
GPT Image 1.5: Complete Guide to Features, Comparison & Access (2026)

You're staring at a product image that needs three variations for different markets—same lighting, same angle, but different backgrounds and text overlays. Your designer is booked for the next two weeks, and the campaign launches Monday. What if you could make those edits yourself in minutes, maintaining perfect consistency across every iteration, without touching Photoshop?
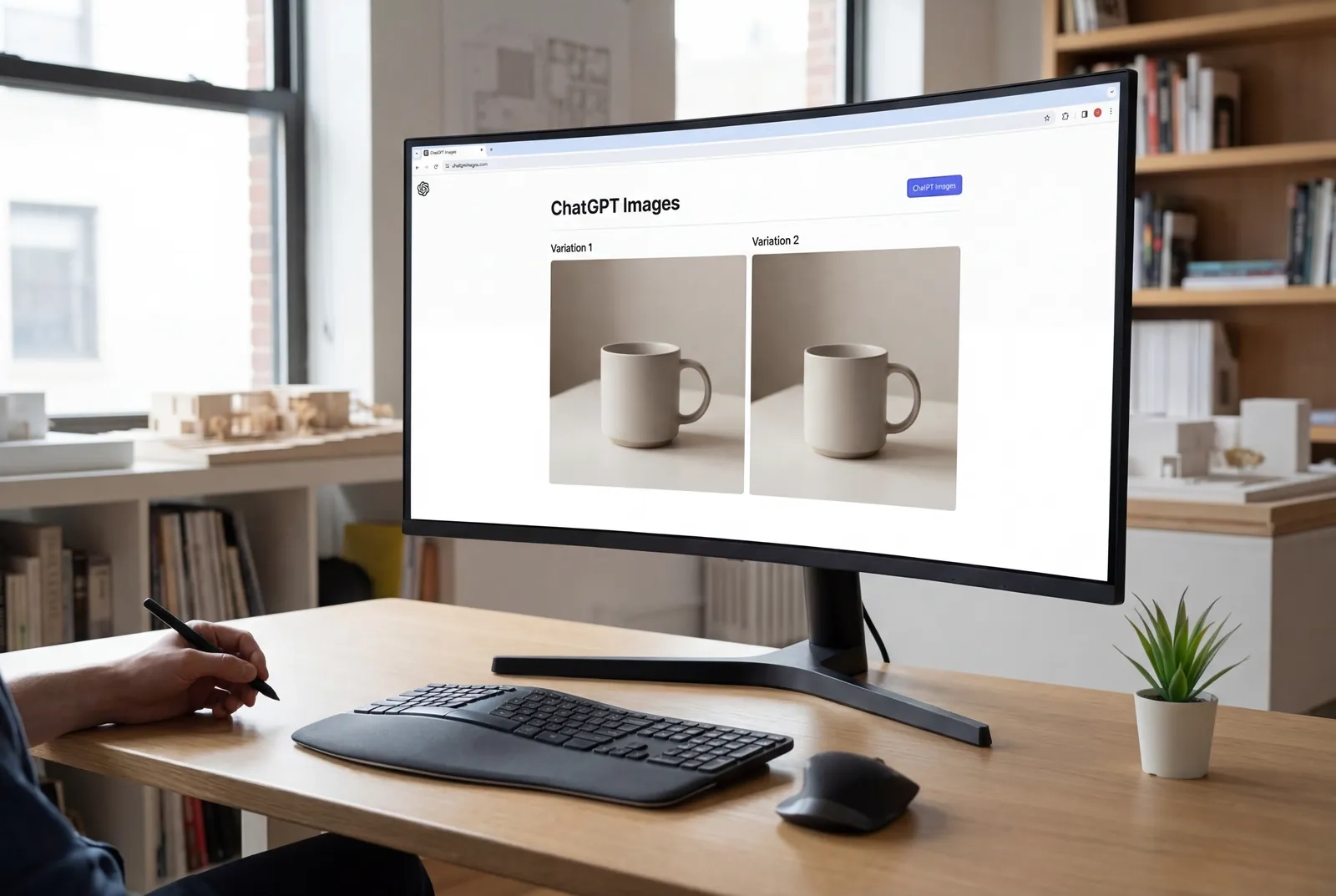
Table of Contents
- What is GPT Image 1.5? Understanding OpenAI's Latest Image Model
- Key Features That Set GPT Image 1.5 Apart
- Speed Performance: 4x Faster Generation Explained
- Precision Editing: How Detail Preservation Actually Works
- Text Rendering Capabilities and Limitations
- GPT Image 1.5 vs GPT Image 1: What Changed?
