
负载均衡路由开发者指南

负载均衡路由不是让一台服务器不堪重负,而是智能地将传入请求分发到一组服务器,或者在现代 AI 应用场景下分发到不同的 AI 模型。结果是获得高可用、高性能的应用,为用户提供无缝体验。
负载均衡路由是如何工作的?
负载均衡路由的核心设计旨在消除单点故障。在典型的单服务器架构中,如果该服务器过载或离线,整个应用就会陷入停滞。
负载均衡路由位于用户和服务器池之间,拦截每一个传入请求,并决定哪一个下游资源最适合在那个时刻处理它。这个概念已经从早期的硬件设备大幅演变为支撑现代分布式系统的复杂软件层。理解这一原理是构建弹性系统的第一步,尤其是在处理具有不可预测性的 API 流量时。
为什么每个现代应用都需要它
对于开发者来说,一个实现良好的负载均衡器提供了关键优势:
- 高可用性: 如果某个服务器或 API 端点发生故障或无响应,路由会自动将其从池中移除,并将流量重定向到健康的实例。您的应用保持在线。
- 可扩展性: 为了处理增加的负载,您只需向池中添加更多服务器。负载均衡器将立即开始向它们路由流量,从而在不宕机的情况下实现水平扩展。
- 性能提升: 通过分担工作量,您可以确保用户请求始终由响应最快的服务器处理,从而降低延迟并提升整体用户体验。
请将负载均衡路由视为应用抵御停机的第一道防线。它将一系列独立的服务器转化为一个单一、强大且具有弹性的系统。
掌握这一概念可以让您从头开始构建弹性架构,而不是将其视为事后的补救。
理解核心负载均衡算法
这些算法为工作负载的分发提供了逻辑。下面的信息图说明了不同的策略如何协同工作以有效管理网络流量。
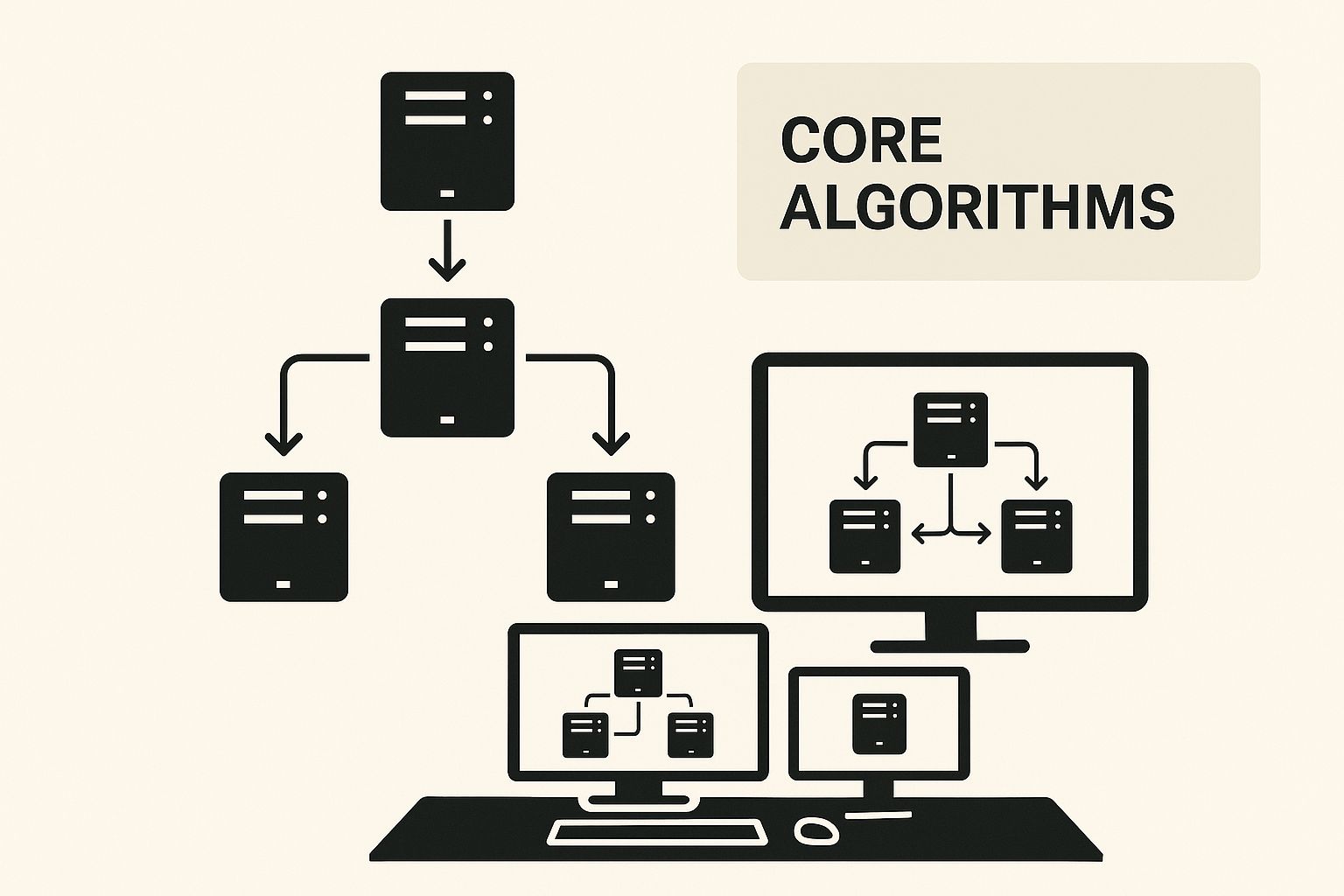
如您所见,这些基本方法是做出更复杂路由决策的基石。目标是防止任何一台服务器过载并导致系统范围内的故障。
常见的分配方法
那么,负载均衡器如何决定将流量发送到哪里呢?它通常使用几种标准算法之一。
-
轮询(Round Robin):这是最简单也最常用的方法。负载均衡器循环遍历服务器列表,将每个新请求发送到序列中的下一台服务器。它具有可预测性,但假设所有服务器具有相同的容量,且所有请求具有相似的处理成本。
-
最少连接(Least Connections):这是一种更具动态性的策略。算法将新请求路由到当前活跃连接数最少的服务器。这在连接持续时间不同的环境中特别有效,可以防止一台服务器被长时间运行的任务占用,而其他服务器处于空闲状态。
-
IP 哈希(IP Hash):该方法使用客户端 IP 地址的哈希值,将该客户端一致地映射到同一台服务器。主要好处是会话持久性(或称“粘性”),这对于状态化应用(如电子商务购物车)至关重要,因为用户会话数据必须保留在特定的服务器上。
常用负载均衡算法对比
选择正确的算法取决于应用的特定需求。下表细分了最常用的方法以供您对比。
| 算法 | 工作原理 | 适用场景 | 潜在缺点 |
|---|---|---|---|
| 轮询 (Round Robin) | 按顺序将请求分发到列表中的每台服务器。 | 服务器性能相同且请求性质统一的环境。 | 不考虑服务器负载或各异的处理时间。 |
| 最少连接 (Least Connections) | 将新请求发送到活跃连接数最少的服务器。 | 存在长连接或请求负载不均的情况。 | 跟踪连接数可能会消耗更多计算资源。 |
| IP 哈希 (IP Hash) | 根据源 IP 地址将请求分配给特定的服务器。 | 需要会话持久性的应用(如购物车)。 | 如果某些 IP 地址发送大量请求,可能导致分配不均。 |
| 加权轮询 (Weighted Round Robin) | 轮询算法的变体,根据容量给服务器分配“权重”。 | 服务器处理能力各异的环境。 | 需要手动配置权重并随着时间的推移进行调整。 |
