
Warum Multi-Modell-KI-Apps eine einheitliche API-Schicht brauchen
TL;DR
Multi-Modell-KI-Apps werden zum Standard. Ein Produkt kann ein Modell für Chat einsetzen, ein anderes für Programmierunterstützung, ein weiteres für strukturierte Datenextraktion und separate Bild- oder Videomodelle für Medien-Workflows.
Die eigentliche Herausforderung liegt nicht allein darin, mehr APIs anzubinden. Die Herausforderung besteht darin, Modellauswahl, Nutzungsverfolgung, Abrechnung, Kostenrichtlinien, Fallback-Verhalten und Produktionsbetrieb unter Kontrolle zu halten, während sich der Modell-Mix verändert.
Eine einheitliche API-Schicht gibt Teams einen zentralen Kontrollpunkt zwischen Anwendungscode und den unterstützten KI-Modellen. Sie macht nicht alle Modelle gleich und ersetzt auch nicht die Notwendigkeit einer Evaluierung. Ihr Wert ist architektonischer Natur: Sie bietet Produkt- und Infrastrukturteams eine stabile Stelle, um Modellzugang, Wechsel, Routing, Transparenz und Betriebsrichtlinien zu verwalten.
Die meisten Teams führen eine einheitliche API nicht ein, weil sie weniger Endpunkte wollen. Sie führen sie ein, weil Multi-Modell-Anwendungen irgendwann eine Steuerungsschicht brauchen.
Sobald eine App von mehreren Modellfamilien abhängt, verlagern sich die schwierigen Fragen von „Können wir dieses Modell aufrufen?" zu „Können wir Modellauswahl, Nutzung, Kosten, Fallback und Zuverlässigkeit steuern, ohne den Produktcode jedes Mal umzuschreiben, wenn sich der Modell-Stack ändert?"
Multi-Modell-Apps werden zum Standard
Frühe KI-Produkte begannen häufig mit einem einzigen Modell und einem einzigen Anbieter. Das war sinnvoll, solange die Produktoberfläche überschaubar blieb: eine Chat-Box, ein Zusammenfassungstool, ein Support-Assistent oder ein einfacher Content-Generator.
Moderne KI-Apps sind anders. Ein einzelnes Produkt kann umfassen:
- ein schnelles Modell für Klassifikation oder Textumschreibung
- ein leistungsfähigeres Reasoning-Modell für komplexe Nutzerfragen
- ein Coding-Modell für Entwickler-Workflows
- ein Long-Context-Modell für Dokumentenanalyse
- ein Bildmodell für Asset-Erstellung oder -Bearbeitung
- ein Videomodell für kreative Produktion
- einen Fallback-Pfad, wenn ein Anbieter langsam, nicht verfügbar oder für eine bestimmte Aufgabe zu teuer ist
Dieser Wandel verändert die Architektur grundlegend. Modellauswahl ist keine einmalige Integrationsentscheidung mehr, sondern wird zu einer laufenden Betriebsentscheidung, die sich nach Feature, Nutzersegment, Workload-Typ, Latenzanforderung und Budget richten kann.
Für Teams, die Agenten entwickeln, ist dieser Druck noch stärker. Ein Agent-Workflow kann Intent klassifizieren, Kontext abrufen, Schritte planen, Tools aufrufen, Ergebnisse zusammenfassen und eine finale Antwort generieren. Nicht jeder Schritt benötigt dasselbe Modell. Wenn jede Modellentscheidung fest im Anwendungscode verankert ist, wird das Produkt schwerer weiterzuentwickeln.
Das Problem sind nicht einfach nur mehrere APIs
Es liegt nahe, das Problem als „Wir müssen OpenAI, Anthropic, Google und vielleicht noch ein paar Bild- oder Video-Provider integrieren" zu beschreiben. Das ist aber nur die sichtbare Oberfläche.
Das tieferliegende Problem ist operativer Drift.