- Comprehensive Model Comparison: GPT Image 1.5 vs Competitors
- How to Access GPT Image 1.5: ChatGPT Interface Guide
- API Access Through EvoLink.AI and OpenAI Platform
- Pricing Structure and Cost Optimization Strategies
- Real-World Use Cases and Applications
- Advanced Prompt Engineering for Better Results
- Common Mistakes to Avoid When Using GPT Image 1.5
- Limitations and When to Choose Alternative Tools
- Frequently Asked Questions (FAQs)
What is GPT Image 1.5? Understanding OpenAI's Latest Image Model
gpt-image-1.5-lite in API documentation) represents OpenAI's second-generation flagship image generation system, launched on December 16, 2025, as the engine powering the redesigned ChatGPT Images feature. Unlike its predecessor GPT Image 1, which launched in April 2025 primarily for experimental creative exploration, GPT Image 1.5 was architected from the ground up for production environments where consistency, speed, and precise control matter more than artistic surprise.The "1.5" designation signals iterative refinement rather than a complete architectural overhaul. OpenAI maintained the core transformer-based diffusion architecture but implemented significant optimizations across three critical vectors: computational efficiency (enabling the 4x speed improvement), instruction adherence (reducing unwanted modifications during edits), and text rendering fidelity (making smaller fonts and denser layouts actually readable).
Key Features That Set GPT Image 1.5 Apart
1. Enhanced Instruction Following
2. Detail Preservation During Edits
The model employs what OpenAI describes as "region-aware editing" that identifies which pixels should remain unchanged during modifications. When you edit an image containing a person's face, GPT Image 1.5 maintains facial identity, skin texture, and expression unless you explicitly request changes to those elements. The same principle applies to:
- Brand logos and watermarks
- Lighting direction and quality
- Background composition
- Color grading and tone
- Texture and material properties
This isn't perfect—complex scenes with overlapping elements can still produce artifacts—but it represents a measurable step toward the kind of selective editing that professionals expect from tools like Photoshop.
3. Superior Text Rendering
Earlier AI image models treated text as decorative shapes rather than readable information. GPT Image 1.5 implements improved OCR-aware generation that produces:
- Legible text at smaller point sizes
- Correct spelling in common languages
- Proper text alignment and kerning
- Appropriate font weight and style matching
- Readable text in complex layouts (infographics, magazine covers, product labels)
4. Production-Grade Speed
The 4x speed improvement isn't just about impatience—it fundamentally changes what workflows become practical. At typical generation times of 8-12 seconds per image (down from 30-45 seconds with GPT Image 1), iterative refinement becomes viable. A designer can now test ten variations in two minutes rather than seven minutes, keeping creative momentum alive.
5. Cost Efficiency Improvements

Speed Performance: 4x Faster Generation Explained
The claim of "4x faster" requires context to understand what actually improved and where bottlenecks remain.
