
Hugging Face Inference API 개발자 가이드

Hugging Face Inference API란 무엇인가

핵심적으로 Hugging Face Inference API는 Hugging Face Hub에 호스팅된 머신러닝 모델을 직접적인 API 호출을 통해 실행할 수 있게 해주는 서비스입니다. GPU 관리, 서버 구성, 확장성 등 모델 배포의 복잡성을 완전히 추상화합니다. 자체 서버를 프로비저닝하는 대신, 모델의 엔드포인트에 데이터를 보내고 예측 결과를 받기만 하면 됩니다.
더 명확한 이해를 돕기 위해 API가 제공하는 주요 기능을 간략히 정리해 보았습니다.
Hugging Face Inference API 한눈에 보기
이 표는 다양한 개발 요구 사항에 대해 Hugging Face Inference API를 사용할 때의 주요 기능과 이점을 요약합니다.
| 기능 | 설명 | 주요 이점 |
|---|---|---|
| 서버리스 추론 | 서버, GPU 또는 기본 인프라 관리 없이 API 호출을 통해 모델을 실행합니다. | 인프라 오버헤드 제로: 기능 구축에 엔지니어링 시간을 집중할 수 있습니다. |
| 방대한 모델 허브 액세스 | Hub에서 제공되는 1,000,000개 이상의 모델을 다양한 작업에 즉시 사용 가능합니다. | 타의 추종을 불허하는 유연성: 특정 사례에 가장 적합한 모델을 쉽게 찾아 교체할 수 있습니다. |
| 간단한 HTTP 인터페이스 | 표준적이고 문서화가 잘 된 HTTP 요청을 사용하여 복잡한 AI 모델과 상호 작용합니다. | 신속한 프로토타이핑: 몇 주가 아닌 몇 분 만에 AI 기반 개념 증명을 구축하고 테스트합니다. |
| 사용량 기반 과금 정책 | 사용한 컴퓨팅 시간에 대해서만 비용을 지불하므로 실험 및 소규모 워크로드에 비용 효율적입니다. | 비용 효율성: 전용 ML 인프라 유지에 따른 높은 고정 비용을 피할 수 있습니다. |
궁극적으로 API는 최소한의 마찰로 개념에서 기능적인 AI 구현까지 이동할 수 있도록 설계되었습니다.
개발자를 위한 핵심 이점
이 API는 분명히 개발자 효율성을 염두에 두고 구축되었으며, 많은 프로젝트에서 선택받는 몇 가지 핵심적인 이점을 제공합니다.
- 인프라 관리 제로: GPU 프로비저닝이나 CUDA 드라이버와의 씨름, 서버 확장성 문제를 잊으세요. API가 모든 백엔드 고된 작업들을 처리합니다.
- 거대한 모델 선택 폭: Hub에 직접 액세스하여 감정 분석, 텍스트 생성 또는 이미지 처리와 같은 작업에 맞춰 API 호출의 파라미터만 변경함으로써 즉시 모델을 전환할 수 있습니다.
- 빠른 프로토타이핑: 사용 편의성 덕분에 단 하루 오후 만에 AI 기능의 개념 증명을 구축할 수 있습니다.
