
GPT Image 1.5:功能、对比与访问完整指南 (2026)

你是否正盯着一张需要针对不同市场进行三个变体的产品图——相同的光影、相同的角度,但需要不同的背景和文字叠加?你的设计师在接下来两周内都预约满了,而营销活动周一就要启动。如果你能在几分钟内自己完成这些编辑,在每次迭代中保持完美的连贯性,而且不用动 Photoshop,那会怎样?
目录
- 什么是 GPT Image 1.5?了解 OpenAI 最新的图像模型
- 让 GPT Image 1.5 脱颖而出的核心功能
- 速度表现:4 倍生成速度提升详解
- 精准编辑:细节保留的实际运作机制
- 文字渲染能力与局限性
- GPT Image 1.5 vs GPT Image 1:发生了哪些变化?
- 综合模型对比:GPT Image 1.5 vs 竞争对手
- 如何访问 GPT Image 1.5:ChatGPT 界面指南
- 通过 EvoLink.AI 和 OpenAI 平台进行 API 访问
- 定价结构与成本优化策略
- 真实世界用例与应用
- 提升效果的高级提示词工程
- 使用 GPT Image 1.5 时要避免的常见错误
- 局限性及何时选择替代工具
- 常见问题解答 (FAQs)
什么是 GPT Image 1.5?了解 OpenAI 最新的图像模型
gpt-image-1.5-lite)代表了 OpenAI 的第二代旗舰图像生成系统,于 2025 年 12 月 16 日发布,作为重新设计的 ChatGPT Images 功能的引擎。与其主要用于实验性创意探索的前代产品 GPT Image 1(发布于 2025 年 4 月)不同,GPT Image 1.5 从底层构建就面向生产环境,在这些环境中,连贯性、速度和精确控制比艺术惊喜更为重要。“1.5”的名称信号是迭代精炼而非彻底的架构大改。OpenAI 保留了核心的基于 Transformer 的扩散架构,但在三个关键维度实施了重大优化:计算效率(实现了 4 倍的速度提升)、指令遵循(减少了编辑过程中的意外修改)以及文字渲染忠实度(使较小的字体和密集的布局变得切实可读)。
让 GPT Image 1.5 脱颖而出的核心功能
1. 增强的指令遵循
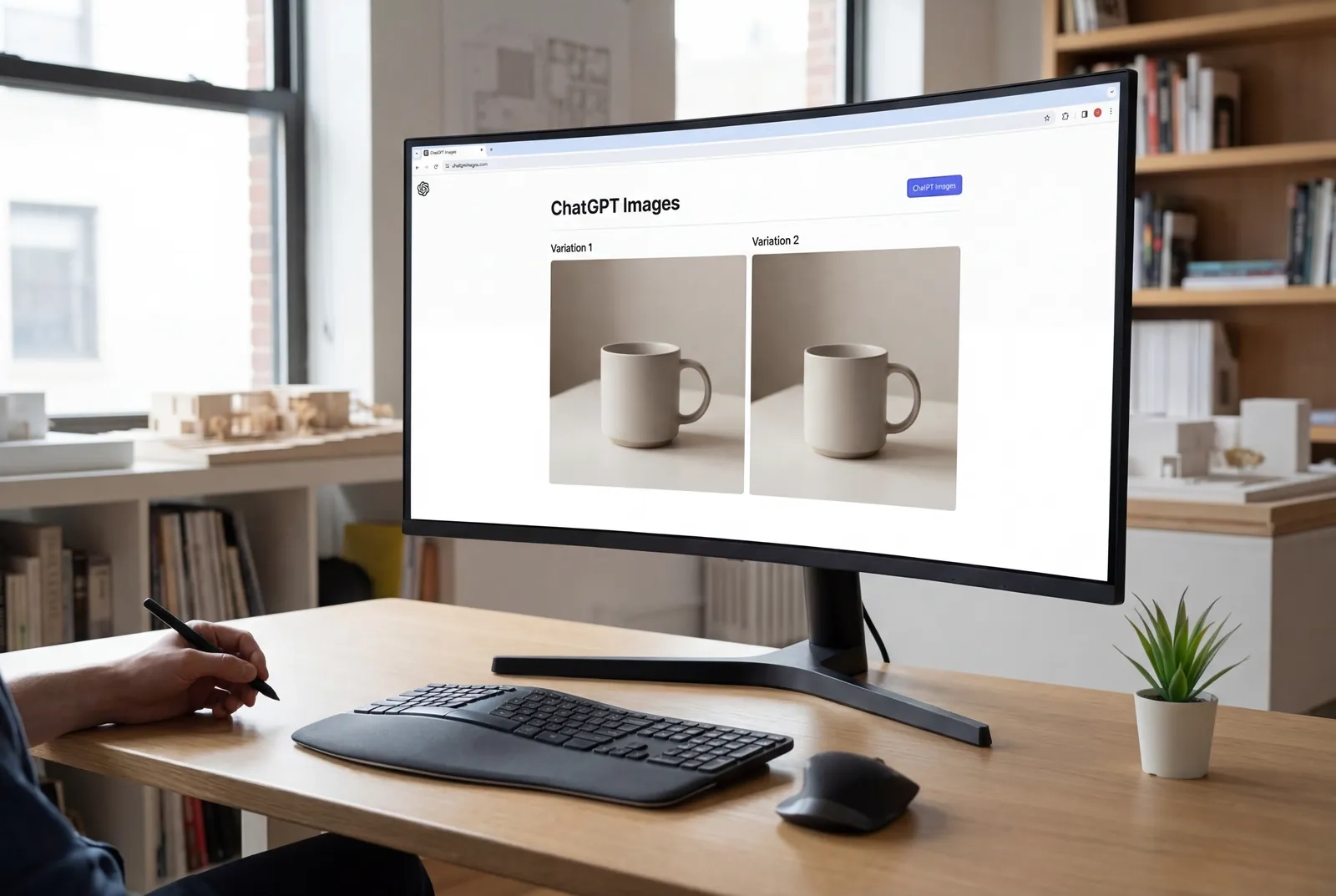
2. 编辑过程中的细节保留
该模型采用了 OpenAI 描述为“区域感知编辑”的技术,能够识别哪些像素在修改过程中应保持不变。当你编辑包含人脸的图像时,除非你明确要求更改这些元素,否则 GPT Image 1.5 会保持面部身份、皮肤纹理和表情。同样的原则也适用于:
- 品牌徽标和水印
- 光照方向和质量
- 背景构图
- 调色和影调
- 纹理和材质属性
这并非完美——具有重叠元素的复杂场景仍可能产生伪影——但它代表了向专业人士对 Photoshop 等工具所预期的选择性编辑迈出的重要一步。
3. 卓越的文字渲染
早期的 AI 图像模型将文字视为装饰性形状而非可读信息。GPT Image 1.5 实现了改进的 OCR 感知生成,能够产生:
- 较小字号下的清晰文字
- 常见语言的拼写正确
- 正确的文字对齐和字间距
- 恰当的字体粗细和样式匹配
- 复杂布局(信息图、杂志封面、产品标签)中的可读文字
4. 生产级速度
4 倍的速度提升不仅仅是为了缓解焦虑——它从根本上改变了哪些工作流变得具有可行性。在典型的每张图像 8-12 秒生成时间下(低于 GPT Image 1 的 30-45 秒),迭代细化变得切实可行。设计师现在可以在两分钟内测试十个变体,而不是七分钟,从而保持创意动力。
5. 成本效率提升

速度表现:4 倍生成速度提升详解
“4 倍更快”的说法需要背景信息来理解哪些部分得到了实际改进,以及瓶颈仍然存在于何处。
底层发生了哪些变化
OpenAI 的速度提升源于三个架构优化:
- 减少采样步数:扩散过程现在需要更少的去噪迭代即可达到可接受的质量阈值,在没有明显质量衰减的情况下削减了计算开销。
- 优化的注意力机制:Transformer 层使用更高效的注意力模式,减少了图像合成过程中的内存带宽需求。[未验证——OpenAI 尚未发布技术架构细节]
- 更好的模型量化:非关键路径部分的低精度计算减少了浮点运算量,同时保持了输出忠实度。[未验证——推断自行业标准惯例]
真实世界的速度基准