最终,并没有单一的“最佳”算法。目标是使分发逻辑与应用行为和基础设施架构保持一致。
加权路由与智能路由
虽然这些经典的算法对传统的 Web 流量很有效,但在跨多个提供商路由 AI 请求时却显得力不从心。简单的轮询算法没有成本或可用性的概念;它可能会盲目地将您的请求发送到一个昂贵或不可用的提供商。这正是 EvoLink 这种先进的负载均衡路由所解决的问题,它实时地将您选择的模型智能地路由到最具成本效益且可靠的提供商。
AI 模型路由的现代挑战
传统的负载均衡假设您在一组相同的服务器之间分配流量。这种模型在处理无状态的 Web 请求时效果很好,但在应用于极其多样化的 AI 模型生态系统时则完全失效。
像 GPT-4、Llama 3 和 Claude Haiku 这样的模型是不可互换的。它们在推理能力、响应延迟以及关键的每个 token 成本方面都有显著差异。这使得问题从简单的流量分配变成了复杂的多目标优化难题。
在此使用基础的轮询方法是低效且昂贵的。您可能会将一个简单的摘要任务分配给最强大(且昂贵)的模型,而一个复杂的分析查询可能被发送到一个速度更快但能力较弱的模型,从而导致结果次优。

从统一服务器到多个 AI 提供商
一旦您选择了所需的 AI 模型,AI 原生路由必须针对每个请求评估几个因素:
- 提供商成本: 同样的 GPT-4 模型,在一个提供商处的成本可能是另一个提供商的 10 倍。为您选择的模型寻找最便宜的可用提供商可以立即节省成本。
- 提供商可用性: 提供商目前是否在线并有响应?实时健康检查可确保您的请求始终到达一个正常工作的端点。
- 提供商延迟: 现在哪个提供商的响应速度最快?动态性能监控会将请求路由到那个时刻响应最灵敏的提供商。
智能 AI 路由不仅仅是平衡负载;它是针对业务成果进行优化。对于您选择的模型,它对每一次 API 调用做出动态、明智的决策,通过选择最佳提供商,以尽可能低的成本提供最佳性能。
智能提供商路由的代码示例
这个概念性的 JavaScript 函数演示了为所选模型选择最佳提供商的逻辑。它检查提供商的可用性和成本,以路由到最佳端点。
// 为所选模型选择最佳提供商的概念函数
async function routeToProvider(selectedModel) {
// 用户已经选择了 GPT-4 作为他们的模型
const providers = [
{ name: 'OpenAI', endpoint: 'https://api.openai.com/v1/chat/completions', cost: 0.03, available: true },
{ name: 'Azure', endpoint: 'https://azure.openai.com/v1/chat/completions', cost: 0.035, available: true },
{ name: 'Provider-A', endpoint: 'https://api.provider-a.com/v1/gpt-4', cost: 0.015, available: true },
{ name: 'Provider-B', endpoint: 'https://api.provider-b.com/v1/gpt-4', cost: 0.012, available: false }
];
// 过滤出仅可用的提供商
const availableProviders = providers.filter(p => p.available);
// 按成本排序,最便宜的优先
availableProviders.sort((a, b) => a.cost - b.cost);
