Ein Leitfaden für Entwickler zur Hugging Face Inference API
Jessie
COO
13. Oktober 2025
19 Min. Lesezeit
Die Hugging Face Inference API bietet direkten, skalierbaren Zugriff auf eine gewaltige Bibliothek von über einer Million vorsteuerbarer Modelle, ohne dass Sie die zugrunde liegende Infrastruktur verwalten müssen. Für Entwickler ist dies ein entscheidender Vorteil. Es bedeutet, dass Sie leistungsstarke KI-Funktionen – wie Textgenerierung oder Bildklassifizierung – über einfache HTTP-Anfragen in Ihre Anwendungen integrieren können und so schneller als je zuvor von der Idee zum funktionierenden KI-Feature gelangen.
Was ist die Hugging Face Inference API?
Ein Entwickler, der an einem Laptop arbeitet, mit Code und abstrakten KI-Netzwerkvisualisierungen im Hintergrund, die die Nutzung der Hugging Face Inference API repräsentieren.
Im Kern ist die Hugging Face Inference API ein Dienst, mit dem Sie auf dem Hugging Face Hub gehostete Modelle für maschinelles Lernen über unkomplizierte API-Aufrufe ausführen können. Sie abstrahiert die Komplexität des Modelldeployments wie GPU-Management, Serverkonfiguration und Skalierung vollständig. Anstatt eigene Server bereitzustellen, senden Sie Daten an den Endpunkt eines Modells und erhalten Vorhersagen zurück.
Dieser serverlose Ansatz ist für das Rapid Prototyping und viele Produktions-Workloads von unschätzbarem Wert. Es ist möglich, ein Dutzend verschiedene Modelle für eine einzige Aufgabe an einem Nachmittag zu testen, ohne eine einzige Zeile Deployment-Code zu schreiben. Die Plattform ist zu einem Eckpfeiler für modernes ML-Deployment geworden, und ihr massives Modell-Repository ist ein entscheidender Vorteil. Wenn Sie bereit sind, auf kommerzielle Modelle in Produktionsqualität umzusteigen, können Sie die von EvoLink unterstützten Modelle für ein einheitliches API-Gateway erkunden.
Um Ihnen ein klareres Bild zu vermitteln, finden Sie hier eine kurze Aufschlüsselung dessen, was die API bietet.
Die Hugging Face Inference API im Überblick
Diese Tabelle fasst die wichtigsten Funktionen und Vorteile der Nutzung der Hugging Face Inference API für verschiedene Entwicklungsanforderungen zusammen.
Funktion
Beschreibung
Hauptvorteil
Serverlose Inferenz
Führen Sie Modelle über API-Aufrufe aus, ohne Server, GPUs oder die zugrunde liegende Infrastruktur verwalten zu müssen.
Kein Infrastruktur-Overhead: Setzt Entwicklungszeit frei, um sich auf den Aufbau von Features zu konzentrieren.
Zugriff auf riesigen Model Hub
Nutzen Sie sofort eines der über 1.000.000 verfügbaren Modelle auf dem Hugging Face Hub für verschiedene Aufgaben.
Unübertroffene Flexibilität: Wechseln Sie Modelle einfach aus, um das beste für Ihren spezifischen Anwendungsfall zu finden.
Einfache HTTP-Schnittstelle
Interagieren Sie mit komplexen KI-Modellen über standardisierte, gut dokumentierte HTTP-Anfragen.
Schnelles Prototyping: Erstellen und testen Sie KI-gestützte Proof-of-Concepts in Minuten statt Wochen.
Nutzungsbasierte Preise
Sie zahlen nur für die verbrauchte Rechenzeit, was es für Experimente und kleinere Lasten kosteneffizient macht.
Kosteneffizienz: Vermeidet hohe Fixkosten für die Wartung dedizierter ML-Infrastruktur.
Letztendlich ist die API darauf ausgelegt, Sie mit so wenig Reibung wie möglich vom Konzept zum funktionalen KI-Feature zu bringen.
Hauptvorteile für Entwickler
Die API wurde eindeutig mit Blick auf die Effizienz für Entwickler entwickelt und bietet einige entscheidende Vorteile, die sie für viele Projekte zur ersten Wahl machen.
Keine Infrastrukturverwaltung: Vergessen Sie das Bereitstellen von GPUs, das Ringen mit CUDA-Treibern oder die Sorge um die Serverskalierung. Die API übernimmt die gesamte schwere Arbeit im Backend.
