
Por qué las aplicaciones IA multi-modelo necesitan una sola capa de API unificada
Resumen
Las aplicaciones IA multi-modelo se están convirtiendo en la norma. Un producto puede usar un modelo para chat, otro para asistencia en programación, otro para extracción estructurada, y modelos de imagen o video separados para flujos de trabajo multimedia.
La parte difícil no es solo llamar a más APIs. La parte difícil es mantener bajo control la selección de modelos, el seguimiento de uso, la facturación, las políticas de costos, el comportamiento de fallback y las operaciones en producción a medida que la combinación de modelos cambia.
Una capa de API unificada ofrece a los equipos un único punto de control entre el código de la aplicación y los modelos de IA compatibles. No hace que todos los modelos se comporten igual ni elimina la necesidad de evaluación. Su valor es arquitectónico: proporciona a los equipos de producto e infraestructura un lugar estable para gestionar el acceso a modelos, el cambio entre ellos, el enrutamiento, la visibilidad y las políticas operativas.
La mayoría de los equipos no adoptan una API unificada porque quieren menos endpoints. La adoptan porque las aplicaciones multi-modelo eventualmente necesitan una capa de control.
Una vez que una aplicación depende de varias familias de modelos, las preguntas difíciles pasan de "¿Podemos llamar a este modelo?" a "¿Podemos gestionar la selección de modelos, el uso, los costos, el fallback y la fiabilidad sin reescribir el código del producto cada vez que cambia la pila de modelos?"
Las aplicaciones multi-modelo se están convirtiendo en el estándar
Los primeros productos de IA solían comenzar con un solo modelo y un solo proveedor. Eso era razonable cuando la superficie del producto era limitada: un chat, un resumidor, un asistente de soporte o un generador de contenido básico.
Las aplicaciones de IA modernas son diferentes. Un solo producto puede incluir:
- un modelo rápido para clasificación o reescritura
- un modelo de razonamiento más potente para preguntas complejas del usuario
- un modelo de código para flujos de trabajo de desarrollo
- un modelo de contexto largo para análisis de documentos
- un modelo de imagen para generación o edición de recursos visuales
- un modelo de video para producción creativa
- una ruta de fallback cuando un proveedor es lento, no está disponible o resulta demasiado costoso para una tarea determinada
Ese cambio transforma la arquitectura. La selección de modelos deja de ser una decisión de integración puntual y se convierte en una decisión operativa que puede cambiar según la funcionalidad, el nivel del usuario, el tipo de carga de trabajo, el objetivo de latencia y el presupuesto.
Para los equipos que construyen agentes, esta presión es aún mayor. Un flujo de trabajo de agente puede clasificar la intención, recuperar contexto, planificar pasos, invocar herramientas, resumir resultados y generar una respuesta final. No todos los pasos necesitan el mismo modelo. Si cada decisión de modelo está hardcodeada en el código de la aplicación, el producto se vuelve más difícil de evolucionar.
El problema no es solo tener múltiples APIs
Es tentador describir el problema como "necesitamos integrar con OpenAI, Anthropic, Google y quizás algunos proveedores de imagen o video." Esa es solo la parte visible.
El problema de fondo es la deriva operativa.
Cada proveedor puede diferir en:
- autenticación y configuración de cuenta
- identificadores de modelos
- formato de solicitud y respuesta
- comportamiento de streaming
- límites de tasa y señales de reintento
- informes de uso
- unidades de precios
- semántica de errores
- modalidades y parámetros compatibles
- cadencia de lanzamientos y política de deprecación
Incluso si dos proveedores exponen un endpoint compatible con OpenAI, los sistemas en producción aún necesitan manejar comportamientos específicos de cada modelo. La compatibilidad con OpenAI a menudo reduce la fricción de onboarding, pero no debería tratarse como un contrato operativo completo.
Para decisiones de arquitectura, la pregunta no es solo "¿Podemos enviar una solicitud?" La mejor pregunta es:
¿Puede la aplicación cambiar de modelos, rastrear el uso, controlar costos, manejar fallos y operar de forma fiable sin dispersar lógica específica de cada proveedor por todo el código base?
