
Why LLM APIs Are Not Standardized

The LLM API Fragmentation Problem (and Why "OpenAI-Compatible" Is Not Enough)
If you're searching for why LLM APIs are not standardized, you're probably already experiencing the pain.
Despite the rapid rise of so-called "OpenAI-compatible" APIs, real-world LLM integrations still break in subtle but expensive ways—especially once you move beyond simple text generation.
This guide explains:
- what the LLM API fragmentation problem actually is
- why OpenAI-compatible APIs are not enough in production
- and how teams in 2026 design systems that survive constant model churn
TL;DR (Too Long; Didn't Read)
- LLM APIs are not standardized because providers optimize for different capabilities, not compatibility.
- "OpenAI-compatible" usually means request-shape compatible, not behavior-compatible.
- Fragmentation shows up most clearly in tool calling, reasoning token accounting, streaming, and error handling.
- Instead of waiting for standards, teams normalize API behavior behind a dedicated gateway layer.
What Is the LLM API Fragmentation Problem?
LLM API fragmentation occurs when different language-model providers expose APIs that look similar but behave differently under real workloads.
Even when APIs share:
- similar endpoints
- similar JSON request schemas
- similar parameter names
they often diverge in:
- tool-calling semantics
- reasoning / thinking token accounting
- streaming behavior
- error codes and retry signals
- structured output guarantees
Over time, application logic fills with provider-specific exceptions.
Why LLM APIs Are Not Standardized
1. Providers Optimize for Different Primitives
Modern LLMs are no longer simple text-in / text-out systems.
Different providers prioritize different primitives:
- reasoning depth vs latency
- long-context retrieval vs throughput
- native multimodality (image, video, audio)
- safety and policy enforcement
A single rigid standard would either:
- hide advanced capabilities
- or slow innovation to the lowest common denominator
Neither outcome is realistic in a competitive market.
2. "OpenAI-Compatible" Only Covers the Happy Path
Most "OpenAI-compatible" APIs are designed to pass a basic smoke test:
client.chat.completions.create(
model="model-name",
messages=[{"role": "user", "content": "Hello"}]
)This works for demos—but production systems depend on much more than this.
Why "OpenAI-Compatible" Is Not Enough in 2026
The real breakage appears when you depend on behavior, not just syntax.
🔽 Table: Why "OpenAI-Compatible" APIs Break in Production
| Dimension | What "OpenAI-Compatible" Promises | What Often Happens in Production |
|---|---|---|
| Request Shape | Similar JSON schema (messages, model, tools) | Edge parameters silently ignored or reinterpreted |
| Tool Calling | Compatible function definitions | Tool calls returned in different locations or shapes |
| Tool Arguments | JSON string that can be parsed reliably | Flattened, stringified, or partially dropped arguments |
| Reasoning Tokens | Transparent usage reporting | Inconsistent token accounting and billing semantics |
| Structured Outputs | Valid JSON responses | "Best-effort" JSON that breaks schema guarantees |
| Streaming | Stable delta chunks | Inconsistent chunk order or missing finish signals |
| Error Handling | Clear rate-limit and retry signals | 500 errors, ambiguous failures, or silent timeouts |
| Migration | Easy provider switching | Prompt rewrites and glue-code proliferation |
These differences rarely appear in demos. They surface only under real load, complex tool usage, or cost-sensitive production systems.
Example 1: Tool Calling Looks Similar — But Breaks on Semantics
OpenAI-style expectation (simplified):
{
"tool_calls": [{
"id": "call_1",
"type": "function",
"function": {
"name": "search",
"arguments": "{\"query\":\"LLM API fragmentation\",\"filters\":{\"year\":2026}}"
}
}]
}Common "compatible" reality:
{
"tool_call": {
"name": "search",
"arguments": "{\"query\":\"LLM API fragmentation\"}"
}
}Both responses may be "successful." They are not behaviorally compatible once your application depends on nested arguments, arrays of tool calls, or stable response paths.
Example 2: Reasoning Tokens — A 2026 Pain Point
Reasoning-focused models introduce additional reasoning / thinking tokens.
Even with "OpenAI-compatible" APIs, fragmentation appears in:
- token accounting (how reasoning tokens are counted and priced)
- usage reporting (where reasoning tokens appear)
- control knobs (different names and semantics for reasoning effort)
- observability (difficulty comparing cost across providers)
The result:
- cost dashboards drift
- evaluation baselines break
- cross-provider optimization becomes unreliable
Reasoning behavior may be comparable—but reasoning accounting rarely is.