인증 및 첫 번째 API 호출
Authorization 헤더에 이를 포함해야 합니다. 이는 Hugging Face 서버에 호출하려는 모델을 실행할 권한이 있는 정당한 사용자임을 알리는 역할을 합니다. 프로세스는 토큰을 얻고, 헤더에 넣고, 호출을 수행하는 간단하지만 중요한 3단계로 이루어집니다.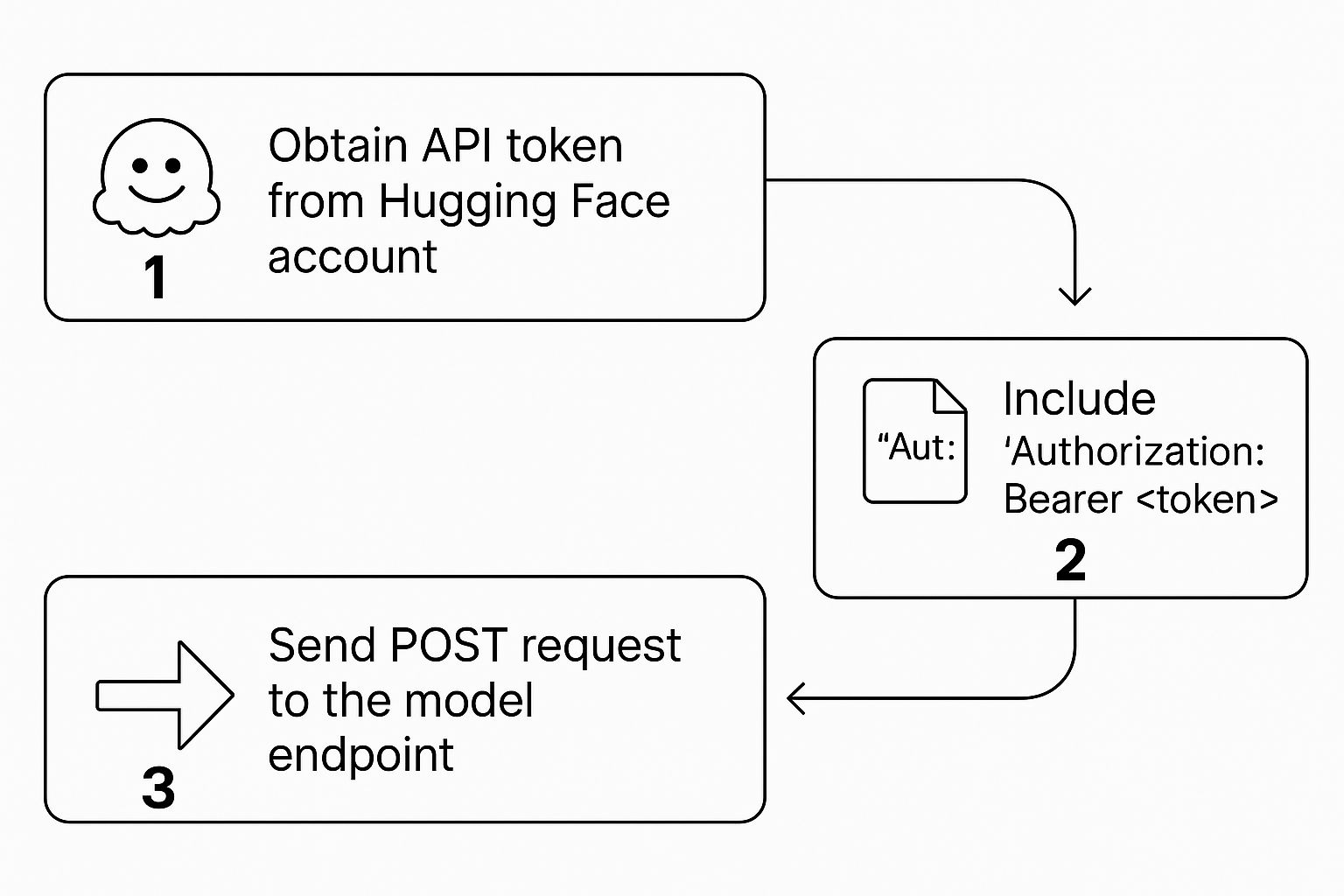
토큰을 생성했다면, 이제 모든 것이 원활하고 안전하게 실행되도록 요청을 적절하게 구조화하기만 하면 됩니다.
