
LLM TCO im Jahr 2026: Warum Token-Kosten nur ein Teil des wahren Preises sind

LLM TCO im Jahr 2026: Warum Token-Kosten nur ein Teil des wahren Preises sind
Die meisten Teams schätzen die Kosten von LLM-Funktionen anhand einer einzigen Metrik: Preis pro 1 Mio. Token.
Diese Metrik ist wichtig – aber nur auf dem Papier.
In realen Produktionssystemen wird die Total Cost of Ownership (TCO) von LLMs oft nicht nur durch Token-Ausgaben getrieben, sondern durch Engineering-Overhead: Integrationsarbeit, Zuverlässigkeitskorrekturen, Prompt-Wartung und Evaluierungslücken, die den KI-ROI im Laufe der Zeit leise untergraben.
Dieser Leitfaden erklärt die versteckten Kosten der LLM-Integration und bietet einen praktischen Rahmen, um zu identifizieren, wohin Geld und Engineering-Zeit tatsächlich fließen:
- Glue Code – die laufende Integrationssteuer
- Eval Debt – die Kosten der Unsicherheit
- Prompt Drift – die Migration, die niemals endet
Ein 10-Minuten LLM TCO Selbst-Audit
Bevor wir tiefer gehen, beantworten Sie diese fünf Fragen:
- Wie viele Modelle oder Anbieter unterstützt Ihr System heute (einschließlich geplanter)?
- Pflegen Sie anbieterspezifische Adapter oder bedingte Verzweigungen?
- Führen Sie bei jeder Modelländerung automatisierte Evaluierungen durch?
- Können Sie den Datenverkehr auf ein anderes Modell umleiten, ohne Prompts oder Geschäftslogik neu zu schreiben?
- Haben Sie eine einzige Ansicht von Kosten, Latenz und Fehlerraten?
Versteckte Kosten #1 — Glue Code: Die Integrationssteuer
Glue Code ist Engineering-Arbeit, die keinen nutzerorientierten Wert erzeugt, aber erforderlich ist, um Unterschiede zwischen Anbietern zu normalisieren.
Er wächst in drei vorhersehbaren Bereichen.
1) Nutzung & Kontextmanagement
Sobald mehrere Modelle involviert sind, ist die Nutzungsabrechnung nicht mehr einheitlich.
Häufige Quellen für Glue Code sind:
- Kontextfenster-Berechnung und Kürzung
- "Sichere maximale Ausgabe"-Schutzvorrichtungen
- Inkonsistente oder fehlende Nutzungsfelder
Kontextüberlauf verursacht oft Wiederholungen, partielle Ausgaben und unerwartete Ausgaben – nicht nur Fehler.
2) Zuverlässigkeit & Fehlernormalisierung
Verschiedene APIs scheitern auf grundlegend unterschiedliche Weise:
- Strukturierte API-Fehler vs. Fehler auf Transportebene
- Drosselung vs. stille Timeouts
- Partielles Streaming vs. abrupte Verbindungsabbrüche
Dies verwandelt "füge einfach Retries hinzu" in einen wachsenden Entscheidungsbaum.
# Illustratives Beispiel: anbieteragnostische Fehlernormalisierung
def should_retry(err) -> bool:
if getattr(err, "status", None) in (408, 429, 500, 502, 503, 504):
return True
if "timeout" in str(err).lower() or "connection" in str(err).lower():
return True
return FalseDieser Code hält Systeme am Leben – trägt aber nichts zur Produktdifferenzierung bei.
3) Tool Calling & Strukturierte Ausgaben
Sobald Sie sich auf Tools oder strikte JSON-Ausgaben verlassen, integrieren Sie ein Protokoll, keine Chat-API.
Selbst APIs, die ähnliche Anfrageformen akzeptieren, können sich unterscheiden in:
- wo Tool-Aufrufe in Antworten erscheinen
- wie Argumente kodiert werden
- wie streng strukturierte Ausgaben durchgesetzt werden
Dies ist eine direkte Folge der LLM-API-Fragmentierung.
Glue Code Geruchstest
Sie zahlen eine Integrationssteuer, wenn:
- Prompts je nach Anbieter verzweigen
- Streaming-Parser pro Modell unterschiedlich sind
- Adapter sich im Laufe der Zeit vervielfachen
- Observability anbieterzentriert statt featurezentriert ist
Versteckte Kosten #2 — Eval Debt: Die Kosten der Unsicherheit
Eval Debt (Evaluierungsschulden) sammelt sich an, wenn Teams Modelle bereitstellen, ohne eine automatisierte Evaluierung an reale Workflows zu binden.
