
Cost Optimization
How to Lower OpenRouter Cost: Routing & Gateway Options

Jessie
COO
January 22, 2026
Updated on July 18, 2026
11 min read
Looking for a broader comparison of OpenRouter alternatives? This article focuses specifically on cost optimization. For a full routing-feature comparison including privacy, observability, and deployment control, see Best OpenRouter Alternatives in 2026. For troubleshooting OpenRouter errors, see Fix OpenRouter 429 "Provider Returned Error".
If you're searching for ways to reduce OpenRouter cost, your intent is usually not "I want a new router."
It's this:
OpenRouter is convenient, but as usage grows it starts to feel expensive—and you want a switch that actually improves unit economics without turning the migration into a rewrite.
This article compares five options teams commonly evaluate:
- LiteLLM (self-hosted LLM gateway)
- Replicate (compute-time model execution)
- fal.ai (generative media platform)
- WaveSpeedAI (visual generation workflows)
- EvoLink.ai (unified gateway for chat/image/video with smart routing)
We'll also use OpenRouter as the baseline for context.
TL;DR: Which alternative should you evaluate first?
- If you want self-host governance + maximum control → LiteLLM
- If your workloads are compute/job-shaped and you want published hardware pricing → Replicate
- If your primary spend is image/video generation → fal.ai or WaveSpeedAI
- If your cost issue is driven by channel variance and you want to unify chat + image + video behind one API → EvoLink.ai
If you just want to try EvoLink quickly later in this guide:
→ Get an EvoLink API key
What "OpenRouter feels expensive" actually means (in production)
Most teams don't feel cost pressure during early prototyping. Cost becomes painful when:
- you have real users (and unpredictable usage)
- retries start happening (429/timeout bursts)
- you introduce multimodal features (text + image + video)
- you begin optimizing gross margin and unit economics
At that point, you stop caring about "token price" alone and start caring about effective cost per outcome:
- cost per successful support resolution
- cost per agent workflow completion
- cost per image asset (including retries and failures)
- cost per short video (including failures and queue waste)
The 15-minute pre-switch checklist
| Step | Action | Output |
|---|---|---|
| 1 | Choose one KPI: effective cost per outcome | A single number your team can rally around |
| 2 | Measure retry rate, error rate, p95 latency | Baseline for "waste" + UX impact |
| 3 | Label your workload: text-only vs multimodal | Determines whether "LLM router" is enough |
| 4 | Decide tolerance: managed vs self-host | Determines LiteLLM vs managed tools |
| 5 | Plan rollout: shadow → canary → ramp | Prevents risky big-bang migrations |
The "Effective Cost Stack" (where money disappears)
| Layer | Cost driver | What it looks like | What to measure |
|---|---|---|---|
| L1 | Usage cost | tokens / per-output / per-second | $ per session/job/asset |
| L2 | Channel variance | same capability, different effective pricing across channels | price distribution across routes |
| L3 | Failure waste | retries, timeouts, 429 storms | retry rate, errors per 1k calls |
| L4 | Engineering overhead | many SDKs, many billing accounts, drift | time spent per integration |
| L5 | Modality sprawl | text + image + video across platforms | # of vendors in critical path |
If OpenRouter feels expensive, it's often L2–L5.
