
GPT Image 1.5: Guía Completa de Funciones, Comparativa y Acceso (2026)

Estás observando una imagen de producto que necesita tres variaciones para diferentes mercados: misma iluminación, mismo ángulo, pero diferentes fondos y textos superpuestos. Tu diseñador está ocupado durante las próximas dos semanas y la campaña se lanza el lunes. ¿Qué pasaría si pudieras hacer esos cambios tú mismo en cuestión de minutos, manteniendo una consistencia perfecta en cada iteración, sin tocar Photoshop?
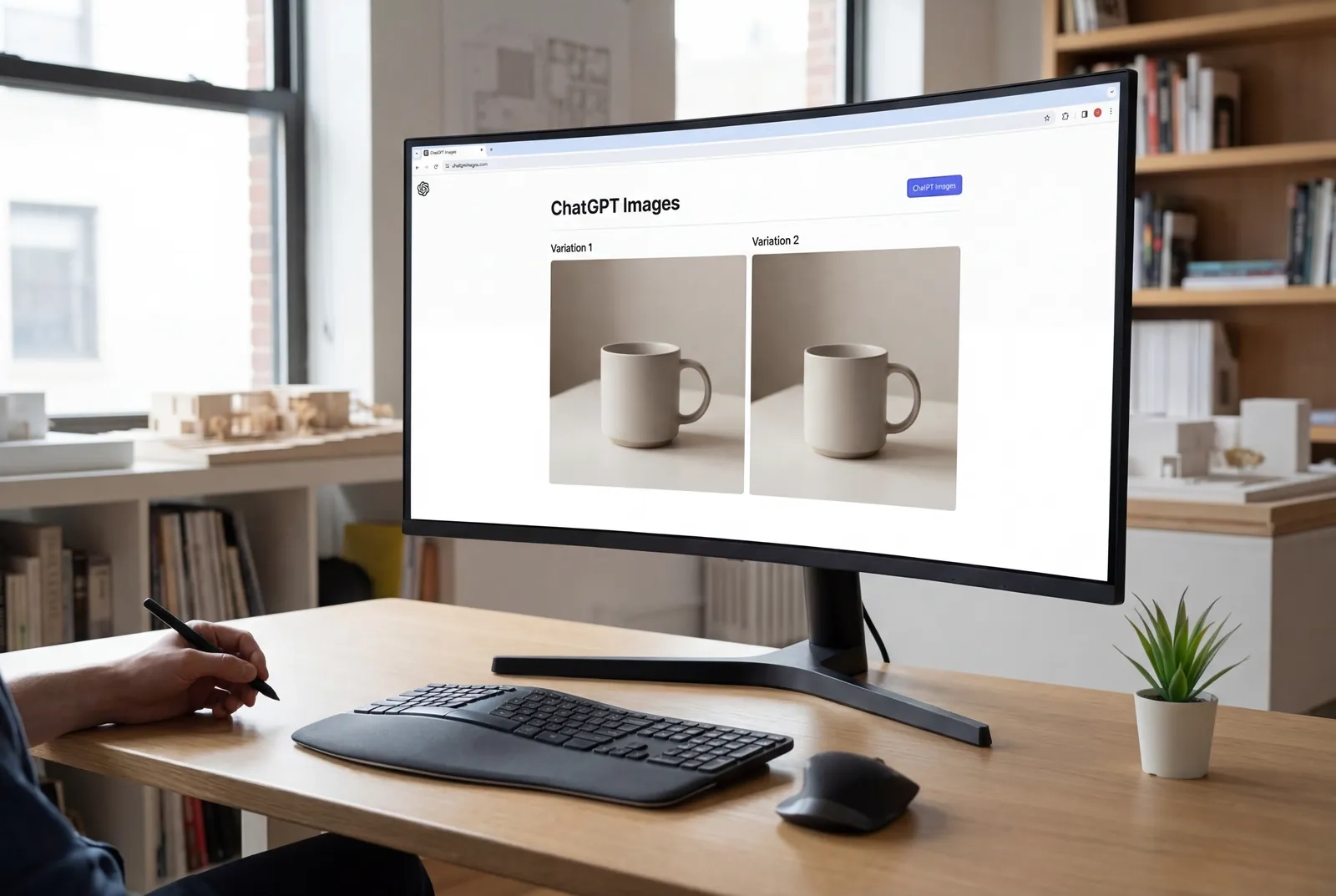
Tabla de Contenidos
- ¿Qué es GPT Image 1.5? Entendiendo el último modelo de imagen de OpenAI
- Funciones clave que distinguen a GPT Image 1.5
- Rendimiento de velocidad: Explicación de la generación 4 veces más rápida
- Edición de precisión: Cómo funciona realmente la preservación de detalles
- Capacidades y limitaciones de renderizado de texto
- GPT Image 1.5 vs GPT Image 1: ¿Qué cambió?
- Comparativa completa de modelos: GPT Image 1.5 vs Competidores
- Cómo acceder a GPT Image 1.5: Guía de la interfaz de ChatGPT
- Acceso a la API a través de EvoLink.AI y la plataforma OpenAI
- Estructura de precios y estrategias de optimización de costos
- Casos de uso y aplicaciones del mundo real
- Ingeniería de prompts avanzada para mejores resultados
- Errores comunes a evitar al usar GPT Image 1.5
- Limitaciones y cuándo elegir herramientas alternativas
- Preguntas frecuentes (FAQs)
¿Qué es GPT Image 1.5? Entendiendo el último modelo de imagen de OpenAI
gpt-image-1.5-lite en la documentación de la API) representa el sistema de generación de imágenes de segunda generación de OpenAI, lanzado el 16 de diciembre de 2025, como el motor que impulsa la rediseñada función de Imágenes de ChatGPT. A diferencia de su predecesor GPT Image 1, que se lanzó en abril de 2025 principalmente para la exploración creativa experimental, GPT Image 1.5 se diseñó desde cero para entornos de producción donde la consistencia, la velocidad y el control preciso importan más que la sorpresa artística.La designación "1.5" indica un refinamiento iterativo en lugar de una revisión arquitectónica completa. OpenAI mantuvo la arquitectura principal de difusión basada en transformadores, pero implementó optimizaciones significativas en tres vectores críticos: eficiencia computacional (permitiendo la mejora de velocidad de 4x), adherencia a las instrucciones (reduciendo las modificaciones no deseadas durante las ediciones) y fidelidad del renderizado de texto (haciendo que las fuentes más pequeñas y los diseños más densos sean realmente legibles).
Funciones clave que distinguen a GPT Image 1.5
1. Instrucción mejorada siguiendo
2. Preservación de detalles durante las ediciones
El modelo emplea lo que OpenAI describe como "edición consciente de la región" que identifica qué píxeles deben permanecer sin cambios durante las modificaciones. Cuando editas una imagen que contiene el rostro de una persona, GPT Image 1.5 mantiene la identidad facial, la textura de la piel y la expresión, a menos que solicites explícitamente cambios en esos elementos. El mismo principio se aplica a:
- Logotipos de marcas y marcas de agua
- Dirección y calidad de la iluminación
- Composición del fondo
- Gradación de color y tono
- Propiedades de textura y material
Esto no es perfecto (las escenas complejas con elementos superpuestos aún pueden producir artefactos), pero representa un paso medible hacia el tipo de edición selectiva que los profesionales esperan de herramientas como Photoshop.