Jeder Anbieter kann sich unterscheiden bei:
- Authentifizierung und Kontoeinrichtung
- Modell-Identifikatoren
- Request- und Response-Format
- Streaming-Verhalten
- Rate Limits und Retry-Signalen
- Nutzungsberichten
- Preiseinheiten
- Fehlersemantik
- unterstützten Modalitäten und Parametern
- Release-Kadenz und Deprecation-Verhalten
Selbst wenn zwei Anbieter einen OpenAI-kompatiblen Endpunkt bereitstellen, müssen Produktionssysteme weiterhin modellspezifisches Verhalten berücksichtigen. OpenAI-Kompatibilität reduziert oft den Onboarding-Aufwand, sollte aber nicht als vollständiger operativer Vertrag betrachtet werden.
Bei Architekturentscheidungen lautet die Frage nicht nur „Können wir einen Request senden?" Die bessere Frage ist:
Kann die Anwendung Modelle wechseln, Nutzung verfolgen, Kosten kontrollieren, Ausfälle handhaben und zuverlässig betrieben werden, ohne anbieterspezifische Logik über die gesamte Codebasis zu verteilen?
Genau hier beginnt eine einheitliche API-Schicht relevant zu werden.
Häufiger Fehler: die einheitliche API nur als Integrationsabkürzung betrachten
Ein häufiger Fehler besteht darin, eine einheitliche API nur danach zu bewerten, wie viele Anbieter sie unterstützt. Das verfehlt die eigentliche Architekturfrage.
Die entscheidende Frage ist, ob die API-Schicht Ihrem Team eine stabile Stelle bietet, um Modellauswahl, Nutzungstransparenz, Kostenrichtlinien, Fallback-Verhalten und Produktionsbetrieb zu verwalten.
Wenn die Schicht lediglich Provider-URLs verbirgt, aber weder Kontrolle noch Transparenz oder betriebliche Konsistenz verbessert, reduziert sie zwar den Integrationsaufwand – löst aber nicht das schwierigere Multi-Modell-Problem.
Eine einheitliche API-Schicht schafft einen zentralen Kontrollpunkt
Eine einheitliche API-Schicht sitzt zwischen der Anwendung und den zugrunde liegenden Modell-Providern oder Modellrouten. Der Anwendungscode kommuniziert mit der einheitlichen Schicht. Die Schicht übernimmt die gemeinsamen Belange, die nicht in jedem Feature-Team dupliziert werden sollten.
In der einfachsten Version bietet diese Schicht:
- eine Basis-URL
- ein einheitliches Authentifizierungsmuster
- eine zentrale Stelle zur Auswahl unterstützter Modelle
- eine einzige Nutzungs- und Abrechnungsoberfläche
- eine Stelle, um Routing, Fallback oder Richtlinien später einzuführen
In einer ausgereifteren Version kann sie Teil einer umfassenderen KI-Bereitstellungsschicht werden: Modellzugang, Routing-Regeln für unterstützte LLM-Anfragen, Nutzungstransparenz, Kostenkontrollen, Fallback-Planung und Produktionsbetrieb sind um denselben API-Einstiegspunkt gruppiert.
Das bedeutet nicht, dass alle Modelle austauschbar werden. Eine einheitliche API-Schicht sollte wichtige Unterschiede bei Qualität, Latenz, Modalität, Kontextfenster, Tool-Verhalten oder Preisgestaltung nicht verschleiern. Gute Architektur hält diese Unterschiede sichtbar genug für die Evaluierung und verhindert gleichzeitig, dass sie überall im Anwendungscode auftauchen.