Riesige Modellauswahl: Mit direktem Zugriff auf den Hub können Sie sofort zwischen Modellen für Aufgaben wie Sentiment-Analyse, Textgenerierung oder Bildverarbeitung wechseln, indem Sie einfach einen Parameter in Ihrem API-Aufruf ändern.
Schnelles Prototyping: Die schiere Benutzerfreundlichkeit ermöglicht es Ihnen, an einem einzigen Nachmittag einen Proof-of-Concept für ein KI-Feature aufzubauen.
Der größte Wert der Hugging Face Inference API ist die Geschwindigkeit. Sie reduziert die Zeit und das Fachwissen, die erforderlich sind, um ein vortrainiertes Modell vom Hub in eine Live-Anwendung zu integrieren, drastisch. Für Engineering-Leiter bedeutet dies geringere Betriebskosten und eine viel schnellere Time-to-Market. Wenn Sie jedoch skalieren und auf mehrere Modelle angewiesen sind, wird die Verwaltung der Kosten und die Gewährleistung der Zuverlässigkeit über verschiedene Anbieter hinweg zu einer neuen Herausforderung.
Und wenn Sie bereit sind, über Open-Source-Modelle hinaus die Leistung kommerzieller KI-Modelle zu nutzen – Modelle wie Sora 2 für die Videogenerierung, VEO3 Fast für die schnelle Videoerstellung, Seedream 4.0 für hochwertige Bilder oder Gemini 2.5 Flash für Text- und Bildaufgaben – vervielfacht sich die Komplexität der Infrastruktur. Hier wird EvoLink unverzichtbar. Es bietet ein einheitliches API-Gateway, das speziell für Produktionsdeployments mit erstklassigen Closed-Source-Modellen entwickelt wurde. Es leitet Ihre Anfragen automatisch an den kosteneffizientesten und leistungsstärksten Anbieter weiter und bietet 20-76 % Ersparnis sowie Enterprise-Zuverlässigkeit ohne Vendor-Lock-in.
Authentifizierung und Ihr erster API-Aufruf
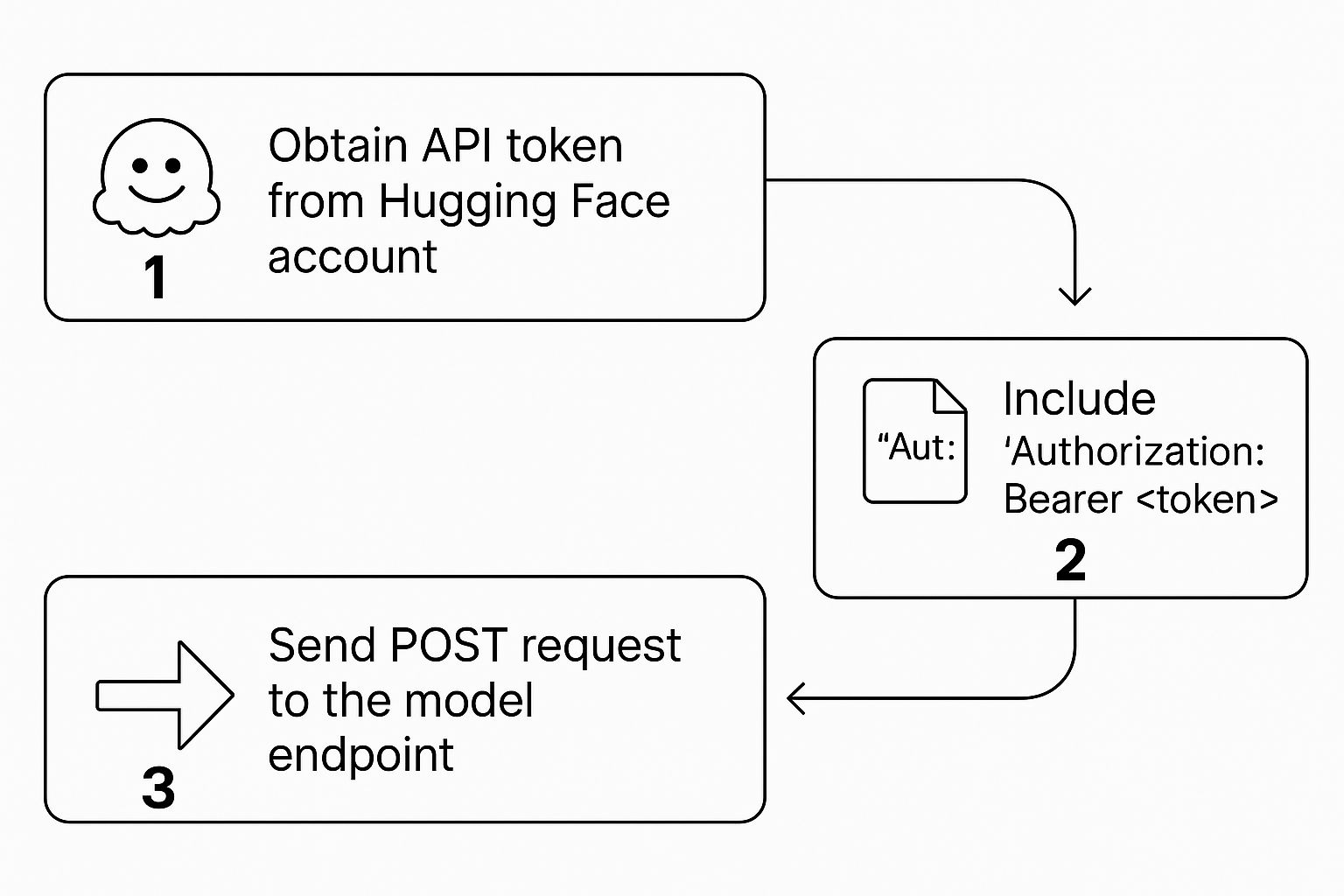
Bevor Sie die Hugging Face Inference API nutzen können, benötigen Sie ein API-Token. Dieses Token ist Ihr privater Schlüssel zu deren Modellbibliothek und kann in Ihren Hugging Face Kontoeinstellungen unter "Access Tokens" gefunden werden.
Sobald Sie Ihr Token haben, müssen Sie es im Authorization-Header jeder Anfrage angeben. Dies teilt den Servern von Hugging Face mit, dass Sie ein legitimer Benutzer mit der Erlaubnis sind, das aufgerufene Modell auszuführen. Der Prozess ist einfach, aber entscheidend: Token holen, in den Header einfügen und den Aufruf tätigen.
Infografik, die den Prozess des Abrufens eines Tokens, dessen Aufnahme in einen Autorisierungsheader und das Senden einer POST-Anfrage an einen Hugging Face Modell-Endpunkt detailliert darstellt.