Das Ergebnis ist vorhersehbar:
- Migrationen fühlen sich riskant an
- Günstigere oder schnellere Modelle bleiben ungenutzt
- Teams bleiben bei teuren Standardeinstellungen
- KI-ROI sinkt im Laufe der Zeit
Der Minimum Viable Eval Loop (MVEL)
Sie benötigen keine vollständige MLOps-Plattform, um Eval Debt zu reduzieren.
Sie benötigen eine Schleife, die eine Frage beantwortet:
Wenn wir das Modell ändern, werden die Benutzer es bemerken?
Eine praktische Baseline, die viele Teams in 1-2 Tagen implementieren können:
1) Kleine, versionierte Datensätze (50–300 Fälle)
Verwenden Sie echte Produktionsbeispiele:
- häufige Benutzerflüsse
- Randfälle
- historische Fehler
eval/
├── datasets/
│ ├── v1_core.jsonl
│ ├── v1_edges.jsonl
│ └── v1_failures.jsonl
2) Wiederholbarer Batch Runner
Ein Skript, das:
- denselben Datensatz über Modelle hinweg ausführt
- Ausgaben, Latenz und Kosten aufzeichnet
- lokal oder in CI läuft
3) Leichtgewichtiges Scoring (Regressions-fokussiert)
Verfolgen Sie mindestens:
- Formatgültigkeit
- Vorhandensein erforderlicher Felder
- Latenz- und Kostenschwellenwerte
4) Einfache Evaluierungs-Konfiguration
dataset: datasets/v1_core.jsonl
model_targets:
- primary
- candidate
metrics:
- format_validity
- required_fields
thresholds:
format_validity: 0.98
latency_p95_ms: 1200
report:
output: reports/diff.htmlAllein diese Struktur senkt das Migrationsrisiko drastisch.
Versteckte Kosten #3 — Prompt Drift: Die Migration, die niemals endet
Das häufigste Missverständnis im LLM-Engineering ist:
"Wir tauschen später einfach die Modell-ID aus."
In der Praxis driften Prompts ab, weil Modelle sich unterscheiden in:
- Formatierungsdisziplin
- Tool-Nutzungsverhalten
- Verweigerungsschwellen
- Anweisungsbefolgungsstil
Ein häufiges Fehlermuster (Anbieterunabhängig)
- Prompt erfordert strikte JSON-Ausgabe
- Modell A hält sich konsequent daran
- Modell B fügt eine kurze Erklärung oder einen Verweigerungssatz hinzu
- Downstream-Parsing schlägt fehl
- Ingenieure patchen Prompts, Parser oder beides
LLM TCO Eisberg: Woher Kosten tatsächlich kommen
- Sichtbare Kosten: Token-Preise
- Versteckte Kosten:
- Glue-Code-Wartung
- Prompt-Drift-Behebung
- Evaluierungsinfrastruktur
- Debugging, Retries und Rollbacks
Hinweis zu multimodalen Systemen (Bild & Video)
Während sich dieser Artikel auf die LLM-Integration konzentriert, gilt derselbe TCO-Rahmen noch stärker für multimodale Systeme wie Bild- und Videogenerierung.
Sobald Sie über Text hinausgehen, erweitert sich der Engineering-Overhead um asynchrone Job-Orchestrierung, Webhooks oder Polling, temporäre Asset-Speicherung, Bandbreitenkosten, Timeout-Handling und Qualitätsevaluierung für nicht-deterministische Ausgaben. In der Praxis überwiegen diese Faktoren oft die Stückpreisgestaltung – egal ob die Einheit Token, Bilder oder Videosekunden sind.
Deshalb erleben Teams, die produktionsreife Bild- oder Video-Workflows bauen, häufig höhere Glue-Code- und Evaluierungskosten als reine Textsysteme, selbst wenn die Modellpreise auf dem Papier billiger erscheinen.
