

大多数团队在估算 LLM 功能成本时,只看一个指标:每百万 Token 的价格。
这个指标很重要——但只停留在纸面上。
在真实的生产系统中,LLM 的总拥有成本(TCO)往往不仅由 Token 消耗驱动,更多源于工程开销:集成工作、可靠性修复、提示词维护,以及那些悄悄侵蚀 AI 投资回报率的评估缺口。
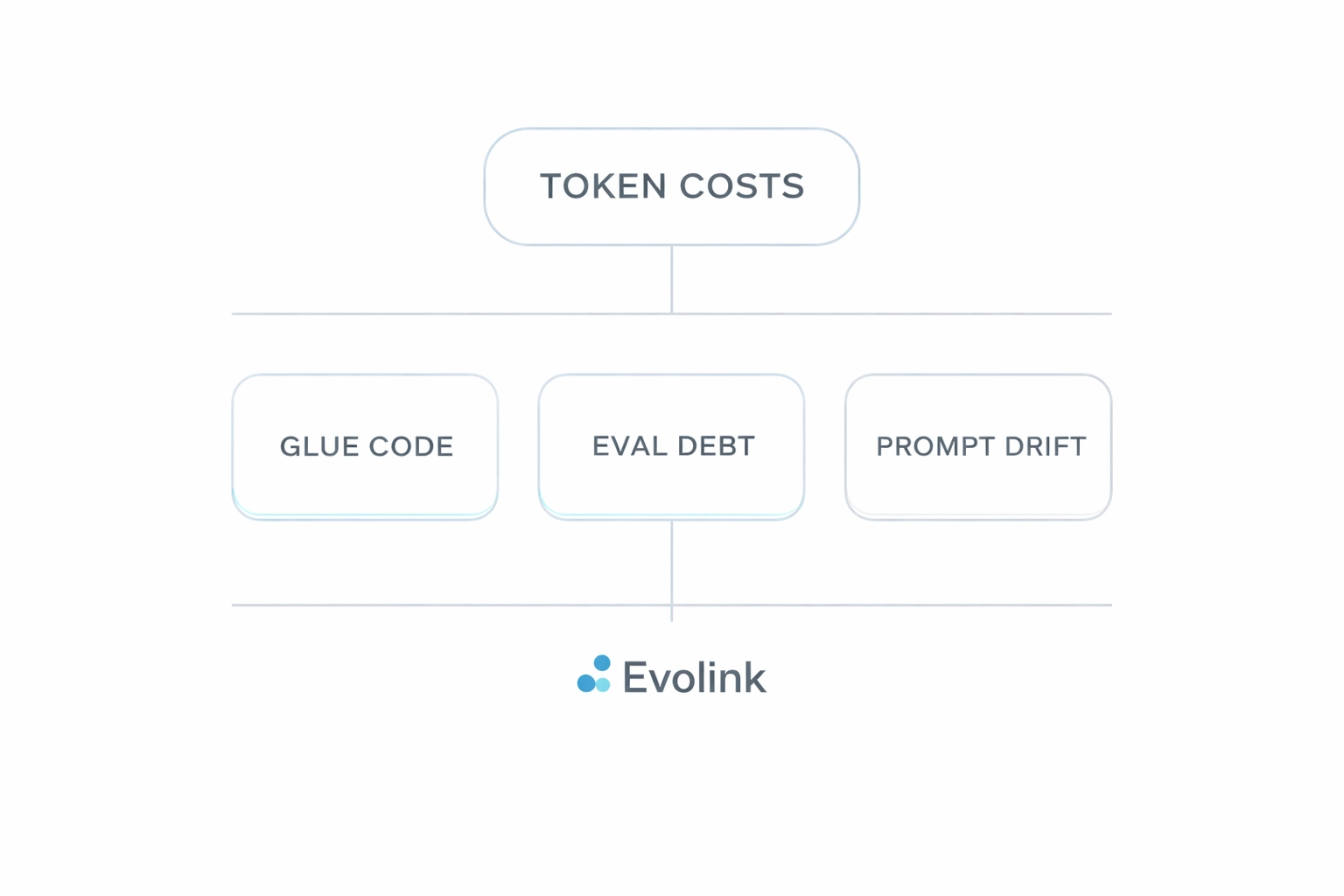
本指南解释了 LLM 集成的隐性成本,并提供了一套实战框架,帮你找到钱和工程时间真正花在了哪里:
- 胶水代码 — 持续的集成税
- 评估债务 — 不确定性的成本
- 提示词漂移 — 永远结束不了的迁移
10 分钟 LLM TCO 自查
在深入之前,先回答这五个问题:
- 你的系统目前支持多少个模型或服务商(包括计划中的)?
- 你是否维护着服务商特定的适配器或条件分支?
