
Guía para desarrolladores sobre el enrutador de equilibrador de carga

En lugar de permitir que un servidor se abrume, el enrutador distribuye de manera inteligente las solicitudes entrantes a través de un grupo de servidores o, en el contexto de las aplicaciones de IA modernas, diferentes modelos de IA. El resultado es una aplicación de alta disponibilidad y alto rendimiento que ofrece una experiencia perfecta para sus usuarios.
¿Cómo funciona un enrutador de equilibrador de carga?
En esencia, un enrutador de equilibrador de carga está diseñado para eliminar los puntos únicos de falla. En una arquitectura típica de un solo servidor, si ese servidor se sobrecarga o se desconecta, toda su aplicación se detiene.
Un enrutador de equilibrador de carga se sitúa entre sus usuarios y su grupo de servidores, interceptando cada solicitud entrante y decidiendo qué recurso descendente está mejor equipado para manejarla en ese momento. Este concepto ha evolucionado significativamente desde los primeros dispositivos de hardware hasta la sofisticada capa de software que sustenta los sistemas distribuidos modernos. Comprender este principio es el primer paso hacia la construcción de sistemas resistentes, especialmente cuando se trata de la naturaleza impredecible del tráfico de API.
Por qué cada aplicación moderna necesita uno
Para los desarrolladores, un equilibrador de carga bien implementado ofrece ventajas críticas:
- Alta disponibilidad: Si un servidor o un endpoint de API falla o deja de responder, el enrutador lo elimina automáticamente del grupo y redirige el tráfico a instancias en buen estado. Su aplicación permanece en línea.
- Escalabilidad: Para manejar una mayor carga, simplemente agregue más servidores al grupo. El equilibrador de carga comenzará a enrutar el tráfico hacia ellos de inmediato, lo que permite el escalado horizontal sin tiempo de inactividad.
- Rendimiento mejorado: Al distribuir la carga de trabajo, se asegura de que las solicitudes de los usuarios sean siempre manejadas por un servidor receptivo, lo que reduce la latencia y mejora la experiencia general del usuario.
Piense en un enrutador de equilibrador de carga como la primera línea de defensa de su aplicación contra las interrupciones. Transforma una colección de servidores independientes en un sistema único, potente y resistente.