// 选择最便宜的可用提供商
const selectedProvider = availableProviders[0];
console.log(`正在将 ${selectedModel} 路由到 ${selectedProvider.name},每次请求费用为 $${selectedProvider.cost}`);
// 在实际应用中,您会在这里进行 API 调用
// const response = await fetch(selectedProvider.endpoint, { ... });
// return response.json();
return {
model: selectedModel,
provider: selectedProvider.name,
endpoint: selectedProvider.endpoint,
cost: selectedProvider.cost
};
}
// 示例用法 - 用户选择了 GPT-4
routeToProvider('GPT-4').then(result => console.log(result));虽然这段代码说明了核心概念,但构建一个生产就绪的系统涉及更多内容:管理数十个提供商的 API 密钥、跟踪实时定价和可用性、在提供商宕机时实施自动故障转移,以及持续监控性能。
通过 EvoLink 将高级 AI 路由付诸实践
从头开始构建智能 AI 路由是一个巨大的工程挑战。它需要管理多个 API 密钥、监控实时模型性能、编写鲁棒的故障转移逻辑,并在新模型发布时持续更新系统。这就是为什么像 EvoLink 这样的托管解决方案对于开发团队来说是游戏规则的改变者。
这种统一的方法极大地减少了运营开销,并使您的工程团队能够专注于核心产品,而不是管理 AI 基础设施。
智能路由在现实世界中如何工作
以下是 EvoLink 的核心功能如何带来切实利益:
- 自动模型故障转移: 如果像 OpenAI 这样的主要提供商发生故障或性能下降,EvoLink 会自动将 API 调用重路由到提供相同模型的健康替代提供商。您的应用将继续无缝运行。
- 动态性能路由: 系统持续监控所选模型的所有可用提供商的延迟和吞吐量,将每个请求发送到那一刻能够提供最快响应的提供商。
- 智能成本优化: EvoLink 自动将您的请求路由到针对所选模型最具成本效益的提供商,不断比较数十个提供商的价格,以确保您始终获得最佳费率。
通过智能路由流量,使用 EvoLink 的开发者通常能实现 20-70% 的成本节约。这不仅仅是选择最便宜的提供商;而是针对每一个请求做出“最明智”的提供商选择,以便在平衡性能和预算的同时,使用您首选的模型。
EvoLink 的实际代码示例
考虑这个 Python 示例。您提供一个优先的模型列表,EvoLink 会自动管理所有路由、优化和故障转移。
import os
import requests
# 从环境变量中设置您的 EvoLink API 密钥
api_key = os.getenv("EVOLINK_API_KEY")
api_url = "https://api.evolink.ai/v1/chat/completions"
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}
# 定义您的首选模型及备选选项
# EvoLink 将每个模型路由到最便宜的可用提供商
# 如果您的第一选择不可用,它会自动故障转移到列表中的下一个模型
payload = {
"model": ["openai/gpt-4o", "anthropic/claude-3.5-sonnet", "google/gemini-1.5-pro"],
