
Guía del desarrollador para la API de inferencia de Hugging Face

¿Qué es la API de inferencia de Hugging Face?

En esencia, la API de inferencia de Hugging Face es un servicio que permite ejecutar modelos de aprendizaje automático alojados en el Hugging Face Hub mediante llamadas API directas. Abstrae por completo las complejidades del despliegue de modelos, como la gestión de GPUs, la configuración de servidores y el escalado. En lugar de aprovisionar sus propios servidores, envía datos al punto final (endpoint) de un modelo y recibe las predicciones de vuelta.
Para darle una imagen más clara, aquí tiene un breve desglose de lo que ofrece la API.
La API de inferencia de Hugging Face de un vistazo
Esta tabla resume las características clave y los beneficios de usar la API de inferencia de Hugging Face para diversas necesidades de desarrollo.
| Característica | Descripción | Beneficio principal |
|---|---|---|
| Inferencia sin servidor | Ejecute modelos mediante llamadas API sin gestionar servidores, GPUs ni infraestructura. | Cero sobrecarga de infraestructura: Libera tiempo de ingeniería para centrarse en construir funciones. |
| Acceso al Hub masivo | Utilice instantáneamente cualquiera de los más de 1.000.000 de modelos disponibles para diversas tareas. | Flexibilidad inigualable: Cambie fácilmente de modelo para encontrar el mejor para su caso de uso. |
| Interfaz HTTP simple | Interactúe con modelos de IA complejos utilizando peticiones HTTP estándar y bien documentadas. | Prototipado rápido: Construya y pruebe pruebas de concepto basadas en IA en minutos, no semanas. |
| Precios de pago por uso | Solo paga por el tiempo de computación que utiliza, lo que lo hace rentable para experimentación. | Eficiencia de costes: Evita los altos costes fijos de mantenimiento de una infraestructura dedicada. |
En última instancia, la API está diseñada para llevarle del concepto a una función de IA operativa con la menor fricción posible.
Beneficios clave para los desarrolladores
La API está claramente construida pensando en la eficiencia del desarrollador, ofreciendo algunas ventajas clave que la convierten en una opción predilecta para muchos proyectos.
- Cero gestión de infraestructura: Olvídese de aprovisionar GPUs, lidiar con controladores CUDA o preocuparse por el escalado de servidores. La API se encarga de todo el trabajo pesado del backend.
- Selección masiva de modelos: Con acceso directo al Hub, puede cambiar instantáneamente entre modelos para tareas como análisis de sentimiento, generación de texto o procesamiento de imágenes simplemente cambiando un parámetro en su llamada API.