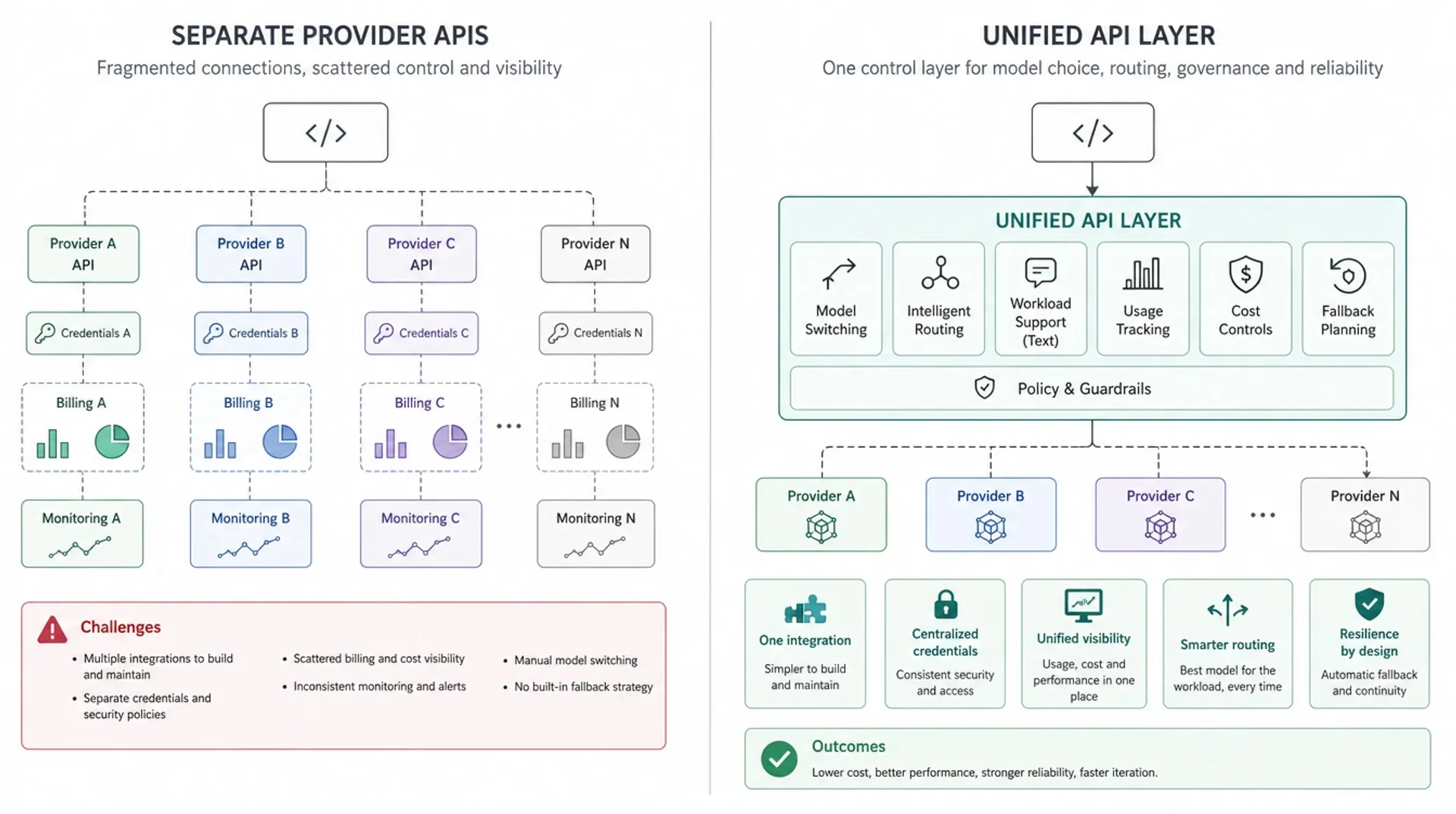
| Dimension | Separate Provider-APIs | Einheitliche API-Schicht |
|---|---|---|
| Integration | Jeder Anbieter erfordert separates Setup, Credentials, SDK-Auswahl und Wartung | Eine Integrationsoberfläche für unterstützte Modelle |
| Modellwechsel | Erfordert oft Codeänderungen, neue SDK-Pfade oder anbieterspezifische Adapter | Wird in der Regel zu einer Modell- oder Routenauswahl-Entscheidung |
| Nutzungsverfolgung | Nutzungsdaten sind über Anbieter und interne Logs verstreut | Nutzung kann in einer einheitlichen Berichtsoberfläche normalisiert werden |
| Kostenkontrolle | Teams vergleichen Ausgaben über verschiedene Abrechnungsportale und Preiseinheiten | Kostenrichtlinien können näher an der API-Schicht verwaltet werden |
| Fallback | Jeder Service implementiert möglicherweise eigene Retry- oder Backup-Logik | Fallback-Planung kann dort zentralisiert werden, wo es sinnvoll ist |
| Betrieb | Incidents, Limits und Modelländerungen verteilen sich über den Produktcode | Betriebskontrollen liegen näher an der Modell-Bereitstellungsschicht |
Was eine einheitliche API-Schicht ermöglicht
Modellwechsel ohne Komplettumbau der Anwendung
Der erste Vorteil liegt auf der Hand: Modellwechsel werden weniger invasiv.