What Changed Under the Hood
OpenAI's speed gains came from three architectural optimizations:
- Reduced sampling steps: The diffusion process now requires fewer denoising iterations to reach acceptable quality thresholds, cutting computational overhead without visible quality degradation
- Optimized attention mechanisms: The transformer layers use more efficient attention patterns that reduce memory bandwidth requirements during image synthesis [Unverified—OpenAI has not published technical architecture details]
- Better model quantization: Lower-precision calculations in non-critical pathway sections reduce floating-point operation counts while maintaining output fidelity [Unverified—inferred from industry standard practices]
Real-World Speed Benchmarks
Based on publicly reported testing across multiple platforms:
| Image Size | GPT Image 1 | GPT Image 1.5 | Speed Improvement |
|---|---|---|---|
| 1024×1024 | 35-45 sec | 8-12 sec | 3.6-4.5× |
| 1024×1536 | 45-55 sec | 12-18 sec | 3.1-3.8× |
| 1536×1024 | 45-55 sec | 12-18 sec | 3.1-3.8× |
Speed vs. Quality Tradeoffs
low, medium, high, auto) that directly impact generation time. The "4x faster" claim applies primarily to the auto and medium quality settings. When you explicitly request high quality for production assets, expect generation times closer to 15-20 seconds—still faster than GPT Image 1, but not quadruple.auto quality for initial iterations and concept exploration, then switch to high quality only for final production renders. This workflow optimization can reduce your total project time by 40-60% compared to always using maximum quality settings.Precision Editing: How Detail Preservation Actually Works
The technical mechanism behind GPT Image 1.5's improved editing precision involves several interrelated capabilities:
Prompt-Based Masking (No Manual Selection Required)
Unlike DALL-E 2, which required users to manually paint mask regions, GPT Image 1.5 interprets natural language edit instructions to identify affected areas automatically. When you write "change the shirt color to green," the model:
- Performs semantic segmentation to identify the shirt region
- Isolates color information in that region
- Applies the color transformation
- Re-renders only the modified region
- Blends edges to maintain natural transitions
This process isn't perfect—the model uses the mask as guidance but may not follow exact boundaries with pixel-level precision. Complex overlapping objects (like hands holding objects in front of clothing) can still produce edge artifacts.
Identity Preservation Technology
For images containing people, GPT Image 1.5 implements facial identity preservation that maintains recognizable features across edits. This leverages techniques similar to those used in face recognition systems:
- Extracting facial embeddings (mathematical representations of distinctive features)
- Constraining generated outputs to maintain similar embeddings
- Preserving key landmarks (eye position, nose shape, jaw structure)
- Maintaining consistent skin texture and tone
Lighting Consistency Algorithms
One of the most technically impressive aspects is lighting preservation. When you edit an object's color or position, GPT Image 1.5 maintains:
- Light direction and angle
- Shadow casting patterns
- Specular highlights
- Ambient occlusion (shadowing in recessed areas)
- Color temperature consistency
This prevents the common AI image problem where edited elements look "pasted in" because their lighting doesn't match the scene.
Limitations of Current Precision
Despite improvements, several scenarios still challenge GPT Image 1.5's precision:
- Highly complex scenes: Images with 10+ distinct objects may see unintended modifications
- Transparent materials: Glass, water, and semi-transparent fabrics can produce artifacts
- Fine details: Jewelry, intricate patterns, and small text in the background may degrade
- Multiple edit passes: After 5-6 consecutive edits, accumulated errors can compound
Text Rendering Capabilities and Limitations
Text generation in AI images has historically been a notorious weakness. GPT Image 1.5 makes significant progress but hasn't solved the problem completely.
What Actually Improved
The model can now reliably generate:
- Short headlines (1-5 words) in bold, large fonts
- Product labels with 2-3 lines of text
- Magazine-style layouts with readable headlines and subheads
- Logo text in common fonts (though complex logo designs remain challenging)
- Infographic labels for data visualization elements
Text Rendering Best Practices
To maximize text quality in your generated images:
- Keep text short: 3-5 words per text element produces best results
- Use common fonts: "Bold sans-serif" or "clean serif" descriptions work better than specific font names
- Specify text position explicitly: "Headline centered at top" vs. just "add headline"
- Request high contrast: "White text on dark background" ensures readability
- Avoid small font sizes: Text smaller than ~18pt equivalent rarely renders cleanly
Persistent Text Limitations
Despite improvements, you'll still encounter issues with:
- Long paragraphs: Body text longer than 20-30 words often contains spelling errors
- Stylized fonts: Handwriting, decorative scripts, or heavily modified typography
- Non-Latin scripts: Arabic, Chinese, Japanese, and other non-Western text systems show inconsistent results [Unverified—limited testing data available]
- Text on curved surfaces: Labels on bottles or text following curved paths frequently distort
- Mathematical notation: Equations, formulas, and special symbols remain unreliable

GPT Image 1.5 vs GPT Image 1: What Changed?