- Prototipado rápido: La gran facilidad de uso permite construir una prueba de concepto para una función de IA en una sola tarde.
Autenticación y su primera llamada a la API
Authorization de cada petición. Esto indica a los servidores de Hugging Face que usted es un usuario legítimo con permiso para ejecutar el modelo al que está llamando. El proceso es sencillo pero crucial: obtenga el token, colóquelo en la cabecera y realice la llamada.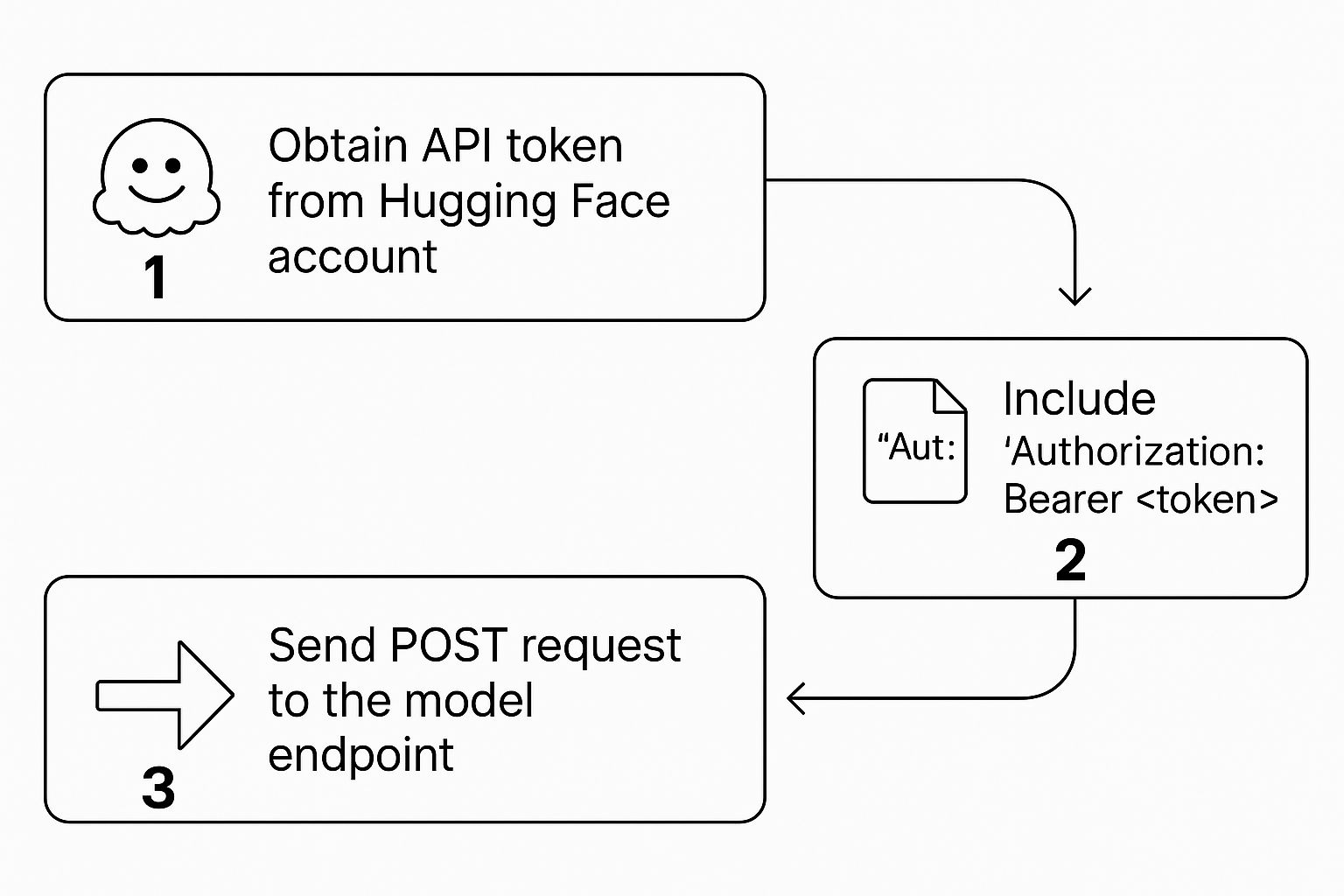
Una vez que haya generado su token, todo consiste en estructurar la petición correctamente para asegurar que todo funcione de forma fluida y segura.
Su primera llamada API en Python
requests de Python. Los componentes clave son la URL de la API específica del modelo y un cuerpo JSON correctamente formateado con su texto de entrada. La cabecera Authorization debe utilizar el esquema "Bearer", estándar para las APIs modernas. Simplemente prefije su token con Bearer —no olvide el espacio."SU_TOKEN_API" con su token real.import requests
import os
# Mejor práctica: guarde su token en una variable de entorno
# Para este ejemplo, lo definimos directamente.
API_TOKEN = "SU_TOKEN_API"
API_URL = "https://api-inference.huggingface.co/models/distilbert/distilbert-base-uncased-finetuned-sst-2-english"
def query_model(payload):
headers = {"Authorization": f"Bearer {API_TOKEN}"}
response = requests.post(API_URL, headers=headers, json=payload)
response.raise_for_status() # Lanza una excepción para códigos de error
return response.json()
# Clasifiquemos una frase
data_payload = {
"inputs": "I love the new features in this software, it's amazing!"
}
try:
output = query_model(data_payload)
print(output)
# La salida esperada podría ser: [[{'label': 'POSITIVE', 'score': 0.9998...}]]
except requests.exceptions.RequestException as e:
print(f"Ocurrió un error: {e}")POSITIVE o NEGATIVE, junto con una puntuación de confianza. Este patrón fundamental se aplica a todo tipo de tareas; solo cambia la estructura del payload. Por supuesto, cuando trabaje con modelos más avanzados como generadores de vídeo, las interacciones con la API pueden volverse más complejas, como puede ver en esta detallada guía de la API de Sora 2 para 2025.Codificar su token de forma rígida (hardcoding) está bien para una prueba rápida, pero es un riesgo de seguridad significativo en un proyecto real. Nunca incluya claves de API en un repositorio Git. Utilice variables de entorno o una herramienta de gestión de secretos para mantener sus credenciales a salvo.