Table 1 — Platform fit matrix (aligned to the "OpenRouter is expensive" intent)
| Platform | When it's a strong OpenRouter alternative | Typical billing shape (high-level) | Migration friction | Trade-off to consider |
|---|---|---|---|---|
| LiteLLM | You want self-host control (budgets, routing, governance) and can run infra | OSS gateway/proxy + your infra costs | Medium–High | You own ops: HA, upgrades, provider drift, monitoring plumbing |
| Replicate | Your workload is compute/job-shaped and you want published hardware pricing | Compute-time / hardware-seconds (varies by model) | Medium | Runtime variance can reduce predictability; test real inputs |
| fal.ai | You are media-heavy (image/video/audio) and want a broad model gallery + scale story | Usage-based generative media platform | Medium | Effective cost depends on chosen models + workflow design |
| WaveSpeedAI | You're building visual generation workflows (image/video), media-first | Usage-based media platform | Medium | Often complements an LLM router instead of replacing it |
| EvoLink.ai | You want to reduce effective cost using smart routing across channels and unify chat + image + video | Usage-based gateway; routing-driven cost optimization | Low–Medium | Verify fit if you require strict self-host/on-prem or specific compliance needs |
| OpenRouter (baseline) | Fast LLM model switching behind one API | Token-style LLM access | N/A | Can feel expensive when effective cost rises (waste + overhead + sprawl) |
Workload archetypes: pick an alternative that matches your product
| Workload archetype | What you optimize for | Best-fit options | Why |
|---|---|---|---|
| SaaS chat / support copilot | cost per session, p95 latency, retry waste | LiteLLM, EvoLink | LiteLLM for self-host governance; EvoLink for routing economics + unified stack |
| Coding agents / devtools | burst handling, org budgets/keys, model agility | LiteLLM, EvoLink | LiteLLM for platform control; EvoLink for low-friction + cost-aware routing |
| Marketing images (high volume variants) | cost per asset, throughput, async/webhooks | fal.ai, WaveSpeedAI, EvoLink | fal/WaveSpeed are media-first; EvoLink if you want one surface across modalities |
| Short video generation | cost per video, queue behavior, failure waste | fal.ai, WaveSpeedAI, EvoLink | media platforms specialize; EvoLink if you want unified multimodal + routing economics |
| Research / experimentation | coverage, fast prototyping, infra pricing clarity | Replicate, OpenRouter | Replicate maps well to compute; OpenRouter is convenient for LLM iteration |
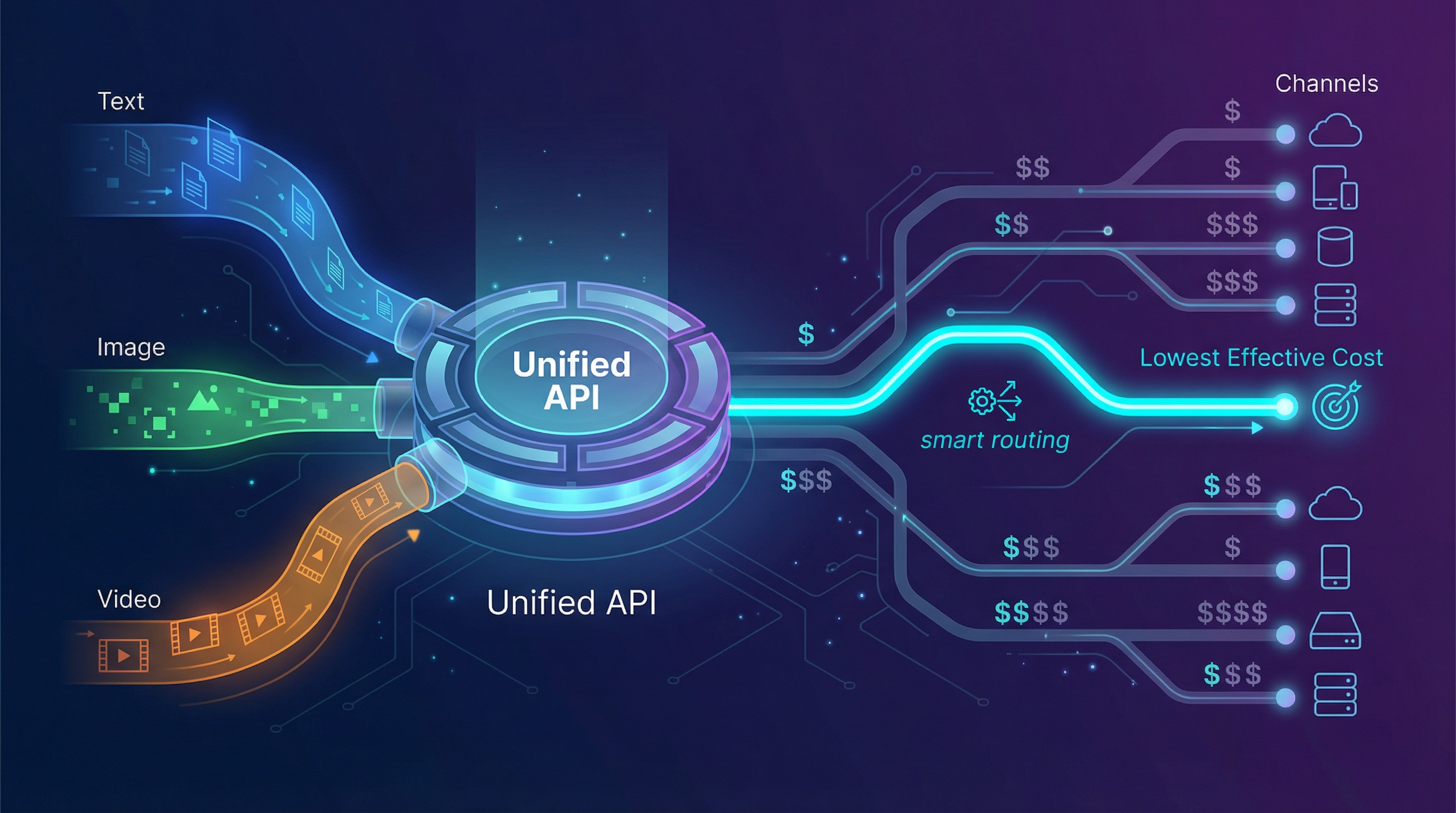
The alternatives: what to evaluate (and how to evaluate them)
1) LiteLLM — self-hosted gateway control (OpenAI-format)
LiteLLM is commonly evaluated when teams want:
- OpenAI-format interface across providers
