
Kostenoptimierung
OpenRouter-Alternativen (2026): Ein praktischer Leitfaden zur Senkung der effektiven KI-API-Kosten (LiteLLM, Replicate, fal.ai, WaveSpeedAI, EvoLink)

Jessie
COO
22. Januar 2026
Aktualisiert am 13. Mai 2026
12 Min. Lesezeit
Suchen Sie einen umfassenderen Vergleich von OpenRouter-Alternativen? Dieser Artikel konzentriert sich speziell auf Kostenoptimierung. Für einen vollständigen Vergleich der Routing-Funktionen einschließlich Datenschutz, Observability und Deployment-Kontrolle siehe Beste OpenRouter-Alternativen 2026. Zur Fehlerbehebung bei OpenRouter-Fehlern siehe Fix OpenRouter 429 „Provider Returned Error".
Wenn Sie nach OpenRouter-Alternativen suchen, ist Ihre Absicht normalerweise nicht: „Ich möchte einen neuen Router.“
Es ist vielmehr dies:
OpenRouter ist bequem, aber bei zunehmender Nutzung fühlt es sich teuer an – und Sie möchten einen Wechsel, der die Unit Economics tatsächlich verbessert, ohne die Migration in ein komplettes Rewrite ausarten zu lassen.
Dieser Artikel vergleicht fünf Optionen, die Teams häufig evaluieren:
- LiteLLM (selbst gehostetes LLM-Gateway)
- Replicate (Modellausführung auf Rechenzeitbasis)
- fal.ai (generative Medienplattform)
- WaveSpeedAI (Workflows für visuelle Generierung)
- EvoLink.ai (einheitliches Gateway für Chat/Bild/Video mit intelligentem Routing)
Wir werden auch OpenRouter als Baseline für den Kontext verwenden.
TL;DR: Welche Alternative sollten Sie zuerst evaluieren?
- Wenn Sie Self-Hosting-Governance + maximale Kontrolle wünschen → LiteLLM
- Wenn Ihre Workloads rechen- oder auftragsbasiert sind und Sie veröffentlichte Hardware-Preise wünschen → Replicate
- Wenn Ihre Hauptausgaben bei der Bild-/Videogenerierung liegen → fal.ai oder WaveSpeedAI
- Wenn Ihr Kostenproblem durch Kanalvarianz getrieben wird und Sie Chat + Bild + Video hinter einer einzigen API vereinen möchten → EvoLink.ai
Wenn Sie EvoLink später in diesem Leitfaden direkt ausprobieren möchten:
→ EvoLink API-Key erhalten
EvoLink Smart Router ansehen
Was „OpenRouter fühlt sich teuer an“ in der Produktion tatsächlich bedeutet
Die meisten Teams spüren während des frühen Prototypings keinen Kostendruck. Die Kosten werden schmerzhaft, wenn:
- Sie echte Benutzer haben (und eine unvorhersehbare Nutzung)
- Retries auftreten (429-Fehler-/Timeout-Bursts)
- Sie multimodale Funktionen einführen (Text + Bild + Video)
