
Warum LLM-APIs nicht standardisiert sind

Das Problem der LLM-API-Fragmentierung (und warum "OpenAI-kompatibel" nicht genug ist)
Wenn Sie danach suchen, warum LLM-APIs nicht standardisiert sind, erleben Sie wahrscheinlich bereits den Schmerz.
Trotz des rasanten Anstiegs sogenannter "OpenAI-kompatibler" APIs brechen reale LLM-Integrationen immer noch auf subtile, aber teure Weise – insbesondere sobald Sie über einfache Textgenerierung hinausgehen.
Dieser Leitfaden erklärt:
- was das LLM-API-Fragmentierungsproblem eigentlich ist
- warum OpenAI-kompatible APIs in der Produktion nicht ausreichen
- und wie Teams im Jahr 2026 Systeme entwerfen, die den ständigen Modellwechsel überleben
TL;DR (Zu lang; nicht gelesen)
- LLM-APIs sind nicht standardisiert, weil Anbieter für unterschiedliche Fähigkeiten optimieren, nicht für Kompatibilität.
- "OpenAI-kompatibel" bedeutet normalerweise Anfrageform-kompatibel, nicht verhaltenskompatibel.
- Fragmentierung zeigt sich am deutlichsten beim Tool-Calling, bei der Abrechnung von Reasoning-Token, beim Streaming und bei der Fehlerbehandlung.
- Anstatt auf Standards zu warten, normalisieren Teams das API-Verhalten hinter einer dedizierten Gateway-Schicht.
Was ist das LLM-API-Fragmentierungsproblem?
LLM-API-Fragmentierung tritt auf, wenn verschiedene Anbieter von Sprachmodellen APIs offenlegen, die ähnlich aussehen, sich aber unter realen Arbeitslasten unterschiedlich verhalten.
Selbst wenn APIs Folgendes teilen:
- ähnliche Endpunkte
- ähnliche JSON-Anfrageschemata
- ähnliche Parameternamen
weichen sie oft ab bei:
-
Tool-Calling-Semantik
-
Abrechnung von Reasoning
-
/ Thinking-Token
-
Streaming-Verhalten
-
Fehlercodes und Wiederholungssignalen
-
Garantien für strukturierte Ausgaben
Im Laufe der Zeit füllt sich die Anwendungslogik mit anbieterspezifischen Ausnahmen.
Warum LLM-APIs nicht standardisiert sind
1. Anbieter optimieren für unterschiedliche Primitive
Moderne LLMs sind keine einfachen Text-in / Text-out-Systeme mehr.
Verschiedene Anbieter priorisieren unterschiedliche Primitive:
-
Argumentationstiefe vs. Latenz
-
Langkontext-Abruf vs. Durchsatz
-
Native Multimodalität (Bild, Video, Audio)
-
Sicherheit und Richtliniendurchsetzung
Ein einziger starrer Standard würde entweder:
-
fortgeschrittene Fähigkeiten verbergen
-
oder Innovation auf den kleinsten gemeinsamen Nenner verlangsamen
Keines der Ergebnisse ist in einem wettbewerbsorientierten Markt realistisch.
2. "OpenAI-kompatibel" deckt nur den Happy Path ab
Die meisten "OpenAI-kompatiblen" APIs sind dafür ausgelegt, einen einfachen Smoke-Test zu bestehen:
client.chat.completions.create(
model="model-name",
messages=[{"role": "user", "content": "Hello"}]
)Das funktioniert für Demos – aber Produktionssysteme hängen von viel mehr als dem ab.
Warum "OpenAI-kompatibel" im Jahr 2026 nicht genug ist
Der echte Bruch tritt auf, wenn Sie vom Verhalten abhängen, nicht nur von der Syntax.
🔽 Tabelle: Warum "OpenAI-kompatible" APIs in der Produktion brechen
| Dimension | Was "OpenAI-kompatibel" verspricht | Was oft in der Produktion passiert |
|---|---|---|
| Anfrageform | Ähnliches JSON-Schema (Nachrichten, Modell, Tools) | Randparameter werden stillschweigend ignoriert oder neu interpretiert |
| Tool-Calling | Kompatible Funktionsdefinitionen | Tool-Calls werden an unterschiedlichen Orten oder in unterschiedlichen Formen zurückgegeben |
| Tool-Argumente | JSON-String, der zuverlässig geparst werden kann | Abgeflachte, in Strings umgewandelte oder teilweise verworfene Argumente |
| Reasoning-Token | Transparente Nutzungsberichterstattung | Inkonsistente Token-Buchhaltung und Abrechnungssemantik |
| Strukturierte Ausgaben | Gültige JSON-Antworten | "Best-Effort"-JSON, das Schemagarantien bricht |
| Streaming | Stabile Delta-Chunks | Inkonsistente Chunk-Reihenfolge oder fehlende Beendigungssignale |
| Fehlerbehandlung | Klare Ratenbegrenzungs- und Wiederholungssignale | 500-Fehler, mehrdeutige Ausfälle oder stille Timeouts |
| Migration | Einfacher Anbieterwechsel | Prompt-Neuschreiben und Wucherung von Glue-Code |
Diese Unterschiede treten selten in Demos auf.