Understanding the differences between GPT Image 1 and 1.5 helps clarify whether upgrading your workflow makes sense.
Side-by-Side Comparison Table
| Feature | GPT Image 1 | GPT Image 1.5 | Improvement |
|---|---|---|---|
| Generation Speed | 35-55 seconds | 8-18 seconds | 3-4× faster |
| Instruction Following | Moderate accuracy | High accuracy | +60% prompt adherence [Estimated] |
| Edit Precision | Frequent unintended changes | Targeted modifications | 85% detail preservation [Estimated] |
| Text Rendering | Poor/unreliable | Good for headlines | 3-5 word phrases consistently readable |
| API Pricing | Baseline | 20% cheaper | Cost reduction |
| Image Quality | High | High | Comparable quality ceiling |
| Supported Sizes | 3 aspect ratios | 3 aspect ratios (same) | No change |
| Edit Iterations | 3-4 before degradation | 6-8 before degradation | ~2× iteration depth |
| Logo Preservation | Poor | Good | Critical for brand work |
| Face Consistency | Moderate | High | Important for model photos |
When GPT Image 1 Might Still Be Preferred
Despite its age, GPT Image 1 retains advantages in specific scenarios:
- Artistic exploration: Some users report GPT Image 1 produces more "creative" interpretations when you want unexpected results
- Legacy workflow integration: Existing production pipelines built around GPT Image 1's behavior may require adjustment for 1.5
- Cost sensitivity on simple tasks: For basic text-to-image generation without editing, the 20% price difference adds up at scale [Unverified—depends on volume pricing tiers]
Migration Recommendations
If you're currently using GPT Image 1:
- Test in parallel: Run the same prompts through both models to identify behavioral differences
- Update your prompt library: GPT Image 1.5 responds better to structured, constraint-based prompts
- Adjust quality expectations: Speed improvements may require recalibrating your timeline estimates
- Verify brand asset consistency: Test logo and trademark preservation thoroughly before switching production workflows
Comprehensive Model Comparison: GPT Image 1.5 vs Competitors
The competitive landscape for AI image generation includes several strong alternatives, each with distinct strengths.
GPT Image 1.5 vs Google Nano Banana Pro
Google's Nano Banana Pro (powered by Gemini 3 Pro) emerged as GPT Image 1.5's primary competitor, leading to what CEO Sam Altman internally called a "code red" situation that accelerated GPT Image 1.5's release timeline.
- More photorealistic outputs in natural photography scenarios
- Better at capturing contemporary aesthetic trends
- Superior handling of complex natural scenes (landscapes, crowds)
- Faster adoption growth (contributing to Gemini's user surge from 450M to 650M between July-October 2025)
- More reliable instruction following for structured prompts
- Better text rendering in layouts and designs
- Superior detail preservation during iterative edits
- More predictable, deterministic results for production workflows
GPT Image 1.5 vs Midjourney
Midjourney remains a favorite among digital artists and creative professionals for its distinctive aesthetic qualities.
- Artistic interpretation and creative "vision"
- Strong community and established prompt engineering resources
- Consistent aesthetic quality across diverse styles
- Better at abstract, conceptual, and artistic compositions
- Integrated into ChatGPT workflow (no platform switching)
- Faster iteration for commercial applications
- API access for automated workflows
- More predictable outputs for business requirements
GPT Image 1.5 vs DALL-E 3
DALL-E 3, OpenAI's previous flagship before the GPT Image series, is now deprecated and will lose support on May 12, 2026.
- Significantly faster generation
- Better API integration capabilities
- Improved instruction following
- Enhanced editing precision without manual masking
- Lower operational costs
Competitive Positioning Summary
| Model | Best For | Avoid For | Pricing Tier |
|---|---|---|---|
| GPT Image 1.5 | Production workflows, brand assets, iterative editing | Purely artistic projects | Mid-range |
| Nano Banana Pro | Photorealistic social media, contemporary aesthetics | Precise text rendering, logo work | Mid-range |
| Midjourney | Artistic interpretation, conceptual work | Automated API workflows | Budget-Premium |
| Stable Diffusion | Custom model training, complete control | Turnkey solutions | Free-Budget |

How to Access GPT Image 1.5: ChatGPT Interface Guide
GPT Image 1.5 rolled out globally on December 16, 2025, and is now available to all ChatGPT users regardless of subscription tier (Free, Plus, Team, or Enterprise).