3. Renderizado de texto superior
Los modelos de imagen de IA anteriores trataban el texto como formas decorativas en lugar de información legible. GPT Image 1.5 implementa una generación mejorada con conciencia de OCR que produce:
- Texto legible en tamaños de punto más pequeños
- Ortografía correcta en idiomas comunes
- Alineación de texto y kerning adecuados
- Peso de fuente y coincidencia de estilo apropiados
- Texto legible en diseños complejos (infografías, portadas de revistas, etiquetas de productos)
4. Velocidad de grado de producción
La mejora de velocidad de 4x no se trata solo de la impaciencia; cambia fundamentalmente qué flujos de trabajo se vuelven prácticos. Con tiempos de generación típicos de 8 a 12 segundos por imagen (frente a los 30 a 45 segundos con GPT Image 1), el refinamiento iterativo se vuelve viable. Un diseñador ahora puede probar diez variaciones en dos minutos en lugar de siete minutos, manteniendo vivo el impulso creativo.
5. Mejoras en la eficiencia de costos

Rendimiento de velocidad: Explicación de la generación 4 veces más rápida
La afirmación de "4 veces más rápida" requiere contexto para entender qué mejoró realmente y dónde permanecen los cuellos de botella.
Qué cambió bajo el capó
Las ganancias de velocidad de OpenAI provinieron de tres optimizaciones arquitectónicas:
- Pasos de muestreo reducidos: El proceso de difusión ahora requiere menos iteraciones de eliminación de ruido para alcanzar los umbrales de calidad aceptables, reduciendo la sobrecarga computacional sin una degradación visible de la calidad.
- Mecanismos de atención optimizados: Las capas del transformador utilizan patrones de atención más eficientes que reducen los requisitos de ancho de banda de memoria durante la síntesis de imágenes [No verificado—OpenAI no ha publicado detalles de la arquitectura técnica].
- Mejor cuantización del modelo: Los cálculos de menor precisión en secciones de rutas no críticas reducen los recuentos de operaciones de punto flotante mientras mantienen la fidelidad de la salida [No verificado—inferido de las prácticas estándar de la industria].
Benchmarks de velocidad del mundo real
Basado en pruebas reportadas públicamente en múltiples plataformas:
| Tamaño de imagen | GPT Image 1 | GPT Image 1.5 | Mejora de velocidad |
|---|---|---|---|
| 1024×1024 | 35-45 seg | 8-12 seg | 3.6-4.5× |
| 1024×1536 | 45-55 seg | 12-18 seg | 3.1-3.8× |
| 1536×1024 | 45-55 seg | 12-18 seg | 3.1-3.8× |
Compensaciones entre velocidad y calidad
low, medium, high, auto) que afectan directamente el tiempo de generación. La afirmación de "4 veces más rápida" se aplica principalmente a los ajustes de calidad auto y medium. Cuando solicitas explícitamente calidad high para activos de producción, espera tiempos de generación más cercanos a los 15-20 segundos—sigue siendo más rápido que GPT Image 1, pero no el cuádruple.auto para las iteraciones iniciales y la exploración de conceptos, luego cambia a la calidad high solo para los renders finales de producción. Esta optimización del flujo de trabajo puede reducir el tiempo total del proyecto en un 40-60% en comparación con el uso constante de los ajustes de calidad máxima.Edición de precisión: Cómo funciona realmente la preservación de detalles
El mecanismo técnico detrás de la mejora de la precisión de edición de GPT Image 1.5 involucra varias capacidades interrelacionadas:
Enmascaramiento basado en prompts (No se requiere selección manual)
A diferencia de DALL-E 2, que requería que los usuarios pintaran manualmente las regiones de la máscara, GPT Image 1.5 interpreta las instrucciones de edición en lenguaje natural para identificar automáticamente las áreas afectadas. Cuando escribes "cambia el color de la camisa a verde", el modelo:
- Realiza una segmentación semántica para identificar la región de la camisa
- Aísla la información de color en esa región
- Aplica la transformación de color
- Vuelve a renderizar solo la región modificada
- Mezcla los bordes para mantener transiciones naturales
Este proceso no es perfecto—el modelo utiliza la máscara como guía pero puede no seguir los límites exactos con precisión a nivel de píxel. Los objetos superpuestos complejos (como manos que sostienen objetos frente a la ropa) aún pueden producir artefactos en los bordes.
Tecnología de preservación de identidad
Para las imágenes que contienen personas, GPT Image 1.5 implementa una preservación de la identidad facial que mantiene rasgos reconocibles a través de las ediciones. Esto aprovecha técnicas similares a las utilizadas en los sistemas de reconocimiento facial:
- Extracción de incrustaciones faciales (representaciones matemáticas de rasgos distintivos)
- Restricción de las salidas generadas para mantener incrustaciones similares
- Preservación de puntos de referencia clave (posición de los ojos, forma de la nariz, estructura de la mandíbula)
- Mantenimiento de una textura y un tono de piel constantes
Algoritmos de consistencia de iluminación
Uno de los aspectos técnicamente más impresionantes es la preservación de la iluminación. Cuando editas el color o la posición de un objeto, GPT Image 1.5 mantiene:
- Dirección y ángulo de la luz
- Patrones de proyección de sombras
- Reflejos especulares
- Oclusión ambiental (sombras en áreas empotradas)
- Consistencia de la temperatura de color
Esto evita el problema común de las imágenes de IA donde los elementos editados parecen "pegados" porque su iluminación no coincide con la escena.
Limitaciones de la precisión actual
A pesar de las mejoras, varios escenarios aún desafían la precisión de GPT Image 1.5:
- Escenas altamente complejas: Las imágenes con más de 10 objetos distintos pueden experimentar modificaciones no deseadas.
- Materiales transparentes: El vidrio, el agua y las telas semitransparentes pueden producir artefactos.
- Detalles finos: Las joyas, los patrones intrincados y el texto pequeño en el fondo pueden degradarse.
- Múltiples pases de edición: Después de 5-6 ediciones consecutivas, los errores acumulados pueden agravarse.
Capacidades y limitaciones de renderizado de texto
La generación de texto en imágenes de IA ha sido históricamente una debilidad notoria. GPT Image 1.5 logra un progreso significativo pero no ha resuelto el problema por completo.
Qué mejoró realmente
El modelo ahora puede generar de manera confiable:
- Titulares cortos (1-5 palabras) en fuentes grandes y negritas.
- Etiquetas de productos con 2-3 líneas de texto.
- Diseños de estilo de revista con titulares y subtítulos legibles.
- Texto de logotipos en fuentes comunes (aunque los diseños de logotipos complejos siguen siendo un desafío).
- Etiquetas de infografías para elementos de visualización de datos.