첫 번째 Python API 호출
requests 라이브러리를 사용하여 텍스트 분류 작업을 실행해 보겠습니다. 핵심 구성 요소는 모델의 특정 API URL과 입력 텍스트가 포함된 올바른 형식의 JSON 페이로드입니다. Authorization 헤더는 현대적인 API의 표준인 "Bearer" 스키마를 사용해야 합니다. 토큰 앞에 Bearer 를 붙이기만 하면 됩니다(공백을 잊지 마세요)."YOUR_API_TOKEN" 부분을 실제 Hugging Face 계정의 토큰으로 바꾸세요.import requests
import os
# 베스트 프랙티스: 토큰을 환경 변수에 저장하세요.
# 이 예시에서는 직접 정의하지만, 프로덕션에서는 os.getenv("HF_API_TOKEN")을 사용하세요.
API_TOKEN = "YOUR_API_TOKEN"
API_URL = "https://api-inference.huggingface.co/models/distilbert/distilbert-base-uncased-finetuned-sst-2-english"
def query_model(payload):
headers = {"Authorization": f"Bearer {API_TOKEN}"}
response = requests.post(API_URL, headers=headers, json=payload)
response.raise_for_status() # 잘못된 상태 코드에 대해 예외 발생
return response.json()
# 문장을 분류해 봅시다.
data_payload = {
"inputs": "I love the new features in this software, it's amazing!"
}
try:
output = query_model(data_payload)
print(output)
# 예상 출력 예시: [[{'label': 'POSITIVE', 'score': 0.9998...}]]
except requests.exceptions.RequestException as e:
print(f"오류가 발생했습니다: {e}")POSITIVE인지 NEGATIVE인지를 나타내는 JSON 응답과 신뢰도 점수를 반환합니다. 이 기본적인 패턴은 텍스트 생성에서 이미지 분석에 이르기까지 모든 종류의 작업에 적용되며, 페이로드 구조만 바뀝니다. 물론 비디오 생성기와 같은 더 고급 모델로 넘어가면 이 상세한 2025년 Sora 2 API 가이드에서 볼 수 있듯이 API 상호 작용이 더 복잡해질 수 있습니다.빠른 테스트를 위해 토큰을 하드코딩하는 것은 괜찮지만, 실제 프로젝트에서는 중대한 보안 위험이 됩니다. API 키를 Git 저장소에 절대 커밋하지 마세요. 간단한 스크립트 이상의 작업을 할 때는 환경 변수나 비밀 관리 도구를 사용하여 자격 증명을 안전하게 보관하세요.
여러 AI 작업에 추론 API 할용하기

inputs 구조를 아는 것입니다.창의적인 텍스트 생성
max_length와 같은 파라미터를 추가할 수도 있습니다.import requests
API_URL = "https://api-inference.huggingface.co/models/gpt2"
headers = {"Authorization": "Bearer YOUR_API_TOKEN"}
def query_text_generation(payload):
response = requests.post(API_URL, headers=headers, json=payload)
return response.json()
output = query_text_generation({
"inputs": "The future of AI in software development will be",
"parameters": {"max_length": 50, "temperature": 0.7}
})
print(output)
# 예상 출력: [{'generated_text': 'The future of AI in software development will be...'}]응답은 생성된 텍스트가 포함된 깔끔한 JSON 객체를 반환하므로 구문 분석하여 애플리케이션에 통합하기 쉽습니다.
이미지 콘텐츠 분류
'rb')로 읽고 해당 데이터를 요청의 data 파라미터에 전달합니다.import requests
API_URL = "https://api-inference.huggingface.co/models/google/vit-base-patch16-224"
headers = {"Authorization": "Bearer YOUR_API_TOKEN"}
def query_image_classification(filename):
with open(filename, "rb") as f:
data = f.read()
response = requests.post(API_URL, headers=headers, data=data)
return response.json()
# 동일한 디렉토리에 이미지 파일(예: 'cat.jpg')이 있는지 확인하세요.
try:
output = query_image_classification("cat.jpg")
print(output)