Dominar este concepto le permite diseñar para la resiliencia desde el principio, en lugar de tratarlo como una idea de último momento.
Comprender los algoritmos básicos de equilibrio de carga
Estos algoritmos proporcionan la lógica para distribuir la carga de trabajo. La infografía siguiente ilustra cómo funcionan juntas las diferentes estrategias para gestionar el tráfico de red de forma eficaz.
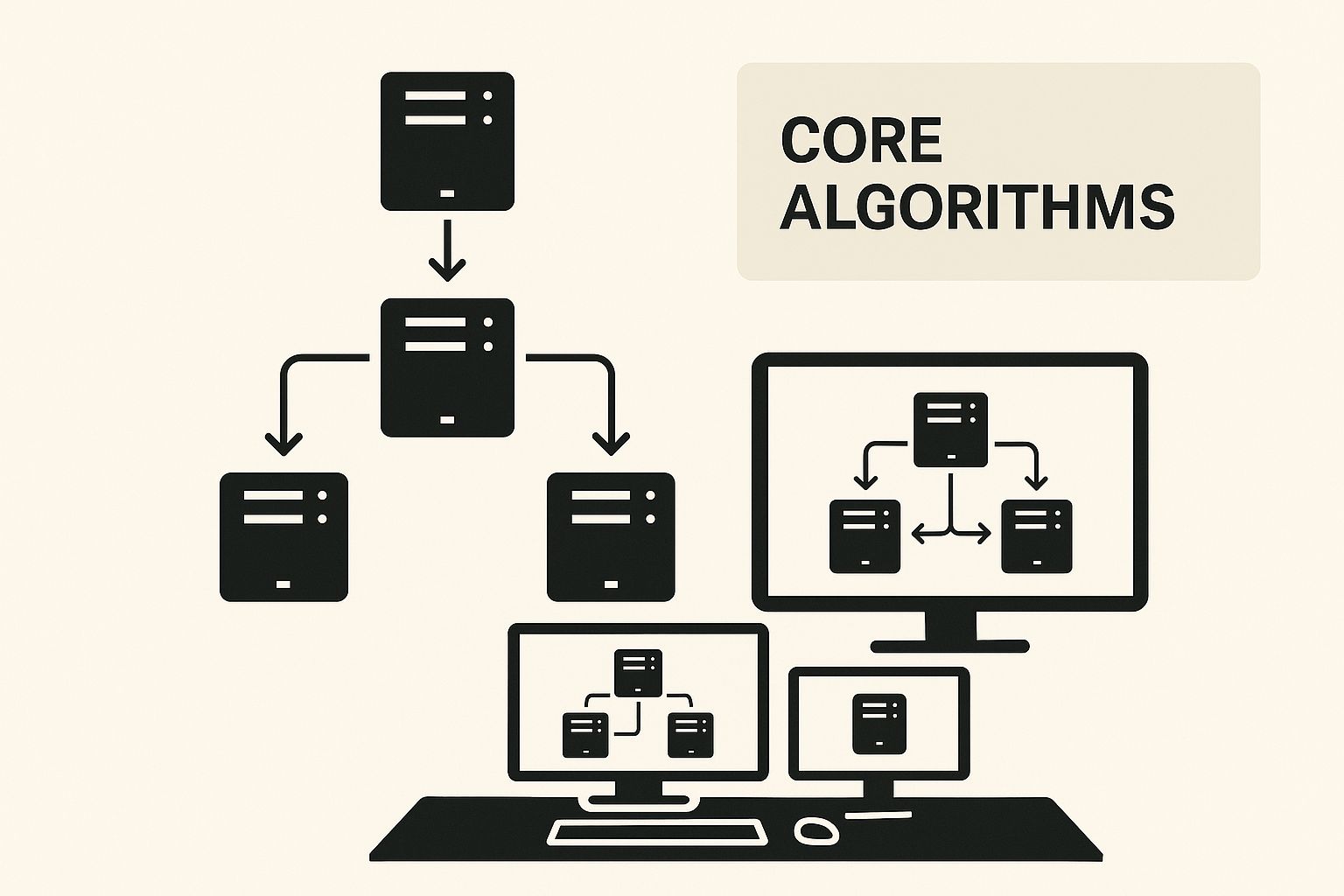
Como puede ver, estos métodos fundamentales son los componentes básicos para decisiones de enrutamiento más sofisticadas. El objetivo es evitar que cualquier servidor individual se abrume y cause una falla en todo el sistema.
Métodos de distribución comunes
Entonces, ¿cómo decide un equilibrador de carga dónde enviar el tráfico? Normalmente utiliza uno de varios algoritmos estándar.
-
Round Robin: Este es el método más simple y común. El equilibrador de carga recorre una lista de servidores, enviando cada nueva solicitud al siguiente servidor de la secuencia. Es predecible, pero asume que todos los servidores tienen la misma capacidad y que todas las solicitudes tienen costos de procesamiento similares.
-
Menos conexiones (Least Connections): Esta es una estrategia más dinámica. El algoritmo enruta las nuevas solicitudes al servidor con la menor cantidad de conexiones activas. Esto es particularmente efectivo en entornos donde la duración de las conexiones varía, evitando que un servidor se vea atado con tareas de larga ejecución mientras otros están inactivos.
-
IP Hash: Este método utiliza un hash de la dirección IP del cliente para mapear consistentemente a ese cliente con el mismo servidor. El beneficio principal es la persistencia de la sesión (o "stickiness"), que es crítica para aplicaciones con estado (stateful) como los carritos de compras de comercio electrónico, donde los datos de la sesión del usuario deben mantenerse en un servidor específico.
Comparación de algoritmos comunes de equilibrio de carga
Elegir el algoritmo adecuado depende de los requisitos específicos de su aplicación. Esta tabla desglosa los métodos más comunes para ayudarle a compararlos.