Ahí es donde una capa de API unificada empieza a ser relevante.
Error común: tratar una API unificada solo como un atajo de integración
Un error frecuente es evaluar una API unificada solo por la cantidad de proveedores que soporta. Eso pasa por alto la cuestión arquitectónica más importante.
La verdadera pregunta es si la capa de API ofrece a su equipo un lugar estable para gestionar la selección de modelos, la visibilidad de uso, las políticas de costos, el comportamiento de fallback y las operaciones en producción.
Si la capa solo oculta URLs de proveedores pero no mejora el control, la visibilidad o la consistencia operativa, puede reducir el trabajo de integración sin resolver el problema multi-modelo más difícil.
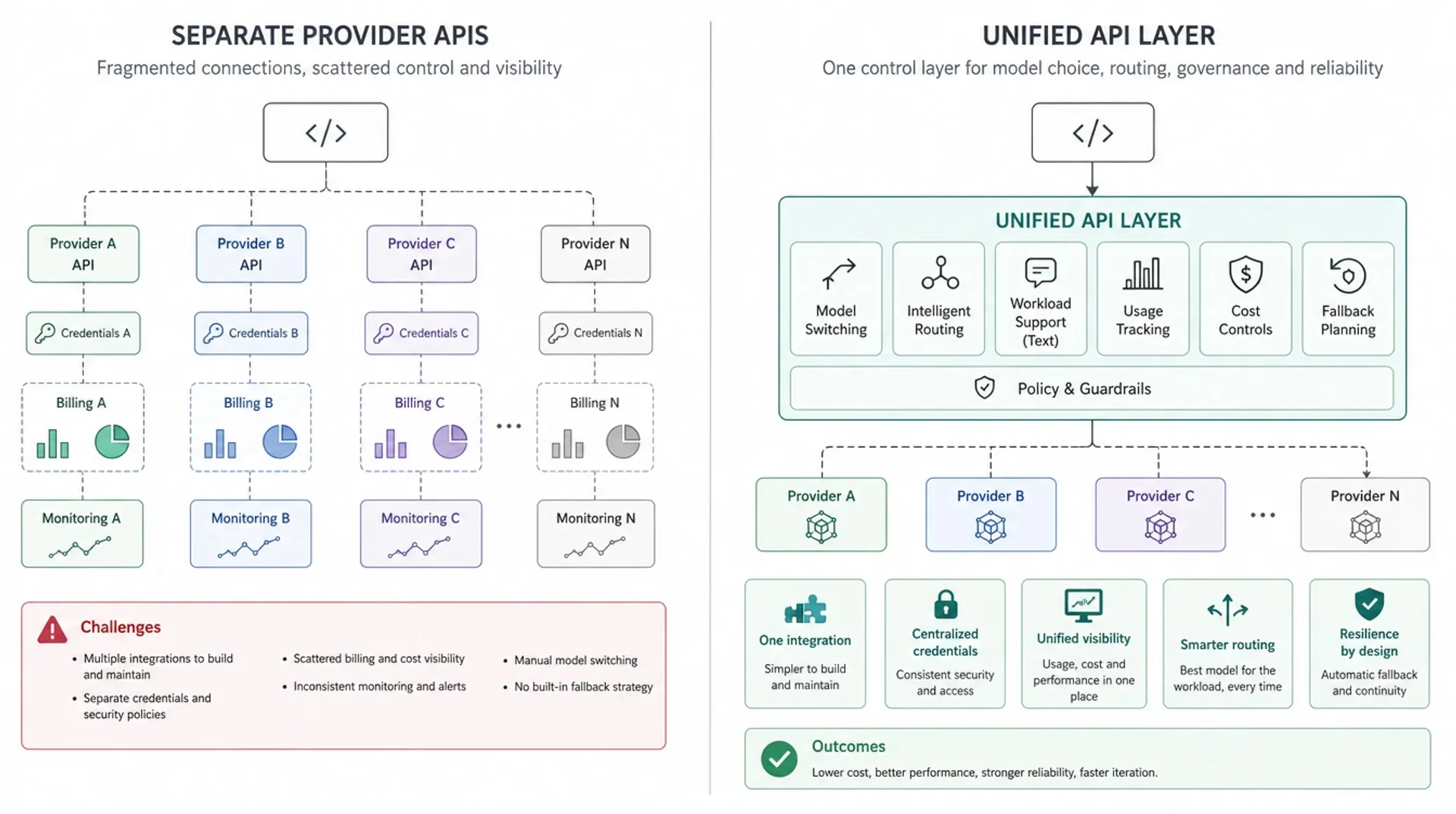
Una capa de API unificada crea un único punto de control
Una capa de API unificada se sitúa entre la aplicación y los proveedores de modelos subyacentes o las rutas de modelos. El código de la aplicación se comunica con la capa unificada. La capa gestiona las preocupaciones compartidas que no deberían duplicarse en cada equipo de funcionalidad.