# 예상 출력 예시: [{'score': 0.99..., 'label': 'Egyptian cat'}, {'score': 0.00..., 'label': 'tabby, tabby cat'}, ...]
except FileNotFoundError:
print("오류: 'cat.jpg'를 찾을 수 없습니다. 유효한 이미지 파일 경로를 제공하세요.")제로샷 (Zero-Shot) 텍스트 분류
inputs(텍스트)와 candidate_labels 리스트가 포함된 parameters 객체가 필요합니다.// fetch를 사용한 JavaScript 예시
async function queryZeroShot(data) {
const response = await fetch(
"https://api-inference.huggingface.co/models/facebook/bart-large-mnli",
{
headers: { Authorization: "Bearer YOUR_API_TOKEN" },
method: "POST",
body: JSON.stringify(data),
}
);
const result = await response.json();
return result;
}
queryZeroShot({
"inputs": "Our new feature launch was a massive success!",
"parameters": {"candidate_labels": ["marketing", "customer feedback", "technical issue"]}
}).then((response) => {
console.log(JSON.stringify(response));
// 예상 출력: {"sequence": "...", "labels": ["customer feedback", ...], "scores": [0.98..., ...]}
});비용 및 사용량 계층 이해하기
시스템은 사용자 계층(Free, Pro, Team, Enterprise)을 중심으로 구축되며, 각 계층에는 월간 사용 크레딧이 할당됩니다. 무료 사용자는 적은 양을 받고, Pro와 Team 사용자는 더 많은 양을 받습니다. 이 크레딧이 모두 소진되면 추론 요청 및 모델 실행 시간에 대해 비용이 청구되는 사용량 기반 과금(pay-as-you-go) 모델로 전환됩니다. 이는 시작하기에는 좋지만, 여러 모델과 제공업체에 걸쳐 별도의 비용을 관리하는 것은 곧 중대한 운영상의 부담으로 이어질 수 있습니다.
비용 관리 단순화
직접 호출에서 스마트 라우팅으로
프로덕션 성능 최적화

단일 엔드포인트를 넘어선 탄력성 구축
이 아키텍처는 모든 프로덕션 시스템에 두 가지 중요한 이점을 제공합니다.
- 자동 장애 조치 (Failover): 주 제공업체가 느리거나 응답이 없으면 EvoLink가 즉시 요청을 정상적인 대안으로 다시 라우팅하여 애플리케이션 안정성을 확보합니다.
- 로드 밸런싱: 트래픽 급증 시 요청이 여러 제공업체에 자동으로 분산되어 병목 현상을 방지하고 지연 시간을 낮게 유지합니다.
제공업체 인프라를 추상화함으로써 애플리케이션에 탄력성을 직접 구축하게 됩니다.
직접 호출에서 통합 게이트웨이로
Python에서의 차이점을 실제로 확인해 보세요.
# 변경 전: Hugging Face에 직접 API 호출
# 이는 단일 장애점을 생성합니다.
import requests
HF_API_URL = "https://api-inference.huggingface.co/models/gpt2"
HF_TOKEN = "YOUR_HF_TOKEN"
def direct_hf_call(payload):
headers = {"Authorization": f"Bearer {HF_TOKEN}"}
response = requests.post(HF_API_URL, headers=headers, json=payload)
return response.json()# 변경 후: 통합 EvoLink API(OpenAI 호환) 호출
# 이제 자동 장애 조치와 로드 밸런싱을 통해 애플리케이션이 탄력적이 됩니다.
import requests
# EvoLink의 통합 API 엔드포인트(OpenAI 호환)
EVOLINK_API_URL = "https://api.evolink.ai/v1"
EVOLINK_TOKEN = "YOUR_EVOLINK_TOKEN"
def evolink_image_generation(prompt):
"""
EvoLink의 지능형 라우팅을 사용하여 이미지를 생성합니다.
EvoLink는 선택한 모델에 대해 가장 저렴한 제공업체로 자동 라우팅합니다.