Sobald Sie Ihr Token generiert haben, geht es darum, die Anfrage korrekt zu strukturieren, um sicherzustellen, dass alles reibungslos und sicher abläuft.
Ihr erster Python API-Aufruf
Lassen Sie uns eine Textklassifizierungsaufgabe mit der Python-Bibliothek requests ausführen. Die Schlüsselkomponenten sind die spezifische API-URL des Modells und ein korrekt formatierter JSON-Payload mit Ihrem Eingabetext. Der Authorization-Header muss das "Bearer"-Schema verwenden, das für moderne APIs Standard ist. Stellen Sie Ihrem Token einfach Bearer voran – vergessen Sie das Leerzeichen nicht.
Hier ist ein komplettes Python-Skript, das Sie sofort ausführen können. Ersetzen Sie einfach "IHR_API_TOKEN" durch Ihr tatsächliches Token aus Ihrem Hugging Face Konto.
import requests
import os
# Best Practice: Speichern Sie Ihr Token in einer Umgebungsvariablen
# In diesem Beispiel definieren wir es direkt, verwenden Sie jedoch os.getenv("HF_API_TOKEN") in der Produktion.
API_TOKEN = "IHR_API_TOKEN"
API_URL = "https://api-inference.huggingface.co/models/distilbert/distilbert-base-uncased-finetuned-sst-2-english"
def query_model(payload):
headers = {"Authorization": f"Bearer {API_TOKEN}"}
response = requests.post(API_URL, headers=headers, json=payload)
response.raise_for_status() # Ausnahme bei fehlerhaften Statuscodes auslösen
return response.json()
# Lassen Sie uns einen Satz klassifizieren
data_payload = {
"inputs": "I love the new features in this software, it's amazing!"
}
try:
output = query_model(data_payload)
print(output)
# Die erwartete Ausgabe könnte so aussehen: [[{'label': 'POSITIVE', 'score': 0.9998...}]]
except requests.exceptions.RequestException as e:
print(f"Ein Fehler ist aufgetreten: {e}")
Dieser Code sendet Ihren Text an ein DistilBERT-Modell, das für die Sentiment-Analyse feinabgestimmt wurde. Die API gibt eine JSON-Antwort zurück, die angibt, ob das Sentiment POSITIVE oder NEGATIVE ist, zusammen mit einem Konfidenzwert. Dieses grundlegende Muster gilt für alle Arten von Aufgaben, von der Textgenerierung bis zur Bildanalyse; nur die Payload-Struktur ändert sich. Wenn Sie zu fortgeschritteneren Modellen wie Videogeneratoren übergehen, können die API-Interaktionen natürlich komplexer werden, wie Sie in diesem detaillierten Sora 2 API-Leitfaden für 2025 sehen können.