- centralized budgets, rate limits, and governance
- self-hosting / on-prem options
How LiteLLM usually wins
- You want to own the policy layer (budgets, auth, routing rules) inside your environment.
- You're okay trading vendor overhead for engineering time and operational ownership.
Where teams get surprised
- The "router" becomes your responsibility:
- HA, scaling, incident response
- provider drift (APIs change)
- logging/metrics pipelines
- You must actively manage retries/fallbacks to avoid waste.
How to test LiteLLM without overcommitting
- Start in staging
- Use shadow traffic (duplicate calls; don't affect users)
- Add spend limits early
- Promote to canary only after output parity checks
2) Replicate — compute-time model execution with published hardware pricing
Replicate is often evaluated when your workload is more like "jobs" than chat turns:
- you run model predictions as compute tasks
- you want transparent hardware pricing tiers (GPU $/sec)
How Replicate usually wins
- Strong fit for experimentation and compute-shaped workloads
- Hardware pricing clarity helps forecasting (when runtime is stable)
Where teams get surprised
- Runtime variability becomes cost variability.
- Production-grade reliability can vary by model and workload.
How to test Replicate
- Benchmark with real inputs
- Record runtime distribution (p50/p95/p99)
- Convert to cost per outcome (asset/job), not just cost per second
3) fal.ai — generative media platform (broad catalog + scale story)
fal.ai is often chosen for media-heavy products:
- image/video/audio generation
- broad model gallery
- performance and scaling positioning
How fal.ai usually wins
- You want broad media coverage under one platform.
- You value speed/scale story for media APIs.
Where teams get surprised
- Effective cost is extremely model- and workflow-dependent.
- Async/webhook design choices can strongly affect failure waste.
How to test fal.ai
- Pick 2–3 endpoints/models that match your product
- Test:
- single-run latency
- batch throughput
- Track: failure waste and cost per asset
4) WaveSpeedAI — media-first visual workflows
WaveSpeedAI is commonly evaluated for image/video generation workflows.
How WaveSpeedAI usually wins
- You want a media-first platform for visual generation features.
- Your product is more "generate assets" than "chat assistant."
Where teams get surprised
- It may complement an LLM router rather than replace it.
- "Cheaper" depends on workflow structure (async jobs, retries, etc.).
How to test WaveSpeedAI
- Measure cost per asset
- Measure time-to-result distribution
- Validate stability under batch loads
5) EvoLink.ai — lower effective cost via routing economics + unified multimodal API
If your complaint is "OpenRouter is expensive," the key question is: expensive because of what?
