
Claude Opus 4.6 Enterprise Deployment Guide
Claude Opus 4.6: Production-Ready Enterprise AI

TL;DR (For Busy CTOs / Tech Leads)
If you're integrating Opus 4.6 into a B2B product, "impressive demo responses" don't equal production-ready. The deployment bar typically involves 5 things:
- Reliability: Does output drift with identical inputs? Does quality degrade under load?
- Controllability: Can you constrain format, refusals, uncertainty, citations, and sensitive content?
- Observability: Can you trace and reproduce prompts, evidence, tool calls, latency, and costs?
- Rollback capability: Can you one-click downgrade models, prompts, or retrieval strategies?
- Security & Compliance: Can you block PII, injection attacks, and unauthorized tool calls?
1. Fact Card (Officially Verifiable)
1.1 Model & Availability
| Item | Details |
|---|---|
| Model Name | Claude Opus 4.6 |
| API Model ID | claude-opus-4-6 |
| 1M Context Beta Platforms | Claude API, Microsoft Foundry, Amazon Bedrock, Google Vertex AI |
Note: Beta features require tier eligibility—see below.
1.2 Context & Output
- Standard context: 200K tokens
- 1M tokens context (Beta): Requires beta header
context-1m-2025-08-07and typically Usage Tier 4 or custom limits - Output limit: 128K output tokens (use streaming for large
max_tokensto avoid HTTP timeouts)
1.3 Pricing (Key: Long Context Triggers Premium)
| Scenario | Input Price | Output Price |
|---|---|---|
| ≤ 200K input | $5 / MTok | $25 / MTok |
| > 200K input (Premium) | $10 / MTok | $37.50 / MTok |
Note: Once input exceeds 200K, all tokens in that request are billed at Premium rates. Factor this explicitly into cost estimates.
1.4 Critical API / Behavior Changes (Migration Must-Read)
- Adaptive thinking recommended:
thinking: {type: "adaptive"} - Effort (4 levels):
low / medium / high (default) / max - Compaction API (Beta): Server-side automatic context compression, beta header
compact-2026-01-12 - Breaking change: Prefill disabled: Assistant prefill in the last message returns 400 on Opus 4.6
output_formatmigrated tooutput_config.format- Tool call parameter JSON escaping may differ slightly from older models: use standard JSON parsers (
JSON.parse/json.loads), not manual string parsing
2. Why Enterprises Feel 4.6 Is "More Production-Ready"
2.1 1M Context (Beta): Not a Gimmick, But a Breakthrough in Available Information

The highest-value enterprise tasks aren't "write pretty copy"—they're:
- Reading piles of materials (contracts, policies, tickets, code, reports)
- Finding key evidence (with citations)
- Turning evidence into actionable conclusions (auditable, reversible)
Long context makes "fitting more raw materials into one pipeline" possible. But you still need to:
- Filter by permissions (ACL): Do this at retrieval, not via prompts
- Cite evidence: Outputs must include
chunk_id/doc_id - Manage costs & limits: >200K triggers Premium + dedicated rate limits (don't get surprised in production)
2.2 Compaction (Beta): Turn "Must-Break" Long Tasks into "Can-Continue"
Many agentic workflows "blow up" around 200K. Compaction's value: when context approaches the threshold, the API automatically generates compressed summaries and continues, enabling sustainable long-running tasks.
Note: With Compaction enabled, track costs viausage.iterations(include compression iterations), or you'll underestimate actual token consumption.
2.3 Agent Teams (Claude Code): Native Parallel Exploration

Practical advice: Before production, treat Agent Teams as an "accelerator" not "full automation"—pair with permissions and auditing to contain blast radius.
2.4 Adaptive Thinking + Effort: Tunable "Intelligence/Speed/Cost" Knobs
In enterprise settings, many tasks don't need "full-power reasoning":
- Customer routing, light classification, field extraction: low/medium is often cheaper and faster
- Complex diagnostics, long document synthesis, code migration: high/max delivers more stable quality
Treat Effort as a unified "cost-quality" dial, layer on schema validation, and you'll achieve more stable SLAs.