Ohne einheitliche Schicht kann der Wechsel von einem Anbieter oder einer Modellfamilie zu einer anderen neue Credentials, SDK-Änderungen, Request-Mapping, Response-Parsing, Änderungen an der Nutzungsverfolgung und neue operative Runbooks erfordern.
Mit einer einheitlichen API-Schicht kann die Anwendung einen stabileren Integrationsvertrag beibehalten, während sich die Modellwahl dahinter ändert. Das heißt nicht, dass die Ausgabequalität identisch sein wird. Es bedeutet, dass der Integrationspfad weniger wahrscheinlich zum Blocker wird.
Beispiel:
- Ein Support-Workflow beginnt mit einem ausgewogenen Modell.
- Später wechselt die Massenklassifikation zu einem günstigeren oder schnelleren Modell.
- Komplexe Eskalationsfälle werden an ein leistungsfähigeres Reasoning-Modell weitergeleitet.
- Die Anwendung muss nicht bei jeder Änderung des Modell-Mix ihre gesamte KI-Integration neu aufbauen.
Der geschäftliche Mehrwert liegt nicht im „Modellwechsel um des Wechsels willen". Der Wert liegt darin, die Kosten der Anpassung zu senken, wenn sich Modelle, Preise und Workload-Anforderungen ändern.
Routing basierend auf Workload-Anforderungen
Multi-Modell-Apps enthalten oft gemischte LLM-Workloads. Eine kurze Formatierungsaufgabe, eine Long-Context-Analyse und ein planungsintensiver Agent-Schritt benötigen nicht dasselbe Modellprofil.
Eine einheitliche API-Schicht bietet Teams eine natürliche Stelle, um Routing-Logik für unterstützte Text-Workloads einzuführen:
- einfache Aufgaben an latenz- oder kostengünstigere Modelle routen
- Reasoning-intensive Aufgaben an leistungsfähigere Modelle routen
- feste Modelle für benchmarkierte oder regulierte Workflows beibehalten
- das tatsächlich ausgewählte Modell zurückgeben, wenn Routing verwendet wird, damit Teams Verhalten loggen und evaluieren können
Nutzungstransparenz und konsistente Abrechnung
Sobald eine App mehrere Modelle nutzt, wird Nutzungstransparenz zu einem Produkt- und Finanzthema – nicht nur zu einem technischen Detail.
Teams müssen beantworten können:
- Welches Feature nutzt welches Modell?
- Welches Kundensegment verursacht welche Kosten?
- Werden teure Modelle für einfache Aufgaben eingesetzt?
- Hat ein Modellwechsel die Latenz, den Token-Verbrauch oder die Fehlerrate erhöht?
- Kann die Nutzung nach Feature, Team, Umgebung oder API-Key zugeordnet werden?
Separate Provider-Dashboards erschweren diese Fragen, weil jeder Anbieter die Nutzung unterschiedlich darstellt. Eine einheitliche API-Schicht kann eine konsistentere Sicht auf Requests, Token, Aufgabenvolumen und Ausgaben über unterstützte Modelle hinweg schaffen.
Diese Transparenz ist die Grundlage für Kostenkontrolle. Modellökonomie lässt sich nicht steuern, wenn die Nutzungsdaten fragmentiert sind.
