sur fond blanc,
éclairage de studio doux par le haut."5. Mise en cache et réutilisation
- Enregistrez les générations réussies avec leurs métadaten (prompt, paramètres, horodatage).
- Créez une bibliothèque d'images de base pour des éditions futures au lieu de les régénérer.
- Implémentez une recherche sémantique dans votre cache d'images pour trouver des actifs existants avant d'en générer de nouveaux.
6. Flux de travail hybrides
Combinez la génération IA avec les outils traditionnels :
- Générez des images de base avec l'IA.
- Ajoutez du texte/logos complexes dans Figma/Photoshop (pour contourner les limites de texte de l'IA).
- Utilisez l'IA pour créer des variations de designs éprouvés plutôt que de partir de zéro.
- Flux de travail tout IA : 10 itérations × 0,XX $ par image = X,XX $ au total.
- Flux de travail hybride : 3 itérations IA + affinement manuel = X,XX $ + temps de conception.
- Si le temps de conception est plus rapide que 7 itérations IA, l'approche hybride permet d'économiser de l'argent.
Remises sur volume pour les entreprises
- Plus de 10 000 images par mois.
- Plus de 1 000 $ de dépenses API mensuelles.
- Engagements pluriannuels.
Études de cas réels et applications
Comprendre comment différentes industries appliquent GPT Image 1.5 met en évidence sa valeur pratique.
Catalogues de produits E-commerce
- Photographiez le produit une fois sur un fond neutre.
- Utilisez le mode image-en-image pour générer des variantes dans divers environnements.
- La préservation des détails garantit que l'apparence du produit reste cohérente.
- Le logo et l'identité de la marque restent intacts à travers toutes les variantes.
Actifs de marketing et de marque
- Générer des designs de base utilisant les couleurs et le style de la marque.
- Itérer sur les éditions tout en préservant les logos et l'identité visuelle.
- Créer rapidement des variantes pour les tests A/B.
- Produire des versions localisées pour différents marchés.
Production de contenu pour les réseaux sociaux
- Générer l'image maîtresse dans la plus grande taille requise.
- Créer des recadrages/variantes spécifiques à chaque plateforme.
- Appliquer des filtres de style pour l'esthétique appropriée à chaque canal.
- Ajouter des superpositions de texte (ou générer le texte via l'IA pour les titres).
- Instagram (1:1) : 1024×1024.
- Instagram Stories (3:4) : 1024×1536.
- Twitter/X (4:3) : 1536×1024.
- Tous générés à partir d'un seul prompt en changeant le paramètre de taille.
Visualisation de concepts de design
- Prototyper des concepts visuels en succession rapide.
- Tester plusieurs directions de style.
- Recueillir des retours sur les options.
- Affiner la direction choisie jusqu'à la qualité de production.
Éditorial et édition
- Générer des illustrations conceptuelles pour des sujets abstraits.
- Créer des visualisations de données avec des étiquettes de texte lisibles.
- Produire des mises en page de style magazine avec titres.
- Développer des thèmes visuels cohérents à travers des séries d'articles.
Matériel de formation et d'éducation
- Générer des illustrations basées sur des scénarios (situations de travail, démonstrations de sécurité).
- Créer des schémas et des organigrammes simplifiés.
- Assurer une représentation diverse dans les supports de formation.
- Développer des visuels sur mesure pour des contextes d'apprentissage spécifiques.
Immobilier et architecture
- Générer des intérieurs meublés à partir de photos de pièces vides.
- Visualiser des concepts de rénovation.
- Créer des images de style de vie pour le marketing immobilier.
- Développer plusieurs options de styles de design pour le choix du client.