| Algoritmo | Cómo funciona | Mejor para | Desventaja potencial |
|---|---|---|---|
| Round Robin | Distribuye las solicitudes secuencialmente a cada servidor en una lista. | Entornos donde los servidores son idénticos y las solicitudes son uniformes. | No tiene en cuenta la carga del servidor ni los tiempos de procesamiento variables. |
| Menos conexiones | Envía nuevas solicitudes al servidor con la menor cantidad de conexiones activas. | Situaciones con conexiones de larga duración o cargas de solicitudes desiguales. | Puede requerir más recursos de computación para rastrear las conexiones. |
| IP Hash | Asigna una solicitud a un servidor específico basado en la dirección IP de origen. | Aplicaciones que requieren persistencia de sesión (p. ej., carritos de compras). | Puede llevar a una distribución desigual si ciertas direcciones IP envían muchas solicitudes. |
| Weighted Round Robin | Una variación de Round Robin donde a los servidores se les asigna un "peso" basado en su capacidad. | Entornos con servidores de diferentes capacidades de procesamiento. | Requiere configuración manual de pesos y ajustes a lo largo del tiempo. |
En última instancia, no existe un único algoritmo "mejor". El objetivo es alinear la lógica de distribución con el comportamiento de su aplicación y la arquitectura de su infraestructura.
Enrutamiento ponderado e inteligente
Si bien estos algoritmos clásicos son efectivos para el tráfico web tradicional, se quedan cortos cuando se trata de enrutar solicitudes de IA a través de múltiples proveedores. Un algoritmo simple de Round Robin no tiene concepto de costo o disponibilidad; podría enviar a ciegas su solicitud a un proveedor costoso o no disponible. Este es precisamente el problema que resuelve un enrutador de equilibrador de carga avanzado como EvoLink, enrutando de manera inteligente su modelo elegido al proveedor más rentable y confiable en tiempo real.
El desafío moderno del enrutamiento de modelos de IA
El equilibrio de carga tradicional asume que está distribuyendo tráfico a través de una flota de servidores idénticos. Este modelo funciona bien para solicitudes web sin estado, pero se rompe por completo cuando se aplica al ecosistema diverso de modelos de IA.
Modelos como GPT-4, Llama 3 y Claude Haiku no son intercambiables. Diferen significativamente en sus capacidades de razonamiento, latencia de respuesta y, críticamente, su costo por token. Esto transforma el problema de la simple distribución de tráfico en un rompecabezas complejo de optimización multiobjetivo.
Usar un enfoque básico de Round Robin aquí es ineficiente y costoso. Podría enrutar una tarea de resumen simple a su modelo más potente (y costoso), mientras que una consulta analítica compleja podría enviarse a un modelo más rápido pero menos capaz, resultando en una respuesta subóptima.

De servidores uniformes a múltiples proveedores de IA
Una vez que selecciona su modelo de IA deseado, un enrutador nativo de IA debe evaluar varios factores para cada solicitud:
- Costo del proveedor: El mismo modelo GPT-4 puede costar 10 veces más en un proveedor que en otro. Encontrar el proveedor disponible más barato para el modelo elegido ofrece ahorros inmediatos.
- Disponibilidad del proveedor: ¿Está el proveedor actualmente en línea y es receptivo? Las comprobaciones de estado en tiempo real aseguran que sus solicitudes siempre lleguen a un endpoint que funcione.
- Latencia del proveedor: ¿Qué proveedor ofrece el tiempo de respuesta más rápido en este momento? El monitoreo dinámico del rendimiento enruta al proveedor más receptivo en ese momento.
Un enrutador de IA inteligente no solo equilibra la carga; optimiza para los resultados comerciales. Para el modelo seleccionado, toma una decisión dinámica e informada para cada llamada a la API para ofrecer el mejor rendimiento al menor costo posible al elegir el proveedor óptimo.
Un ejemplo de código para el enrutamiento inteligente de proveedores
Esta función conceptual de JavaScript demuestra la lógica para seleccionar el proveedor óptimo para un modelo elegido. Comprueba la disponibilidad y el costo del proveedor para enrutar al mejor endpoint.