En su versión más simple, esta capa proporciona:
- una URL base única
- un patrón de autenticación único
- un lugar para elegir los modelos compatibles
- una superficie unificada de uso y facturación
- un punto donde introducir enrutamiento, fallback o políticas más adelante
En una versión más madura, puede convertirse en parte de una capa de entrega de IA más amplia: acceso a modelos, reglas de enrutamiento para solicitudes LLM compatibles, visibilidad de uso, controles de costos, planificación de fallback y operaciones en producción se gestionan desde el mismo punto de entrada de la API.
Esto no significa que todos los modelos se vuelvan intercambiables. Una capa de API unificada no debería ocultar diferencias importantes en calidad, latencia, modalidad, ventana de contexto, comportamiento de herramientas o precios. Una buena arquitectura mantiene esas diferencias lo suficientemente visibles para evaluarlas, evitando que se filtren por todo el código de la aplicación.
| Dimensión | APIs de proveedores separadas | Capa de API unificada |
|---|---|---|
| Integración | Cada proveedor requiere configuración separada, credenciales, elección de SDK y mantenimiento | Una superficie de integración para los modelos compatibles |
| Cambio de modelo | Suele requerir cambios en el código, nuevas rutas de SDK o adaptadores específicos del proveedor | Generalmente se reduce a una decisión de selección de modelo o ruta |
| Seguimiento de uso | Los datos de uso están dispersos entre proveedores y logs internos | El uso puede normalizarse en una única superficie de informes |
| Control de costos | Los equipos comparan gastos entre diferentes portales de facturación y unidades de precio | Las políticas de costos pueden gestionarse más cerca de la capa de API |
| Fallback | Cada servicio puede implementar su propia lógica de reintento o respaldo | La planificación de fallback puede centralizarse donde corresponda |
| Operaciones | Incidentes, límites y cambios de modelo se dispersan por el código del producto | Los controles operativos residen más cerca de la capa de entrega de modelos |
Lo que hace posible una capa de API unificada
Cambiar de modelo sin reescribir la aplicación
El primer beneficio es directo: el cambio de modelo se vuelve menos invasivo.
Sin una capa unificada, cambiar de un proveedor o familia de modelos a otro puede requerir nuevas credenciales, cambios de SDK, mapeo de solicitudes, análisis de respuestas, modificaciones en el seguimiento de uso y nuevos runbooks operativos.
Con una capa de API unificada, la aplicación puede mantener un contrato de integración más estable mientras la elección de modelo cambia detrás de ese contrato. Eso no significa que la calidad del output será idéntica. Significa que la ruta de integración tiene menos probabilidades de convertirse en el cuello de botella.
Ejemplo:
- Un flujo de soporte comienza con un modelo equilibrado.
- Más tarde, la clasificación de alto volumen se mueve a un modelo más económico o rápido.
- Los casos de escalación complejos se mueven a un modelo de razonamiento más potente.