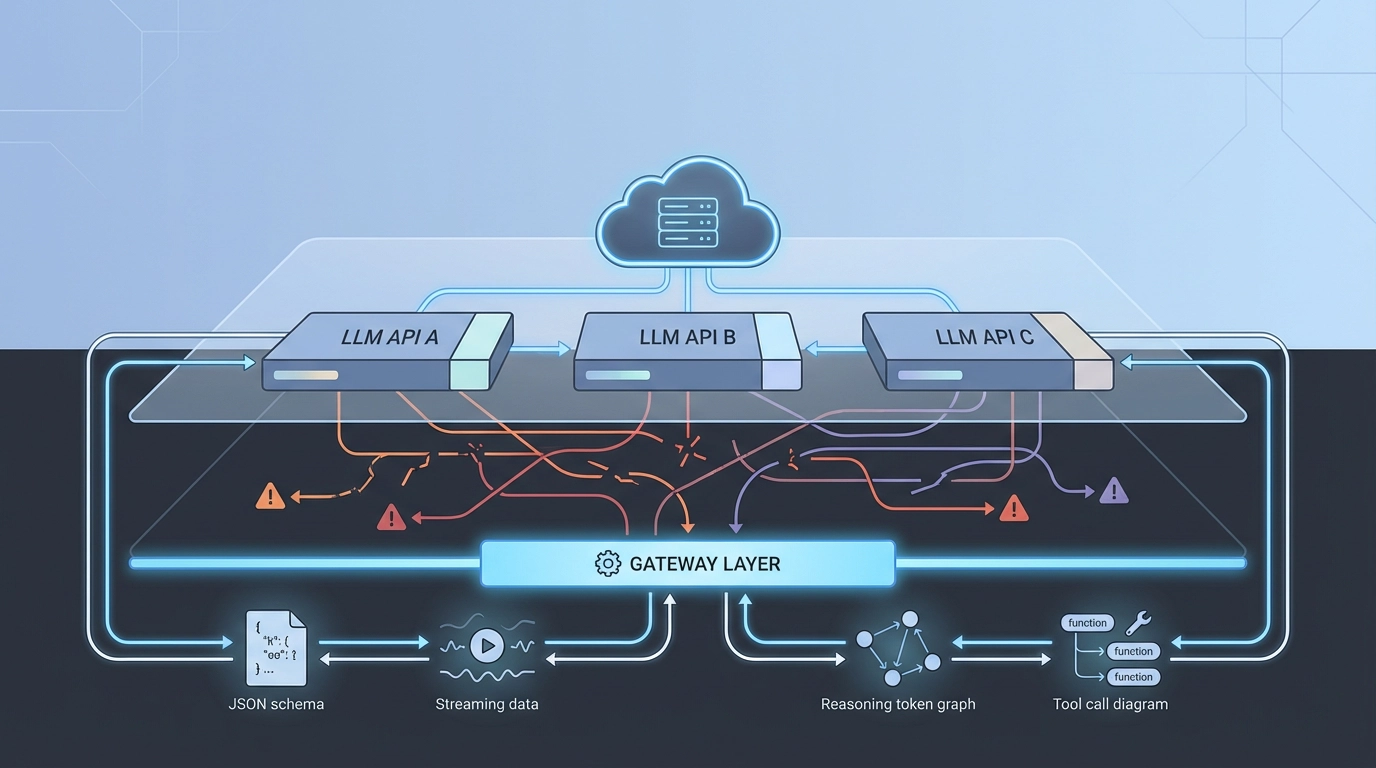
The Hidden Cost of LLM API Fragmentation
1. Glue Code Accumulates Quietly
def get_reasoning_usage(resp: dict) -> int | None:
details = resp.get("usage", {}).get("output_tokens_details", {})
if "reasoning_tokens" in details:
return details["reasoning_tokens"]
if "reasoning_tokens" in resp.get("usage", {}):
return resp["usage"]["reasoning_tokens"]
return NoneThis pattern repeats across tools, retries, streaming, and usage tracking.
Glue code does not ship features. It only prevents breakage.
2. Migrating Between LLM Providers Is Harder Than Expected
What teams expect:
"We'll just switch models later."
What actually happens:
- prompt drift
- incompatible tool schemas
- different rate-limit semantics
- mismatched usage metrics
3. Multimodal APIs Multiply Fragmentation
Beyond text:
- video APIs differ in duration units and safety rules
- image APIs vary in mask formats and references
There is no shared multimodal contract today.
Why Teams Try (and Struggle) to Build Their Own Wrapper
Initially, a custom abstraction feels reasonable.
Over time, it becomes:
- a second product
- a maintenance burden
- a bottleneck for experimentation
Many teams independently rediscover the same conclusion.
A Practical Standardization Checklist
Before trusting any "compatible" API or internal wrapper, ask:
- Are tool calls behavior-compatible or schema-only?
- Are reasoning tokens exposed consistently?
- Can usage be compared across providers?
- Are error codes normalized?
- Is streaming stable under load?