- Sie beginnen, die Bruttomarge und die Unit Economics zu optimieren
Ab diesem Punkt verlassen Sie sich nicht mehr nur auf den „Token-Preis“, sondern konzentrieren sich auf die effektiven Kosten pro Ergebnis:
- Kosten pro erfolgreicher Support-Lösung
- Kosten pro Abschluss eines Agenten-Workflows
- Kosten pro Bild-Asset (einschließlich Retries und Fehlern)
- Kosten pro Kurzvideo (einschließlich Fehlern und Warteschlangenverlusten)
Die 15-Minuten-Checkliste vor dem Wechsel
| Schritt | Aktion | Ergebnis |
|---|---|---|
| 1 | Wählen Sie einen KPI: effektive Kosten pro Ergebnis | Eine einzige Kennzahl, auf die sich Ihr Team konzentrieren kann |
| 2 | Messen Sie Retry-Rate, Fehlerrate, p95-Latenz | Baseline für „Verschwendung“ + UX-Auswirkungen |
| 3 | Kategorisieren Sie Ihren Workload: nur Text vs. multimodal | Entscheidet, ob ein „LLM-Router“ ausreicht |
| 4 | Entscheiden Sie über die Toleranz: Managed vs. Self-Hosted | Entscheidet zwischen LiteLLM und Managed Tools |
| 5 | Planen Sie den Rollout: Shadow → Canary → Ramp | Verhindert riskante „Big-Bang“-Migrationen |
Der „Effective Cost Stack“ (wo das Geld verschwindet)
| Ebene | Kostentreiber | Wie es aussieht | Was zu messen ist |
|---|---|---|---|
| L1 | Nutzungskosten | Tokens / pro Ergebnis / pro Sekunde | $ pro Sitzung/Auftrag/Asset |
| L2 | Kanalvarianz | gleiche Fähigkeit, unterschiedliche effektive Preise über verschiedene Kanäle | Preisverteilung über die Routen |
| L3 | Fehlverluste | Retries, Timeouts, 429-Stürme | Retry-Rate, Fehler pro 1k Aufrufe |
| L4 | Engineering-Overhead | viele SDKs, viele Abrechnungskonten, Drift | Zeitaufwand pro Integration |
| L5 | Modality Sprawl | Text + Bild + Video über verschiedene Plattformen | Anzahl der Anbieter im kritischen Pfad |
Wenn sich OpenRouter teuer anfühlt, liegt das oft an den Ebenen L2–L5.
Tabelle 1 — Plattform-Fit-Matrix (ausgerichtet auf die Absicht „OpenRouter ist teuer“)
| Plattform | Wann ist es eine starke OpenRouter-Alternative | Typische Abrechnungsform (High-Level) | Migrationsaufwand | Zu berücksichtigende Kompromisse |
|---|---|---|---|---|
| LiteLLM | Sie wünschen Self-Hosting-Kontrolle (Budgets, Routing, Governance) und können die Infrastruktur betreiben | OSS-Gateway/Proxy + Ihre Infrastrukturkosten | Mittel–Hoch | Sie sind für den Betrieb verantwortlich: HA, Upgrades, Provider-Drift, Monitoring |