Aplicando la API de inferencia a diferentes tareas de IA

inputs para cada modelo.Generación de texto creativo
max_length.import requests
API_URL = "https://api-inference.huggingface.co/models/gpt2"
headers = {"Authorization": "Bearer SU_TOKEN_API"}
def query_text_generation(payload):
response = requests.post(API_URL, headers=headers, json=payload)
return response.json()
output = query_text_generation({
"inputs": "The future of AI in software development will be",
"parameters": {"max_length": 50, "temperature": 0.7}
})
print(output)
# Salida esperada: [{'generated_text': 'The future of AI in software development will be...'}]La respuesta devuelve un objeto JSON limpio con el texto generado, lo que facilita su procesamiento e integración.
Clasificar contenido de imágenes
'rb').import requests
API_URL = "https://api-inference.huggingface.co/models/google/vit-base-patch16-224"
headers = {"Authorization": "Bearer SU_TOKEN_API"}
def query_image_classification(filename):
with open(filename, "rb") as f:
data = f.read()
response = requests.post(API_URL, headers=headers, data=data)
return response.json()
try:
output = query_image_classification("cat.jpg")
print(output)
except FileNotFoundError:
print("Error: 'cat.jpg' no encontrado.")Clasificación de texto Zero-Shot
inputs (su texto) y un objeto parameters con una lista de candidate_labels.// Ejemplo en JavaScript usando fetch
async function queryZeroShot(data) {
const response = await fetch(
"https://api-inference.huggingface.co/models/facebook/bart-large-mnli",
{
headers: { Authorization: "Bearer SU_TOKEN_API" },
method: "POST",
body: JSON.stringify(data),
}
);
const result = await response.json();
return result;
}
queryZeroShot({
"inputs": "Our new feature launch was a massive success!",
"parameters": {"candidate_labels": ["marketing", "customer feedback", "technical issue"]}
}).then((response) => {
console.log(JSON.stringify(response));
});Comprendiendo los costes y niveles de uso
Cada nivel incluye una cantidad de créditos mensuales. Una vez agotados, se pasa a un modelo de pago por uso. Aunque es ideal para empezar, gestionar costes separados para múltiples modelos puede ser un reto operativo.
Simplificando su gestión de costes
De llamadas directas al enrutamiento inteligente
Optimizando el rendimiento para producción

Construyendo resiliencia más allá de un único punto final
Esta arquitectura ofrece dos beneficios críticos:
- Failover automático: Si un proveedor falla, EvoLink redirige instantáneamente la petición a una alternativa sana.
- Balanceo de carga: Durante picos de tráfico, las peticiones se distribuyen automáticamente entre varios proveedores.
De la llamada directa a la pasarela unificada
La transición es sencilla: sustituya la llamada directa por el endpoint de EvoLink. Este cambio mejora inmediatamente la fiabilidad y reduce significativamente los costes.
# Antes: Llamada directa a Hugging Face
import requests
HF_API_URL = "https://api-inference.huggingface.co/models/gpt2"
HF_TOKEN = "SU_TOKEN_HF"
def direct_hf_call(payload):
headers = {"Authorization": f"Bearer {HF_TOKEN}"}
response = requests.post(HF_API_URL, headers=headers, json=payload)
return response.json()# Después: Llamando a la API unificada de EvoLink
import requests
EVOLINK_API_URL = "https://api.evolink.ai/v1"
EVOLINK_TOKEN = "SU_TOKEN_EVOLINK"
def evolink_image_generation(prompt):
headers = {"Authorization": f"Bearer {EVOLINK_TOKEN}"}
payload = {
'model': 'doubao-seedream-4.0',
'prompt': prompt,
'size': '1024x1024'
}
response = requests.post(f"{EVOLINK_API_URL}/images/generations",
headers=headers, json=payload)
return response.json()Preguntas frecuentes y respuestas prácticas
¿Cómo debo manejar los límites de frecuencia (Rate Limits)?
Varias tácticas pueden ayudar:
- Batching: Agrupe sus peticiones en una sola llamada.
- Exponential Backoff: Implemente una lógica de reintento que espere progresivamente más tiempo entre intentos.
¿Puedo ejecutar modelos privados?
Authorization. Asegúrese de que la cuenta tenga los permisos necesarios.