Das Hardcoding Ihres Tokens ist für einen kurzen Test in Ordnung, stellt jedoch in einem echten Projekt ein erhebliches Sicherheitsrisiko dar. Committen Sie API-Keys niemals in ein Git-Repository. Verwenden Sie für alles, was über ein einfaches Skript hinausgeht, Umgebungsvariablen oder ein Secrets-Management-Tool, um Ihre Zugangsdaten sicher aufzubewahren.
Wenn Ihre Anforderungen wachsen, werden Sie feststellen, dass Sie mit verschiedenen Modellen, Endpunkten und Kosten jonglieren müssen. Hier wird ein einheitliches API-Gateway wie EvoLink zu einer leistungsstarken Lösung. Es vereinfacht alles, indem es einen einzigen Endpunkt bietet, der Ihre Anfragen intelligent an das leistungsfähigste und kosteneffizienteste Modell weiterleitet, was oft zu Ersparnissen von 20-76 % führt, während die hohe Zuverlässigkeit erhalten bleibt.
Einsatz der Inference API für verschiedene KI-Aufgaben
Eine abstrakte Visualisierung, die verschiedene KI-Aufgaben wie Textgenerierung, Bildklassifizierung und Sentiment-Analyse zeigt, die von einem zentralen API-Knoten ausgehen.
Nachdem die Authentifizierung erledigt ist, können wir die Flexibilität der Hugging Face Inference API erkunden. Sie können verschiedene Aufgaben ausführen, indem Sie einfach auf einen neuen Modell-Endpunkt verweisen und den JSON-Payload anpassen.
Lassen Sie uns einige gängige Beispiele mit Python durchgehen. Das Grundrezept ist immer dasselbe: Definieren Sie die API-URL des Modells, erstellen Sie einen Payload für die spezifische Aufgabe und senden Sie dann eine POST-Anfrage mit Ihrem Autorisierungsheader. Der Schlüssel liegt darin zu wissen, wie man die inputs für jedes Modell strukturiert.
Generierung von kreativem Text
Die Textgenerierung ist ein häufiger Ausgangspunkt. Mit einem Modell wie GPT-2 können Sie alles generieren, von Marketing-Texten bis hin zu Code-Snippets. Der Payload ist einfach – nur eine Textzeichenfolge, um das Modell aufzufordern. Sie können auch Parameter wie max_length hinzufügen, um die Ausgabe zu steuern.
import requests
API_URL = "https://api-inference.huggingface.co/models/gpt2"
headers = {"Authorization": "Bearer IHR_API_TOKEN"}
def query_text_generation(payload):
response = requests.post(API_URL, headers=headers, json=payload)
return response.json()
output = query_text_generation({
"inputs": "The future of AI in software development will be",
"parameters": {"max_length": 50, "temperature": 0.7}
})
print(output)
# Erwartete Ausgabe: [{'generated_text': 'The future of AI in software development will be...'}]
Die Antwort gibt ein sauberes JSON-Objekt mit dem generierten Text zurück, das sich einfach parsen und in Ihre Anwendung integrieren lässt.
Klassifizierung von Bildinhalten
Die API verarbeitet Computer-Vision-Aufgaben ebenso reibungslos. Für die Bildklassifizierung können Sie ein Modell wie den Vision Transformer (ViT) von Google verwenden. Hier senden Sie anstelle eines JSON-Payloads rohe Bilddaten. Lesen Sie dazu die Bilddatei im Binärmodus ('rb') ein und übergeben Sie diese Daten im data-Parameter Ihrer Anfrage.
import requests
API_URL = "https://api-inference.huggingface.co/models/google/vit-base-patch16-224"
headers = {"Authorization": "Bearer IHR_API_TOKEN"}
def query_image_classification(filename):
with open(filename, "rb") as f:
data = f.read()
response = requests.post(API_URL, headers=headers, data=data)
return response.json()
# Stellen Sie sicher, dass Sie eine Bilddatei (z. B. 'cat.jpg') im selben Verzeichnis haben
try:
output = query_image_classification("cat.jpg")
print(output)
# Erwartete Ausgabe könnte so aussehen: [{'score': 0.99..., 'label': 'Egyptian cat'}, {'score': 0.00..., 'label': 'tabby, tabby cat'}, ...]
except FileNotFoundError:
print("Fehler: 'cat.jpg' nicht gefunden. Bitte geben Sie einen gültigen Pfad zur Bilddatei an.")