Kostenkontrolle über Modelle hinweg
Kostenkontrolle bedeutet nicht automatisch garantierte Einsparungen. Eine einheitliche API-Schicht sollte nicht versprechen, dass jeder Request günstiger wird.
Der praktische Mehrwert liegt in der Steuerungsfähigkeit:
- Modelle nach Aufgabentyp vergleichen
- den übermäßigen Einsatz von Premium-Modellen für einfache Aufgaben vermeiden
- Budgets oder Limits auf API-Key-, Team- oder Produktebene festlegen
- Modelländerungen anhand von Nutzungs- und Qualitätsdaten evaluieren
- Kostenrichtlinien näher an der Plattformschicht halten, statt sie über den Anwendungscode zu verstreuen
In der Produktion ist das größte Kostenproblem oft nicht ein einzelner teurer Request. Es ist eine teure Standardkonfiguration, die stillschweigend Millionen einfacher Anfragen bedient, weil niemand eine saubere Stelle hat, um sie zu ändern.
Fallback- und Zuverlässigkeitsplanung
KI-Systeme im Produktionsbetrieb brauchen einen Plan für Ausfälle:
- Provider-Ausfall
- Kontingenterschöpfung
- Rate Limiting
- verschlechterte Latenz
- modellspezifische Fehler
- unerwartete Qualitätseinbußen nach einem Modell-Update
Bei separaten Provider-Integrationen taucht Fallback-Logik häufig innerhalb der Produktservices auf. Ein Team implementiert Retries auf eine Weise. Ein anderes Team verwendet andere Timeouts. Ein drittes Team hat gar keinen Backup-Pfad.
Eine einheitliche API-Schicht bietet Teams eine bessere Stelle, um Fallback-Verhalten und operative Richtlinien zu definieren. Sie hilft dabei, Anwendungslogik von Entscheidungen zur Provider-Verfügbarkeit zu trennen.
Fallback erfordert dennoch Sorgfalt. Ein Backup-Modell kann ein anderes Ausgabeverhalten, andere Kontextlimits, Tool-Unterstützung oder Preisgestaltung aufweisen. Das Ziel ist nicht blinde Substitution. Das Ziel ist eine kontrollierte Stelle, um die Substitution zu planen und zu testen.
Sauberer Produktionsbetrieb
Mit wachsender KI-Nutzung benötigt die Modellschicht dieselbe operative Disziplin wie andere Infrastruktur:
- Logging
- Nutzungszuordnung
- Latenz-Tracking
- Fehlerklassifikation
- Zugriffskontrollen
- Review von Modelländerungen
- Incident Response
- Umgebungstrennung
- Dokumentation für Entwickler
Wenn jedes Feature-Team seine eigene Provider-Integration betreut, werden diese Praktiken inkonsistent. Eine einheitliche API-Schicht erleichtert es, gemeinsame Standards dafür zu definieren, wie Modellaufrufe erfolgen, beobachtet und geändert werden.
Deshalb kann der Begriff „eine API" irreführend sein. Der eigentliche architektonische Wert liegt nicht in einem einzelnen Endpunkt. Er liegt in einer zentralen Stelle, um die Modellbereitstellung zu betreiben.
Wann eine einfache einheitliche API ausreicht
Eine einfache einheitliche API kann ausreichend sein, wenn Ihr Hauptbedarf die Integrationsstabilität ist.
Verwenden Sie eine einfache einheitliche API-Schicht, wenn:
- Sie eine überschaubare Anzahl von Modellen nutzen
- Sie einen API-Key und ein einheitliches Request-Muster möchten
- die Modellauswahl überwiegend explizit erfolgt
- das Anfragevolumen handhabbar ist
- Fallback-Anforderungen begrenzt sind
- Ihr Team hauptsächlich den Integrationsaufwand reduzieren möchte
Beispiel: Ein Startup nutzt ein Modell für den User-Chat, ein Modell für interne Zusammenfassungen und ein Bildmodell für Content-Erstellung. Wenn das Produkt noch kein dynamisches Routing oder erweiterte Governance benötigt, liegt der erste Gewinn in einer stabilen, gemeinsamen Integrationsschicht.