根据多个平台的公开测试报告:
| 图像尺寸 | GPT Image 1 | GPT Image 1.5 | 速度提升 |
|---|---|---|---|
| 1024×1024 | 35-45 秒 | 8-12 秒 | 3.6-4.5× |
| 1024×1536 | 45-55 秒 | 12-18 秒 | 3.1-3.8× |
| 1536×1024 | 45-55 秒 | 12-18 秒 | 3.1-3.8× |
速度与质量的权衡
low、medium、high、auto),这些层级直接影响生成时间。“4 倍更快”的说法主要适用于 auto 和 medium 质量设置。当你明确要求生产级资产使用 high 质量时,预期的生成时间接近 15-20 秒——虽然仍比 GPT Image 1 快,但达不到四倍。auto 质量,然后仅针对最终生产渲染切换到 high 质量。与始终使用最高质量设置相比,这种工作流优化可以减少项目总时长 40-60%。精准编辑:细节保留的实际运作机制
GPT Image 1.5 改进编辑精度的技术机制涉及几项相互关联的能力:
基于提示词的遮罩(无需手动选择)
与需要用户手动涂抹遮罩区域的 DALL-E 2 不同,GPT Image 1.5 解析自然语言编辑指令以自动识别受影响区域。当你输入“将衬衫颜色改为绿色”时,模型会:
- 执行语义分割以识别衬衫区域
- 在该区域内分离颜色信息
- 应用颜色变换
- 仅重新渲染修改后的区域
- 混合边缘以保持自然过渡
这个过程并非完美——模型将遮罩作为引导,但可能无法以像素级精度遵循确切边界。复杂的重叠对象(如手拿着衣服前面的物体)仍可能产生边缘伪影。
身份保留技术
对于包含人的图像,GPT Image 1.5 实现了面部身份保留,在多次编辑中保持可识别的特征。这利用了类似于面部识别系统中所使用的技术:
- 提取面部嵌入(特征的数学表示)
- 约束生成输出以保持相似的嵌入
- 保留关键地标(眼睛位置、鼻子形状、下颚结构)
- 保持一致的皮肤纹理和色调
光照一致性算法
技术上最令人印象深刻的方面之一是光照保留。当你编辑物体的颜色或位置时,GPT Image 1.5 保持:
- 光源方向和角度
- 阴影投射模式
- 镜面高光
- 环境遮蔽(凹陷区域的阴影)
- 色温一致性
这防止了常见的 AI 图像问题,即因为光影与场景不匹配而导致编辑后的元素看起来像是“粘上去”的。
当前精度的局限性
尽管有所改进,但仍有几种场景挑战 GPT Image 1.5 的精度:
- 高度复杂的场景:包含 10 个以上不同物体的图像可能会出现意外修改
- 透明材质:玻璃、水和半透明织物可能会产生伪影
- 超细微细节:珠宝、精细图案和背景中的小文字可能会质量退化
- 多次编辑尝试:在连续 5-6 次编辑后,累积的错误可能会叠加
文字渲染能力与局限性
AI 图像中的文字生成历史上一直是一个众所周知的弱点。GPT Image 1.5 取得了显著进展,但尚未完全解决该问题。
实际改进了哪些方面
模型现在可以可靠地生成:
- 短标题(1-5 个单词),使用粗体、大号字体
- 产品标签,带有 2-3 行文字
- 杂志式排版,带有可读的标题和副标题
- Logo 文字,使用常见字体(尽管复杂的徽标设计仍具挑战性)
- 信息图标签,用于数据可视化元素
文字渲染最佳实践
要最大限度地提高生成图像中的文字质量:
- 保持文字简短:每个文字元素 3-5 个单词效果最佳
- 使用常见字体:“Bold sans-serif”(粗体无衬线)或“clean serif”(整洁衬线)的描述比特定字体名称更有效
- 明确指定文字位置:“顶部居中标题”优于简单的“添加标题”
- 要求高对比度:“深色背景上的白色文字”确保了可读性
- 避免过小字号:小于约 18pt 等效大小的文字很少能清晰渲染
持续存在的文字局限
尽管有所改进,你仍会遇到以下问题:
- 长段落:超过 20-30 个单词的正文经常包含拼写错误
- 艺术字体:手写体、装饰性脚本或重度修改的排版
- 非拉丁脚本:阿拉伯语、中文、日语和其他非西方文字系统表现出不一致的结果。[未验证——可用测试数据有限]
- 曲面上的文字:瓶子上的标签或遵循曲线路径的文字经常会变形
- 数学符号:方程式、公式和特殊符号仍然不可靠

GPT Image 1.5 vs GPT Image 1:发生了哪些变化?