| Replicate | Ihr Workload ist rechen-/auftragsbasiert und Sie wünschen veröffentlichte Hardware-Preise | Rechenzeit / Hardware-Sekunden (variiert je nach Modell) | Mittel | Schwankungen in der Laufzeit können die Vorhersehbarkeit verringern; testen Sie mit realen Eingaben |
| fal.ai | Sie sind medienintensiv (Bild/Video/Audio) und wünschen eine breite Modellgalerie + Skalierung | Nutzungsbasierte generative Medienplattform | Mittel | Effektive Kosten hängen stark von den gewählten Modellen + dem Workflow-Design ab |
| WaveSpeedAI | Sie bauen Workflows für die visuelle Generierung (Bild/Video), Medien stehen im Vordergrund | Nutzungsbasierte Medienplattform | Mittel | Ergänzt oft einen LLM-Router, anstatt ihn zu ersetzen |
| EvoLink.ai | Sie möchten die effektiven Kosten durch intelligentes Routing über Kanäle senken und Chat + Bild + Video vereinheitlichen | Nutzungsbasiertes Gateway; routing-gesteuerte Kostenoptimierung | Niedrig–Mittel | Prüfen Sie die Eignung, falls Sie striktes Self-Hosting/On-Prem oder spezifische Compliance-Anforderungen haben |
| OpenRouter (Baseline) | Schnelles Wechseln von LLM-Modellen hinter einer einzigen API | Token-basierter LLM-Zugriff | N/A | Kann sich teuer anfühlen, wenn die effektiven Kosten steigen (Verschwendung + Overhead + Sprawl) |
Workload-Archetypen: Wählen Sie eine Alternative, die zu Ihrem Produkt passt
| Workload-Archetyp | Wofür Sie optimieren | Bestpassende Optionen | Warum |
|---|---|---|---|
| SaaS Chat / Support-Copilot | Kosten pro Sitzung, p95-Latenz, Retry-Verschwendung | LiteLLM, EvoLink | LiteLLM für Self-Hosting-Governance; EvoLink für Routing-Ökonomie + einheitlichen Stack |
| Coding-Agents / DevTools | Handling von Bursts, Orga-Budgets/Keys, Modell-Agilität | LiteLLM, EvoLink | LiteLLM für Plattform-Kontrolle; EvoLink für reibungsarmes + kostenbewusstes Routing |
| Marketing-Bilder (hohes Volumen) | Kosten pro Asset, Durchsatz, Async/Webhooks | fal.ai, WaveSpeedAI, EvoLink | fal/WaveSpeed sind medienfokussiert; EvoLink, wenn Sie eine Oberfläche für alle Modalitäten wünschen |
| Kurzvideo-Generierung | Kosten pro Video, Warteschlangenverhalten, Fehlverluste | fal.ai, WaveSpeedAI, EvoLink | Medienplattformen sind spezialisiert; EvoLink für einheitliche Multimodalität + Routing-Ökonomie |
| Forschung / Experimente | Abdeckung, schnelles Prototyping, Klarheit bei Infrastrukturpreisen | Replicate, OpenRouter | Replicate passt gut zu rechenintensiven Aufgaben; OpenRouter ist bequem für LLM-Iterationen |