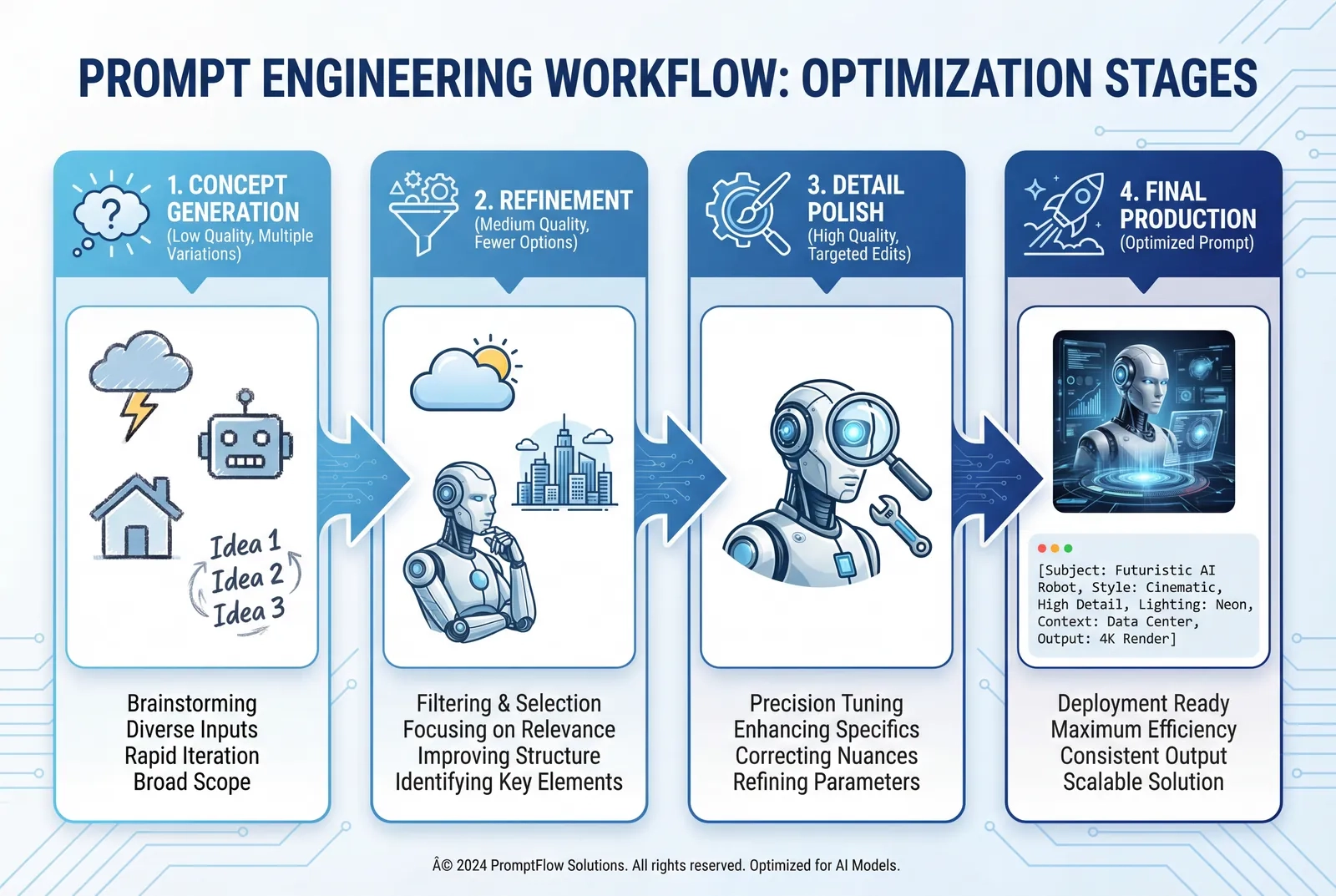
Ingénierie de prompt avancée pour de meilleurs résultats
La maîtrise de la structure des prompts améliore considérablement la qualité du résultat et réduit les itérations.