Zero-Shot Textklassifizierung
Die Zero-Shot-Klassifizierung ist eine leistungsstarke Technik, mit der Sie Text in benutzerdefinierte Kategorien sortieren können, ohne dass ein Modell speziell darauf trainiert sein muss. Dies ist ein entscheidender Vorteil für dynamische Anwendungen, bei denen sich Kategorien weiterentwickeln können. Der Payload erfordert zwei Dinge: die inputs (Ihr Text) und ein parameters-Objekt, das eine Liste von candidate_labels enthält.
// Beispiel in JavaScript mit fetch
async function queryZeroShot(data) {
const response = await fetch(
"https://api-inference.huggingface.co/models/facebook/bart-large-mnli",
{
headers: { Authorization: "Bearer IHR_API_TOKEN" },
method: "POST",
body: JSON.stringify(data),
}
);
const result = await response.json();
return result;
}
queryZeroShot({
"inputs": "Our new feature launch was a massive success!",
"parameters": {"candidate_labels": ["marketing", "customer feedback", "technical issue"]}
}).then((response) => {
console.log(JSON.stringify(response));
// Erwartete Ausgabe: {"sequence": "...", "labels": ["customer feedback", ...], "scores": [0.98..., ...]}
});
Während der direkte Aufruf der Hugging Face API gut funktioniert, kann das Jonglieren mit mehreren Endpunkten für verschiedene Aufgaben bei steigender Skalierung komplex und kostspielig werden. Hier bietet EvoLink eine optimierte Lösung. Es bietet eine einzige, einheitliche API für den Zugriff auf eine Vielzahl von Modellen. EvoLink übernimmt das Routing im Hintergrund, was Ihnen 20-76 % an Kosten sparen kann und sicherstellt, dass Ihre Anwendung zuverlässig bleibt.
Kosten und Nutzungsklassen verstehen
Der Übergang eines Projekts vom Prototyp zur Produktion erfordert ein sorgfältiges Kostenmanagement. Die Hugging Face Inference API verwendet ein flexibles, gestaffeltes Preismodell, das Entwickler im Auge behalten müssen, wenn die Nutzung zunimmt.
Das System ist um Benutzerstufen (Free, Pro, Team, Enterprise) herum aufgebaut, von denen jede eine bestimmte Menge an monatlichen Nutzungsguthaben enthält. Kostenlose Benutzer erhalten einen kleinen Betrag, während Pro- und Team-Benutzer mehr erhalten. Sobald dieses Guthaben aufgebraucht ist, wechseln Sie zu einem Pay-per-Use-Modell, bei dem die Inferenzanfragen und die Laufzeit des Modells abgerechnet werden. Das ist zwar großartig für den Einstieg, aber die Verwaltung separater Kosten über mehrere Modelle und Anbieter hinweg kann schnell zu einer erheblichen operativen Belastung werden.
Vereinfachen Sie Ihr Kostenmanagement
Hier glänzt ein einheitlicher API-Anbieter wie EvoLink. Anstatt mit mehreren Konten und Rechnungen zu jonglieren, fungiert EvoLink als intelligentes Gateway, das alle Ihre KI-Operationen unter einem einfachen Abrechnungssystem konsolidiert.
Die Plattform leitet Ihre API-Aufrufe automatisch in Echtzeit an den effizientesten Anbieter weiter. Diese dynamische Optimierung ist es, was zu erheblichen Einsparungen führt, oft zwischen 20-76 %, ohne dass ein manuelles Eingreifen erforderlich ist. Für Engineering-Leiter bedeutet dies eine planbare Budgetierung und eine einfachere finanzielle Übersicht mit einer einzigen, klaren Rechnung und einem Dashboard, das genau zeigt, wohin Ihr Geld fließt. Dieser Ansatz erspart Ihnen das Management separater Konten bei verschiedenen Anbietern und macht es viel einfacher, Ihre KI-Features zu skalieren, ohne dass Ihr Budget außer Kontrolle gerät. Wir haben einen vollständigen Leitfaden zu diesem Thema zusammengestellt, den Sie hier lesen können: KI-API Kostenoptimierungsstrategien: 70 % Ersparnis erzielen.