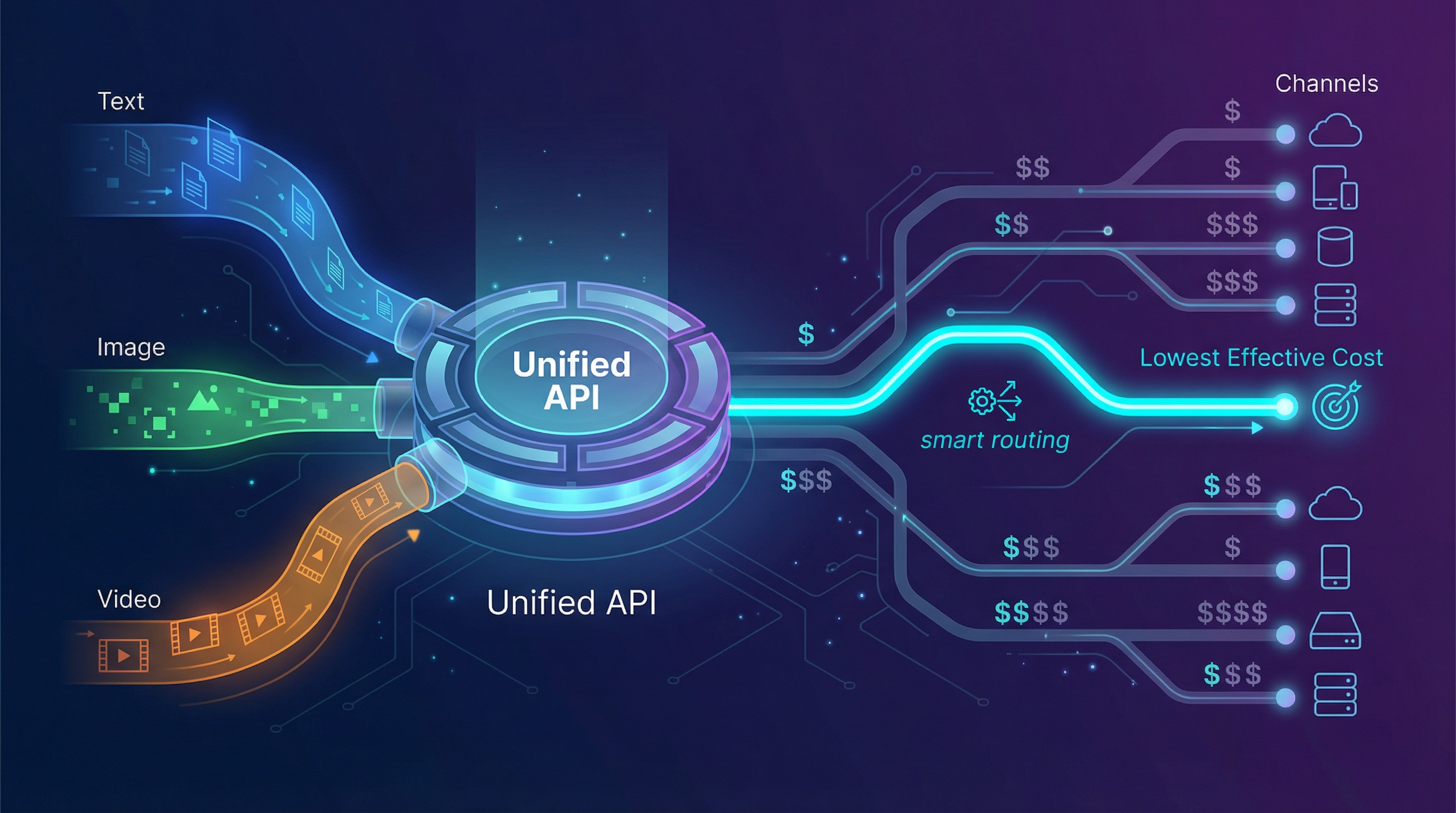
Die Alternativen: Was zu evaluieren ist (und wie)
1) LiteLLM — Kontrolle durch selbst gehostetes Gateway (OpenAI-Format)
LiteLLM wird häufig evaluiert, wenn Teams Folgendes wünschen:
- OpenAI-Format-Schnittstelle über verschiedene Anbieter hinweg
- zentrale Budgets, Rate-Limits und Governance
- Self-Hosting / On-Prem-Optionen
Wie LiteLLM normalerweise punktet
- Sie möchten die Policy-Ebene (Budgets, Auth, Routing-Regeln) innerhalb Ihrer Umgebung besitzen.
- Sie sind bereit, Anbieter-Overhead gegen Engineering-Zeit und operative Verantwortung einzutauschen.
Wo Teams überrascht werden
- Der „Router“ liegt in Ihrer Verantwortung:
- HA, Skalierung, Incident Response
- Provider-Drift (APIs ändern sich)
- Logging/Metrik-Pipelines
- Sie müssen Retries/Fallbacks aktiv verwalten, um Verschwendung zu vermeiden.
Wie man LiteLLM testet, ohne sich zu sehr zu binden
- Starten Sie in der Staging-Umgebung
- Verwenden Sie Shadow-Traffic (Anrufe duplizieren; keine Auswirkungen auf Benutzer)
- Fügen Sie frühzeitig Ausgabenlimits hinzu
- Befördern Sie den Dienst erst nach Prüfungen der Ergebnisparität zu Canary
2) Replicate — Modellausführung auf Rechenzeitbasis mit veröffentlichten Hardware-Preisen
Replicate wird oft evaluiert, wenn Ihr Workload eher „Aufträgen“ als Chat-Runden ähnelt:
- Sie führen Modellvorhersagen als Rechenaufgaben aus
- Sie wünschen transparente Hardware-Preisstufen (GPU $/Sek)
Wie Replicate normalerweise punktet
- Sehr gut geeignet für Experimente und rechenintensive Workloads
- Klarheit bei Hardware-Preisen hilft bei der Prognose (wenn die Laufzeit stabil ist)
Wo Teams überrascht werden
- Variabilität in der Laufzeit wird zu Variabilität in den Kosten.
- Die Zuverlässigkeit auf Produktionsniveau kann je nach Modell und Workload variieren.
Wie man Replicate testet
- Benchmarking mit realen Eingaben
- Aufzeichnung der Laufzeitverteilung (p50/p95/p99)
- Umrechnung in Kosten pro Ergebnis (Asset/Auftrag), nicht nur Kosten pro Sekunde
3) fal.ai — Generative Medienplattform (breiter Katalog + Skalierung)
fal.ai wird oft für medienintensive Produkte gewählt:
- Bild-/Video-/Audiogenerierung
- breite Modellgalerie
- Positionierung auf Performance und Skalierung
Wie fal.ai normalerweise punktet
- Sie wünschen eine breite Medienabdeckung unter einer Plattform.
- Sie schätzen Schnelligkeit/Skalierung bei Medien-APIs.