- La aplicación no necesita reconstruir toda su integración de IA cada vez que cambia la combinación de modelos.
El valor de negocio no es "cambiar modelos por diversión." El valor es reducir el costo de adaptación a medida que los modelos, los precios y las necesidades de carga de trabajo evolucionan.
Enrutamiento basado en las necesidades de la carga de trabajo
Las aplicaciones multi-modelo a menudo contienen cargas de trabajo LLM mixtas. Una tarea breve de formateo, una tarea de análisis con contexto largo y un paso de planificación de un agente no necesitan el mismo perfil de modelo.
Una capa de API unificada ofrece a los equipos un lugar natural para introducir lógica de enrutamiento en cargas de trabajo de texto compatibles:
- dirigir tareas simples a modelos de menor latencia o menor costo
- dirigir tareas de razonamiento intensivo a modelos más potentes
- mantener modelos fijos para flujos de trabajo con benchmarks o regulados
- devolver el modelo realmente seleccionado cuando se utiliza enrutamiento, para que los equipos puedan registrar y evaluar el comportamiento
Visibilidad de uso y consistencia en la facturación
Una vez que una aplicación usa múltiples modelos, la visibilidad del uso se convierte en un problema de producto y finanzas, no solo un detalle de ingeniería.
Los equipos necesitan responder:
- ¿Qué funcionalidad está usando qué modelo?
- ¿Qué segmento de clientes está generando el gasto?
- ¿Se están usando modelos costosos para tareas simples?
- ¿Un cambio de modelo aumentó la latencia, el consumo de tokens o la tasa de fallos?
- ¿Se puede atribuir el uso por funcionalidad, equipo, entorno o API key?
Los dashboards separados de cada proveedor dificultan responder estas preguntas porque cada proveedor reporta el uso de forma distinta. Una capa de API unificada puede crear una vista más consistente de solicitudes, tokens, volumen de tareas y gasto en todos los modelos compatibles.
Esa visibilidad es la base del control de costos. No es posible gestionar la economía de modelos si los datos de uso están fragmentados.
Control de costos entre modelos
El control de costos no es lo mismo que ahorros garantizados. Una capa de API unificada no debería prometer que cada solicitud se vuelve más barata.
El valor práctico es el control:
- comparar modelos por tipo de tarea
- evitar el uso excesivo de modelos premium para trabajo simple
- establecer presupuestos o límites a nivel de API key, equipo o producto
- evaluar cambios de modelo contra datos de uso y calidad
- mantener las políticas de costos más cerca de la capa de plataforma en lugar de dispersarlas por el código de la aplicación
En producción, el mayor problema de costos a menudo no es una solicitud costosa puntual. Es un modelo costoso configurado por defecto que silenciosamente sirve millones de solicitudes simples porque nadie tiene un lugar limpio para cambiarlo.
Planificación de fallback y fiabilidad
Los sistemas de IA en producción necesitan un plan para los fallos:
- caída del proveedor
- agotamiento de cuotas
- limitación de tasa (rate limiting)
- latencia degradada
- errores específicos del modelo
- regresión inesperada de calidad tras una actualización del modelo
Con integraciones separadas por proveedor, la lógica de fallback suele aparecer dentro de los servicios del producto. Un equipo reintenta de una forma. Otro equipo usa un timeout diferente. Un tercer equipo no tiene ruta de respaldo.
Una capa de API unificada ofrece a los equipos un mejor lugar para definir el comportamiento de fallback y las políticas operativas. Puede ayudar a separar la lógica de la aplicación de las decisiones sobre disponibilidad de proveedores.
El fallback aún requiere cuidado. Un modelo de respaldo puede tener diferente comportamiento de salida, límites de contexto, soporte de herramientas o precio. El objetivo no es la sustitución ciega. El objetivo es tener un lugar controlado para planificar y probar la sustitución.