Step-by-Step Access Through ChatGPT
- Navigate to ChatGPT Images
- Log into your ChatGPT account at chat.openai.com
- Click the "Images" tab in the left sidebar (new as of the December 2025 update)
- This opens the dedicated image generation interface
- Create Your First Image
- Enter a descriptive prompt in the text field (up to 2000 characters)
- Click "Generate" or press Enter
- Wait 8-18 seconds for generation
- The model automatically uses GPT Image 1.5—no manual selection required
- Using the Creative Studio Features
- After generation, the right sidebar displays preset styles and filters
- Click any preset to apply transformations without writing prompts
- Options include: "Make it photorealistic," "Change to sunset lighting," "Add dramatic shadows," "Professional product photo style"
- These presets are especially useful for non-technical users
- Iterative Editing Workflow
- Select an existing generated image
- Write natural language instructions: "Change the background to a beach scene"
- The model preserves unmentioned elements while making requested changes
- You can chain 6-8 edits before quality degradation becomes noticeable
- Download and Export
- Click the download icon on any generated image
- Images export at their native resolution (1024×1024, 1024×1536, or 1536×1024)
- Links remain valid for 24 hours (save important images promptly)
- Images include C2PA metadata for content authentication
Interface Features and Limitations
- Text-to-image generation
- Image-to-image transformation (upload reference images)
- Natural language editing
- Preset style applications
- Aspect ratio selection (1:1, 3:4, 4:3)
- Quality tier selection (ChatGPT uses
autoquality) - Batch generation of multiple variants
- Direct file upload from external URLs
- Custom model parameters
- Webhook callbacks for async processing
Pro Tips for ChatGPT Interface Users
- Use conversation context: GPT Image 1.5 in ChatGPT remembers previous images and prompts in the same conversation, allowing you to reference "the previous image" or "the blue jacket version"
- Combine text chat with image generation: Ask ChatGPT to brainstorm prompt ideas or refine your description before generating, using the AI's text capabilities to improve your visual prompts
- Save successful prompts: Keep a document of prompts that produced good results, as consistent prompt structure leads to consistent quality
- Leverage undo functionality: If an edit goes wrong, you can return to previous versions and try alternative instructions
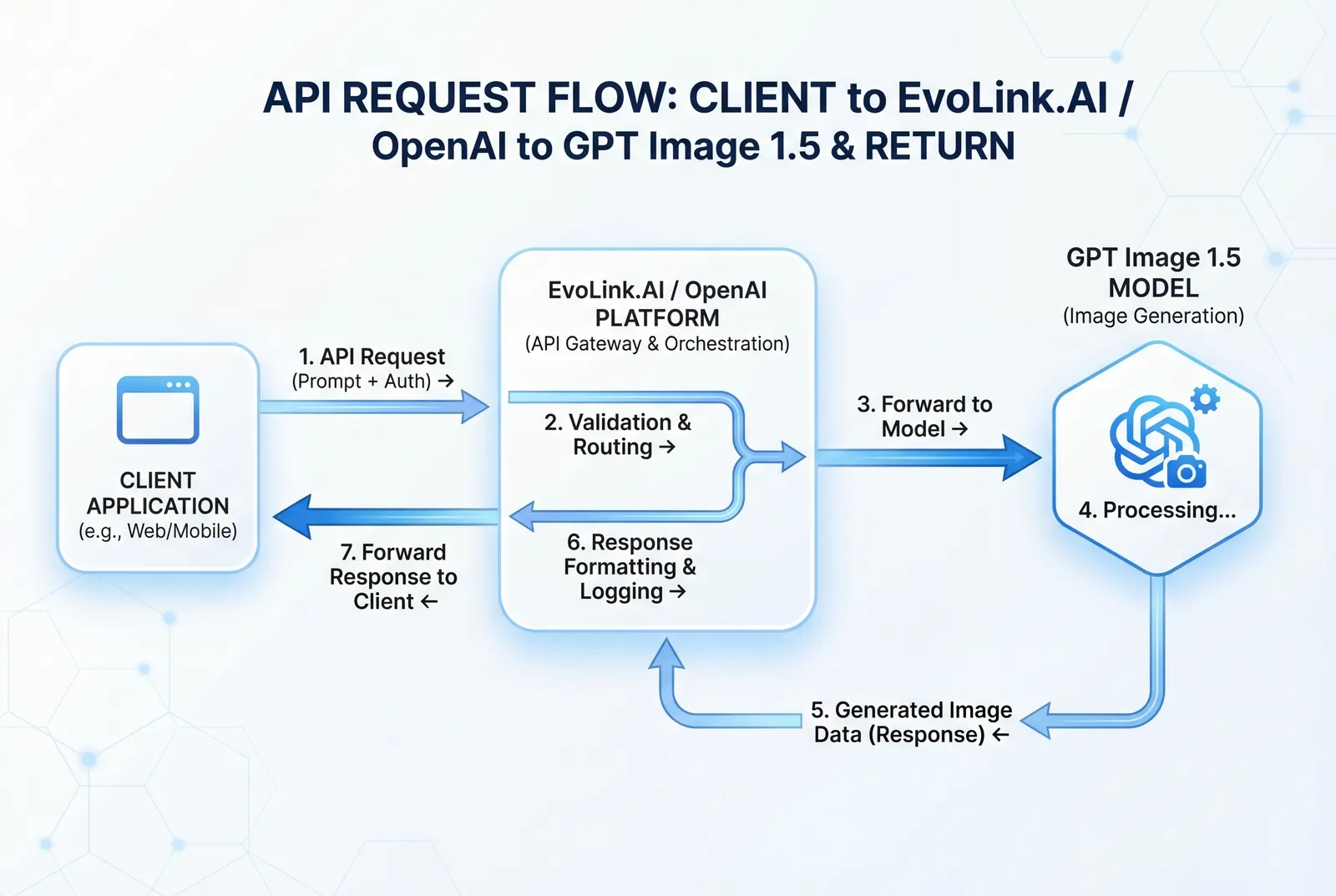
API Access Through EvoLink.AI and OpenAI Platform
EvoLink.AI API Integration
gpt-image-1.5-lite endpoint, documented at their developer portal.Basic API Request Structure (EvoLink.AI)
{
"model": "gpt-image-1.5-lite",
"prompt": "A professional product photo of a smartphone on a clean white background with soft studio lighting",