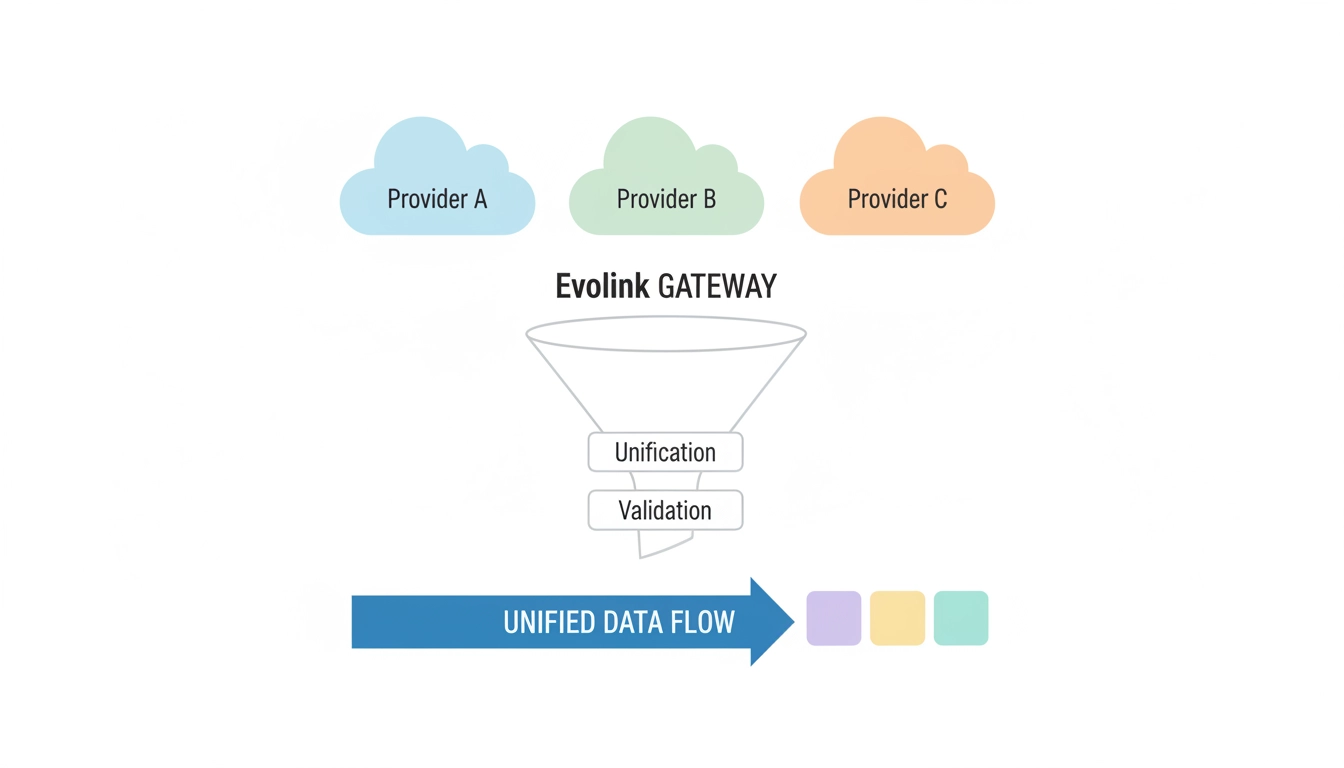
Direkte Integration vs. Normalisiertes Gateway
| Kostenbereich | Direkte Integration | Normalisiertes Gateway |
|---|---|---|
| Token-Kosten | Niedrig–variabel | Niedrig–variabel |
| Integrationsaufwand | Hoch | Niedriger |
| Wartung | Kontinuierlich | Zentralisiert |
| Migrationsgeschwindigkeit | Langsam | Schneller |
| Observability | Fragmentiert | Einheitlich |
| Engineering-Overhead | Wiederholt | Konsolidiert |
In diesem Stadium ist die wirkliche Entscheidung nicht, welches Modell verwendet werden soll – sondern wo Sie möchten, dass diese Komplexität lebt.
Führende Teams verlagern Fragmentierung, Routing und Observability aus dem Anwendungscode in eine dedizierte Gateway-Ebene.
Diese architektonische Verschiebung ist genau der Grund, warum Evolink.ai existiert.
FAQ (Suchmaschinenoptimiert)
Wie berechnet man die versteckten Kosten der LLM-Integration?
Indem man die für Integration, Evaluierung, Prompt-Wartung, Zuverlässigkeitskorrekturen und Migrationen aufgewendete Engineering-Zeit berücksichtigt – nicht nur die Token-Ausgaben.
Was ist der Engineering-Overhead von Multi-LLM-Strategien?
Er umfasst Glue Code, Prompt-Drift-Handling, Evaluierungsinfrastruktur und anbieterübergreifende Observability.
Was ist Eval Debt in LLM-Systemen?
Eval Debt ist das akkumulierte Risiko, das durch die Bereitstellung von Modellen ohne automatisierte Evaluierung verursacht wird, was zukünftige Änderungen langsamer und teurer macht.
Wie verbessert ein LLM-Gateway den KI-ROI?
Durch die Zentralisierung von Normalisierung, Routing und Observability, wodurch Teams Modelle optimieren oder wechseln können, ohne featurespezifischen Integrationscode neu zu schreiben.