Operaciones en producción más limpias
A medida que crece el uso de IA, la capa de modelos necesita la misma disciplina operativa que el resto de la infraestructura:
- logging
- atribución de uso
- seguimiento de latencia
- clasificación de errores
- controles de acceso
- revisión de cambios de modelo
- respuesta ante incidentes
- separación de entornos
- documentación para desarrolladores
Si cada equipo de funcionalidad posee su propia integración con el proveedor, esas prácticas se vuelven inconsistentes. Una capa de API unificada facilita la definición de estándares compartidos sobre cómo se realizan, se observan y se modifican las llamadas a modelos.
Por eso la frase "una sola API" puede resultar engañosa. El verdadero valor arquitectónico no es solo un endpoint. Es un único lugar para operar la entrega de modelos.
Cuándo basta con una API unificada sencilla
Una API unificada sencilla puede ser suficiente cuando la necesidad principal es la estabilidad de integración.
Use una capa de API unificada sencilla cuando:
- está usando un número pequeño de modelos
- quiere una sola API key y un solo patrón de solicitud
- la selección de modelo es mayormente explícita
- el volumen de tráfico es manejable
- los requisitos de fallback son limitados
- su equipo principalmente quiere reducir la carga de integración
Por ejemplo, una startup puede usar un modelo para chat con usuarios, un modelo para resúmenes internos y un modelo de imagen para generación de contenido. Si el producto aún no necesita enrutamiento dinámico o gobernanza avanzada, la primera ganancia es una capa de integración compartida y estable.
Esa etapa sigue siendo valiosa. Evita que el producto desarrolle tres pilas de integración separadas antes de que el equipo entienda su carga de trabajo real.
Cuándo se necesita un gateway o una capa de enrutamiento más avanzada
La necesidad de un gateway más avanzado aparece cuando la capa de API unificada debe hacer más que solo proporcionar acceso.
Puede necesitar enrutamiento, controles de gateway o una capa gestionada de entrega de modelos cuando:
- el volumen de solicitudes es lo suficientemente alto como para que la elección de modelo afecte el margen
- las cargas de trabajo varían ampliamente en complejidad
- los requisitos de fiabilidad son explícitos
- múltiples equipos o servicios dependen de las llamadas a modelos
- el uso debe atribuirse por producto, cliente o equipo
- el comportamiento de fallback debe probarse y documentarse
- los cambios de modelo necesitan revisión en lugar de ediciones ad hoc
| Escenario | Lo que probablemente necesita | Por qué |
|---|---|---|
| Probar un modelo en un prototipo | API directa o API unificada sencilla | La velocidad importa más que el control de plataforma |
| Usar 2-3 modelos en un producto | Capa de API unificada sencilla | Una superficie de integración reduce el código específico de cada proveedor |
| Ejecutar cargas de trabajo de alto volumen en producción | API unificada con controles de costos y uso | El gasto, la latencia y la atribución de uso empiezan a importar |
| Construir agentes con tareas variables | API unificada con enrutamiento para cargas de texto compatibles | Distintos pasos del agente pueden necesitar diferentes perfiles de modelo |
| Gestionar fiabilidad entre proveedores | Gateway o capa de enrutamiento con planificación de fallback | La gestión de fallos no debería duplicarse en cada servicio |
Cómo se aplica esto a EvoLink
EvoLink está construido en torno a este patrón de entrega de modelos: un punto de entrada de API para los modelos compatibles, con capacidades de plataforma en torno al acceso, la visibilidad de costos, el enrutamiento de cargas de texto y el control operativo.
En lugar de tratar cada integración de modelo como un proyecto separado, los equipos pueden usar EvoLink como una capa compartida de entrega de modelos entre las familias de modelos compatibles.
Ese posicionamiento es importante porque EvoLink no es solo una lista de modelos. La arquitectura a largo plazo se acerca más a una infraestructura de entrega de modelos de IA:
- Acceso unificado: use una sola ruta de integración para los modelos compatibles en lugar de reconstruir el acceso para cada proveedor o familia de modelos.
- Control de costos: compare opciones de modelos, inspeccione precios y evite que la política de costos sea una ocurrencia tardía en el código de la aplicación.