Von direkten Aufrufen zum smarten Routing
Stellen Sie sich vor, Sie nutzen mehrere verschiedene Modelle – eines für die Textgenerierung, ein anderes für die Zusammenfassung und ein drittes für die Sentiment-Analyse. Normalerweise würden Sie jeden Modell-Endpunkt direkt aufrufen und die damit verbundenen Kosten jeweils separat bezahlen. EvoLink ändert diese Dynamik durch die Bereitstellung eines einzigen Endpunkts. Sie tätigen einen einzigen API-Aufruf, und das System übernimmt die Schwerstarbeit und findet das optimale Gleichgewicht zwischen Preis und Leistung für diese spezifische Anfrage. Dies spart nicht nur Geld, sondern erhöht auch die Zuverlässigkeit Ihrer Anwendung.
Optimierung für die Produktionsleistung
Ein Split-Screen-Bild, das auf der einen Seite einen traditionellen direkten API-Aufruf und auf der anderen Seite ein intelligentes Routing-System zeigt, was den Wechsel zu einer resilienteren Architektur mit EvoLink symbolisiert.
In der Produktion ist Leistung das A und O. Sich ausschließlich auf die Hugging Face Inference API zu verlassen, bedeutet, reale Probleme wie Latenzzeiten durch Kaltstarts von Modellen, die Verwaltung gleichzeitiger Anfragen und die Gewährleistung der Serviceverfügbarkeit während Spitzenlasten einzuplanen.
Ein häufiger Engpass sind synchrone API-Aufrufe, die den Hauptthread Ihrer Anwendung einfrieren können, während sie auf eine Antwort des Modells warten, was zu einer schlechten Benutzererfahrung führt. Eine klügere Strategie ist die Implementierung von asynchronen Anfragen. Dieses nicht blockierende Muster ist unerlässlich, um die Reaktionsfähigkeit in jedem System mit nennenswertem Durchsatz aufrechtzuerhalten, zumal Inferenzzeiten von Modellen stark variieren können.
Die Hugging Face Inference API wird von einem Netzwerk aus über 200 globalen Inferenzanbietern unterstützt, darunter Hardwarespezialisten wie Groq und Together AI. Dies erleichtert die Skalierung vom Prototyp zur Produktion. Während die Kosten oft angemessen sind, werden Sie dennoch auf Nutzungslimits stoßen. Pro-Abonnements bieten bis zum 20-fachen des Kontingents der kostenlosen Stufe, was für Anwendungen mit hohem Volumen entscheidend ist. Für einen tieferen Einblick hat Hugging Face einen großartigen Beitrag über die Auswahl der richtigen Open-Source-KI-Modelle und deren Leistungsmetriken veröffentlicht.
Aufbau von Resilienz über einen einzelnen Endpunkt hinaus
Selbst mit optimiertem Code schafft die Bindung Ihrer Anwendung an einen einzelnen Modell-Endpunkt einen Single Point of Failure. Wenn dieser Endpunkt ausfällt oder überlastet wird, kommt die Kernfunktionalität Ihrer App zum Erliegen. Hier wird ein einheitliches KI-Gateway wie EvoLink zu einem wesentlichen Bestandteil Ihrer Architektur. Anstatt einen Modell-Endpunkt direkt aufzurufen, tätigen Sie einen einzigen API-Aufruf an EvoLink. Die Plattform leitet Ihre Anfrage dann intelligent an den leistungsfähigsten und zuverlässigsten Anbieter weiter, der in diesem Moment verfügbar ist.
Diese Architektur bietet zwei entscheidende Vorteile für jedes Produktionssystem:
Automatisches Failover: Wenn ein primärer Anbieter langsam ist oder nicht reagiert, leitet EvoLink die Anfrage sofort an eine gesunde Alternative um und gewährleistet so die Stabilität der Anwendung.
Lastverteilung (Load Balancing): Bei Traffic-Spitzen werden Anfragen automatisch über mehrere Anbieter verteilt, was Engpässe verhindert und die Latenz niedrig hält.
Durch die Abstraktion der Anbieter-Infrastruktur bauen Sie Resilienz direkt in Ihre Anwendung ein.
Vom direkten Aufruf zum einheitlichen Gateway
Der Übergang ist denkbar einfach: Ersetzen Sie den direkten Aufruf der Hugging Face API durch den EvoLink-Endpunkt. Diese einzige Codeänderung verbessert sofort die Zuverlässigkeit und Leistung Ihrer Anwendung und erschließt gleichzeitig erhebliche Kosteneinsparungen von 20-76 %.
Hier ist ein praktischer Blick auf den Unterschied in Python:
Vorher: Ein riskanter direkter API-Aufruf
Dieser Standardansatz ist anfällig für anbieterspezifische Ausfälle.