Wo Teams überrascht werden
- Die effektiven Kosten hängen extrem vom gewählten Modell und dem Workflow-Design ab.
- Designentscheidungen bei Async/Webhooks können die Fehlverschwendung stark beeinflussen.
Wie man fal.ai testet
- Wählen Sie 2–3 Endpunkte/Modelle aus, die zu Ihrem Produkt passen
- Testen Sie:
- Latenz bei Einzelaufrufen
- Batch-Durchsatz
- Erfassen Sie: Fehlverschwendung und Kosten pro Asset
4) WaveSpeedAI — Medienfokussierte visuelle Workflows
WaveSpeedAI wird häufig für Workflows zur Bild-/Videogenerierung evaluiert.
Wie WaveSpeedAI normalerweise punktet
- Sie wünschen eine medienfokussierte Plattform für visuelle Generierungsfeatures.
- Ihr Produkt ist mehr „Generierung von Assets“ als „Chat-Assistent“.
Wo Teams überrascht werden
- Es kann einen LLM-Router eher ergänzen als ersetzen.
- „Günstiger“ hängt von der Workflow-Struktur ab (asynchrone Aufträge, Retries etc.).
Wie man WaveSpeedAI testet
- Messen Sie die Kosten pro Asset
- Messen Sie die Verteilung der Zeit bis zum Ergebnis
- Validieren Sie die Stabilität unter Batch-Lasten
5) EvoLink.ai — Niedrigere effektive Kosten durch Routing-Ökonomie + einheitliche multimodale API
Wenn Ihre Beschwerde lautet „OpenRouter ist teuer“, lautet die Schlüsselfrage: Warum teuer?
Wenn die Antwort lautet:
- Ihre effektiven Kosten werden durch Kanalvarianz aufgebläht
- Retries und Fehler erzeugen Verschwendung
- Ihre App wird multimodal (Text + Bild + Video)
- Sie möchten nicht fünf verschiedene Anbieter-Integrationen verwalten
…dann ist EvoLink genau für diese Situation positioniert.
EvoLink positioniert sich öffentlich durch:
- Eine API für Chat, Bild und Video
- 40+ Modelle
- Intelligentes Routing, das auf Kostensenkung ausgelegt ist (behauptet „bis zu 70 % Ersparnis“)
- Zuverlässigkeitsversprechen wie 99,9 % Uptime und automatisches Failover
Wie man EvoLink evaluiert (damit Finanzen + Engineering beiden vertrauen)
- Wählen Sie 1 repräsentativen Workflow (keinen Toy-Prompt).
- Führen Sie einen 1–5 % Canary-Test für 24–48 Stunden aus.
- Vergleichen Sie effektive Kosten pro Ergebnis, Retry-Rate, p95-Latenz.
- Behalten Sie Rollback-Möglichkeiten bei.
Hier starten
- Haupt-CTA: API-Key erhalten
- Modellkatalog: EvoLink Modelle
- Implementierung: EvoLink API-Dokumentation
- Engineering-Praxis: Produktionsleitfaden für GPT Image 1.5
Wie man sich entscheidet (ohne zu viel nachzudenken): Ein einfacher Entscheidungsfluss
-
Benötigen Sie Self-Hosting / On-Prem / tiefgehende interne Governance? → Starten Sie mit LiteLLM.
-
Besteht Ihr Workload hauptsächlich aus Mediengenerierung (Bild/Video)? → Starten Sie mit fal.ai oder WaveSpeedAI.
-
Ist Ihr Workload rechen-/auftragsbasiert und achten Sie auf die Laufzeit-Ökonomie? → Starten Sie mit Replicate.