- Control de invocación: mantenga la selección de modelos, las decisiones de enrutamiento para solicitudes LLM compatibles, las API keys y los límites de uso más cerca de la capa de plataforma.
- Preparación para producción: trate las llamadas a modelos como tráfico operativo que necesita visibilidad, planificación de fallback y prácticas de integración estables.
El límite importante es este: una capa de API unificada puede facilitar la operación de entrega de modelos, pero no debería pretender que todos los modelos tienen un comportamiento idéntico. Los equipos aún necesitan evaluación, logging, revisión de costos y QA específico de cada flujo de trabajo.
Lista de verificación para la decisión
Use esta lista de verificación antes de decidir si su aplicación necesita una capa de API unificada, un gateway o llamadas directas a proveedores.
- ¿Está usando más de una familia de modelos hoy?
- ¿Agregará modelos de imagen, video, audio, código o contexto largo más adelante?
- ¿Puede cambiar de modelo sin modificar el código de la aplicación en múltiples lugares?
- ¿Puede ver el uso por funcionalidad, equipo, cliente o API key?
- ¿Puede comparar costos entre modelos en un mismo flujo de trabajo?
- ¿Sabe qué modelo atendió cada solicitud en producción?
- ¿Tiene un plan de fallback para límites de tasa, fallos de proveedores o latencia degradada?
- ¿Es consistente el comportamiento de reintentos y timeouts entre servicios?
- ¿Pueden los desarrolladores usar un solo patrón documentado de acceso a modelos?
- ¿Se revisa la elección de modelo como una decisión operativa y no solo como un cambio de código?
Si la mayoría de las respuestas son "no," el problema no es solo conveniencia de integración. Su capa de modelos se está convirtiendo en parte de la infraestructura de producción.
Preguntas frecuentes
¿Qué es una API unificada para modelos de IA?
Una API unificada para modelos de IA es una capa de integración que permite a una aplicación llamar a los modelos compatibles a través de un punto de entrada de API consistente. Puede reducir la configuración duplicada por proveedor y crear un lugar compartido para el acceso a modelos, la visibilidad de uso, la facturación, los controles de costos, el enrutamiento y las políticas operativas.
¿Es lo mismo una API unificada que un gateway LLM?
No siempre. Una API unificada sencilla puede ofrecer solo una superficie de acceso para múltiples modelos. Un gateway LLM suele agregar más capacidades de infraestructura, como enrutamiento, fallback, observabilidad, controles de políticas, límites de tasa o gobernanza. En la práctica, muchos equipos comienzan con acceso unificado y avanzan hacia un gateway a medida que crecen los requisitos de producción.
¿Necesito una API unificada si solo uso un modelo?
Generalmente no. Si su producto usa un solo modelo, tiene bajo tráfico y no necesita fallback ni visibilidad multi-proveedor, el acceso directo a la API puede ser más sencillo. Una API unificada se vuelve más útil cuando se espera que la selección de modelos, el control de costos o la planificación de fiabilidad se conviertan en trabajo recurrente.
¿Cómo ayuda una API unificada con el enrutamiento de modelos?
El enrutamiento necesita un lugar estable para tomar decisiones de selección de modelos. Una capa de API unificada ofrece a la aplicación una ruta de solicitud única mientras la lógica de enrutamiento elige un modelo según el tipo de tarea, las necesidades de latencia, el perfil de costos u otras señales. En producción, el enrutamiento también debería exponer qué modelo fue seleccionado para que los equipos puedan registrar, evaluar y depurar el comportamiento.
¿Una API unificada hace que todos los modelos se comporten igual?
No. Una API unificada puede normalizar partes del acceso, la autenticación, el formato de solicitud, los informes de uso o las políticas de enrutamiento, pero no hace que la calidad, la latencia, los límites de contexto, el comportamiento de herramientas, el soporte de modalidades o los precios sean idénticos. Los equipos deben seguir probando cada modelo contra sus propios flujos de trabajo.