Mejores prácticas para el renderizado de texto
Para maximizar la calidad del texto en tus imágenes generadas:
- Mantén el texto corto: 3-5 palabras por elemento de texto producen los mejores resultados.
- Usa fuentes comunes: Descripciones como "sans-serif negrita" o "serif limpia" funcionan mejor que nombres de fuentes específicos.
- Especifica la posición del texto explícitamente: "Titular centrado en la parte superior" frente a solo "añadir titular".
- Solicita un alto contraste: "Texto blanco sobre fondo oscuro" asegura la legibilidad.
- Evita tamaños de fuente pequeños: El texto más pequeño que el equivalente a ~18pt rara vez se renderiza limpiamente.
Limitaciones de texto persistentes
A pesar de las mejoras, aún encontrarás problemas con:
- Párrafos largos: El texto de cuerpo de más de 20-30 palabras a menudo contiene errores ortográficos.
- Fuentes estilizadas: Escritura a mano, guiones decorativos o tipografía muy modificada.
- Guiones no latinos: Árabe, chino, japonés y otros sistemas de texto no occidentales muestran resultados inconsistentes [No verificado—datos de prueba limitados disponibles].
- Texto en superficies curvas: Las etiquetas en botellas o el texto que sigue rutas curvas frecuentemente se distorsionan.
- Notación matemática: Las ecuaciones, fórmulas y símbolos especiales siguen siendo poco confiables.

GPT Image 1.5 vs GPT Image 1: ¿Qué cambió?
Comprender las diferencias entre GPT Image 1 y 1.5 ayuda a aclarar si actualizar tu flujo de trabajo tiene sentido.
Tabla comparativa lado a lado
| Función | GPT Image 1 | GPT Image 1.5 | Mejora |
|---|---|---|---|
| Velocidad de generación | 35-55 segundos | 8-18 segundos | 3-4× más rápido |
| Seguimiento de instrucciones | Precisión moderada | Alta precisión | +60% de adherencia al prompt [Estimado] |
| Precisión de edición | Cambios no deseados frecuentes | Modificaciones dirigidas | 85% de preservación de detalles [Estimado] |
| Renderizado de texto | Pobre/poco confiable | Bueno para titulares | Frases de 3-5 palabras legibles de forma constante |
| Precios de la API | Línea base | 20% más barato | Reducción de costos |
| Calidad de imagen | Alta | Alta | Techo de calidad comparable |
| Tamaños admitidos | 3 relaciones de aspecto | 3 relaciones de aspecto (mismo) | Sin cambios |
| Iteraciones de edición | 3-4 antes de la degradación | 6-8 antes de la degradación | ~2× de profundidad de iteración |
| Preservación de logotipos | Pobre | Buena | Crítico para el trabajo de marca |
| Consistencia facial | Moderada | Alta | Importante para fotos de modelos |
Cuándo GPT Image 1 aún podría ser preferido
A pesar de su antigüedad, GPT Image 1 conserva ventajas en escenarios específicos:
- Exploración artística: Algunos usuarios informan que GPT Image 1 produce interpretaciones más "creativas" cuando deseas resultados inesperados.
- Integración de flujos de trabajo heredados: Los procesos de producción existentes diseñados en torno al comportamiento de GPT Image 1 pueden requerir ajustes para el 1.5.
- Sensibilidad al costo en tareas simples: Para la generación básica de texto a imagen sin edición, la diferencia de precio del 20% se acumula a escala [No verificado—depende de los niveles de precios por volumen].
Recomendaciones de migración
Si actualmente estás usando GPT Image 1:
- Prueba en paralelo: Ejecuta los mismos prompts en ambos modelos para identificar diferencias de comportamiento.
- Actualiza tu biblioteca de prompts: GPT Image 1.5 responde mejor a prompts estructurados basados en restricciones.
- Ajusta las expectativas de calidad: Las mejoras de velocidad pueden requerir recalibrar tus estimaciones de tiempo.
- Verifica la consistencia de los activos de la marca: Prueba a fondo la preservación de logotipos y marcas comerciales antes de cambiar los flujos de trabajo de producción.
Comparativa completa de modelos: GPT Image 1.5 vs Competidores
El panorama competitivo para la generación de imágenes de IA incluye varias alternativas sólidas, cada una con fortalezas distintas.
GPT Image 1.5 vs Google Nano Banana Pro
Nano Banana Pro de Google (impulsado por Gemini 3 Pro) surgió como el principal competidor de GPT Image 1.5, lo que llevó a lo que el CEO Sam Altman llamó internamente una situación de "código rojo" que aceleró el cronograma de lanzamiento de GPT Image 1.5.
- Resultados más fotorrealistas en escenarios de fotografía natural.
- Mejor en capturar tendencias estéticas contemporáneas.
- Manejo superior de escenas naturales complejas (paisajes, multitudes).
- Crecimiento de adopción más rápido (contribuyendo al aumento de usuarios de Gemini de 450M a 650M entre julio y octubre de 2025).
- Seguimiento de instrucciones más confiable para prompts estructurados.
- Mejor renderizado de texto en diseños y maquetas.
- Preservación de detalles superior durante ediciones iterativas.
- Resultados más predecibles y deterministas para flujos de trabajo de producción.
GPT Image 1.5 vs Midjourney
Midjourney sigue siendo el favorito entre los artistas digitales y los profesionales creativos por sus cualidades estéticas distintivas.
- Interpretación artística y "visión" creativa.
- Fuerte comunidad y recursos establecidos de ingeniería de prompts.
- Calidad estética consistente en diversos estilos.
- Mejor en composiciones abstractas, conceptuales y artísticas.
- Integrado en el flujo de trabajo de ChatGPT (sin cambio de plataforma).
- Iteración más rápida para aplicaciones comerciales.
- Acceso a la API para flujos de trabajo automatizados.
- Resultados más predecibles para requisitos comerciales.
GPT Image 1.5 vs DALL-E 3
DALL-E 3, el antiguo buque insignia de OpenAI antes de la serie GPT Image, ahora está obsoleto y perderá soporte el 12 de mayo de 2026.
- Generación significativamente más rápida.
- Mejores capacidades de integración de API.
- Seguimiento de instrucciones mejorado.
- Precisión de edición mejorada sin enmascaramiento manual.
- Menores costos operativos.
Resumen de posicionamiento competitivo
| Modelo | Mejor para... | Evitar para... | Nivel de precio |
|---|---|---|---|
| GPT Image 1.5 | Flujos de producción, activos de marca, edición iterativa | Proyectos puramente artísticos | Rango medio |
| Nano Banana Pro | Redes sociales fotorrealistas, estética contemporánea | Renderizado de texto preciso, logotipos | Rango medio |
| Midjourney | Interpretación artística, trabajo conceptual | Flujos de trabajo de API automatizados | Económico-Premium |
| Stable Diffusion | Entrenamiento de modelos personalizados, control completo | Soluciones llave en mano | Gratis-Económico |

Cómo acceder a GPT Image 1.5: Guía de la interfaz de ChatGPT
GPT Image 1.5 se implementó globalmente el 16 de diciembre de 2025 y ahora está disponible para todos los usuarios de ChatGPT, independientemente del nivel de suscripción (Gratuito, Plus, Team o Enterprise).