# Vorher: Direkter API-Aufruf bei Hugging Face
# Dies erzeugt einen Single Point of Failure.
import requests
HF_API_URL = "https://api-inference.huggingface.co/models/gpt2"
HF_TOKEN = "IHR_HF_TOKEN"
def direct_hf_call(payload):
headers = {"Authorization": f"Bearer {HF_TOKEN}"}
response = requests.post(HF_API_URL, headers=headers, json=payload)
return response.json()
Nachher: Ein resilienter Aufruf über EvoLink
Ihre App ist nun durch automatisches Failover und Lastverteilung geschützt.
# Nachher: Aufruf der einheitlichen EvoLink-API (OpenAI-kompatibel)
# Ihre Anwendung ist nun durch automatisches Failover und Lastverteilung resilient.
import requests
# Der einheitliche API-Endpunkt von EvoLink (OpenAI-kompatibel)
EVOLINK_API_URL = "https://api.evolink.ai/v1"
EVOLINK_TOKEN = "IHR_EVOLINK_TOKEN"
def evolink_image_generation(prompt):
"""
Generieren Sie Bilder mit dem intelligenten Routing von EvoLink.
EvoLink leitet automatisch zum günstigsten Anbieter für Ihr gewähltes Modell weiter.
"""
headers = {"Authorization": f"Bearer {EVOLINK_TOKEN}"}
# Beispiel: Nutzung von Seedream 4.0 für storygetriebene 4K-Bildgenerierung
payload = {
'model': 'doubao-seedream-4.0', # Oder 'gpt-4o-image', 'nano-banana'
'prompt': prompt,
'size': '1024x1024'
}
response = requests.post(f"{EVOLINK_API_URL}/images/generations",
headers=headers, json=payload)
return response.json()
def evolink_video_generation(prompt):
"""
Generieren Sie Videos mit den Videomodellen von EvoLink.
"""
headers = {"Authorization": f"Bearer {EVOLINK_TOKEN}"}
# Beispiel: Nutzung von Sora 2 für ein 10-sekündiges Video mit Audio
payload = {
'model': 'sora-2', # Oder 'veo3-fast' für 8-sekündige Videos
'prompt': prompt,
'duration': 10
}
response = requests.post(f"{EVOLINK_API_URL}/videos/generations",
headers=headers, json=payload)
return response.json()
Mit dieser einfachen Änderung haben Sie Ihre Anwendung effektiv gegen anbieterspezifische Probleme gewappnet und gleichzeitig Zugriff auf Bild- und Videogenerierungsfunktionen in Produktionsqualität erhalten.
Häufige Fragen und praktische Antworten
Bei der Arbeit mit der Hugging Face Inference API werden Sie auf typische Herausforderungen stoßen. Hier sind klare Antworten auf häufig gestellte Fragen.
Wie sollte ich mit Rate-Limits umgehen?
Das Erreichen eines Rate-Limits ist ein häufiges Problem. Ihr Limit hängt von Ihrer Abonnementstufe ab, und ein Überschreiten führt dazu, dass Ihre Anwendung fehlschlägt.
Mehrere Taktiken können helfen:
Batching von Anfragen: Bündeln Sie, wo unterstützt, mehrere Eingaben in einem einzigen API-Aufruf, anstatt hunderte separate Anfragen zu senden.
Implementieren von Exponential Backoff: Wenn eine Anfrage aufgrund eines Rate-Limits fehlschlägt, bauen Sie eine Retry-Logik ein, die zwischen den Versuchen progressiv länger wartet (z. B. 1s, 2s, 4s). Dies verhindert ein Spamming der API und gibt ihr Zeit, sich zu erholen.
Für eine robustere Produktionslösung bietet ein Dienst wie EvoLink eine dauerhafte Lösung. Sein einheitliches API-Gateway verteilt Anfragen automatisch über verschiedene Endpunkte, wodurch Rate-Limit-Probleme effektiv umgangen und die Systemresilienz erhöht wird.
Kann ich meine privaten Modelle über die Inference API ausführen?
Ja, die Nutzung privater Modelle ist ein Kernfeature, insbesondere für Teams, die mit feinabgestimmten Modellen auf proprietären Daten arbeiten. Der Prozess ist identisch mit dem Aufruf eines öffentlichen Modells: Übergeben Sie Ihr API-Token im Authorization-Header. Wichtig ist dabei sicherzustellen, dass das mit dem Token verknüpfte Konto über die erforderlichen Berechtigungen für den Zugriff auf das private Modell-Repository verfügt. Ohne die entsprechenden Berechtigungen erhalten Sie einen Authentifizierungsfehler.