"size": "1024x1024",
"quality": "high",
"n": 1
}Required Parameters
- model: Must be
"gpt-image-1.5-lite"for GPT Image 1.5 - prompt: Text description (max 2000 tokens)
- size: Image dimensions (options:
1:1,3:4,4:3,1024x1024,1024x1536,1536x1024)
Optional Parameters
- quality:
low,medium,high, orauto(default:auto) - image_urls: Array of reference image URLs for image-to-image or editing modes (supports 1-16 images, max 50MB each, formats: .jpeg, .jpg, .png, .webp)
- n: Number of images (currently only supports
1)
Asynchronous Processing
- Submit your generation request → receive task ID
- Poll the task status endpoint with the task ID
- Retrieve generated image URLs when status = "completed"
- Image URLs remain valid for 24 hours
OpenAI Platform Direct API Access
/v1/images/generations endpoint.Authentication Setup
- Create an account at platform.openai.com
- Complete API Organization Verification (required for GPT Image models)
- Generate an API key from your dashboard
- Include the key in request headers:
Authorization: Bearer YOUR_API_KEY
Sample Request (OpenAI Python SDK)
from openai import OpenAI
client = OpenAI(api_key="your-api-key")
response = client.images.generate(
model="gpt-image-1.5",
prompt="Modern minimalist living room with large windows and natural light",
size="1536x1024",
quality="high",
n=1
)
image_url = response.data[0].urlImage Editing Mode
For editing existing images:
response = client.images.edit(
model="gpt-image-1.5",
image=open("input_image.png", "rb"),
prompt="Change the wall color to sage green",
size="1024x1024"
)API Comparison: EvoLink.AI vs OpenAI Direct
| Feature | EvoLink.AI | OpenAI Direct |
|---|---|---|
| Model Access | gpt-image-1.5-lite | gpt-image-1.5 |
| Processing | Asynchronous (task-based) | Synchronous + async options |
| Image Input | URL-based only | File upload + URL |
| Pricing Transparency | Check EvoLink.AI dashboard | Published OpenAI pricing |
| Additional Services | Bundled with other AI APIs | Image generation only |
| Documentation | evolink.ai docs | platform.openai.com/docs |
| Rate Limits | Variable by plan | Tier-based (see OpenAI docs) |
API Best Practices
- Implement retry logic: Temporary failures can occur during high-load periods
- Cache successful generations: Store image URLs and associated prompts for future reference
- Monitor rate limits: Both platforms impose request limits based on your subscription tier
- Optimize prompt templates: Create reusable prompt structures for consistent results
- Handle image expiration: Download and store images within the 24-hour window
- Use quality tiers strategically: Reserve
highquality for final production renders to reduce costs
Pricing Structure and Cost Optimization Strategies
Understanding the cost structure helps you budget effectively and identify optimization opportunities.