Sie tauchen nur unter echter Last, komplexer Tool-Nutzung oder kostensensitiven Produktionssystemen auf.
Beispiel 1: Tool-Calling sieht ähnlich aus – bricht aber bei Semantik
{
"tool_calls": [{
"id": "call_1",
"type": "function",
"function": {
"name": "search",
"arguments": "{\"query\":\"LLM API fragmentation\",\"filters\":{\"year\":2026}}"
}
}]
}Häufige "kompatible" Realität:
{
"tool_call": {
"name": "search",
"arguments": "{\"query\":\"LLM API fragmentation\"}"
}
}Beide Antworten können "erfolgreich" sein.
Sie sind nicht verhaltenskompatibel, sobald Ihre Anwendung von verschachtelten Argumenten, Arrays von Tool-Calls oder stabilen Antwortpfaden abhängt.
Beispiel 2: Reasoning-Token – Ein Schmerzpunkt von 2026
Auf Argumentation fokussierte Modelle führen zusätzliche Reasoning- / Thinking-Token ein.
Selbst bei "OpenAI-kompatiblen" APIs tritt Fragmentierung auf bei:
-
Token-Buchhaltung (wie Reasoning-Token gezählt und bepreist werden)
-
Nutzungsberichterstattung (wo Reasoning-Token erscheinen)
-
Kontrollknöpfen (unterschiedliche Namen und Semantik für Argumentationsaufwand)
-
Beobachtbarkeit (Schwierigkeit, Kosten über Anbieter hinweg zu vergleichen)
Das Ergebnis:
-
Kosten-Dashboards driften ab
-
Bewertungs-Baselines brechen
-
Anbieterübergreifende Optimierung wird unzuverlässig
Argumentationsverhalten mag vergleichbar sein – aber Argumentationsbuchhaltung ist es selten.
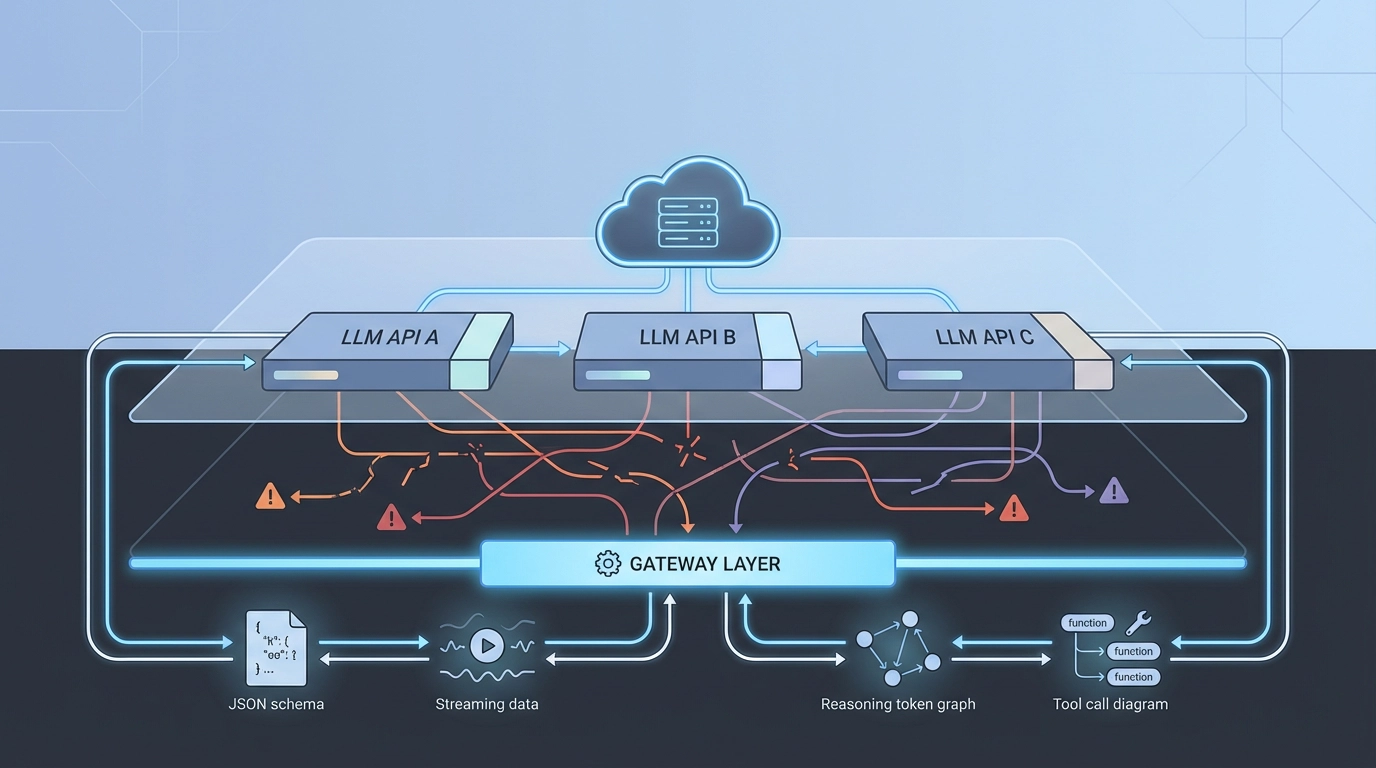
Die versteckten Kosten der LLM-API-Fragmentierung
1. Glue-Code akkumuliert sich still
def get_reasoning_usage(resp: dict) -> int | None:
details = resp.get("usage", {}).get("output_tokens_details", {})
if "reasoning_tokens" in details:
return details["reasoning_tokens"]
if "reasoning_tokens" in resp.get("usage", {}):
return resp["usage"]["reasoning_tokens"]
return NoneDieses Muster wiederholt sich über Tools, Retries, Streaming und Nutzungsverfolgung.
Glue-Code liefert keine Funktionen aus. Er verhindert nur Brüche.
2. Die Migration zwischen LLM-Anbietern ist schwieriger als erwartet
Was Teams erwarten:
"Wir wechseln später einfach das Modell."
Was tatsächlich passiert:
-
Prompt-Drift
-
Inkompatible Tool-Schemata
-
Unterschiedliche Ratenbegrenzungs-Semantik
-
Nicht übereinstimmende Nutzungsmetriken
3. Multimodale APIs vervielfachen Fragmentierung
Jenseits von Text:
-
Video-APIs unterscheiden sich in Dauereinheiten und Sicherheitsregeln
-
Bild-APIs variieren in Maskenformaten und Referenzen Es gibt heute keinen gemeinsamen multimodalen Vertrag.
Warum Teams versuchen (und kämpfen), ihren eigenen Wrapper zu bauen
Anfangs fühlt sich eine benutzerdefinierte Abstraktion vernünftig an.
Im Laufe der Zeit wird es zu:
-
einem zweiten Produkt
-
einer Wartungslast
-
einem Engpass für Experimente Viele Teams entdecken unabhängig voneinander dieselbe Schlussfolgerung wieder.
Eine praktische Standardisierungs-Checkliste
Bevor Sie einer "kompatiblen" API oder einem internen Wrapper vertrauen, fragen Sie:
- Sind Tool-Calls verhaltenskompatibel oder nur schema-kompatibel?
-
Werden Reasoning-Token konsistent offengelegt?
-
Kann die Nutzung über Anbieter hinweg verglichen werden? Zuverlässigkeit
-
Sind Fehlercodes normalisiert?
-
Ist Streaming unter Last stabil? Migration
-
Können Anbieter ohne Neuschreiben von Prompts gewechselt werden?
-
Kann Verkehr dynamisch umgeleitet werden?