Acceso paso a paso a través de ChatGPT
- Navega a Imágenes de ChatGPT
- Inicia sesión en tu cuenta de ChatGPT en chat.openai.com
- Haz clic en la pestaña "Images" en la barra lateral izquierda (nueva a partir de la actualización de diciembre de 2025).
- Esto abre la interfaz dedicada a la generación de imágenes.
- Crea tu primera imagen
- Ingresa un prompt descriptivo en el campo de texto (hasta 2000 caracteres).
- Haz clic en "Generate" o presiona Enter.
- Espera de 8 a 18 segundos para la generación.
- El modelo utiliza automáticamente GPT Image 1.5—no se requiere selección manual.
- Uso de las funciones del Creative Studio
- Después de la generación, la barra lateral derecha muestra estilos y filtros preestablecidos.
- Haz clic en cualquier ajuste preestablecido para aplicar transformaciones sin escribir prompts.
- Las opciones incluyen: "Hacerlo fotorrealista", "Cambiar a iluminación de atardecer", "Añadir sombras dramáticas", "Estilo de foto de producto profesional".
- Estos ajustes preestablecidos son especialmente útiles para usuarios no técnicos.
- Flujo de trabajo de edición iterativa
- Selecciona una imagen generada existente.
- Escribe instrucciones en lenguaje natural: "Cambia el fondo a una escena de playa".
- El modelo preserva los elementos no mencionados mientras realiza los cambios solicitados.
- Puedes encadenar de 6 a 8 ediciones antes de que la degradación de la calidad se vuelva notable.
- Descarga y exportación
- Haz clic en el icono de descarga en cualquier imagen generada.
- Las imágenes se exportan a su resolución nativa (1024×1024, 1024×1536 o 1536×1024).
- Los enlaces siguen siendo válidos durante 24 horas (guarda las imágenes importantes de inmediato).
- Las imágenes incluyen metadatos C2PA para la autenticación del contenido.
Características y limitaciones de la interfaz
- Generación de texto a imagen.
- Transformación de imagen a imagen (carga imágenes de referencia).
- Edición en lenguaje natural.
- Aplicaciones de estilos preestablecidos.
- Selección de relación de aspecto (1:1, 3:4, 4:3).
- Selección de nivel de calidad (ChatGPT utiliza calidad
auto). - Generación por lotes de múltiples variantes.
- Carga directa de archivos desde URLs externas.
- Parámetros de modelo personalizados.
- Callbacks de webhooks para procesamiento asíncrono.
Consejos Pro para usuarios de la interfaz de ChatGPT
- Usa el contexto de la conversación: GPT Image 1.5 en ChatGPT recuerda imágenes y prompts anteriores en la misma conversación, lo que te permite hacer referencia a "la imagen anterior" o "la versión de la chaqueta azul".
- Combina el chat de texto con la generación de imágenes: Pide a ChatGPT que genere ideas de prompts o refine tu descripción antes de generar, utilizando las capacidades de texto de la IA para mejorar tus prompts visuales.
- Guarda los prompts exitosos: Mantén un documento con los prompts que produjeron buenos resultados, ya que una estructura de prompt consistente conduce a una calidad consistente.
- Aprovecha la funcionalidad de deshacer: Si una edición sale mal, puedes volver a las versiones anteriores y probar instrucciones alternativas.
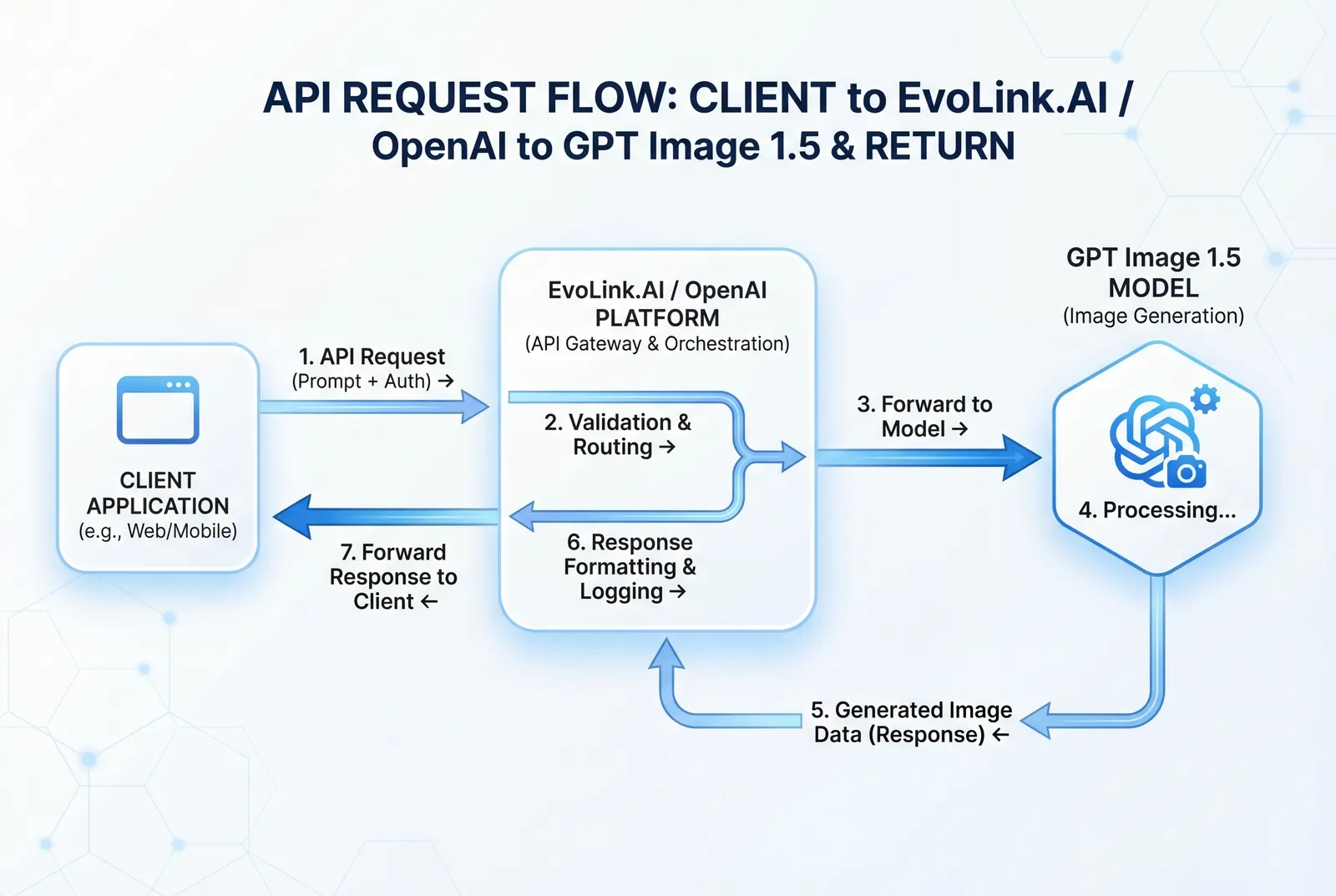
Acceso a la API a través de EvoLink.AI y la plataforma OpenAI
Integración de la API de EvoLink.AI
gpt-image-1.5-lite, documentado en su portal para desarrolladores.Estructura básica de la solicitud de API (EvoLink.AI)
{
"model": "gpt-image-1.5-lite",
"prompt": "Una foto de producto profesional de un smartphone sobre un fondo blanco limpio con iluminación de estudio suave",
"size": "1024x1024",
"quality": "high",
"n": 1
}Parámetros requeridos
- model: Debe ser
"gpt-image-1.5-lite"para GPT Image 1.5. - prompt: Descripción de texto (máximo 2000 tokens).