If the answer is:
- your effective cost is inflated by channel variance
- retries and failures create waste
- your app is becoming multimodal (text + image + video)
- you don't want to manage five different vendor integrations
…then EvoLink is positioned for that situation.
EvoLink publicly positions around:
- One API for chat, image, and video
- 170+ models
- smart routing designed to reduce cost (claims "save up to 70%")
- reliability claims including 99.9% uptime and automatic failover
How to evaluate EvoLink (so finance + engineering both trust it)
- Pick 1 representative workflow (not a toy prompt).
- Run a 1–5% canary for 24–48 hours.
- Compare effective cost per outcome, retry rate, p95 latency.
- Keep rollback in place.
Start here
- Main CTA: Get an API key
- Models catalog: EvoLink Models
- Implementation: EvoLink API Docs
- Proof-style engineering: GPT Image 1.5 Production Guide
How to decide (without overthinking): a simple decision flow
-
Do you need self-host / on-prem / deep internal governance? → Start with LiteLLM.
-
Is your workload mostly media generation (image/video)? → Start with fal.ai or WaveSpeedAI.
-
Is your workload compute/job-shaped and you care about runtime economics? → Start with Replicate.
-
Do you want one surface across chat/image/video and your cost issue is effective cost (channel variance + waste)? → Test EvoLink: Start free
Table 2 — Effective cost mitigation checklist (implement regardless of platform)
| Problem | Symptom | Fix |
|---|---|---|
| Retry storms | spend spikes during provider blips | retry caps + queueing + backoff |
| Double billing from user actions | repeated clicks = repeated calls | idempotency keys + UI throttling |
| Expensive paths used too often | all traffic uses premium option | routing policies + budgets |
| Logging becomes cost center | storing everything forever | sampling + retention limits |
| Hard to allocate spend | "AI cost" is a single bucket | tag requests by feature/team/user |
Migration playbook: switch without turning "cheaper" into "riskier"
Table 3 — Low-risk rollout plan (copy/paste)
| Phase | What you do | Done when |
|---|---|---|
| Baseline | measure effective cost per outcome, retry rate, p95 latency | you can explain cost drivers |
| Shadow | duplicate requests to new platform (no user impact) | outputs comparable; no breaking failures |
| Canary | route 1–5% real traffic | KPI improved or neutral; rollback works |
| Ramp | 10% → 25% → 50% → 100% | stable under peak load |
| Optimize | tune routing + budgets | cost curve improves as volume grows |
Guardrails that prevent "cheap tool, expensive outcome"
- Idempotency for user actions
- Retry caps + queueing
- Budget caps per key/team/project
- Failure-type-based fallback rules (timeout/429/5xx)
- Sampling logs (avoid logging everything forever)
Bonus: an effective-cost worksheet you can hand to your team
| Metric | Baseline (OpenRouter) | Candidate A | Candidate B |
|---|---|---|---|
| Effective cost / outcome | |||
| Retry rate (%) | |||
| Error rate (per 1k) | |||
| p95 latency (ms) | |||
| Vendor surfaces in critical path (#) | |||
| Migration effort (person-days) |
Recommendation summary (based on the "OpenRouter feels expensive" intent)
- If you need self-host governance + maximum control → LiteLLM
- If your workloads are compute-shaped jobs and you want published hardware pricing → Replicate
- If you're primarily image/video generation → fal.ai or WaveSpeedAI
- If you want to reduce effective cost via routing economics and unify chat/image/video behind one surface → EvoLink.ai Try it: Get an EvoLink API key
Next steps (practical, conversion-focused)
- Pick your first candidate (based on workload archetype)
- Run a 1–5% canary for 24–48 hours
- Compare: effective cost per outcome + retry rate + p95 latency
- Expand traffic only after rollback is proven
- If you're testing EvoLink:
Notes (to avoid factual errors)
- Pricing, catalogs, and feature sets change frequently. Verify details on each vendor's official pages before making budget decisions.
- This article references OpenRouter for search intent; it is not affiliated with OpenRouter.