3. Enterprise Integration & Availability
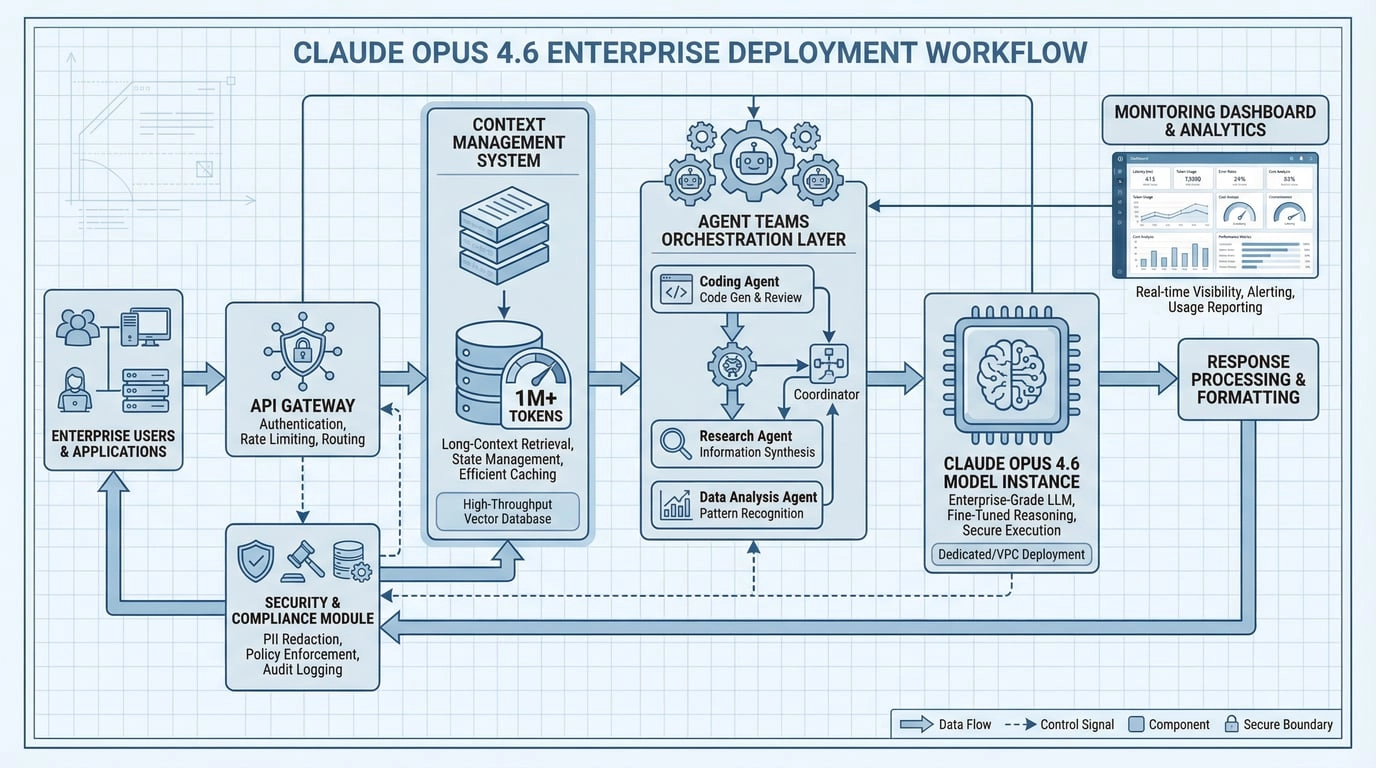
3.1 Platform Side
- Claude API: For product embedding and backend workflows
- Microsoft Foundry / Bedrock / Vertex AI: For enterprise cloud governance and compliance
- GitHub Copilot: Opus 4.6 is rolling out in the Copilot ecosystem
3.2 Office Tools (Closer to "Enterprise Daily Life")
- Claude in Excel: Reads current workbook cells, formulas, and tab structures to assist (great for data cleaning, model validation, report interpretation)
- Claude in PowerPoint (Research Preview): Generates or edits slides within existing templates (great for "making enterprise templates look more enterprise")
Reminder: Office capabilities typically require specific plans or preview access; suitable for "efficiency boost" scenarios—critical outputs should still be human-reviewed.
4. Migration & Deployment: 4 "Don't Crash" Hard Rules
- Stop using Assistant Prefill: Opus 4.6 returns 400. Use System instructions, Structured Outputs, or
output_config.formatinstead - Migrate all output_format to output_config.format: Future API versions will deprecate the old format
- Use only standard JSON parsers for tool call parameters: No manual string parsing
- Always stream large outputs: Large
max_tokenswithout streaming is more prone to timeouts
5. Copy-Paste Templates
5.1 1M Context (Beta) Call Example
curl https://api.anthropic.com/v1/messages \
-H "x-api-key: $ANTHROPIC_API_KEY" \
-H "anthropic-version: 2023-06-01" \
-H "anthropic-beta: context-1m-2025-08-07" \
-H "content-type: application/json" \
-d '{
"model": "claude-opus-4-6",
"max_tokens": 1024,
"messages": [{"role":"user","content":"Process this large document..."}]
}'5.2 Adaptive Thinking + Effort (Python)
import anthropic
client = anthropic.Anthropic()
resp = client.messages.create(
model="claude-opus-4-6",
max_tokens=4096,
thinking={"type": "adaptive"},
output_config={"effort": "medium"},
messages=[{
"role": "user",
"content": "Summarize the risks in this contract clause..."