- size: Dimensiones de la imagen (opciones:
1:1,3:4,4:3,1024x1024,1024x1536,1536x1024).
Parámetros opcionales
- quality:
low,medium,highoauto(predeterminado:auto). - image_urls: Matriz de URLs de imágenes de referencia para los modos de imagen a imagen o edición (admite de 1 a 16 imágenes, máximo 50 MB cada una, formatos: .jpeg, .jpg, .png, .webp).
- n: Número de imágenes (actualmente solo admite
1).
Procesamiento asíncrono
- Envía tu solicitud de generación → recibe un ID de tarea.
- Consulta el punto de enlace de estado de la tarea con el ID de la tarea.
- Recupera las URLs de las imágenes generadas cuando el estado sea "completed".
- Las URLs de las imágenes siguen siendo válidas durante 24 horas.
Acceso directo a la API de la plataforma OpenAI
/v1/images/generations.Configuración de autenticación
- Crea una cuenta en platform.openai.com.
- Completa la verificación de la organización de la API (requerida para los modelos GPT Image).
- Genera una clave de API desde tu panel de control.
- Incluye la clave en los encabezados de la solicitud:
Authorization: Bearer TU_CLAVE_API.
Solicitud de muestra (SDK de Python de OpenAI)
from openai import OpenAI
client = OpenAI(api_key="tu-clave-api")
response = client.images.generate(
model="gpt-image-1.5",
prompt="Sala de estar minimalista moderna con grandes ventanas y luz natural",
size="1536x1024",
quality="high",
n=1
)
image_url = response.data[0].urlModo de edición de imágenes
Para editar imágenes existentes:
response = client.images.edit(
model="gpt-image-1.5",
image=open("imagen_entrada.png", "rb"),
prompt="Cambia el color de la pared a verde salvia",
size="1024x1024"
)Comparación de API: EvoLink.AI vs OpenAI Direct
| Característica | EvoLink.AI | OpenAI Direct |
|---|---|---|
| Acceso al modelo | gpt-image-1.5-lite | gpt-image-1.5 |
| Procesamiento | Asíncrono (basado en tareas) | Síncrono + opciones asíncronas |
| Entrada de imagen | Solo basada en URL | Carga de archivos + URL |
| Transparencia de precios | Consulta el panel de EvoLink.AI | Precios publicados de OpenAI |
| Servicios adicionales | En paquete con otras API de IA | Solo generación de imágenes |
| Documentación | evolink.ai docs | platform.openai.com/docs |
| Límites de velocidad | Variable según el plan | Basado en niveles (consulta docs de OpenAI) |
Mejores prácticas de API
- Implementa lógica de reintento: Pueden ocurrir fallas temporales durante los períodos de alta carga.
- Almacena en caché las generaciones exitosas: Guarda las URLs de las imágenes y los prompts asociados para referencia futura.
- Monitorea los límites de velocidad: Ambas plataformas imponen límites de solicitud según tu nivel de suscripción.
- Optimiza las plantillas de prompts: Crea estructuras de prompts reutilizables para obtener resultados consistentes.
- Maneja la expiración de imágenes: Descarga y almacena imágenes dentro de la ventana de 24 horas.
- Usa los niveles de calidad estratégicamente: Reserva la calidad
highpara los renders de producción finales para reducir costos.
Estructura de precios y estrategias de optimización de costos
Comprender la estructura de costos te ayuda a presupuestar de manera efectiva e identificar oportunidades de optimización.
Precios oficiales de OpenAI (A partir de diciembre de 2025)
- Generación de imágenes: Basada en el tamaño y el nivel de calidad.
- Entradas de imagen (para edición): Un 20% más baratas que GPT Image 1.
- Salidas de imagen: Un 20% más baratas que GPT Image 1.
Precios de EvoLink.AI
- Nivel de suscripción (varía según el volumen de llamadas API incluidas).
- Tarifas por solicitud más allá de la asignación incluida.
- Descuentos potenciales por volumen para clientes empresariales.
Estrategias de optimización de costos
1. Selección del nivel de calidad
quality afecta significativamente tanto al tiempo de generación como al costo:Calidad baja: Más rápida, más barata (buena para pruebas de concepto)
Calidad media: Equilibrada (adecuada para la mayoría de las aplicaciones)
Calidad alta: Más lenta, más cara (activos listos para producción)
Calidad automática: El modelo decide basándose en la complejidad del promptlow o medium para las iteraciones iniciales, luego regenera las selecciones finales con calidad high. Esto puede reducir los costos totales en un 40-60% en comparación con el uso constante de high.2. Optimización de la relación de aspecto
Las imágenes más grandes cuestan más generarlas. Jerarquía de costos:
1024×1024 (1:1) < 1024×1536 (3:4) = 1536×1024 (4:3)3. Procesamiento por lotes vs. tiempo real
Para flujos de trabajo no urgentes:
- Poner en cola múltiples solicitudes de generación.
- Procesar durante las horas de menor actividad (si el precio varía según el tiempo).
- Usar procesamiento asíncrono para evitar reintentos relacionados con el tiempo de espera.
4. Eficiencia del prompt
Los prompts más largos consumen más tokens. Técnicas de optimización:
- Elimina adjetivos innecesarios.
- Usa formatos estructurados (atributos separados por comas vs. párrafos).
- Evita descripciones redundantes.
- Prueba prompts mínimos viables.
Ejemplo de transformación:
Ineficiente (87 tokens): "Me gustaría que crearas una hermosa, impresionante y
asombrosa fotografía profesional de un smartphone moderno sobre un fondo blanco
limpio y prístino con una iluminación de estudio suave y gentil que venga desde arriba"
Eficiente (28 tokens): "Foto de producto profesional: smartphone sobre fondo
blanco, iluminación de estudio suave desde arriba"5. Almacenamiento en caché y reutilización
- Almacena generaciones exitosas con metadatos (prompt, parámetros, marca de tiempo).
- Crea una biblioteca de imágenes base para ediciones futuras en lugar de regenerarlas.
- Implementa la búsqueda semántica en tu caché de imágenes para encontrar activos existentes antes de generar nuevos.
6. Flujos de trabajo híbridos
Combina la generación de IA con herramientas tradicionales:
- Genera imágenes base con IA.