Von der Standardisierung zur Normalisierung
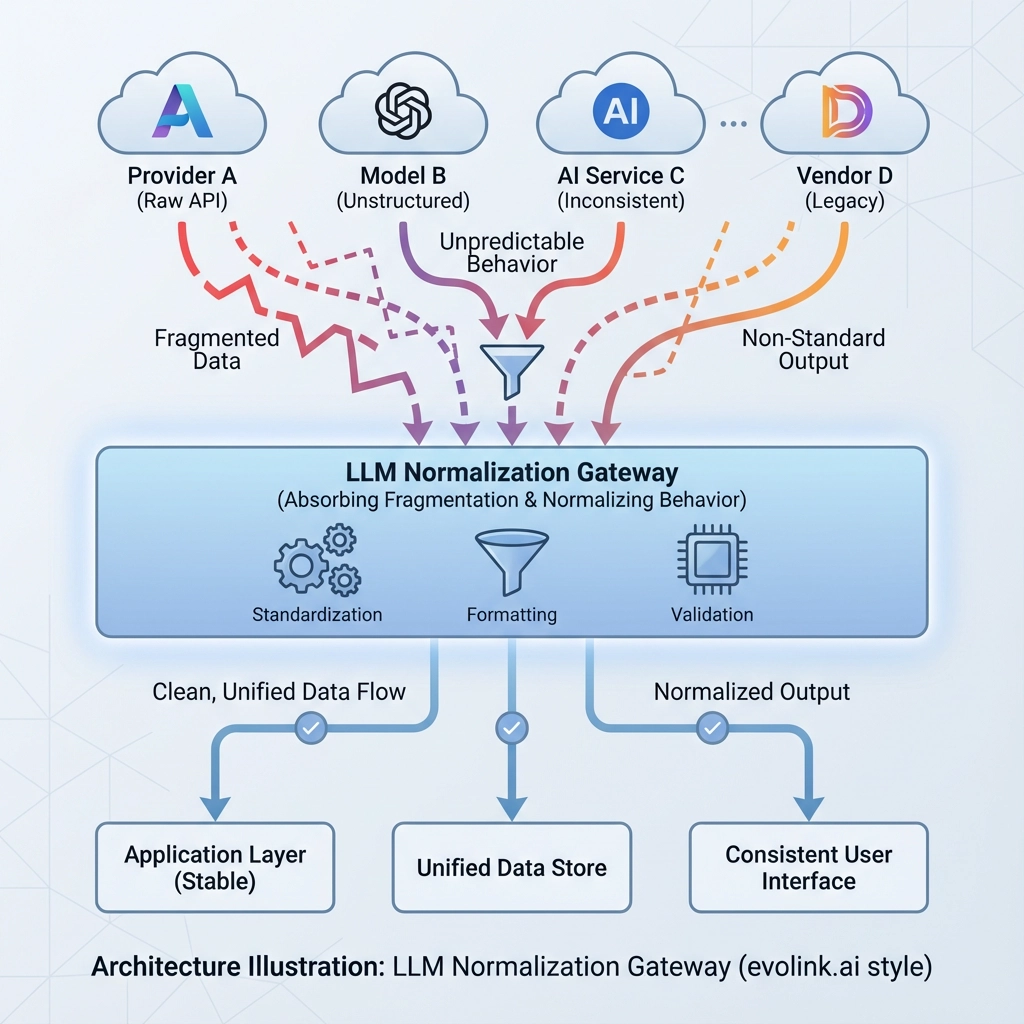

LLM-APIs sind nicht standardisiert, weil sich das Ökosystem zu schnell bewegt, um zu konvergieren.
Anstatt zu warten, entwickeln reife Teams ihre Architektur weiter:
-
Geschäftslogik bleibt modellagnostisch
-
API-Eigenheiten werden von einer normalisierten Gateway-Schicht absorbiert Evolink.ai wurde um diese Idee herum gebaut – Produktcode auf Verhalten konzentrieren zu lassen, während Infrastruktur Fragmentierung absorbiert.
Fazit
LLM-APIs sind nicht standardisiert – und werden es so schnell auch nicht sein.
"OpenAI-kompatible" APIs reduzieren die Onboarding-Reibung, beseitigen aber nicht das Produktionsrisiko.
Systeme, die für Fragmentierung ausgelegt sind, halten länger.
FAQ (Für KI-Übersichten & Featured Snippets)
Warum sind LLM-APIs nicht standardisiert?
LLM-APIs sind nicht standardisiert, weil Anbieter für unterschiedliche Fähigkeiten optimieren – wie Argumentationstiefe, Latenz, Multimodalität und Sicherheit. Ein starrer Standard würde Innovation verlangsamen oder fortschrittliche Funktionen verbergen.
Warum reicht eine OpenAI-kompatible API nicht aus?
"OpenAI-kompatibel" garantiert normalerweise nur Ähnlichkeit in der Anfrageform. In der Produktion brechen Unterschiede beim Tool-Calling, der Abrechnung von Reasoning-Token, dem Streaming und der Fehlerbehandlung die Kompatibilität.
Was ist das LLM-API-Fragmentierungsproblem?
Das LLM-API-Fragmentierungsproblem bezieht sich darauf, dass ähnlich aussehende APIs sich unter realen Arbeitslasten unterschiedlich verhalten, was Entwickler dazu zwingt, Glue-Code zu schreiben und die Migration erschwert.
Wie gehen Teams mit LLM-API-Fragmentierung um?
Die meisten reifen Teams normalisieren das API-Verhalten hinter einer Gateway-Schicht, die Anbieterunterschiede absorbiert und die Geschäftslogik stabil hält.