Auch diese Stufe ist wertvoll. Sie verhindert, dass das Produkt drei separate Integrationsstacks aufbaut, bevor das Team seine tatsächlichen Workloads versteht.
Wann Sie eine fortgeschrittene Gateway- oder Routing-Schicht brauchen
Der Bedarf an einem fortgeschritteneren Gateway entsteht, wenn die einheitliche API-Schicht mehr leisten muss als nur Zugang bereitzustellen.
Routing, Gateway-Kontrollen oder eine verwaltete Modell-Bereitstellungsschicht werden relevant, wenn:
- das Anfragevolumen hoch genug ist, dass die Modellwahl die Marge beeinflusst
- Workloads stark in ihrer Komplexität variieren
- Zuverlässigkeitsanforderungen explizit definiert sind
- mehrere Teams oder Services von Modellaufrufen abhängen
- die Nutzung nach Produkt, Kunde oder Team zugeordnet werden muss
- Fallback-Verhalten getestet und dokumentiert sein muss
- Modelländerungen einem Review unterliegen sollen statt Ad-hoc-Edits
| Szenario | Was Sie voraussichtlich benötigen | Warum |
|---|---|---|
| Test eines Modells in einem Prototyp | Direkte API oder einfache einheitliche API | Geschwindigkeit ist wichtiger als Plattformkontrolle |
| Nutzung von 2–3 Modellen in einem Produkt | Einfache einheitliche API-Schicht | Eine Integrationsoberfläche reduziert anbieterspezifischen Glue-Code |
| Hochvolumige Produktions-Workloads | Einheitliche API mit Kosten- und Nutzungskontrollen | Ausgaben, Latenz und Nutzungszuordnung werden relevant |
| Entwicklung von Agenten mit variablen Aufgaben | Einheitliche API mit Routing für unterstützte Text-Workloads | Verschiedene Agent-Schritte benötigen möglicherweise unterschiedliche Modellprofile |
| Zuverlässigkeitsmanagement über Anbieter hinweg | Gateway- oder Routing-Schicht mit Fallback-Planung | Fehlerbehandlung sollte nicht in jedem Service dupliziert werden |
Wie sich das auf EvoLink abbildet
EvoLink basiert auf genau diesem Modell-Bereitstellungsmuster: ein API-Einstiegspunkt für unterstützte Modelle, mit Plattformfunktionen rund um Zugang, Kostentransparenz, Text-Workload-Routing und operative Kontrolle.
Statt jede Modellintegration als separates Projekt zu behandeln, können Teams EvoLink als gemeinsame Modell-Bereitstellungsschicht über unterstützte Modellfamilien hinweg nutzen.
Diese Positionierung ist bedeutsam, weil EvoLink nicht nur eine Modellliste ist. Die langfristige Architektur entspricht eher einer KI-Modell-Bereitstellungsinfrastruktur:
- Einheitlicher Zugang: Nutzen Sie einen Integrationspfad für unterstützte Modelle, statt den Zugang für jeden Anbieter oder jede Modellfamilie neu aufzubauen.
- Kostenkontrolle: Vergleichen Sie Modelloptionen, prüfen Sie Preisgestaltung und vermeiden Sie, dass Kostenrichtlinien im Anwendungscode untergehen.
- Aufrufkontrolle: Halten Sie Modellauswahl, Routing-Entscheidungen für unterstützte LLM-Anfragen, API-Keys und Nutzungsgrenzen näher an der Plattformschicht.
- Produktionsreife: Behandeln Sie Modellaufrufe als operativen Traffic, der Transparenz, Fallback-Planung und stabile Integrationspraktiken erfordert.
Die entscheidende Abgrenzung lautet: Eine einheitliche API-Schicht kann den Modellbetrieb vereinfachen, sollte aber nicht vortäuschen, dass alle Modelle identisches Verhalten zeigen. Teams brauchen weiterhin Evaluierung, Logging, Kostenprüfung und workflowspezifische Qualitätssicherung.