Anatomie d'un prompt efficace
Les prompts performants suivent cette structure :
[SUJET] + [ACTION/POSE] + [CADRE/CONTEXTE] + [STYLE/ESTHÉTIQUE] +
[SPÉCIFICATIONS TECHNIQUES] + [RÈGLES DE COMPOSITION]Sujet : Femme d'affaires professionnelle en costume bleu marine
Action : Se tenant confiante, les bras croisés
Cadre : Bureau vitré moderne avec vue sur la ville à travers les fenêtres
Style : Esthétique de photographie d'entreprise professionnelle
Technique : Faible profondeur de champ, lumière naturelle de la fenêtre venant de gauche
Composition : Sujet positionné dans le tiers droit de l'image, espace négatif à gaucheFormules de prompts pour les scénarios courants
Photographie de produit
"Photo de produit professionnelle de [PRODUIT] sur [ARRIÈRE-PLAN],
[STYLE D'ÉCLAIRAGE], [ANGLE DE CAMÉRA], [AMBIANCE], qualité publicitaire haut de gamme"Exemple : "Photo de produit professionnelle d'une montre de luxe sur une surface en marbre noir, éclairage latéral dramatique avec ombres douces, angle de 45 degrés, ambiance élégante et haut de gamme, qualité publicitaire premium"
Portrait photographique
"[TYPE DE PRISE DE VUE] portrait de [DESCRIPTION DU SUJET], [EXPRESSION FACIALE],
[VÊTEMENTS], [ARRIÈRE-PLAN], [ÉCLAIRAGE], [STYLE DE RÉGLAGE CAMÉRA]"Exemple : "Portrait en gros plan d'une femme d'âge mûr avec des cheveux gris courts, sourire authentique, portant une veste en jean décontractée, arrière-plan extérieur flou, lumière naturelle de l'heure dorée, faible profondeur de champ"
Scène de vie (Lifestyle)
"Scène de [MOMENT DE LA JOURNÉE] montrant [ACTIVITÉ] dans [LIEU],
[HUMEUR/ATMOSPHÈRE], [DESCRIPTION DES PERSONNES], [RÉFÉRENCE DE STYLE]"Exemple : "Scène matinale montrant un petit-déjeuner en famille dans une cuisine scandinave moderne, atmosphère chaleureuse et accueillante, famille diverse de quatre personnes, style de photographie lifestyle naturelle"
Infographie/Visualisation de données
"Infographie claire montrant [DONNÉES/CONCEPT], [MISE EN PAGE],
[SCHÉMA DE COULEURS], [ÉLÉMENTS DE TEXTE], qualité de design professionnel"Exemple : "Infographie claire montrant la croissance trimestrielle des revenus, mise en page de graphique à barres verticales, schéma de couleurs bleu et blanc, titre en gras 'Résultats 2025 T4' en haut avec étiquettes de pourcentage de croissance, qualité de design business professionnel"
Stratégies pour le prompt négatif
Bien que GPT Image 1.5 ne supporte pas officiellement le prompt négatif de la même manière que Stable Diffusion, vous pouvez vous éloigner des éléments indésirables en utilisant une formulation positive :
Flux de travail pour un affinement en plusieurs étapes
Pour les projets complexes nécessitant une haute qualité :
- Génération de concept initiale (qualité basse, prompt large)
- Générer 3 à 5 variations.
- Identifier une direction prometteuse.
- Itération d'affinement (qualité moyenne, prompt détaillé)
- Ajouter des contraintes spécifiques au concept retenu.
- Ajuster la composition, l'éclairage et les éléments.
- Tester 2 ou 3 variantes.
- Polissage des détails (qualité haute, prompts d'édition précis)
- Apporter des modifications ciblées à la version presque finale.
- Ajuster les éléments spécifiques un par un.
- Préserver tout sauf les éléments modifiés.
- Production finale (qualité haute)
- Régénérer l'image avec un prompt optimisé intégrant tous les enseignements.
- Exporter en pleine résolution.
Bibliothèques de prompts et versionnage
Maintenez une bibliothèque de prompts structurée :
Projet : Campagne Vacances 2025
Version : 1.0
Date : décembre 2025
Modèle de prompt de base :
"Scène de vacances festive montrant [SUJET], atmosphère chaleureuse et cosy,
éclairage doré, photographie professionnelle, [ÉLÉMENTS_SPÉCIFIQUES]"
Variations :
V1.0 : Concept initial → ajout de "faible profondeur de champ"
V1.1 : Retour client → changement de "chaleureux cosy" à "lumineux joyeux"
V1.2 : Version finale → ajout de "couleurs d'accent rouge et or"
Prompt gagnant : [Version finale optimisée]
Images générées : [Liens vers les résultats enregistrés]Cette documentation évite de redécouvrir des formules réussies et permet la collaboration d'équipe.
Erreurs courantes à éviter lors de l'utilisation de GPT Image 1.5
Apprendre des erreurs typiques accélère votre maîtrise de l'outil et évite les efforts inutiles.