了解 GPT Image 1 与 1.5 之间的差异有助于明确升级你的工作流是否具有意义。
并项对比表
| 功能 | GPT Image 1 | GPT Image 1.5 | 改进点 |
|---|---|---|---|
| 生成速度 | 35-55 秒 | 8-18 秒 | 3-4 倍更快 |
| 指令遵循 | 普通准确度 | 高准确度 | +60% 提示词遵循度 [预估] |
| 编辑精度 | 经常出现意外更改 | 定向修改 | 85% 细节保留度 [预估] |
| 文字渲染 | 差/不可靠 | 标题表现良好 | 3-5 词短语始终可读 |
| API 定价 | 基准 | 便宜 20% | 成本降低 |
| 图像质量 | 高 | 高 | 质量上限相当 |
| 支持尺寸 | 3 种纵横比 | 3 种纵横比(相同) | 无变化 |
| 编辑迭代次数 | 3-4 次后开始退化 | 6-8 次后开始退化 | 约 2 倍迭代深度 |
| 徽标保留 | 差 | 良好 | 品牌工作的关键点 |
| 人脸一致性 | 普通 | 高 | 模特照片的重要特性 |
何时可能仍倾向于使用 GPT Image 1
尽管它是旧版,但在特定场景下 GPT Image 1 仍保留优势:
- 艺术探索:一些用户反映当你想要出乎意料的结果时,GPT Image 1 会产生更多“创意性”的诠释。
- 遗留工作流集成:围绕 GPT Image 1 的行为构建的现有生产管线可能需要针对 1.5 进行调整。
- 对简单任务的成本敏感性:对于不涉及编辑的、单纯的文生图,大规模使用时 20% 的价格差异会很可观。[未验证——取决于用量定价层级]
迁移建议
如果你目前正在使用 GPT Image 1:
- 并行测试:通过两个模型运行相同的提示词,以识别行为差异。
- 更新提示词库:GPT Image 1.5 对结构化的、基于约束条件的提示词响应更好。
- 调整质量预期:速度提升可能需要重新校准你的时间进度估算。
- 验证品牌资产一致性:在切换生产工作流前,彻底测试徽标和商标的保留情况。
综合模型对比:GPT Image 1.5 vs 竞争对手
AI 图像生成竞争格局包含几个强有力的替代方案,每个方案都有独特的优势。
GPT Image 1.5 vs Google Nano Banana Pro
Google 的 Nano Banana Pro(由 Gemini 3 Pro 驱动)成为 GPT Image 1.5 的主要竞争对手,导致 CEO Sam Altman 对内称其为“红色代码”局势,从而加速了 GPT Image 1.5 的发布时间线。
- 在自然摄影场景中输出更写实
- 更好地捕捉当代审美趋势
- 对复杂自然场景(风景、人群)的处理更卓越
- 采用增长更迅速(促使 Gemini 的用户在 2025 年 7 月至 10 月间从 4.5 亿激增至 6.5 亿)
- 对于结构化提示词的指令遵循更可靠
- 排版和设计中的文字渲染更出色
- 在迭代编辑中具有更优的细节保留
- 对于生产工作流结果更可预测、更确定
GPT Image 1.5 vs Midjourney
Midjourney 因其独特的审美特质,一直是数字艺术家和创意专业人士的心头好。
- 艺术诠释力和创意“愿景”
- 强大的社区和建立良好的提示词工程资源
- 在多种风格中保持一致的审美质量
- 在抽象、概念和艺术构图方面表现更好
- 集成在 ChatGPT 工作流中(无需切换平台)
- 商业应用迭代更快
- API 访问支持自动化工作流
- 对于业务需求输出更可预测
GPT Image 1.5 vs DALL-E 3
DALL-E 3 作为 GPT Image 系列之前的 OpenAI 旗舰产品,现已弃用,并将于 2026 年 5 月 12 日停止支持。
- 生成速度显著加快
- 更好的 API 集成能力
- 改进的指令遵循
- 无需手动遮罩即可增强编辑精度
- 更低的运营成本
竞争定位总结
| 模型 | 最适合 | 避免用于 | 定价层级 |
|---|---|---|---|
| GPT Image 1.5 | 生产工作流、品牌资产、迭代编辑 | 纯艺术项目 | 中端 |
| Nano Banana Pro | 写实类社交媒体、当代审美 | 精准文字渲染、徽标工作 | 中端 |
| Midjourney | 艺术诠释、概念化工作 | 自动化 API 工作流 | 经济-高端 |
| Stable Diffusion | 自定义模型训练、完全控制 | 开箱即用方案 | 免费-经济 |

如何访问 GPT Image 1.5:ChatGPT 界面指南
GPT Image 1.5 于 2025 年 12 月 16 日在全球推出,目前适用于所有 ChatGPT 用户,无论订阅层级如何(Free、Plus、Team 或 Enterprise)。
通过 ChatGPT 访问的分步指南