- 每次模型变更时,你是否运行自动化评估?
- 你能否在不重写提示词或业务逻辑的情况下,将流量切换到另一个模型?
- 你是否有统一的成本、延迟和失败率视图?
隐性成本 #1 — 胶水代码:集成税
胶水代码是指那些不产生任何用户价值,但为了抹平服务商之间的差异而必须编写的工程代码。
它在三个可预见的领域增长。
1) 用量与上下文管理
一旦涉及多个模型,用量统计就不再统一。
常见的胶水代码来源包括:
- 上下文窗口计算和截断
- "安全最大输出"保护
- 不一致或缺失的用量字段
上下文溢出经常导致重试、部分输出和意外消费——而不仅仅是报错。
2) 可靠性与失败归一化
不同的 API 以根本不同的方式失败:
- 结构化 API 错误 vs 传输层失败
- 限流 vs 静默超时
- 部分流式传输 vs 突然断开
这让"加个重试"变成了一棵不断生长的决策树。
# 示例:服务商无关的失败归一化
def should_retry(err) -> bool:
if getattr(err, "status", None) in (408, 429, 500, 502, 503, 504):
return True
if "timeout" in str(err).lower() or "connection" in str(err).lower():
return True
return False这段代码让系统保持运行——但对产品差异化毫无帮助。
3) 工具调用与结构化输出
当你依赖工具或严格的 JSON 输出时,你集成的是一个协议,而不是聊天 API。
即使 API 接受相似的请求格式,它们也可能在以下方面存在差异:
- 工具调用在响应中的位置
- 参数的编码方式
- 结构化输出的严格执行程度
这是 LLM API 碎片化的直接后果。
胶水代码气味测试
如果存在以下情况,说明你正在支付集成税:
- 提示词按服务商分叉
- 流式解析器因模型而异
- 适配器随时间增多
- 可观测性以服务商为中心,而非以功能为中心
隐性成本 #2 — 评估债务:不确定性的成本
评估债务会在团队部署模型时累积,如果没有与实际工作流绑定的自动化评估。
结果是可预见的:
- 迁移让人感觉有风险
- 更便宜或更快的模型无人使用
- 团队固守昂贵的默认选项
- AI 投资回报率随时间下降
最小可行评估循环(MVEL)
你不需要一个完整的 MLOps 平台来减少评估债务。
你需要的是一个能回答一个问题的循环:
如果我们更换模型,用户会注意到吗?
一个实用的基线,大多数团队可以在 1-2 天内实现:
1) 小型、版本化的数据集(50-300 个案例)
使用真实生产案例:
- 常见用户流程
- 边缘情况
- 历史故障
eval/
├── datasets/
│ ├── v1_core.jsonl
│ ├── v1_edges.jsonl
│ └── v1_failures.jsonl
2) 可重复的批处理运行器
一个脚本能够:
- 在多个模型上运行相同的数据集
- 记录输出、延迟和成本
- 在本地或 CI 中运行
3) 轻量级评分(聚焦回归)
至少追踪:
- 格式有效性
- 必需字段存在性
- 延迟和成本阈值