- Añade texto/logotipos complejos en Figma/Photoshop (evitando las limitaciones de texto de la IA).
- Usa la IA para variaciones de diseños probados en lugar de empezar desde cero.
- Flujo de trabajo de IA pura: 10 iteraciones × $0.XX por imagen = $X.XX en total.
- Flujo de trabajo híbrido: 3 iteraciones de IA + refinamiento manual = $X.XX + tiempo de diseño.
- Si el tiempo de diseño es más rápido que 7 iteraciones de IA, el enfoque híbrido ahorra dinero.
Descuentos por volumen para empresas
- Más de 10,000 imágenes al mes.
- Más de $1,000 de gasto mensual en la API.
- Acuerdos de compromiso de varios años.
Casos de uso y aplicaciones del mundo real
Comprender cómo diferentes industrias aplican GPT Image 1.5 aclara su valor práctico.
Catálogos de productos de comercio electrónico
- Fotografiar el producto una vez sobre un fondo neutro.
- Usar el modo de imagen a imagen para generar variantes en diferentes entornos.
- La preservación de detalles asegura que la apariencia del producto sea consistente.
- El logotipo y la marca permanecen intactos en todas las variantes.
Activos de marketing y marca
- Generar diseños base con colores y estilo de marca.
- Iterar ediciones preservando los logotipos y la identidad visual.
- Crear variantes de prueba A/B rápidamente.
- Producir versiones localizadas para diferentes mercados.
Producción de contenido para redes sociales
- Generar una imagen maestra al tamaño más grande requerido.
- Crear recortes/variantes específicos para cada plataforma.
- Aplicar filtros de estilo para estéticas apropiadas para cada canal.
- Añadir superposiciones de texto (o generar con el renderizado de texto de IA para titulares).
- Instagram (1:1): 1024×1024
- Instagram Stories (3:4): 1024×1536
- Twitter/X (4:3): 1536×1024
- Todo generado a partir de un solo prompt con cambios en el parámetro de tamaño.
Visualización de conceptos de diseño
- Prototipar visualmente conceptos de forma rápida.
- Probar múltiples direcciones de estilo.
- Recopilar comentarios sobre las opciones.
- Refinar la dirección ganadora hasta obtener una calidad de producción.
Editorial y publicaciones
- Generar ilustraciones conceptuales para temas abstractos.
- Crear visualizaciones de datos con etiquetas de texto legibles.
- Producir diseños de estilo de revista con titulares.
- Desarrollar temas visuales consistentes a lo largo de series de artículos.
Materiales educativos y de capacitación
- Generar ilustraciones basadas en escenarios (situaciones laborales, demostraciones de seguridad).
- Crear diagramas y organigramas simplificados.
- Producir una representación diversa en los materiales de instrucción.
- Desarrollar visuales personalizados para contextos de aprendizaje específicos.
Inmobiliaria y arquitectura
- Generar interiores decorados a partir de fotos de habitaciones vacías.
- Visualizar conceptos de renovación.
- Crear imágenes de estilo de vida para el marketing inmobiliario.
- Desarrollar múltiples opciones de estilo de diseño para la selección del cliente.
Ingeniería de prompts avanzada para mejores resultados
Dominar la estructura de los prompts mejora drásticamente la calidad de la salida y reduce el desperdicio de iteraciones.
Anatomía de un prompt efectivo
Los prompts de alto rendimiento siguen esta estructura:
[SUJETO] + [ACCIÓN/POSE] + [ESCENARIO/CONTEXTO] + [ESTILO/ESTÉTICA] +
[ESPECIFICACIONES TÉCNICAS] + [REGLAS DE COMPOSICIÓN]Sujeto: Mujer de negocios profesional con traje azul marino
Acción: De pie con confianza con los brazos cruzados
Escenario: Oficina de vidrio moderna con el horizonte de la ciudad visible a través de las ventanas
Estilo: Estética de fotografía profesional corporativa
Técnico: Profundidad de campo superficial, iluminación natural de la ventana desde la izquierda
Composición: Sujeto posicionado en el tercio derecho del encuadre, espacio negativo a la izquierdaFórmulas de prompts para escenarios comunes
Fotografía de producto
"Foto de producto profesional de [PRODUCTO] en [FONDO],
[ESTILO DE ILUMINACIÓN], [ÁNGULO DE CÁMARA], [HUMOR], calidad comercial de alta gama"Ejemplo: "Foto de producto profesional de un reloj de lujo sobre una superficie de mármol negro, iluminación lateral dramática con sombras suaves, ángulo de 45 grados, humor elegante y premium, calidad comercial de alta gama"
Fotografía de retrato
"Retrato [TIPO DE TOMA] de [DESCRIPCIÓN DEL SUJETO], [EXPRESIÓN],
[ROPA], [FONDO], [ILUMINACIÓN], [ESTILO DE CONFIGURACIÓN DE CÁMARA]"Ejemplo: "Retrato de primer plano de una mujer de mediana edad con cabello corto gris, sonrisa genuina, vistiendo una chaqueta de mezclilla informal, fondo exterior desenfocado, iluminación natural de hora dorada, profundidad de campo superficial"
Escena de estilo de vida
"Escena de [MOMENTO DEL DÍA] que muestra [ACTIVIDAD] en [UBICACIÓN],
[HUMOR/ATMÓSFERA], [DESCRIPCIÓN DE PERSONAS], [REFERENCIA DE ESTILO]"Ejemplo: "Escena matutina que muestra un desayuno familiar en una cocina escandinava moderna, atmósfera cálida y acogedora, familia diversa de cuatro personas, estilo de fotografía de estilo de vida natural"
Infografía/Visualización de datos
"Infografía limpia que muestra [DATOS/CONCEPTO], [ESTILO DE DISEÑO],
[ESQUEMA DE COLORES], [ELEMENTOS DE TEXTO], calidad de diseño profesional"Ejemplo: "Infografía limpia que muestra el crecimiento de las ventas trimestrales, diseño de gráfico de barras vertical, esquema de colores azul y blanco, titular en negrita 'Resultados del cuarto trimestre de 2025' en la parte superior con etiquetas de porcentaje, calidad de diseño empresarial profesional"
Estrategias de prompts negativos
Aunque GPT Image 1.5 no admite oficialmente prompts negativos de la misma manera que Stable Diffusion, puedes evitar elementos no deseados a través de frases positivas:
Usa: "Fondo limpio y minimalista"
Usa: "Iluminación natural y realista"
Usa: "Estilo de fotografía profesional y fotorrealista"
Flujo de trabajo de refinamiento en varios pasos
Para proyectos complejos que requieren alta calidad:
- Generación de concepto inicial (calidad baja, prompt amplio)
- Generar de 3 a 5 variaciones.
- Identificar la dirección prometedora.
- Iteración de refinamiento (calidad media, prompt detallado)
- Añadir restricciones específicas al concepto ganador.
- Ajustar la composición, la iluminación y los elementos.
- Probar de 2 a 3 variantes.
- Pulido de detalles (calidad alta, prompts de edición precisos)
- Realizar ediciones dirigidas a la versión casi final.