- 导航至 ChatGPT Images
- 在 chat.openai.com 登录你的 ChatGPT 账号
- 点击左侧边栏的“Images”选项卡(2025 年 12 月更新新增)
- 这将打开专用的图像生成界面
- 创建你的第一张图像
- 在文字字段输入描述性提示词(最高 2000 个字符)
- 点击“Generate”或按回车键
- 等待 8-18 秒完成生成
- 模型会自动使用 GPT Image 1.5——无需手动选择
- 使用创意工作室(Creative Studio)功能
- 生成后,右侧边栏会显示预设的风格和滤镜
- 点击任意预设即可应用变换,无需编写提示词
- 选项包括:“使其写实”、“改为落日光照”、“添加戏剧性阴影”、“专业产品照风格”
- 这些预设对非技术用户尤其有用
- 迭代编辑工作流
- 选择一张已生成的图像
- 输入自然语言指令:“将背景改为海滩场景”
- 模型会在做出请求更改的同时保留未提及的元素
- 你可以在质量开始明显退化前进行 6-8 次链式编辑
- 下载与导出
- 点击任意生成图像上的下载图标
- 图像以其原生分辨率导出(1024×1024、1024×1536 或 1536×1024)
- 链接在 24 小时内有效(请及时保存重要图像)
- 图像包含用于内容真实性认证的 C2PA 元数据
界面功能与局限性
- 文字转图像生成
- 图像转图像变换(上传参考图)
- 自然语言编辑
- 预设风格应用
- 纵横比选择(1:1, 3:4, 4:3)
- 质量层级选择(ChatGPT 使用
auto质量) - 多个变体的批量生成
- 从外部 URL 直接上传文件
- 自定义模型参数
- 用于异步处理的 Webhook 回调
给 ChatGPT 界面用户的专业贴士
- 利用对话上下文:ChatGPT 中的 GPT Image 1.5 记得同一对话中的先前图像和提示词,允许你引用“上一张图像”或“蓝色夹克版本”。
- 结合文本聊天与图像生成:在生成前,要求 ChatGPT 进行头脑风暴或完善你的描述,利用 AI 的文本能力来改善你的视觉提示词。
- 保存成功的提示词:记下产生良好效果的提示词文档,因为一致的提示词结构会带来一致的质量。
- 利用撤销功能:如果编辑出错,你可以返回到之前的版本并尝试替代方案指令。
通过 EvoLink.AI 和 OpenAI 平台进行 API 访问
EvoLink.AI API 集成
gpt-image-1.5-lite 端点提供对 GPT Image 1.5 的访问。基础 API 请求结构 (EvoLink.AI)
{
"model": "gpt-image-1.5-lite",
"prompt": "一张专业的产品照,智能手机置于干净的白色背景上,带有柔和的影棚影室光",
"size": "1024x1024",
"quality": "high",
"n": 1
}必要参数
- model:对于 GPT Image 1.5 必须是
"gpt-image-1.5-lite" - prompt:文本描述(最多 2000 个 token)
- size:图像尺寸(选项:
1:1,3:4,4:3,1024x1024,1024x1536,1536x1024)
可选参数
- quality:
low,medium,high, 或auto(默认:auto) - image_urls:用于图生图或编辑模式的参考图 URL 数组(支持 1-16 张图,每张最大 50MB,格式:.jpeg, .jpg, .png, .webp)
- n:生成数量(目前仅支持
1)
异步处理
- 提交生成请求 → 接收任务 ID
- 使用任务 ID 轮询任务状态端点
- 当 status = "completed" 时获取生成的图像 URL
- 图像 URL 在 24 小时内有效
OpenAI 平台直接 API 访问
/v1/images/generations 端点提供访问。认证设置
- 在 platform.openai.com 创建账号
- 完成组织验证(GPT Image 模型所必需)
- 在控制面板生成 API 密钥
- 在请求头中包含密钥:
Authorization: Bearer YOUR_API_KEY
请求示例 (OpenAI Python SDK)
from openai import OpenAI
client = OpenAI(api_key="your-api-key")
response = client.images.generate(
model="gpt-image-1.5",
prompt="现代极简客厅,带有大窗户和自然采光",
size="1536x1024",
quality="high",
n=1
)
image_url = response.data[0].url图像编辑模式
用于编辑现有图像:
response = client.images.edit(