4) 简单的评估配置
dataset: datasets/v1_core.jsonl
model_targets:
- primary
- candidate
metrics:
- format_validity
- required_fields
thresholds:
format_validity: 0.98
latency_p95_ms: 1200
report:
output: reports/diff.html仅这个结构就能显著降低迁移风险。
隐性成本 #3 — 提示词漂移:永远结束不了的迁移
LLM 工程中最常见的误解是:
"到时候我们只需要换个模型 ID 就行了。"
实际上,提示词会漂移,因为模型在以下方面存在差异:
- 格式遵守程度
- 工具使用行为
- 拒绝阈值
- 指令遵循风格
一个常见的失败模式(与服务商无关)
- 提示词要求严格的 JSON 输出
- 模型 A 始终如一地遵守
- 模型 B 添加简短的解释或拒绝语句
- 下游解析失败
- 工程师修补提示词、解析器或两者
LLM TCO 冰山:成本的真正来源
- 可见成本: Token 定价
- 隐性成本:
- 胶水代码维护
- 提示词漂移修复
- 评估基础设施
- 调试、重试和回滚
关于多模态系统(图像与视频)的说明
虽然本文聚焦于 LLM 集成,但同样的 TCO 框架在多模态系统(如图像和视频生成)中适用性更强。
一旦超越文本,工程开销会扩展到包括异步任务编排、Webhook 或轮询、临时资源存储、带宽成本、超时处理,以及对非确定性输出的质量评估。实际上,这些因素往往超过单位定价的影响——无论单位是 Token、图像还是视频秒数。
这就是为什么构建生产级图像或视频工作流的团队,经常会遇到比纯文本系统更高的胶水代码和评估成本,即使模型定价在纸面上看起来更便宜。
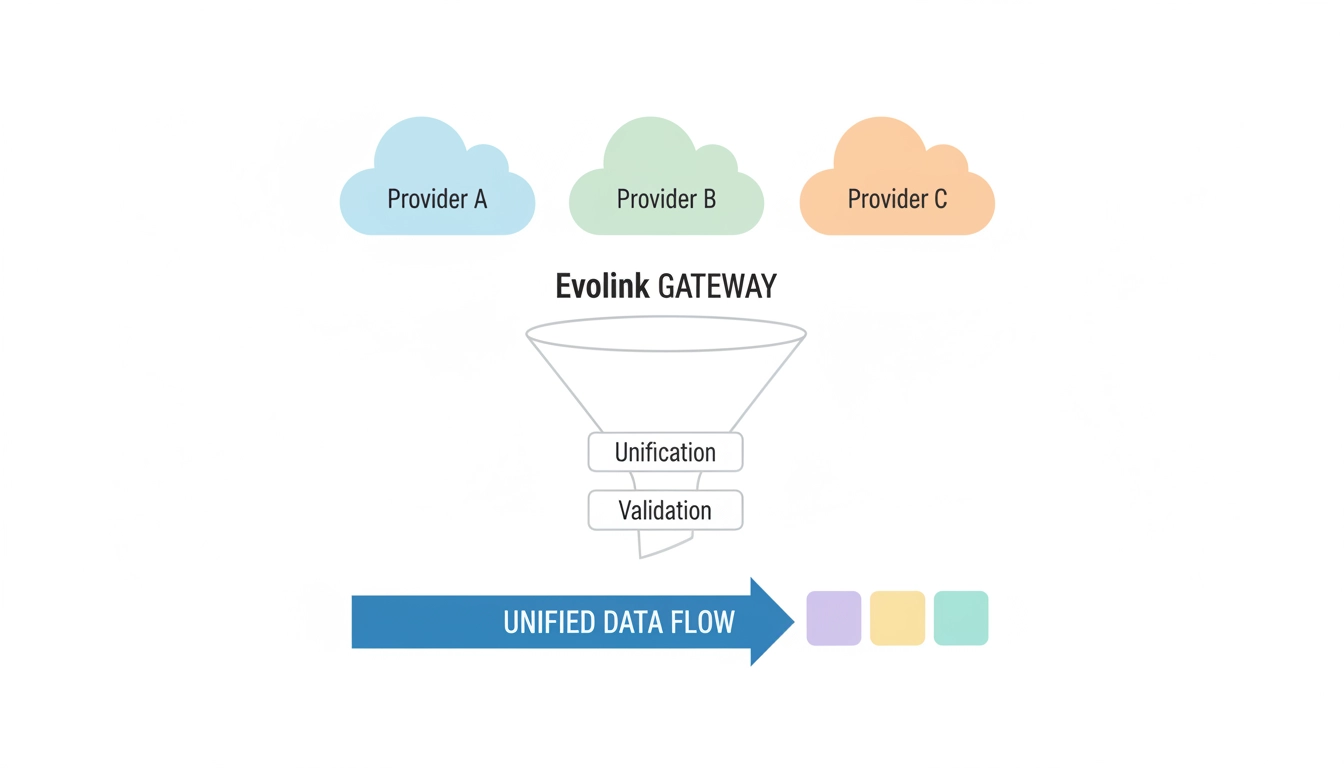
直接集成 vs 规范化网关
| 成本领域 | 直接集成 | 规范化网关 |
|---|---|---|
| Token 成本 | 低–可变 | 低–可变 |
| 集成工作量 | 高 | 较低 |
| 维护 | 持续性 | 集中化 |
| 迁移速度 | 慢 | 快 |
| 可观测性 | 碎片化 | 统一 |
| 工程开销 | 重复性 | 集中式 |
到这个阶段,真正的决策不是用哪个模型——而是你希望这些复杂性存在于哪里。
领先的团队会将碎片化、路由和可观测性从应用代码中移出,放入专门的网关层。
这正是 Evolink.ai 存在的架构转变原因。
常见问题(SEO 优化)
如何计算 LLM 集成的隐性成本?
通过核算花在集成、评估、提示词维护、可靠性修复和迁移上的工程时间——而不仅仅是 Token 消费。
多 LLM 策略的工程开销是什么?
包括胶水代码、提示词漂移处理、评估基础设施和跨服务商可观测性。
LLM 系统中的评估债务是什么?
评估债务是指部署模型时没有自动化评估而累积的风险,使得未来的变更更慢且更昂贵。
LLM 网关如何提升 AI 投资回报率?
通过集中化归一化、路由和可观测性,让团队能够优化或切换模型,而无需重写功能级集成代码。