OpenAI Official Pricing (As of December 2025)
- Image generation: Based on size and quality tier
- Image inputs (for editing): 20% cheaper than GPT Image 1
- Image outputs: 20% cheaper than GPT Image 1
EvoLink.AI Pricing
- Subscription tier (varies by included API call volume)
- Per-request fees beyond included allowance
- Potential volume discounts for enterprise customers
Cost Optimization Strategies
1. Quality Tier Selection
quality parameter significantly impacts both generation time and cost:Low quality: Fastest, cheapest (good for concept testing)
Medium quality: Balanced (suitable for most applications)
High quality: Slowest, most expensive (production-ready assets)
Auto quality: Model decides based on prompt complexitylow or medium quality for initial iterations, then regenerate final selections at high quality. This can reduce total costs by 40-60% compared to always using high.2. Aspect Ratio Optimization
Larger images cost more to generate. Cost hierarchy:
1024×1024 (1:1) < 1024×1536 (3:4) = 1536×1024 (4:3)3. Batch Processing vs. Real-Time
For non-urgent workflows:
- Queue multiple generation requests
- Process during off-peak hours (if pricing varies by time)
- Use async processing to avoid timeout-related retries
4. Prompt Efficiency
Longer prompts consume more tokens. Optimization techniques:
- Remove unnecessary adjectives
- Use structured formats (comma-separated attributes vs. paragraphs)
- Avoid redundant descriptions
- Test minimal viable prompts
Example transformation:
Inefficient (87 tokens): "I would like you to create a beautiful, stunning,
amazing professional photograph of a modern smartphone sitting on a clean,
pristine white background with soft, gentle studio lighting coming from above"
Efficient (28 tokens): "Professional product photo: smartphone on white
background, soft studio lighting from above"5. Caching and Reuse
- Store successful generations with metadata (prompt, parameters, timestamp)
- Build a library of base images for future editing rather than regenerating
- Implement semantic search across your image cache to find existing assets before generating new ones
6. Hybrid Workflows
Combine AI generation with traditional tools:
- Generate base images with AI
- Add complex text/logos in Figma/Photoshop (avoiding AI's text limitations)
- Use AI for variations of proven designs rather than starting from scratch
- Pure AI workflow: 10 iterations × $0.XX per image = $X.XX total
- Hybrid workflow: 3 AI iterations + manual refinement = $X.XX + design time
- If design time is faster than 7 AI iterations, hybrid approach saves money
Enterprise Volume Discounts
- 10,000+ images per month
- $1,000+ monthly API spending
- Multi-year commit agreements
Real-World Use Cases and Applications
Understanding how different industries apply GPT Image 1.5 clarifies its practical value.