"messages": [
{"role": "user", "content": "Analyze the sentiment of this customer review: 'The product is good, but the shipping was slow.'"}
]
}
try:
response = requests.post(api_url, headers=headers, json=payload)
response.raise_for_status() # 为错误的响应(4xx 或 5xx)抛出 HTTPError
print(response.json())
except requests.exceptions.RequestException as e:
print(f"发生 API 错误: {e}")这段代码展示了抽象的力量。您的应用代码保持整洁并专注于业务逻辑,而一个强大的负载均衡路由在后台工作,使您的应用更具弹性和成本效益。
EvoLink 消除了构建和维护复杂的内部系统的需求,提供了一个可以立即产生效果的生产就绪解决方案。这使您的团队能够更快、更高效地集成世界一流的 AI 能力。
您可以实施的实用路由策略
让我们探索您可以实施的四种实用策略。

基于成本的路由
这种策略优先考虑您的预算。基于成本的路由会自动将您的请求发送到您所选模型的最实惠提供商。
基于延迟的路由
当用户体验至关重要时,基于延迟的路由是最佳选择。这对于实时应用(如客户服务聊天机器人或交互式 AI 工具)至关重要,因为每一毫秒都至关重要。
路由会持续监控所选模型的所有可用提供商的实时性能。当请求到达时,它会立即转发到当前响应时间最低的提供商,确保您的用户收到尽可能快的回复,而无需更改您使用的模型。
故障转移路由
故障转移路由是您应用的保险。API 提供商不可避免地会经历故障或性能下降。当这种情况发生时,路由会自动将请求重路由到预定义优先级列表中的下一个健康模型。
这一策略是构建高可用系统的基础,这类系统可以优雅地处理提供商故障,而不会对终端用户体验产生任何影响。
常见问题解答
负载均衡器和路由器有什么区别?
虽然经常一起使用,但这些组件在网络中提供不同的功能。
我可以自己构建 AI 模型负载均衡器吗?
技术上来说是可以的,您可以构建自定义解决方案。然而,生产级 AI 路由的复杂性是非常巨大的。
一个鲁棒的解决方案需要的不仅仅是简单的请求分派。您需要负责安全地管理数十个 API 密钥、跟踪每个模型的实时成本和延迟、实施可靠的健康检查以及编写有效的故障转移逻辑。此外,该系统需要持续维护以纳入新模型并适应 API 变化。
这正是像 EvoLink 这样的托管解决方案提供显著价值的地方。我们已经构建了一个经过生产验证的系统,可以处理所有这些复杂性。您获得了一个内置智能路由的统一 API,让您的团队能够专注于核心产品而不是基础设施。这种方法可以带来立即生效的 20-70% 的成本节约,并确保从第一天起就具有高可靠性。
负载均衡路由实际上是如何让我的应用更可靠的?
可靠性是通过两个主要机制实现的:冗余和自动健康检查。
通过在多个模型或服务器之间分发请求,负载均衡器消除了单点故障。如果一个模型 API 不可用或一台服务器宕机,由于流量会自动导向健康的备选方案,应用仍能保持运行。
系统还会对每个端点进行持续的健康检查,就像监测生命体征一样。它会定期发送请求以验证每个端点是否有响应。如果某个端点未通过这些检查或返回错误,路由会立即将其从活跃池中移除,并将新请求无缝地重定向到剩余的健康端点。这种自动故障转移确保了即使在部分系统发生故障时也能保持高可用性。