1. Prompts vagues et non structurés
2. Espérer un texte parfait dès le premier essai
3. Ignorer l'impact des niveaux de qualité
4. Sur-édition au-delà des limites du modèle
5. Ne pas conserver les prompts réussis
6. Préparation insuffisante des images de référence
- En haute résolution (au moins 1024px sur le bord le plus long).
- Bien éclairées avec une mise au point claire sur le sujet.
- D'une composition propre sans éléments distrayants.
- Dans un format correct (.jpg, .png, .webp).
7. Attentes de précision architecturale/technique
8. Négliger les délais d'expiration des images
9. Structure de prompt incohérente entre les projets
10. Ne pas tester les modèles concurrents
Limites et quand choisir des outils alternatifs
GPT Image 1.5 représente un bond en avant significatif mais n'est pas universellement optimal. Comprendre ses limites vous guide vers le bon outil.
Limites techniques
- Cohérence des scènes complexes
- Les images avec plus de 10 objets distincts présentent souvent des incohérences spatiales.
- Les éléments transparents superposés (verre, eau) créent des artefacts.
- Les scènes avec plusieurs personnes peinent avec la précision anatomique dans les foules.
- Conséquence : Photos de groupe nombreuses, arrangements de produits complexes, illustrations détaillées.
- Plafond du réalisme photographique
- Certaines sorties conservent le "look IA" (lissage excessif, perfection non naturelle).
- La texture de la peau et les détails des pores paraissent parfois artificiels.
- Certains scénarios d'éclairage (soleil de midi dur, reflets complexes) restent difficiles.
- Conséquence : Photographie de mode haut de gamme, travail documentaire, portraits naturalistes.
- Frontières du rendu de texte
- Le texte de plus de 20 à 30 mots contient des erreurs.
- Les scripts non latins sont peu fiables.
- Les polices stylisées et manuscrites sont incohérentes.
- Le texte sur des surfaces courbes se déforme.
- Conséquence : Infographies avec texte étendu, contenu multilingue, typographie décorative.
- Spécificité culturelle et géographique
- Les données d'entraînement semblent biaisées vers les contextes occidentaux [Non vérifié – déduit de l'analyse des résultats].
- L'architecture régionale, les vêtements et les détails culturels peuvent manquer d'authenticité.
- Les sous-cultures de niche et les contextes spécialisés sont sous-représentés.
- Conséquence : Marketing culturellement spécifique, campagnes régionales, besoins de représentation authentique.
- Limites de la profondeur d'itération
- La qualité se dégrade après 6 à 8 éditions successives.
- Les artefacts accumulés se multiplient au fil des passages.
- La cohérence du visage et du logo diminue lors d'itérations excessives.
- Conséquence : Projets nécessitant plus de 10 cycles d'affinement, édition collaborative extensive.
Quand choisir des outils alternatifs
Choisissez Nano Banana Pro si :
- Le photoréalisme est l'exigence primaire.
- Le contenu des réseaux sociaux doit refléter les tendances esthétiques contemporaines.
- Les scènes naturelles (paysages, foules, événements) dominent vos besoins.
- La vitesse d'adoption et la croissance de l'écosystème sont importantes pour l'onboarding de l'équipe.
Choisissez Midjourney si :
- L'interprétation artistique ajoute de la valeur par rapport à la précision littérale.
- Le travail conceptuel, abstrait ou stylisé correspond à votre marque.
- Les bibliothèques de prompts et les styles pilotés par la communauté aident votre flux de travail.
- La vision créative est plus importante que le contrôle de la production.
Choisissez Stable Diffusion si :
- Vous avez besoin d'un contrôle total sur l'entraînement et la personnalisation du modèle.
- Les contraintes budgétaires exigent une solution gratuite/open-source.
- Une équipe technique peut gérer l'auto-hébergement et l'optimisation.
- Des ajustements spécialisés sont nécessaires pour des applications de niche.
Choisissez la photographie/design traditionnel si :
- La précision technique n'est pas négociable (architecture, ingénierie, médical).
- Les exigences légales imposent un contenu authentifié créé par l'homme.
- Les valeurs de la marque mettent l'accent sur le talent humain plutôt que sur l'assistance par IA.
- Le budget permet des services professionnels et la qualité justifie le coût.
Choisissez des flux de travail hybrides si :
- Les projets nécessitent à la fois l'efficacité de l'IA et le contrôle qualité humain.