model="gpt-image-1.5",
image=open("input_image.png", "rb"),
prompt="将墙面颜色改为灰绿色",
size="1024x1024"
)API 对比:EvoLink.AI vs OpenAI Direct
| 功能 | EvoLink.AI | OpenAI Direct |
|---|---|---|
| 模型访问 | gpt-image-1.5-lite | gpt-image-1.5 |
| 处理方式 | 异步(基于任务) | 同步 + 异步选项 |
| 图像输入 | 仅限 URL 为主 | 文件上传 + URL |
| 定价透明度 | 在 EvoLink.AI 控制面板查看 | 公布的 OpenAI 定价 |
| 附加服务 | 与其他 AI API 打包服务 | 仅图像生成 |
| 文档 | evolink.ai 文档 | platform.openai.com/docs |
| 速率限制 | 按计划而异 | 按层级而异(见 OpenAI 文档) |
API 最佳实践
- 实现重试逻辑:高负载期间可能会发生临时失败。
- 缓存成功的生成结果:存储图像 URL 和关联的提示词供未来参考。
- 监控速率限制:两个平台都会根据你的订阅层级施加请求限制。
- 优化提示词模板:创建可重用的提示词结构以获得一致的结果。
- 处理图像过期:在 24 小时窗口内下载并存储图像。
- 策略性使用质量层级:将
high质量留给最终生产渲染以降低成本。
定价结构与成本优化策略
了解成本结构有助于你有效做预算并识别优化机会。
OpenAI 官方定价(截至 2025 年 12 月)
- 图像生成:基于尺寸和质量层级。
- 图像输入(用于编辑):比 GPT Image 1 便宜 20%。
- 图像输出:比 GPT Image 1 便宜 20%。
EvoLink.AI 定价
- 订阅层级(包含不同的 API 调用额度)
- 超出包含额度后的单次请求费用
- 面向企业客户的潜在批量折扣
成本优化策略
1. 质量层级选择
quality 参数显著影响生成时间和成本:低质量 (Low):最快、最便宜(适用于概念测试)
中等质量 (Medium):均衡(适用于大多数应用场景)
高质量 (High):最慢、最贵(生产级资产)
自动质量 (Auto):模型根据提示词复杂度决定low 或 medium 质量,然后将最终选中的方案以 high 质量重新生成。与始终使用 high 相比,这可以降低总成本 40-60%。2. 纵横比优化
更大的图像生成成本更高。成本层级:
1024×1024 (1:1) < 1024×1536 (3:4) = 1536×1024 (4:3)3. 批量处理 vs. 实时处理
对于非紧急工作流:
- 将多个生成请求排队。
- 在非高峰时段处理(如果定价随时间变动)。
- 使用异步处理以避免超时相关的重试。
4. 提示词效率
更长的提示词消耗更多 token。优化技巧:
- 删除不必要的形容词。
- 使用结构化格式(逗号分隔的属性优于长段落)。
- 避免冗余描述。
- 测试最小可行提示词。
示例转换:
低效 (87 token):"我想让你创建一张美丽的、令人惊叹的、
不可思议的专业照片,一个现代智能手机置于干净、
纯净的白色背景上,带有从上方投射的柔和、温和的影棚光"
高效 (28 token):"专业产品照:智能手机,白色
背景,上方投射柔和影棚光"5. 缓存与重用
- 存储成功的生成结果及其元数据(提示词、参数、时间戳)。
- 构建基础图像库用于未来编辑,而非重新生成。
- 在你的图像缓存中实施语义搜索,在生成新图像前先查找现有资产。
6. 混合工作流
将 AI 生成与传统工具结合:
- 使用 AI 生成基础图像。
- 在 Figma/Photoshop 中添加复杂的文字/徽标(避开 AI 的文字限制)。
- 针对已证明设计有效的方案利用 AI 生成变体,而非从头开始。
- 纯 AI 工作流:10 次迭代 × $0.XX 每张图 = 总计 $X.XX
- 混合工作流:3 次 AI 迭代 + 手动精修 = $X.XX + 设计工时
- 如果设计工时快于 7 次 AI 迭代,混合方法能省钱。
企业批量折扣
- 每月 10,000+ 张图像。
- 每月 $1,000+ API 支出。
- 多年期承诺协议。
真实世界用例与应用
了解不同行业如何应用 GPT Image 1.5 可明确其实际价值。
电商产品目录
- 在自然背景中拍摄一次产品。
- 使用图生图模式在不同环境中生成变体。
- 细节保留确保产品外观保持一致。
- 徽标和品牌在所有变体中保持完好。
营销与品牌资产
- 使用品牌颜色和风格生成基础设计。
- 进行编辑迭代,同时保留徽标和视觉身份。
- 快速创建 A/B 测试变体。
- 为不同市场制作本地化版本。
社交媒体内容生产
- 以所需的最大尺寸生成主图。