}],
)
print(resp.content[0].text)5.3 Structured Outputs (JSON Schema) + Evidence Gate
resp = client.messages.create(
model="claude-opus-4-6",
max_tokens=2048,
thinking={"type": "adaptive"},
output_config={
"effort": "medium",
"format": {
"type": "json_schema",
"schema": {
"name": "kb_answer",
"schema": {
"type": "object",
"properties": {
"answer": {"type": "string"},
"evidence": {"type": "array", "items": {"type": "string"}},
"uncertainties": {"type": "array", "items": {"type": "string"}}
},
"required": ["answer", "evidence"]
}
}
}
},
messages=[{
"role": "user",
"content": """Only answer based on EVIDENCE blocks. Cite evidence IDs.
<evidence>
[#a1] Revenue grew 15% YoY in Q3 2025...
[#b7] Customer churn rate increased to 8.2%...
</evidence>
Question: What are the key business risks?"""
}],
)
print(resp.content[0].text) # JSON string (validate before downstream use)5.4 Compaction (Beta) Enable Example
curl https://api.anthropic.com/v1/messages \
--header "x-api-key: $ANTHROPIC_API_KEY" \
--header "anthropic-version: 2023-06-01" \
--header "anthropic-beta: compact-2026-01-12" \
--header "content-type: application/json" \
--data '{
"model": "claude-opus-4-6",
"max_tokens": 4096,
"messages": [{"role":"user","content":"Help me build a website"}],
"context_management": {
"edits": [{"type":"compact_20260112"}]
}
}'5.5 Agent Teams (Claude Code) Setup
{
"env": {
"CLAUDE_CODE_EXPERIMENTAL_AGENT_TEAMS": "1"
}
}Once enabled, use natural language in Claude Code:
- "Create an agent team with roles A/B/C to review this codebase…"
- "Lead agent synthesizes findings; teammates focus on security/perf/tests…"
6. Cost Estimation & Limit Governance
6.1 Typical Scenario Cost Comparison
| Scenario | Input Tokens | Output Tokens | Cost (Standard) | Cost (Premium >200K) |
|---|---|---|---|---|
| Short doc summary | 5K | 500 | $0.04 | - |
| Medium code review | 50K | 2K | $0.30 | - |
| Long doc analysis | 150K | 3K | $0.83 | - |
| Extended context | 500K | 5K | - | $5.19 |
| Agent Teams (3 rounds) | 200K × 3 | 10K | $3.25 | - |
Note: Agent Teams spawn multiple parallel sessions. Total token consumption = Lead + Teammates combined; if single-round input exceeds 200K, Premium may trigger.
6.2 Limit Governance Recommendations
- Set independent rate limits per Effort level: high/max has lower volume but higher cost—monitor separately
- Require explicit approval for >200K input: Avoid accidental Premium billing
- Reserve 2-3x buffer for Compaction scenarios: Compression iterations increase actual consumption
- Test Agent Teams in sandbox first: Parallelism × context may exceed expectations
7. Security & Compliance
7.1 Security Configuration Example
security_config = {
"content_filtering": {
"hate_speech": "strict",
"violence": "strict",
"sexual_content": "strict",
"self_harm": "strict"
},
"output_validation": {
"check_for_pii": True,
"check_for_credentials": True,
"check_for_malicious_code": True
},
"audit_logging": {
"enabled": True,
"log_level": "detailed",
"retention_days": 90
}
}7.2 Enterprise Checklist
- PII filtering: Scan both input and output for sensitive information
- Tool call whitelist: Only allow predefined function calls
- Output format validation: Enforce constraints via JSON Schema
- Evidence traceability: Every conclusion must trace back to source documents
- Audit logging: Record all API calls, input summaries, output summaries
- Downgrade switch: One-click rollback to older models or lower Effort
- Cost circuit breaker: Auto-stop when per-user/per-task limits exceeded
8. Performance Benchmarks (Official Data)
| Benchmark | Claude Opus 4.6 Score | Description |
|---|---|---|
| Terminal-Bench 2.0 | 65.4% | Agentic programming evaluation (highest ever) |
| GDPval-AA | 1606 Elo | Finance and legal professional tasks |
| BigLaw Bench | 90.2% | Legal reasoning capability |
| BrowseComp | Industry #1 | Web information retrieval |
Source: Anthropic official release
9. Conclusion: Treat Opus 4.6 as a "System Component," Not a "Magic Input Box"
Opus 4.6's real value isn't "better at chatting"—it's being more suitable for engineering:
- Long context + Compaction makes long tasks sustainable
- Agent Teams makes parallel collaboration native
- Adaptive Thinking + Effort makes cost/quality controllable
Layer on Schema, evidence gates, auditing, and rollback—that's the path to enterprise production.
Quick Start
References (Official / Primary Sources)
- Anthropic: Introducing Claude Opus 4.6
- Claude API Docs: What's new in Claude 4.6
- Claude API Docs: Context windows
- Claude API Docs: Pricing
- Claude API Docs: Compaction
- Claude Code Docs: Agent Teams
- Microsoft Azure Blog: Claude Opus 4.6 on Foundry