Entscheidungs-Checkliste
Nutzen Sie diese Checkliste, bevor Sie entscheiden, ob Ihre App eine einheitliche API-Schicht, ein Gateway oder direkte Provider-Aufrufe benötigt.
- Verwenden Sie heute mehr als eine Modellfamilie?
- Werden Sie später Bild-, Video-, Audio-, Coding- oder Long-Context-Modelle hinzufügen?
- Können Sie Modelle wechseln, ohne den Anwendungscode an mehreren Stellen zu ändern?
- Können Sie die Nutzung nach Feature, Team, Kunde oder API-Key einsehen?
- Können Sie Kosten über Modelle hinweg in einem Workflow vergleichen?
- Wissen Sie, welches Modell jeden Produktions-Request bedient hat?
- Haben Sie einen Fallback-Plan für Rate Limits, Provider-Ausfälle oder verschlechterte Latenz?
- Ist das Retry- und Timeout-Verhalten über Services hinweg konsistent?
- Können Entwickler ein dokumentiertes Modellzugangs-Muster nutzen?
- Wird die Modellwahl als operative Entscheidung geprüft und nicht nur als Codeänderung?
Wenn die meisten Antworten „Nein" lauten, geht es nicht nur um Integrationskomfort. Ihre Modellschicht wird Teil der Produktionsinfrastruktur.
FAQ
Was ist eine einheitliche API für KI-Modelle?
Eine einheitliche API für KI-Modelle ist eine Integrationsschicht, über die eine Anwendung unterstützte Modelle über einen konsistenten API-Einstiegspunkt aufrufen kann. Sie kann doppeltes Provider-Setup vermeiden und eine gemeinsame Stelle für Modellzugang, Nutzungstransparenz, Abrechnung, Kostenkontrollen, Routing und operative Richtlinien schaffen.
Ist eine einheitliche API dasselbe wie ein LLM-Gateway?
Nicht immer. Eine einfache einheitliche API stellt möglicherweise nur eine Zugangsschicht für mehrere Modelle bereit. Ein LLM-Gateway bietet in der Regel zusätzliche Infrastrukturfunktionen wie Routing, Fallback, Observability, Richtlinienkontrollen, Rate Limits oder Governance. In der Praxis beginnen viele Teams mit einem einheitlichen Zugang und entwickeln sich in Richtung Gateway, wenn die Produktionsanforderungen wachsen.
Brauche ich eine einheitliche API, wenn ich nur ein Modell nutze?
In der Regel nicht. Wenn Ihr Produkt ein einzelnes Modell verwendet, wenig Traffic hat und weder Fallback noch Multi-Provider-Transparenz benötigt, kann ein direkter API-Zugang einfacher sein. Eine einheitliche API wird dann wertvoller, wenn Modellauswahl, Kostenkontrolle oder Zuverlässigkeitsplanung zu wiederkehrenden Aufgaben werden.
Wie unterstützt eine einheitliche API beim Modell-Routing?
Routing benötigt eine stabile Stelle für Modellauswahl-Entscheidungen. Eine einheitliche API-Schicht bietet der Anwendung einen Request-Pfad, während die Routing-Logik ein Modell anhand von Aufgabentyp, Latenzanforderung, Kostenprofil oder anderen Signalen auswählt. Für den Produktionseinsatz sollte das Routing auch offenlegen, welches Modell ausgewählt wurde, damit Teams das Verhalten loggen, evaluieren und debuggen können.
Macht eine einheitliche API alle Modelle gleich?
Nein. Eine einheitliche API kann Teile des Zugangs, der Authentifizierung, des Request-Formats, der Nutzungsberichte oder der Routing-Richtlinien normalisieren – aber sie macht Modellqualität, Latenz, Kontextlimits, Tool-Verhalten, Modalitätsunterstützung oder Preisgestaltung nicht identisch. Teams sollten jedes Modell weiterhin gegen ihre eigenen Workflows testen.