- Ajustar elementos específicos uno a la vez.
- Preservar todo excepto los elementos cambiados.
- Producción final (calidad alta)
- Regenerar con un prompt optimizado que incorpore todos los aprendizajes.
- Exportar a resolución completa.
Bibliotecas de prompts y control de versiones
Mantén una biblioteca de prompts estructurada:
Proyecto: Campaña de vacaciones 2025
Versión: 1.0
Fecha: Diciembre de 2025
Plantilla de prompt base:
"Escena festiva de vacaciones que muestra [SUJETO], atmósfera cálida y acogedora,
iluminación dorada, fotografía profesional, [ELEMENTOS_ESPECÍFICOS]"
Variaciones:
V1.0: Concepto inicial → Se añadió "profundidad de campo superficial"
V1.1: Comentarios del cliente → Se cambió "cálida y acogedora" por "brillante y alegre"
V1.2: Final → Se añadieron "colores de acento rojo y dorado"
Prompt ganador: [Versión final optimizada]
Imágenes generadas: [Enlaces a los resultados guardados]Esta documentación evita volver a descubrir fórmulas exitosas y permite la colaboración en equipo.
Errores comunes a evitar al usar GPT Image 1.5
Aprender de los errores típicos acelera tu dominio y evita esfuerzos inútiles.
1. Prompts vagos y no estructurados
2. Esperar un texto perfecto al primer intento
3. Ignorar las implicaciones del nivel de calidad
high para cada generación, incluyendo las pruebas de concepto iniciales.low o medium es suficiente.4. Sobre-editar más allá de los límites del modelo
5. No preservar los prompts exitosos
6. Preparación inadecuada de la imagen de referencia
- De alta resolución (mínimo 1024 px en el borde más largo).
- Bien iluminadas con sujetos claros.
- De composición limpia sin elementos que distraigan.
- Con el formato correcto (.jpg, .png, .webp).
7. Esperar precisión arquitectónica/técnica
8. Descuidar los plazos de expiración de las imágenes
9. Estructura de prompt inconsistente entre proyectos
10. No probar modelos competitivos
Limitaciones y cuándo elegir herramientas alternativas
GPT Image 1.5 representa un avance significativo, pero no es universalmente óptimo. Comprender sus límites te ayuda a realizar selecciones de herramientas informadas.
Limitaciones técnicas
- Coherencia de escenas complejas
- Las imágenes con más de 10 objetos distintos a menudo muestran inconsistencias espaciales.
- Los elementos transparentes superpuestos (vidrio, agua) producen artefactos.
- Escenas con múltiples personas tienen dificultades con la precisión anatómica en las multitudes.
- Cuándo importa: fotos de grupos grandes, arreglos de productos complejos, ilustraciones detalladas.
- Techo de realismo fotográfico
- Algunas salidas todavía muestran el "aspecto de IA" (suavizado excesivo, perfección antinatural).
- La textura de la piel y los detalles de los poros a veces parecen artificiales.
- Ciertos escenarios de iluminación (sol intenso del mediodía, reflejos complejos) siguen siendo un desafío.
- Cuándo importa: fotografía de moda de alta gama, trabajo documental, retratos naturalistas.
- Límites del renderizado de texto
- El texto de cuerpo de más de 20-30 palabras contiene errores.
- Guiones no latinos poco confiables.
- Fuentes estilizadas y escritura a mano inconsistentes.
- El texto en superficies curvas se distorsiona.
- Cuándo importa: infografías con texto extenso, contenido multilingüe, tipografía decorativa.
- Especificidad cultural y geográfica
- Los datos de entrenamiento se inclinan hacia contextos occidentales [No verificado—inferido del análisis de salida].
- La arquitectura regional, la ropa y los detalles culturales pueden carecer de autenticidad.
- Subculturas de nicho y contextos especializados subrepresentados.
- Cuándo importa: marketing culturalmente específico, campañas regionales, requisitos de representación auténtica.
- Límites de la profundidad de iteración
- La calidad se degrada después de 6 a 8 ediciones consecutivas.
- Los artefactos acumulados se agravan durante los pases de edición.
- La consistencia de rostros y logotipos se reduce con iteraciones excesivas.
- Cuándo importa: proyectos que requieren más de 10 pases de refinamiento, edición colaborativa extensa.
Cuándo elegir herramientas alternativas
Elige Nano Banana Pro cuando:
- El fotorrealismo es el requisito principal.
- El contenido de las redes sociales necesita tendencias estéticas contemporáneas.
- Las escenas naturales (paisajes, multitudes, eventos) dominan tus necesidades.
- La velocidad de adopción y el crecimiento del ecosistema importan para la incorporación del equipo.
Elige Midjourney cuando:
- La interpretación artística agrega valor sobre la precisión literal.
- El trabajo conceptual, abstracto o estilizado encaja con tu marca.
- Las bibliotecas de prompts y los estilos impulsados por la comunidad benefician tu flujo de trabajo.
- La visión creativa importa más que el control de la producción.
Elige Stable Diffusion cuando:
- Necesitas un control total sobre el entrenamiento y la personalización del modelo.
- Las restricciones presupuestarias requieren soluciones gratuitas/de código abierto.
- El equipo técnico puede manejar el autoalojamiento y la optimización.
- Es necesario un ajuste fino especializado para casos de uso de nicho.
Elige fotografía/diseño tradicional cuando:
- La precisión técnica no es negociable (arquitectura, ingeniería, medicina).
- Los requisitos legales exigen contenido creado por humanos autenticado.
- Los valores de la marca enfatizan el arte humano sobre la asistencia de la IA.
- El presupuesto permite servicios profesionales y la calidad justifica el costo.
Elige flujos de trabajo híbridos cuando:
- Los proyectos requieren tanto la eficiencia de la IA como el control de calidad humano.
- Los elementos de texto exceden las capacidades de la IA.
- Las pautas de marca exigen una consistencia absoluta.
- La verificación del cumplimiento y la autenticidad son críticas.
Consideraciones éticas y legales
Preguntas frecuentes (FAQs)
1. ¿Cuánto cuesta GPT Image 1.5 en comparación con la contratación de un diseñador?
Sin embargo, los diseñadores proporcionan dirección creativa, comprensión de la marca y precisión técnica que la IA no puede igualar. El enfoque óptimo para muchas empresas es un modelo híbrido: usar la IA para contenido de alto volumen y menor riesgo (redes sociales, pruebas de conceptos, imágenes de estilo stock) mientras se reserva el tiempo del diseñador para campañas insignia, trabajos que definen la marca y proyectos que requieren una visión creativa humana.
2. ¿Puede GPT Image 1.5 mantener una apariencia de personaje constante en múltiples imágenes?
- Generar una imagen de personaje inicial con una descripción detallada.
- Guardar esta imagen como referencia de tu personaje.
- Usar el modo de imagen a imagen con la referencia para las siguientes generaciones.
- Proporcionar una estructura de prompt consistente que describa al personaje.
- Aceptar que ocurrirán variaciones menores—la consistencia perfecta en generaciones completamente nuevas aún no es confiable.