- 创建平台特定的裁剪/变体。
- 应用风格滤镜以符合频道审美。
- 添加文字叠加(或利用 AI 文字渲染生成标题)。
- Instagram (1:1):1024×1024
- Instagram Stories (3:4):1024×1536
- Twitter/X (4:3):1536×1024
- 所有图像均通过更改尺寸参数从单个提示词生成。
设计概念可视化
- 快速原型化视觉概念。
- 测试多个风格方向。
- 收集对各选项的反馈。
- 将获胜方向精修至生产质量。
社论与出版
- 为抽象主题生成概念性插图。
- 创建带有可读文字标签的数据可视化。
- 制作带有标题的杂志式排版。
- 在文章系列中开发连贯的视觉主题。
培训与教学材料
- 生成基于场景的插图(工作场所情况、安全演示)。
- 创建简化的示意图和流程图。
- 在教学材料中实现多元化的呈现。
- 针对特定学习语境开发定制化视觉效果。
房地产与建筑
- 根据毛坯房照片生成软装后的室内效果。
- 可视化翻新概念。
- 为物业营销创建生活方式图像。
- 为客户选择开发多个设计风格选项。
提升效果的高级提示词工程
掌握提示词结构可显著提高输出质量并减少迭代浪费。
有效提示词的剖析
高性能提示词遵循以下结构:
[主体/对象] + [动作/姿势] + [场景/语境] + [风格/审美] +
[技术参数] + [构图规则]主体:穿海军蓝西装的专业商务女性
动作:自信直立,双臂交叉
场景:现代玻璃办公室,窗外可见城市天际线
风格:企业专业摄影审美
技术:浅景深,左侧自然窗光
构图:主体置于画框右侧三分之一,左侧留白常见场景的提示词公式
产品摄影
"Professional product photo of [PRODUCT] on [BACKGROUND],
[LIGHTING STYLE], [CAMERA ANGLE], [MOOD], high-end commercial quality"示例:"Professional product photo of luxury watch on black marble surface, dramatic side lighting with soft shadows, 45-degree angle, elegant and premium mood, high-end commercial quality"
肖像摄影
"[SHOT TYPE] portrait of [SUBJECT DESCRIPTION], [EXPRESSION],
[CLOTHING], [BACKGROUND], [LIGHTING], [CAMERA SETTINGS STYLE]"示例:"Close-up portrait of middle-aged woman with short gray hair, genuine smile, wearing casual denim jacket, blurred outdoor background, golden hour natural lighting, shallow depth of field"
生活方式场景
"[TIME OF DAY] scene showing [ACTIVITY] in [LOCATION],
[MOOD/ATMOSPHERE], [PEOPLE DESCRIPTION], [STYLE REFERENCE]"示例:"Morning scene showing family breakfast in modern Scandinavian kitchen, warm and inviting atmosphere, diverse family of four, natural lifestyle photography style"
信息图/数据可视化
"Clean infographic showing [DATA/CONCEPT], [LAYOUT STYLE],
[COLOR SCHEME], [TEXT ELEMENTS], professional design quality"示例:"Clean infographic showing quarterly sales growth, vertical bar chart layout, blue and white color scheme, bold headline '2025 Q4 Results' at top with percentage labels, professional business design quality"
负面提示策略
虽然 GPT Image 1.5 不像 Stable Diffusion 那样正式支持负面提示词,但你可以通过正面表述来引导避开不需要的元素:
要用:"干净、极简的背景"
要用:"自然、真实的采光"
要用:"写真级、专业摄影风格"