- Les éléments de texte dépassent les capacités de l'IA.
- Les directives de marque exigent une cohérence absolue.
- La conformité et la vérification de l'authenticité sont critiques.
Considérations éthiques et légales
Questions fréquemment posées (FAQ)
1. Combien coûte GPT Image 1.5 par rapport à l'embauche d'un designer ?
Cependant, les designers apportent une direction créative, une compréhension de la marque et une précision technique que l'IA ne peut pas égaler. L'approche optimale pour de nombreuses entreprises est un modèle hybride : utilisez l'IA pour les gros volumes de contenu à faible risque (réseaux sociaux, tests de concepts, images de style banque d'images) et réservez le temps des designers pour les campagnes majeures, le travail de définition de la marque et les projets nécessitant une vision créative humaine.
2. GPT Image 1.5 peut-il maintenir une apparence de personnage cohérente sur plusieurs images ?
- Générer l'image initiale du personnage avec une description détaillée.
- Enregistrer cette image comme votre référence de personnage.
- Utiliser le mode image-en-image avec cette référence pour les générations suivantes.
- Maintenir une structure de prompt cohérente décrivant le personnage.
- Accepter que des variations mineures surviennent – la cohérence parfaite pour des générations entièrement nouvelles n'est pas encore fiable.
Pour les projets nécessitant une cohérence absolue (séries d'animation, mascottes de marque, campagnes continues), envisagez d'utiliser l'IA pour créer le concept initial puis travaillez avec un illustrateur pour créer une fiche de modèle définie qui servira de référence pour tout le travail futur.
3. GPT Image 1.5 fonctionne-t-il dans d'autres langues que l'anglais ?
- Espagnol, français, allemand, italien : Généralement fonctionnel avec une certaine réduction de la précision par rapport à l'anglais.
- Langues CJK (chinois, japonais, coréen) : Compréhension du prompt présente mais le rendu du texte dans les images reste peu fiable.
- Autres langues : Données de test limitées disponibles [Non vérifié].
4. Comment GPT Image 1.5 gère-t-il le droit d'auteur et la propriété intellectuelle des images générées ?
- Propriété intellectuelle de tiers : Le modèle est conçu pour refuser de générer des contenus basés sur des personnages protégés, des logos déposés ou l'image de célébrités identifiables.
- Données d'entraînement : Le modèle a été entraîné sur des images accessibles publiquement, ce qui peut inclure des matériaux protégés utilisés selon les doctrines d'usage équitable (fair use) pour l'entraînement.
- Usage commercial : Les sorties peuvent généralement être utilisées commercialement, mais vérifiez les conditions actuelles d'OpenAI et votre cas d'utilisation spécifique.
- Attribution : OpenAI n'impose pas d'attribution pour les images générées par IA, mais certaines plateformes et contextes peuvent exiger la divulgation du caractère généré par l'IA.
5. Puis-je utiliser GPT Image 1.5 pour éditer des photos existantes que je possède ?
- Télécharger vos propres photos.
- Demander des modifications spécifiques via des prompts en langage naturel.
- Préserver les éléments originaux tout en changeant les traits spécifiés.
- Générer des variations de vos images existantes.
- La photo originale est de haute qualité (au moins 1024px).
- L'éclairage est bon et le sujet est clairement défini.
- L'arrière-plan n'est pas excessivement complexe.
- Votre demande d'édition est spécifique et ciblée.
6. Quelle est la différence entre GPT Image 1.5 et GPT Image 1.5 Lite ?
gpt-image-1.5-lite) est la désignation du modèle API utilisée par des plateformes comme evolink.ai. Selon la documentation disponible, "Lite" se réfère au nom du point de terminaison de l'API plutôt qu'à une version aux capacités réduites. Le modèle accessible via ce point de terminaison semble être le même modèle phare GPT Image 1.5 disponible dans ChatGPT.Certaines plateformes peuvent proposer des niveaux de qualité additionnels ou des options de paramètres qui pourraient être décrits sous des noms "Lite" vs "Full". Cependant, le modèle officiel d'OpenAI s'appelle simplement "GPT Image 1.5". S'il existe des différences de coût ou de capacité entre les implémentations des plateformes, consultez la documentation de votre fournisseur d'API spécifique pour plus de précisions.