// Una función conceptual para seleccionar el mejor proveedor para un modelo elegido
async function routeToProvider(selectedModel) {
// El usuario ya ha seleccionado GPT-4 como su modelo
const providers = [
{ name: 'OpenAI', endpoint: 'https://api.openai.com/v1/chat/completions', cost: 0.03, available: true },
{ name: 'Azure', endpoint: 'https://azure.openai.com/v1/chat/completions', cost: 0.035, available: true },
{ name: 'Provider-A', endpoint: 'https://api.provider-a.com/v1/gpt-4', cost: 0.015, available: true },
{ name: 'Provider-B', endpoint: 'https://api.provider-b.com/v1/gpt-4', cost: 0.012, available: false }
];
// Filtrar solo a los proveedores disponibles
const availableProviders = providers.filter(p => p.available);
// Ordenar por costo, el más barato primero
availableProviders.sort((a, b) => a.cost - b.cost);
// Seleccionar el proveedor disponible más barato
const selectedProvider = availableProviders[0];
console.log(`Enrutando ${selectedModel} a ${selectedProvider.name} a $${selectedProvider.cost} por solicitud`);
// En una aplicación real, haría la llamada a la API aquí
// const response = await fetch(selectedProvider.endpoint, { ... });
// return response.json();
return {
model: selectedModel,
provider: selectedProvider.name,
endpoint: selectedProvider.endpoint,
cost: selectedProvider.cost
};
}
// Ejemplo de uso - el usuario seleccionó GPT-4
routeToProvider('GPT-4').then(result => console.log(result));Si bien este código ilustra el concepto central, construir un sistema listo para producción implica mucho más: administrar claves de API para docenas de proveedores, rastrear precios y disponibilidad en tiempo real, implementar failover automático cuando los proveedores caen y monitorear continuamente el rendimiento.
Poniendo en acción el enrutamiento avanzado de IA con EvoLink
Construir un enrutador de IA inteligente desde cero es un desafío de ingeniería significativo. Requiere administrar múltiples claves de API, monitorear el rendimiento del modelo en tiempo real, codificar una lógica de failover robusta y actualizar continuamente el sistema a medida que se lanzan nuevos modelos. Esta es la razón por la que una solución administrada como EvoLink es un cambio de juego para los equipos de desarrollo.
Este enfoque unificado reduce drásticamente la sobrecarga operativa y libera a su equipo de ingeniería para concentrarse en su producto principal, no en administrar la infraestructura de IA.
Cómo funciona el enrutamiento inteligente en el mundo real
Así es como las funciones principales de EvoLink brindan beneficios tangibles:
- Failover automático del modelo: Si un proveedor principal como OpenAI experimenta una interrupción o degradación del rendimiento, EvoLink redirige automáticamente las llamadas a la API a un proveedor alternativo en buen estado que ofrezca el mismo modelo. Su aplicación continúa funcionando sin problemas.
- Enrutamiento de rendimiento dinámico: El sistema monitorea continuamente la latencia y el rendimiento de todos los proveedores disponibles para el modelo elegido, enviando cada solicitud al proveedor que pueda entregar la respuesta más rápida en ese momento.
- Optimización inteligente de costos: EvoLink enruta automáticamente su solicitud al proveedor más rentable para el modelo elegido, comparando constantemente los precios entre docenas de proveedores para asegurar que siempre esté obteniendo la mejor tarifa.
Al dirigir el tráfico de manera inteligente, los desarrolladores que usan EvoLink a menudo logran ahorros de costos de entre el 20 y el 70%. Esto no se trata solo de seleccionar el proveedor más barato; se trata de hacer la elección de proveedor más inteligente para cada solicitud para equilibrar el rendimiento y el presupuesto mientras usa sus modelos preferidos.
Un ejemplo de código práctico con EvoLink
Considere este ejemplo de Python. Usted proporciona una lista priorizada de modelos, y EvoLink administra todo el enrutamiento, la optimización y el failover automáticamente.
import os
import requests
# Establezca su clave de API de EvoLink desde las variables de entorno
api_key = os.getenv("EVOLINK_API_KEY")
api_url = "https://api.evolink.ai/v1/chat/completions"
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}
# Defina su modelo preferido con opciones de reserva
# EvoLink enruta cada modelo al proveedor disponible más barato
# Si su primera opción no está disponible, hace failover al siguiente modelo de su lista
payload = {
"model": ["openai/gpt-4o", "anthropic/claude-3.5-sonnet", "google/gemini-1.5-pro"],
"messages": [
{"role": "user", "content": "Analyze the sentiment of this customer review: 'The product is good, but the shipping was slow.'"}
]
}
try:
response = requests.post(api_url, headers=headers, json=payload)
response.raise_for_status() # Generar un HTTPError para respuestas malas (4xx o 5xx)
print(response.json())
except requests.exceptions.RequestException as e:
print(f"Ocurrió un error en la API: {e}")Este fragmento demuestra el poder de la abstracción. El código de su aplicación se mantiene limpio y enfocado en la lógica comercial, mientras que un potente enrutador de equilibrador de carga trabaja en segundo plano para que su aplicación sea más resistente y económica.