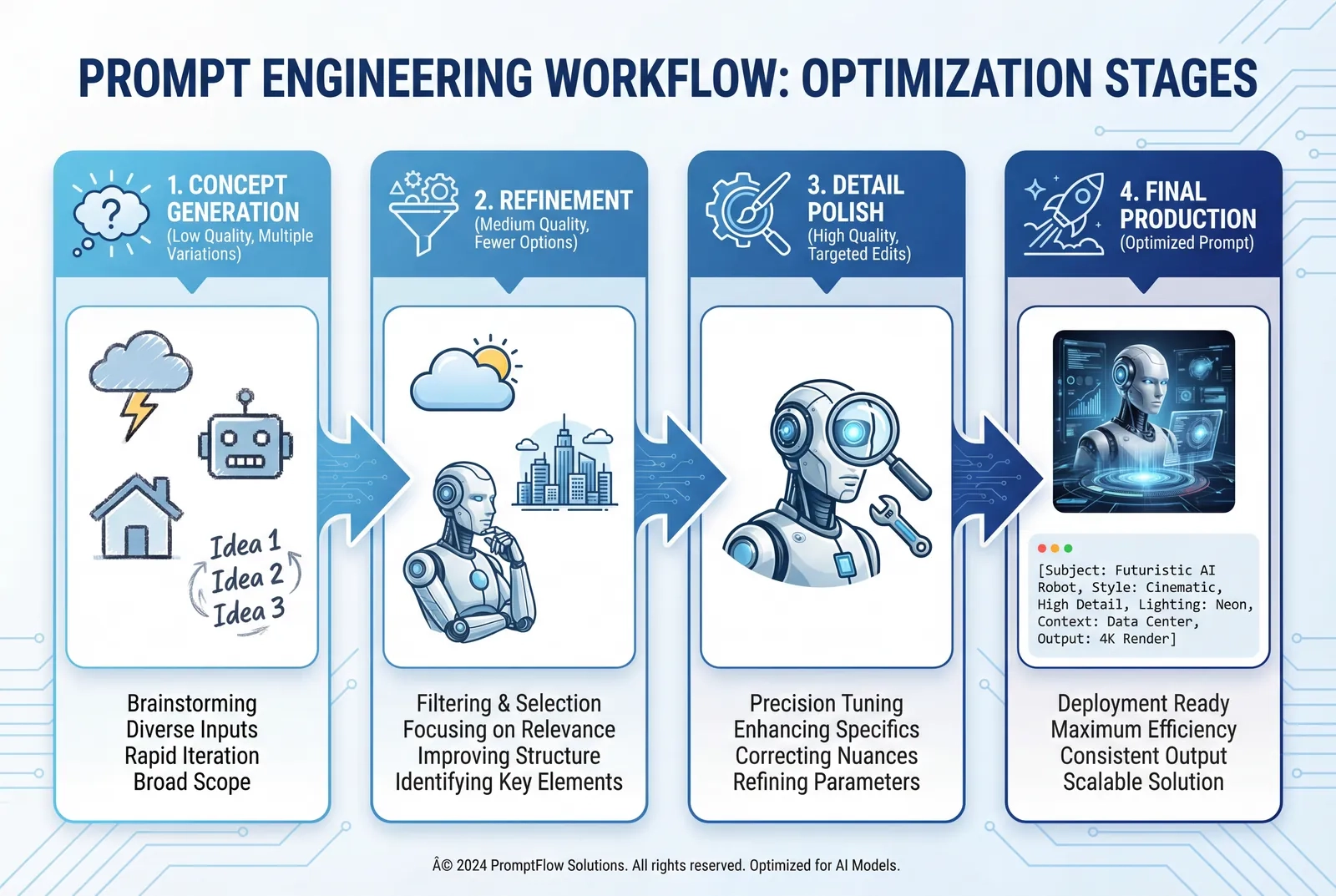
多步精修工作流
对于需要高品质的复杂项目:
- 初始概念生成(低质量,宽泛提示词)
- 生成 3-5 个变体。
- 确定有前途的方向。
- 细化迭代(中等质量,详细提示词)
- 在获胜概念中添加具体约束条件。
- 调整构图、光影、元素。
- 测试 2-3 个变体。
- 细节打磨(高质量,精准编辑提示词)
- 对接近最终的版本进行针对性编辑。
- 每次只调整一个具体元素。
- 保留除更改项之外的所有内容。
- 最终生产(高质量)
- 结合所有习得经验,使用优化后的提示词重新生成。
- 以全分辨率导出。
提示词库与版本控制
维护一个结构化的提示词库:
项目:2025 节日营销活动
版本:1.0
日期:2025 年 12 月
基础提示词模板:
"节日场景展示 [主体], 温暖舒适的氛围,
金色采光, 专业摄影, [特定元素]"
迭代记录:
V1.0:初始概念 → 添加了 "浅景深"
V1.1:客户反馈 → 将 "温暖舒适" 改为 "亮丽欢快"
V1.2:最终版 → 添加了 "红金配色点缀"
获胜提示词:[最终优化的版本]
生成的图像:[保存结果的链接]这种记录方式可防止重复摸索已成功的 formula,并赋能团队协作。
使用 GPT Image 1.5 时要避免的常见错误
从常见的陷阱中学习可加速你的掌握过程并防止无效劳动。
1. 模糊、缺乏结构的提示词
2. 期待第一次尝试就有完美文字
3. 忽视质量层级的影响
high 质量,包括早期的概念测试。low 或 medium 质量已足够的探索阶段造成不必要的成本和时间浪费。4. 超出模型极限的过度编辑
5. 不保留成功的提示词
6. 图像参考准备不足
- 高分辨率(长边至少 1024px)
- 光照良好且主体清晰
- 构图简洁,没有干扰元素
- 格式正确(.jpg, .png, .webp)
7. 期待建筑/技术层面的精确性
8. 忽视图像过期时限
9. 跨项目提示词结构不一致
10. 不测试竞争模型
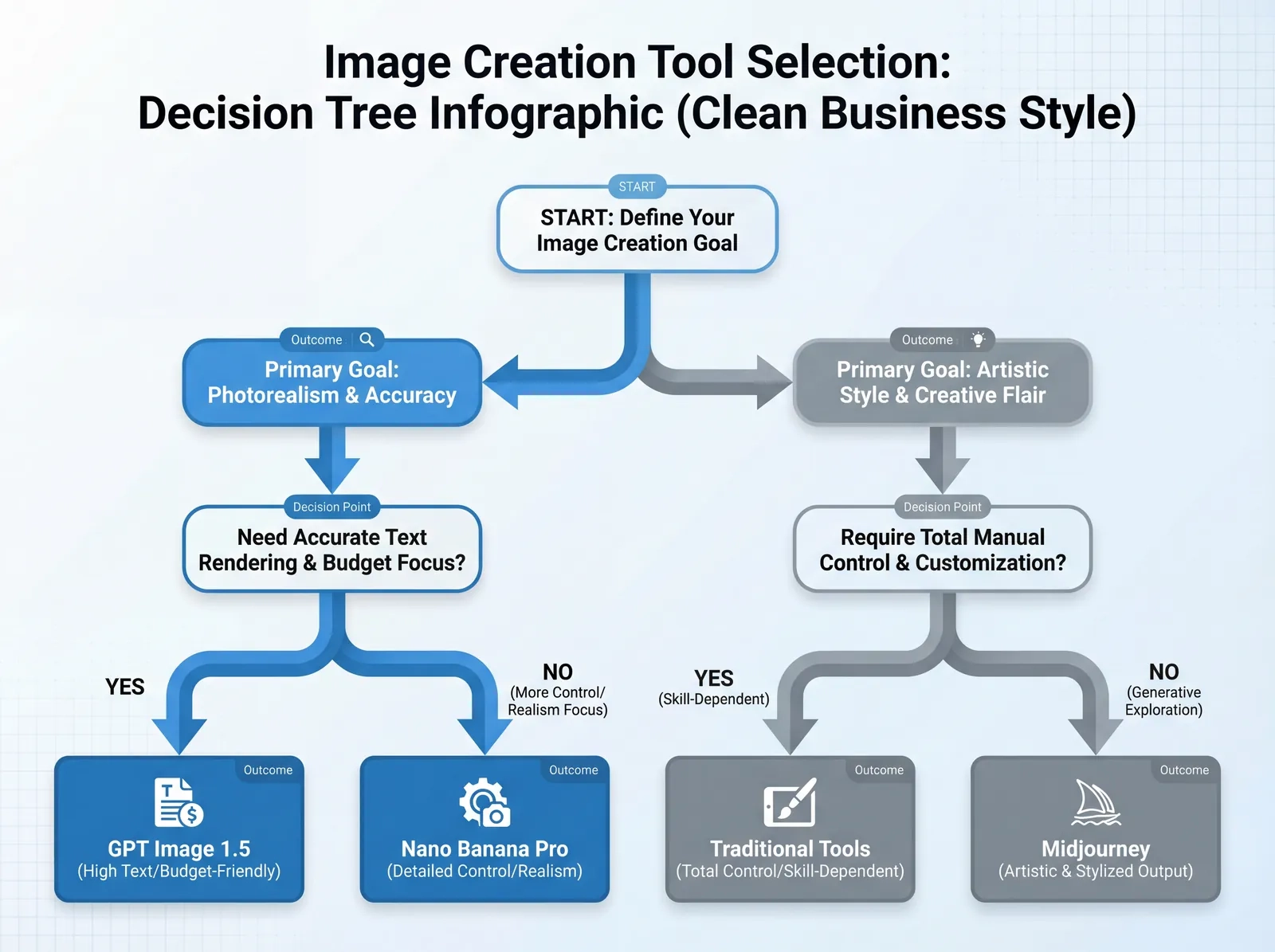
局限性及何时选择替代工具
GPT Image 1.5 代表了重大进步,但并非在所有方面都是最优的。了解其边界有助于你做出明智的工具选择。
技术局限性
- 复杂场景的连贯性
- 包含 10 个以上独立物体的图像常显示出空间不一致。
- 重叠的透明元素(玻璃、水)会产生伪影。
- 多人场景在人群的解剖准确性上表现挣扎。
- 影响严重的场景:大型合照、复杂产品陈列、精细插图。
- 摄影写实上限
- 部分输出仍展现出“AI 感”(过度平滑、不自然的完美)。
- 皮肤纹理和毛孔细节有时显得虚假。
- 某些光照场景(正午强光、复杂反射)仍然具有挑战性。
- 影响严重的场景:高端时尚摄影、纪实作品、写实肖像。
- 文字渲染边界
- 超过 20-30 词的正文会出现错误。
- 非拉丁脚本不可靠。
- 艺术字体和手写体不一致。
- 曲面上的文字会变形。
- 影响严重的场景:带有大量文字的信息图、多语言内容、装饰性排版。
- 文化与地域特异性
- 训练数据向西方背景倾斜。[未验证——推断自输出分析]
- 地域性建筑、服饰和文化细节可能缺乏真实性。
- 小众亚文化和专业化语境呈现不足。
- 影响严重的场景:具有特定文化背景的营销、地区性活动、真实代表性要求。
- 迭代深度限制
- 质量在 6-8 次连续编辑后退化。
- 伪影随编辑次数叠加。
- 人脸和徽标一致性随过度迭代而降低。
- 影响严重的场景:需要 10 次以上细节打磨的项目、大规模协作编辑。
何时选择替代工具
在以下情况选择 Nano Banana Pro:
- 照片写实感是首要要求。
- 社交媒体内容需要当代审美趋势。
- 自然场景(风景、人群、活动)占主导。
- 团队入职更看重采用速度和生态系统增长。
在以下情况选择 Midjourney:
- 艺术诠释比字面准确更有价值。
- 概念性、抽象或艺术化的风格符合你的品牌。
- 社区驱动的提示词库和风格有益于你的工作流。
- 创意愿景比生产控制更重要。
在以下情况选择 Stable Diffusion:
- 你需要对模型训练和自定义拥有完全控制。
- 预算约束要求免费/开源方案。
- 技术团队能管理自托管和优化。
- 需要针对垂直领域进行专门的微调。
在以下情况选择传统摄影/设计:
- 技术精度不可逾越(建筑、工程、医疗)。
- 法律要求必须经过认证的人工创作内容。
- 品牌价值观强调人工技艺而非 AI 辅助。
- 预算允许专业服务且质量能证明该成本的合理性。
在以下情况选择混合工作流:
- 项目既需要 AI 效率又需要人工质控。
- 文字元素超出 AI 能力。
- 品牌指南要求绝对的一致性。
- 合规性与真实性验证至关重要。
伦理与法律考虑
常见问题解答 (FAQs)
1. 相比聘请设计师,GPT Image 1.5 的成本是多少?