- Can providers be switched without rewriting prompts?
- Can traffic be rerouted dynamically?
From Standardization to Normalization
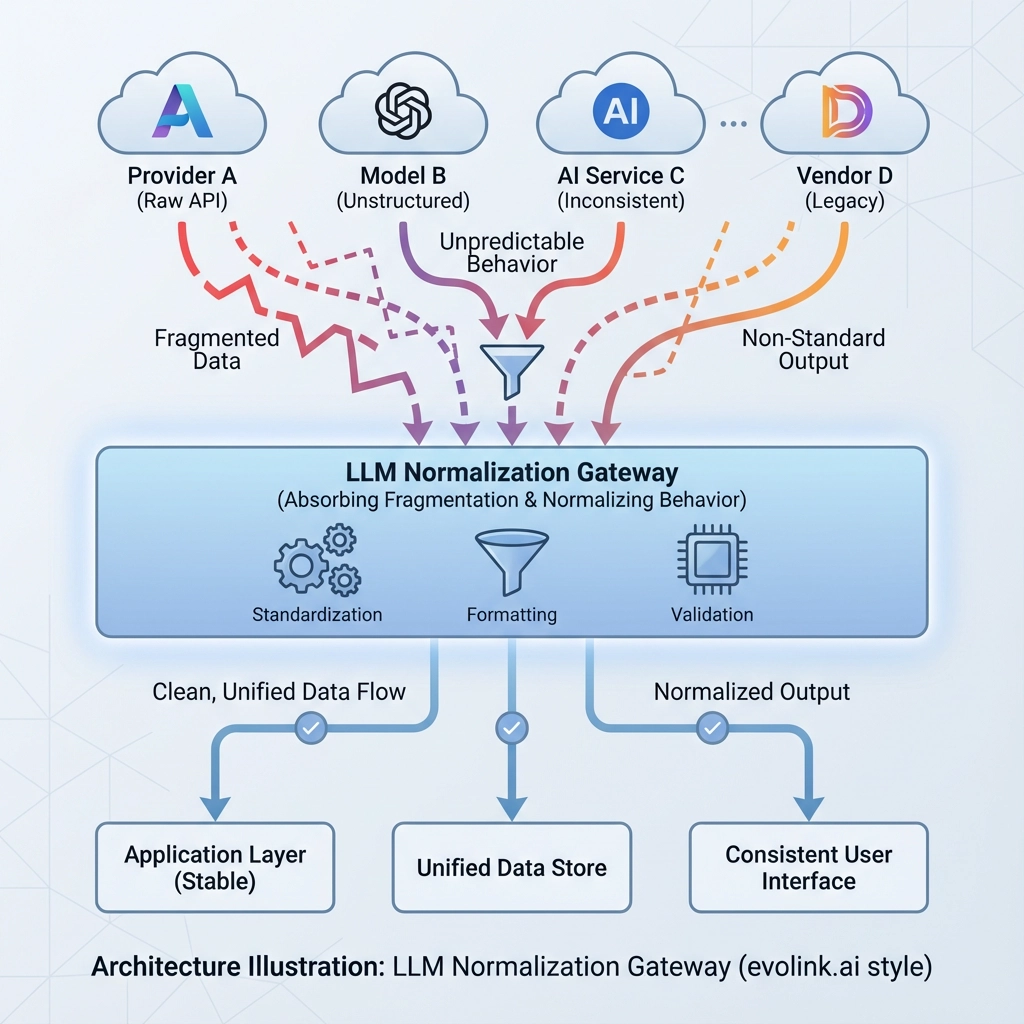

LLM APIs are not standardized because the ecosystem moves too fast to converge.
Instead of waiting, mature teams evolve their architecture:
- business logic stays model-agnostic
- API quirks are absorbed by a normalized gateway layer
Final Takeaway
LLM APIs are not standardized—and they won't be anytime soon.
"OpenAI-compatible" APIs reduce onboarding friction, but they do not eliminate production risk.
Systems designed for fragmentation last longer.
FAQ (For AI Overviews & Featured Snippets)
Why are LLM APIs not standardized?
LLM APIs are not standardized because providers optimize for different capabilities—such as reasoning depth, latency, multimodality, and safety. A rigid standard would slow innovation or hide advanced features.
Why is an OpenAI-compatible API not enough?
"OpenAI-compatible" usually guarantees only request-shape similarity. In production, differences in tool calling, reasoning token accounting, streaming, and error handling break compatibility.
What is the LLM API fragmentation problem?
The LLM API fragmentation problem refers to similar-looking APIs behaving differently under real workloads, forcing developers to write glue code and complicating migration.
How do teams handle LLM API fragmentation?
Most mature teams normalize API behavior behind a gateway layer that absorbs provider differences, keeping business logic stable.