"""
headers = {"Authorization": f"Bearer {EVOLINK_TOKEN}"}
# 예시: Seedream 4.0을 사용하여 4K 이미지 생성
payload = {
'model': 'doubao-seedream-4.0', # 또는 'gpt-4o-image', 'nano-banana'
'prompt': prompt,
'size': '1024x1024'
}
response = requests.post(f"{EVOLINK_API_URL}/images/generations",
headers=headers, json=payload)
return response.json()
def evolink_video_generation(prompt):
"""
EvoLink의 영상 모델을 사용하여 영상을 생성합니다.
"""
headers = {"Authorization": f"Bearer {EVOLINK_TOKEN}"}
# 예시: Sora 2를 사용하여 오디오가 포함된 10초 영상 생성
payload = {
'model': 'sora-2', # 또는 8초 영상을 위한 'veo3-fast'
'prompt': prompt,
'duration': 10
}
response = requests.post(f"{EVOLINK_API_URL}/videos/generations",
headers=headers, json=payload)
return response.json()이 간단한 변경만으로 애플리케이션을 제공업체별 문제로부터 보호하는 동시에 프로덕션급 이미지 및 비디오 생성 기능을 활용할 수 있게 됩니다.
자주 묻는 질문 및 실용적 답변
속도 제한(Rate Limits)에는 어떻게 대처해야 합니까?
속도 제한에 도달하는 것은 흔한 문제입니다. 제한은 구독 계층에 따라 다르며 이를 초과하면 애플리케이션이 실패합니다.
다음과 같은 전략이 도움이 될 수 있습니다.
- 리퀘스트 배치 처리: 지원되는 경우 수백 개의 개별 요청을 보내는 대신 여러 입력을 하나의 API 호출로 묶습니다.
- 지수 백오프(Exponential Backoff) 구현: 속도 제한으로 요청이 실패할 경우 재시도 사이의 대기 시간을 점진적으로 늘리는(예: 1초, 2초, 4초) 로직을 구축합니다. 이는 API에 무리한 부하를 주는 것을 방지하고 복구할 시간을 줍니다.
추론 API에서 비공개 모델을 실행할 수 있나요?
Authorization 헤더에 API 토큰을 전달하세요. 중요한 점은 토큰과 연결된 계정이 해당 비공개 모델 저장소에 액세스할 수 있는 권한이 있는지 확인하는 것입니다. 권한이 없으면 인증 오류가 발생합니다.모델 버전 관리의 베스트 프랙티스는 무엇입니까?
gpt2)으로만 호출하면 기본적으로 main 브랜치의 최신 버전이 사용됩니다. 이는 테스트에는 문제가 없지만 모델 작성자가 업데이트를 푸시하면 프로덕션에서 중대한 변경 사항이 발생할 수 있습니다. 전문적인 접근 방식은 요청을 특정 커밋 해시(commit hash)에 고정하는 것입니다. 허브의 모든 모델에는 Git과 유사한 커밋 이력이 있습니다. 테스트한 정확한 버전을 식별하고 해당 커밋 해시를 가져와 API 호출에 해당 리비전을 포함하세요. 이를 통해 항상 동일한 모델 버전을 사용하도록 보장하여 일관되고 예측 가능한 결과를 얻을 수 있습니다.오픈 소스 모델을 넘어 확장할 준비가 되셨나요?
Hugging Face API를 숙달하는 것은 AI 개발자에게 가치 있는 기술입니다. 하지만 언제 그리고 어떻게 더 견고하고 확장이 가능하며 비용 효율적인 프로덕션 설정으로 ‘졸업’해야 하는지 아는 것이 성공하는 프로젝트와 멈춰 서는 프로젝트의 차이를 만듭니다. EvoLink와 같은 통합 게이트웨이를 통해 강력한 폐쇄형 모델을 활용함으로써 당신은 단순히 더 나은 기술을 사용하는 것 이상으로 미래를 위한 스마트하고 탄력적인 인프라를 구축하게 됩니다.