然而,设计师提供创意指导、品牌理解和 AI 无法匹敌的技术精度。对许多企业而言,最佳方法是混合模式:将 AI 用于高通量、低风险内容(社交媒体、概念测试、素材图风格图像),同时为旗舰活动、定义品牌的工作以及需要人类创意愿景的项目预留设计师时间。
2. GPT Image 1.5 能在多张图像中保持一致的角色形象吗?
- 生成带有详细描述的初始角色图像。
- 将此图存为你的角色参考图。
- 在后续生成中使用图生图模式并附带该参考。
- 提供一致的、描述该角色的提示词结构。
- 接受会有微小差异——跨全新生成的完美一致性尚不可靠。
对于需要绝对角色一致性的项目(动画系列、品牌吉祥物、持续营销活动),考虑使用 AI 生成初始概念,然后由插画师创建一个确定的规格模型表(Model Sheet),供未来所有工作参考。
3. GPT Image 1.5 支持除英语以外的语言吗?
- 西班牙语、法语、德语、意大利语:通常可用,但准确性相比英语有所下降。
- CJK 语言(中日韩):提示词理解力存在,但图像中的文字渲染仍然不可靠。
- 其他语言:可用测试数据有限。[未验证]
4. GPT Image 1.5 如何处理生成图像中的版权和知识产权?
- 第三方 IP:模型设计为拒绝生成基于受版权保护角色、注册徽标或可辨认名人肖像的内容。
- 训练数据:模型在公开可用的图像上训练,这可能包含了在合理使用原则下用于训练目的的版权材料。
- 商业用途:输出通常可商业化,但请审阅 OpenAI 的当前条款及你的具体用例。
- 归属:OpenAI 不要求对 AI 生成图像进行署名,但部分平台和语境可能要求披露内容是由 AI 生成。
5. 我可以使用 GPT Image 1.5 编辑我自己拥有的现有照片吗?
- 上传你自己的照片。
- 通过自然语言提示词请求特定修改。
- 在更改指定特征的同时保留原始元素。
- 基于你现有影像生成变体。
- 原照质量高(至少 1024px)。
- 光照良好且主体清晰可见。
- 背景不过于复杂。
- 你的编辑请求具体且目标明确。
6. GPT Image 1.5 和 GPT Image 1.5 Lite 有什么区别?
gpt-image-1.5-lite) 是 evolink.ai 等平台使用的 API 模型名称。根据现有文档,“Lite”指的是 API 端点名称,而非表示一个缩减能力版本。通过该端点访问的模型似乎与 ChatGPT 中可用的旗舰 GPT Image 1.5 模型相同。某些平台可能会提供其他的质量层级或参数选项并描述为“精简版” vs “完整版”,但 OpenAI 官方模型名称就是 “GPT Image 1.5”。如果是平台实现之间存在成本或能力差异,请查阅你特定 API 提供商的文档以获取说明。
7. 生成的图像 URL 有效期多久,我该如何存储图像?
- 立即下载:在你的工作流中设置自动下载,以便在生成后立即截取图像。
- 云存储:上传到你自己的 S3、Google Cloud Storage 或类似服务进行永久存档。
- 元数据保留:为每张图存储关联提示词、参数和生成时间戳供未来参考。
- 命名规范:使用描述性的、可搜索的、包含项目标识符和版本号的文件名。
- 备份策略:为关键业务资产维护冗余副本。
- 生成图像 → 获取临时 URL。
- 在 1 小时内下载图像至本地/云端存储。
- 在你的数据库中存储永久 URL。
- 从你的记录中删除临时 OpenAI URL。
- 今后引用你的永久存储 URL。
8. GPT Image 1.5 能生成适合印刷的图像吗,还是仅限数字用途?
- 1024×1024 像素(正方形)
- 1024×1536 像素(纵向)
- 1536×1024 像素(横向)
| 印刷尺寸 | 所需 DPI | 适合的分辨率 | GPT Image 1.5 可用吗? |
|---|---|---|---|
| 社交媒体 | 72 DPI | 1200×1200 | ✓ 是 |
| 网站 Hero 图 | 72-96 DPI | 1920×1080 | ✓ 是 |
| 演示幻灯片 | 96-150 DPI | 1920×1080 | ✓ 是 |
| 名片 | 300 DPI | 1050×600 | ⚠️ 凑合 |
| 8×10" 照片冲印 | 300 DPI | 2400×3000 | ✗ 否 |
| 杂志整页 | 300 DPI | 2550×3300 | ✗ 否 |
| 广告牌 | 150 DPI+ | 14400×4800+ | ✗ 否 |
- AI 无损放大:使用专业的放大工具 (Topaz Gigapixel, Real-ESRGAN) 在生成后增加分辨率。
- 印刷尺寸限制:仅将 AI 生成图像用于较小的印刷元素(图标、小插画)而非满版页面。
- 数字优先策略:将 AI 生成优先用于数字渠道,而为印刷活动委托传统摄影/插画。
- 矢量转换:对于徽标和简单图形,将 AI 输出转换为矢量格式以实现分辨率无关性。
9. 对于专业设计工作,GPT Image 1.5 比 Midjourney 更好吗?
- 你需要对迭代编辑拥有精确控制。
- 与 ChatGPT 的工作流集成能让你的团队获益。
- 图像中的文字渲染很重要。
- 需要 API 自动化。
- 徽标和品牌元素保留至关重要。
- 速度(快 4 倍)能证明稍微牺牲艺术质量是值得的。
- 企业级功能和支持是优先项。
- 艺术诠释能增强你的作品。
- 审美质量是核心考量。
- 社区提示词库和风格与你的品牌契合。
- 你正在创作概念艺术、插画或创意活动素材。
- 基于 Discord 的工作流符合你的团队结构。
- 需要高性价比方案。
- 使用 Midjourney 生成主形象图、Hero 横幅和旗舰创意。
- 使用 GPT Image 1.5 生成产品变体、社交垂直内容和迭代性的客户汇报稿。
- 使用传统设计进行最终打磨和技术要求实现。
10. 既然 1.5 已经推出,GPT Image 1 会怎样?
- 卓越的性能(生成快 4 倍)。
- 更好的指令遵循。
- 增强的编辑精度。
- 输入和输出成本降低 20%。
- 持续的开发和改进。