7. Combien de temps les URL d'images générées sont-elles valides et comment dois-je enregistrer les images ?
- Téléchargement immédiat : Configurez des téléchargements automatisés dans votre flux de travail pour capturer les images dès la génération.
- Stockage Cloud : Téléchargez les images sur votre propre S3, Google Cloud Storage ou service similaire pour une conservation permanente.
- Conservation des métadonnées : Archivez les prompts associés, les paramètres et les horodatages de génération avec chaque image pour référence future.
- Conventions de nommage : Utilisez des noms de fichiers descriptifs et recherchables incluant les identifiants de projet et les numéros de version.
- Stratégie de sauvegarde : Maintenez des copies redondantes pour les actifs commerciaux critiques.
1. Générer l'image → Réception d'une URL temporaire
2. Télécharger l'image dans l'heure sur votre stockage local/cloud
3. Enregistrer l'URL permanente dans votre base de données
4. Supprimer l'URL temporaire d'OpenAI de vos archives
5. Se référer à votre URL de stockage permanente à l'avenir8. GPT Image 1.5 peut-il générer des images adaptées à l'impression ou est-ce seulement pour un usage numérique ?
- 1024×1024 pixels (Carré)
- 1024×1536 pixels (Portrait)
- 1536×1024 pixels (Paysage)
| Taille d'impression | DPI requis | Résolution idéale | GPT Image 1.5 OK ? |
|---|---|---|---|
| Réseaux sociaux | 72 DPI | 1200×1200 | ✓ Oui |
| Hero de site web | 72-96 DPI | 1920×1080 | ✓ Oui |
| Diapositives de présentation | 96-150 DPI | 1920×1080 | ✓ Oui |
| Carte de visite | 300 DPI | 1050×600 | ⚠️ Limite |
| Tirage photo 8×10" | 300 DPI | 2400×3000 | ✗ Non |
| Page de magazine entière | 300 DPI | 2550×3300 | ✗ Non |
| Panneau publicitaire | 150 DPI+ | 14400×4800+ | ✗ Non |
- Upscale IA : Utilisez des outils d'upscaling spécialisés (Topaz Gigapixel, Real-ESRGAN) pour augmenter la résolution après la génération.
- Limitation de la taille d'impression : Utilisez les images générées par IA uniquement pour les petits éléments d'impression (icônes, petites illustrations) plutôt que pour des pages entières.
- Stratégie Digital-First : Priorisez la génération IA pour les canaux numériques et utilisez la photographie/illustration traditionnelle pour les campagnes imprimées.
- Conversion vectorielle : Convertissez les sorties IA en format vectoriel pour les logos et graphiques simples afin de permettre une utilisation indépendante de la résolution.
9. GPT Image 1.5 est-il meilleur que Midjourney pour le travail de design professionnel ?
- Vous avez besoin d'un contrôle précis sur les éditions itératives.
- L'intégration du flux de travail avec ChatGPT aide votre équipe.
- Le rendu de texte dans les images est important pour vous.
- L'automatisation via API est requise.
- La préservation des logos et des éléments de marque est cruciale.
- La vitesse (4x plus rapide) justifie une qualité artistique légèrement inférieure.
- Les fonctionnalités d'entreprise et le support sont prioritaires.
- L'interprétation artistique élève votre travail.
- La qualité esthétique est la priorité absolue.
- Les bibliothèques de prompts et les styles de la communauté correspondent à votre marque.
- Vous créez de l'art conceptuel, des illustrations ou des campagnes créatives.
- Un flux de travail basé sur Discord convient à la structure de votre équipe.
- Des solutions économes pour votre budget sont nécessaires.
- Utilisez Midjourney pour les images hero, les bannières et le contenu créatif phare.
- Utilisez GPT Image 1.5 pour les variantes de produits, le contenu des réseaux sociaux et les revues itératives avec les clients.
- Utilisez le design traditionnel pour les touches finales et les exigences techniques.
10. Qu'advient-il de GPT Image 1 maintenant que la version 1.5 est disponible ?
- Performance supérieure (génération 4x plus rapide).
- Meilleur suivi des instructions.
- Précision d'édition avancée.
- Coûts d'entrée et de sortie diminués de 20 %.
- Développement et améliorations continus.