-
Wünschen Sie eine einheitliche Oberfläche für Chat/Bild/Video und ist Ihr Kostenproblem die effektive Kostenstruktur (Kanalvarianz + Verschwendung)? → Testen Sie EvoLink: Kostenlos starten
Tabelle 2 — Checkliste zur Minderung effektiver Kosten (unabhängig von der Plattform implementieren)
| Problem | Symptom | Lösung |
|---|---|---|
| Retry-Stürme | Ausgabenspitzen bei Provider-Störungen | Retry-Limits + Queueing + Backoff |
| Doppelte Abrechnung durch Benutzeraktionen | wiederholte Klicks = wiederholte Aufrufe | Idempotenz-Keys + UI-Drosselung |
| Zu häufige Nutzung teurer Pfade | gesamter Traffic nutzt Premium-Option | Routing-Policies + Budgets |
| Logging wird zum Kostentreiber | Speicherung von allem für immer | Sampling + Aufbewahrungsfristen |
| Schwierige Zuordnung von Ausgaben | „KI-Kosten“ sind ein einziger Topf | Requests nach Feature/Team/User taggen |
Migrations-Playbook: Wechseln, ohne „günstiger“ in „riskanter“ zu verwandeln
Tabelle 3 — Rollout-Plan mit geringem Risiko (Kopieren/Einfügen)
| Phase | Was Sie tun | Abgeschlossen, wenn |
|---|---|---|
| Baseline | messen der effektiven Kosten pro Ergebnis, Retry-Rate, p95-Latenz | Sie die Kostentreiber erklären können |
| Shadow | Anfragen an die neue Plattform duplizieren (keine Auswirkungen für Benutzer) | Ergebnisse vergleichbar; keine kritischen Fehler |
| Canary | 1–5 % des echten Traffics routen | KPI verbessert oder neutral; Rollback funktioniert |
| Ramp | 10 % → 25 % → 50 % → 100 % | stabil unter Spitzenlast |
| Optimieren | Tuning von Routing + Budgets | Kostenkurve verbessert sich bei steigendem Volumen |
Guardrails, die „günstiges Tool, teures Ergebnis“ verhindern
- Idempotenz für Benutzeraktionen
- Retry-Limits + Queueing
- Budget-Obergrenzen pro Key/Team/Projekt
- Fallback-Regeln basierend auf Fehlertypen (Timeout/429/5xx)
- Sampling von Logs (vermeiden Sie es, alles für immer zu loggen)
Bonus: Ein Arbeitsblatt für effektive Kosten, das Sie Ihrem Team geben können
| Metrik | Baseline (OpenRouter) | Kandidat A | Kandidat B |
|---|---|---|---|
| Effektive Kosten / Ergebnis | |||
| Retry-Rate (%) | |||
| Fehlerrate (pro 1k) | |||
| p95-Latenz (ms) | |||
| Vendor-Oberflächen im kritischen Pfad (#) | |||
| Migrationsaufwand (Personentage) |
Zusammenfassung der Empfehlungen (basierend auf der Absicht „OpenRouter fühlt sich teuer an“)
- Wenn Sie Self-Hosting-Governance + maximale Kontrolle benötigen → LiteLLM
- Wenn Ihre Workloads rechenintensive Aufträge sind und Sie veröffentlichte Hardware-Preise wünschen → Replicate
- Wenn Sie hauptsächlich Bild-/Videogenerierung betreiben → fal.ai oder WaveSpeedAI
- Wenn Sie die effektiven Kosten durch Routing-Ökonomie senken und Chat/Bild/Video hinter einer Oberfläche vereinheitlichen möchten → EvoLink.ai Probieren Sie es aus: EvoLink API-Key erhalten
Nächste Schritte (praktisch, konversionsorientiert)
- Wählen Sie Ihren ersten Kandidaten (basierend auf dem Workload-Archetyp)
- Führen Sie einen 1–5 % Canary-Test für 24–48 Stunden aus
- Vergleichen Sie: effektive Kosten pro Ergebnis + Retry-Rate + p95-Latenz
- Erweitern Sie den Traffic erst, nachdem das Rollback erfolgreich getestet wurde
- Wenn Sie EvoLink testen:
Hinweise (zur Vermeidung von Fehlern)
- Preise, Kataloge und Feature-Sets ändern sich häufig. Überprüfen Sie die Details auf den offiziellen Seiten der jeweiligen Anbieter, bevor Sie Budgetentscheidungen treffen.
- Dieser Artikel bezieht sich auf OpenRouter aufgrund der Suchintention; er steht in keiner Verbindung zu OpenRouter.