Para proyectos que requieren una consistencia de personaje absoluta (series animadas, mascotas de marca, campañas en curso), considera usar la IA para generar el concepto inicial y luego trabaja con un ilustrador para crear una hoja de modelo definitiva que pueda ser referenciada para todo el trabajo futuro.
3. ¿Funciona GPT Image 1.5 en otros idiomas además del inglés?
- Español, francés, alemán, italiano: Generalmente funcionales con cierta reducción en la precisión en comparación con el inglés.
- Idiomas CJK (chino, japonés, coreano): Existe comprensión del prompt, pero el renderizado del texto en las imágenes sigue siendo poco confiable.
- Otros idiomas: Datos de prueba limitados disponibles [No verificado].
4. ¿Cómo maneja GPT Image 1.5 los derechos de autor y la propiedad intelectual en las imágenes generadas?
- PI de terceros: El modelo está diseñado para negarse a generar contenido basado en personajes con derechos de autor, logotipos de marcas registradas o imágenes de celebridades identificables.
- Datos de entrenamiento: El modelo se entrenó con imágenes disponibles públicamente, que pueden incluir material con derechos de autor utilizado bajo doctrinas de uso justo para fines de entrenamiento.
- Uso comercial: Las salidas normalmente pueden usarse comercialmente, pero revisa los términos actuales de OpenAI y tu caso de uso específico.
- Atribución: OpenAI no requiere atribución para las imágenes generadas por IA, pero algunos contextos y plataformas pueden requerir la divulgación de que el contenido es generado por IA.
5. ¿Puedo usar GPT Image 1.5 para editar fotos existentes que poseo?
- Cargar tus propias fotos.
- Solicitar modificaciones específicas a través de prompts en lenguaje natural.
- Preservar los elementos originales mientras cambias características especificadas.
- Generar variaciones sobre tu imaginería existente.
- La foto original es de alta calidad (mínimo 1024 px).
- La iluminación es buena y el sujeto es claramente visible.
- El fondo no es excesivamente complejo.
- Tu solicitud de edición es específica y dirigida.
6. ¿Cuál es la diferencia entre GPT Image 1.5 y GPT Image 1.5 Lite?
gpt-image-1.5-lite) es la designación del modelo de API utilizada por plataformas como evolink.ai. Según la documentación disponible, "Lite" se refiere al nombre del punto de enlace de la API en lugar de indicar una versión con capacidades reducidas. El modelo accesible a través de este punto de enlace parece ser el mismo modelo insignia GPT Image 1.5 disponible en ChatGPT.Algunas plataformas pueden ofrecer niveles de calidad adicionales o parámetros que podrían describirse como versiones "lite" vs. "full", pero el modelo oficial de OpenAI es simplemente "GPT Image 1.5". Si existen diferencias de costo o capacidad entre las implementaciones de las plataformas, consulta la documentación de tu proveedor de API específico para obtener aclaraciones.
7. ¿Cuánto tiempo son válidas las URLs de las imágenes generadas y cómo debo almacenarlas?
- Descarga inmediata: Configura descargas automáticas en tu flujo de trabajo para capturar las imágenes inmediatamente después de la generación.
- Almacenamiento en la nube: Sube las imágenes a tu propio S3, Google Cloud Storage o servicio similar para un archivado permanente.
- Preservación de metadatos: Almacena los prompts asociados, los parámetros y las marcas de tiempo de generación con cada imagen para referencia futura.
- Convenciones de nombres: Usa nombres de archivos descriptivos y buscables que incluyan identificadores de proyectos y números de versión.
- Estrategia de respaldo: Mantén copias redundantes para los activos comerciales críticos.
1. Generar imagen → recibir URL temporal
2. Descargar la imagen al almacenamiento local/en la nube en 1 hora
3. Almacenar la URL permanente en tu base de datos
4. Eliminar la URL temporal de OpenAI de tus registros
5. Hacer referencia a tu URL de almacenamiento permanente de ahora en adelante8. ¿Puede GPT Image 1.5 generar imágenes adecuadas para impresión o es solo para uso digital?
- 1024×1024 píxeles (cuadrado)
- 1024×1536 píxeles (retrato)
- 1536×1024 píxeles (paisaje)
| Tamaño de impresión | DPI necesario | Resolución adecuada | ¿GPT Image 1.5 OK? |
|---|---|---|---|
| Redes sociales | 72 DPI | 1200×1200 | ✓ Sí |
| Cabecera de sitio web | 72-96 DPI | 1920×1080 | ✓ Sí |
| Diapositivas de presentación | 96-150 DPI | 1920×1080 | ✓ Sí |
| Tarjeta de presentación | 300 DPI | 1050×600 | ⚠️ Marginal |
| Impresión de foto 8×10" | 300 DPI | 2400×3000 | ✗ No |
| Página completa de revista | 300 DPI | 2550×3300 | ✗ No |
| Valla publicitaria | 150 DPI+ | 14400×4800+ | ✗ No |
- Escalado de IA: Usa herramientas de escalado especializadas (Topaz Gigapixel, Real-ESRGAN) para aumentar la resolución después de la generación.
- Limitación del tamaño de impresión: Usa imágenes generadas por IA solo para elementos de impresión más pequeños (iconos, ilustraciones puntuales) en lugar de páginas de sangrado completo.
- Estrategia digital primero: Prioriza la generación de IA para los canales digitales y encarga fotografía/ilustración tradicional para las campañas impresas.
- Conversión a vectores: Para logotipos y gráficos simples, convierte las salidas de IA al formato vectorial para que sean independientes de la resolución.
9. ¿Es GPT Image 1.5 mejor que Midjourney para el trabajo de diseño profesional?
- Necesitas un control preciso sobre las ediciones iterativas.
- La integración del flujo de trabajo con ChatGPT beneficia a tu equipo.
- El renderizado de texto en las imágenes es importante.
- Se requiere automatización de API.
- La preservación del logotipo y los elementos de la marca importa.
- La velocidad (4 veces más rápida) justifica una calidad artística ligeramente inferior.
- Las funciones y el soporte empresarial son prioridades.
- La interpretación artística mejora tu trabajo.
- La calidad estética es primordial.
- Las bibliotecas de prompts y los estilos de la comunidad se alinean con tu marca.
- Estás creando arte conceptual, ilustraciones o campañas creativas.
- El flujo de trabajo basado en Discord encaja con la estructura de tu equipo.
- Se necesitan soluciones conscientes del presupuesto.
- Usa Midjourney para imágenes destacadas, banners principales y creatividad insignia.
- Usa GPT Image 1.5 para variantes de productos, contenido social y revisiones iterativas de clientes.
- Usa el diseño tradicional para el pulido final y los requisitos técnicos.
10. ¿Qué pasa con GPT Image 1 ahora que el 1.5 está disponible?
- Rendimiento superior (generación 4 veces más rápida).
- Mejor seguimiento de instrucciones.
- Precisión de edición mejorada.
- Costos un 20% más bajos para entradas y salidas.
- Desarrollo y mejoras continuas.