EvoLink elimina la necesidad de construir y mantener un complejo sistema interno, proporcionando una solución lista para producción que brinda resultados inmediatos. Esto permite a su equipo integrar capacidades de IA de clase mundial de manera más rápida y eficiente.
Estrategias de enrutamiento prácticas que puede implementar
Exploremos cuatro estrategias prácticas que puede implementar.

Enrutamiento basado en costos
Esta estrategia prioriza su presupuesto. El enrutamiento basado en costos envía automáticamente su solicitud al proveedor más asequible para el modelo elegido.
Enrutamiento basado en la latencia
Cuando la experiencia del usuario es primordial, el enrutamiento basado en la latencia es la elección óptima. Es esencial para aplicaciones en tiempo real como chatbots de servicio al cliente o herramientas de IA interactivas donde cada milisegundo cuenta.
El enrutador monitorea continuamente el rendimiento en tiempo real de todos los proveedores disponibles para el modelo elegido. Cuando llega una solicitud, se reenvía instantáneamente al proveedor con el tiempo de respuesta actual más bajo, lo que garantiza que sus usuarios reciban la respuesta más rápida posible sin cambiar el modelo que está utilizando.
Enrutamiento de Failover
El enrutamiento de failover es la red de seguridad de su aplicación. Inevitablemente, los proveedores de API experimentan interrupciones o degradación del rendimiento. Cuando esto ocurre, el enrutador redirige automáticamente las solicitudes al siguiente modelo en buen estado en una lista de prioridad predefinida.
Esta estrategia es fundamental para construir sistemas de alta disponibilidad que puedan manejar con gracia las fallas de los proveedores sin ningún impacto en la experiencia del usuario final.
Preguntas frecuentes
¿Cuál es la diferencia entre un equilibrador de carga y un enrutador?
Aunque a menudo se usan juntos, estos componentes cumplen funciones distintas en una red.
¿Puedo construir mi propio equilibrador de carga de modelos de IA?
Técnicamente, sí, puede construir una solución personalizada. Sin embargo, la complejidad de un enrutador de IA de grado de producción es sustancial.
Una solución robusta requiere más que una simple distribución de solicitudes. Usted sería responsable de administrar de forma segura docenas de claves de API, rastrear el costo y la latencia en tiempo real para cada modelo, implementar comprobaciones de estado de salud confiables y diseñar una lógica de failover efectiva. Además, este sistema requeriría un mantenimiento constante para incorporar nuevos modelos y adaptarse a los cambios de las API.
Aquí es donde una solución administrada como EvoLink proporciona un valor significativo. Ya hemos diseñado un sistema endurecido para producción que maneja toda esta complejidad. Usted obtiene una única API unificada con enrutamiento inteligente incorporado, lo que permite a su equipo concentrarse en su producto principal en lugar de en la infraestructura. Este enfoque puede generar ahorros de costos inmediatos del 20 al 70% y garantizar una alta confiabilidad desde el primer día.
¿Cómo hace realmente un enrutador de equilibrador de carga que mi aplicación sea más confiable?
La confiabilidad se logra a través de dos mecanismos principales: redundancia y comprobaciones de estado automatizadas.
Al distribuir las solicitudes entre múltiples modelos o servidores, un equilibrador de carga elimina los puntos únicos de falla. Si una API de modelo deja de estar disponible o un servidor falla, la aplicación permanece operativa porque el tráfico se dirige automáticamente a las alternativas en buen estado.
El sistema también realiza comprobaciones de estado continuas en cada endpoint, de forma similar al monitoreo de signos vitales. Envía solicitudes regularmente para verificar que cada endpoint sea receptivo. Si un endpoint falla en estas comprobaciones o devuelve errores, el enrutador lo elimina instantáneamente del grupo activo y redirige sin problemas las nuevas solicitudes a los endpoints restantes en buen estado. Este failover automático es lo que garantiza la alta disponibilidad, incluso durante fallas parciales del sistema.