Was ist die Best Practice für die Verwaltung von Modellversionen?
Für Produktionsanwendungen ist dies entscheidend. Der Aufruf eines Modells nach Namen (z. B. gpt2) verwendet standardmäßig die neueste Version auf dem main-Branch. Das ist für Tests in Ordnung, kann aber in der Produktion zu Breaking Changes führen, wenn ein Modellautor ein Update veröffentlicht. Der professionelle Ansatz besteht darin, Ihre Anfragen an einen spezifischen Commit-Hash zu binden. Jedes Modell auf dem Hub hat eine Git-ähnliche Commit-Historie. Identifizieren Sie die genaue Version, die Sie getestet haben, kopieren Sie deren Commit-Hash und geben Sie diese Revision in Ihrem API-Aufruf an. Dies garantiert, dass Sie immer dieselbe Modellversion verwenden, was zu konsistenten und vorhersehbaren Ergebnissen führt.
Bereit für die Skalierung über Open-Source-Modelle hinaus?
Die Open-Source-Modelle von Hugging Face sind perfekt zum Lernen, Experimentieren und Erstellen Ihrer ersten Prototypen. Sie ermöglichen es Entwicklern, praktische Erfahrungen mit echten KI-Funktionen zu sammeln, ohne dass dazu Enterprise-Budgets oder komplexe Verträge erforderlich sind. Doch wenn Ihr Projekt reift – insbesondere wenn Sie auf einen kommerziellen Launch zugehen, Anwendungen mit direktem Benutzerkontakt verwalten oder mit Traffic auf Produktionsniveau arbeiten – werden Sie sich ganz natürlich der Leistung, Zuverlässigkeit und den spezialisierten Fähigkeiten kommerzieller Closed-Source-Modelle zuwenden, wie Sora 2 für die Videogenerierung, VEO3 Fast für die schnelle Videoerstellung, Seedream 4.0 für die 4K-Bildgenerierung und Gemini 2.5 Flash für Text- und Bildaufgaben.
Hier wird der Übergang vom Open-Source-Experiment zur KI in Produktionsqualität entscheidend. Anstatt mehrere API-Keys, Abrechnungskonten und Anbieterbeziehungen zu verwalten, ermöglicht Ihnen ein einheitliches Gateway wie EvoLink den Zugriff auf diese erstklassigen Closed-Source-Modelle über eine einzige, zuverlässige API. EvoLink vereinfacht nicht nur die Integration – es leitet Ihre Anfragen in Echtzeit intelligent an den kosteneffizientesten Anbieter für Ihr gewähltes Modell weiter und bietet eine Kostenersparnis von 20-76 % bei einer Verfügbarkeit von 99,9 %. Sie wählen das Modell, das Sie benötigen, und EvoLink übernimmt die Komplexität, den besten Anbieter zu finden, sodass Sie immer die optimale Leistung zum niedrigsten Preis erhalten.
Die Beherrschung der Hugging Face API ist eine wertvolle Fähigkeit für jeden KI-Entwickler. Aber zu wissen, wann und wie man zu einem robusteren, skalierbareren und kosteneffizienteren Produktions-Setup wechselt, unterscheidet erfolgreiche Projekte von solchen, die ins Stocken geraten. Indem Sie leistungsstarke Closed-Source-Modelle über ein einheitliches Gateway wie EvoLink nutzen, greifen Sie nicht nur auf bessere Technologie zu – Sie übernehmen eine intelligentere, resilientere Infrastruktur für die Zukunft.
Anstatt mit mehreren Rechnungen und API-Keys für verschiedene kommerzielle Modelle zu jonglieren, bietet Ihnen EvoLink eine einzige, zuverlässige API, die Sie mit den besten Closed-Source-Optionen der Top-Anbieter verbindet. Sein intelligentes Routing optimiert jeden Aufruf automatisch für niedrigste Kosten und beste Leistung, sodass Sie sich auf den Aufbau von Features konzentrieren können. Dieser Ansatz hat Teams geholfen, 20-76 % Kosteneinsparungen bei gleichzeitiger drastischer Verbesserung der Zuverlässigkeit zu erreichen.
Der beste Weg, den Unterschied zu verstehen, ist es, ihn selbst zu erleben. Besuchen Sie die EvoLink-Website und melden Sie sich für eine kostenlose Testversion an. Sie können es in Ihre Projekte integrieren und selbst sehen, wie ein einheitliches Gateway Ihnen helfen kann, sich wieder auf den Aufbau zu konzentrieren, anstatt die Infrastruktur zu verwalten.