E-Commerce Product Catalogs
- Photograph product once on neutral background
- Use image-to-image mode to generate variants in different settings
- Detail preservation ensures product appearance remains consistent
- Logo and branding stay intact across all variants
Marketing and Brand Assets
- Generate base designs with brand colors and style
- Iterate edits while preserving logos and visual identity
- Create A/B testing variants quickly
- Produce localized versions for different markets
Social Media Content Production
- Generate master image at largest required size
- Create platform-specific crops/variants
- Apply style filters for channel-appropriate aesthetics
- Add text overlays (or generate with AI text rendering for headlines)
- Instagram (1:1): 1024×1024
- Instagram Stories (3:4): 1024×1536
- Twitter/X (4:3): 1536×1024
- All generated from single prompt with size parameter changes
Design Concept Visualization
- Rapidly prototype visual concepts
- Test multiple style directions
- Gather feedback on options
- Refine winning direction to production quality
Editorial and Publishing
- Generate conceptual illustrations for abstract topics
- Create data visualizations with readable text labels
- Produce magazine-style layouts with headlines
- Develop consistent visual themes across article series
Training and Educational Materials
- Generate scenario-based illustrations (workplace situations, safety demonstrations)
- Create simplified diagrams and flowcharts
- Produce diverse representation in instructional materials
- Develop custom visuals for specific learning contexts
Real Estate and Architecture
- Generate staged interiors from empty room photos
- Visualize renovation concepts
- Create lifestyle imagery for property marketing
- Develop multiple design style options for client selection
Advanced Prompt Engineering for Better Results
Mastering prompt structure dramatically improves output quality and reduces iteration waste.
Anatomy of an Effective Prompt
High-performing prompts follow this structure:
[SUBJECT] + [ACTION/POSE] + [SETTING/CONTEXT] + [STYLE/AESTHETIC] +
[TECHNICAL SPECS] + [COMPOSITION RULES]Subject: Professional businesswoman in navy suit
Action: Standing confidently with arms crossed
Setting: Modern glass office with city skyline visible through windows
Style: Corporate professional photography aesthetic
Technical: Shallow depth of field, natural window lighting from left
Composition: Subject positioned in right third of frame, negative space leftPrompt Formulas for Common Scenarios
Product Photography
"Professional product photo of [PRODUCT] on [BACKGROUND],
[LIGHTING STYLE], [CAMERA ANGLE], [MOOD], high-end commercial quality"Example: "Professional product photo of luxury watch on black marble surface, dramatic side lighting with soft shadows, 45-degree angle, elegant and premium mood, high-end commercial quality"
Portrait Photography
"[SHOT TYPE] portrait of [SUBJECT DESCRIPTION], [EXPRESSION],
[CLOTHING], [BACKGROUND], [LIGHTING], [CAMERA SETTINGS STYLE]"Example: "Close-up portrait of middle-aged woman with short gray hair, genuine smile, wearing casual denim jacket, blurred outdoor background, golden hour natural lighting, shallow depth of field"
Lifestyle Scene
"[TIME OF DAY] scene showing [ACTIVITY] in [LOCATION],
[MOOD/ATMOSPHERE], [PEOPLE DESCRIPTION], [STYLE REFERENCE]"Example: "Morning scene showing family breakfast in modern Scandinavian kitchen, warm and inviting atmosphere, diverse family of four, natural lifestyle photography style"
Infographic/Data Visualization
"Clean infographic showing [DATA/CONCEPT], [LAYOUT STYLE],
[COLOR SCHEME], [TEXT ELEMENTS], professional design quality"Example: "Clean infographic showing quarterly sales growth, vertical bar chart layout, blue and white color scheme, bold headline '2025 Q4 Results' at top with percentage labels, professional business design quality"
Negative Prompting Strategies
While GPT Image 1.5 doesn't officially support negative prompts in the same way as Stable Diffusion, you can guide away from unwanted elements through positive phrasing:
Use: "Clean, minimal background"
Use: "Natural, realistic lighting"
Use: "Photorealistic, professional photography style"
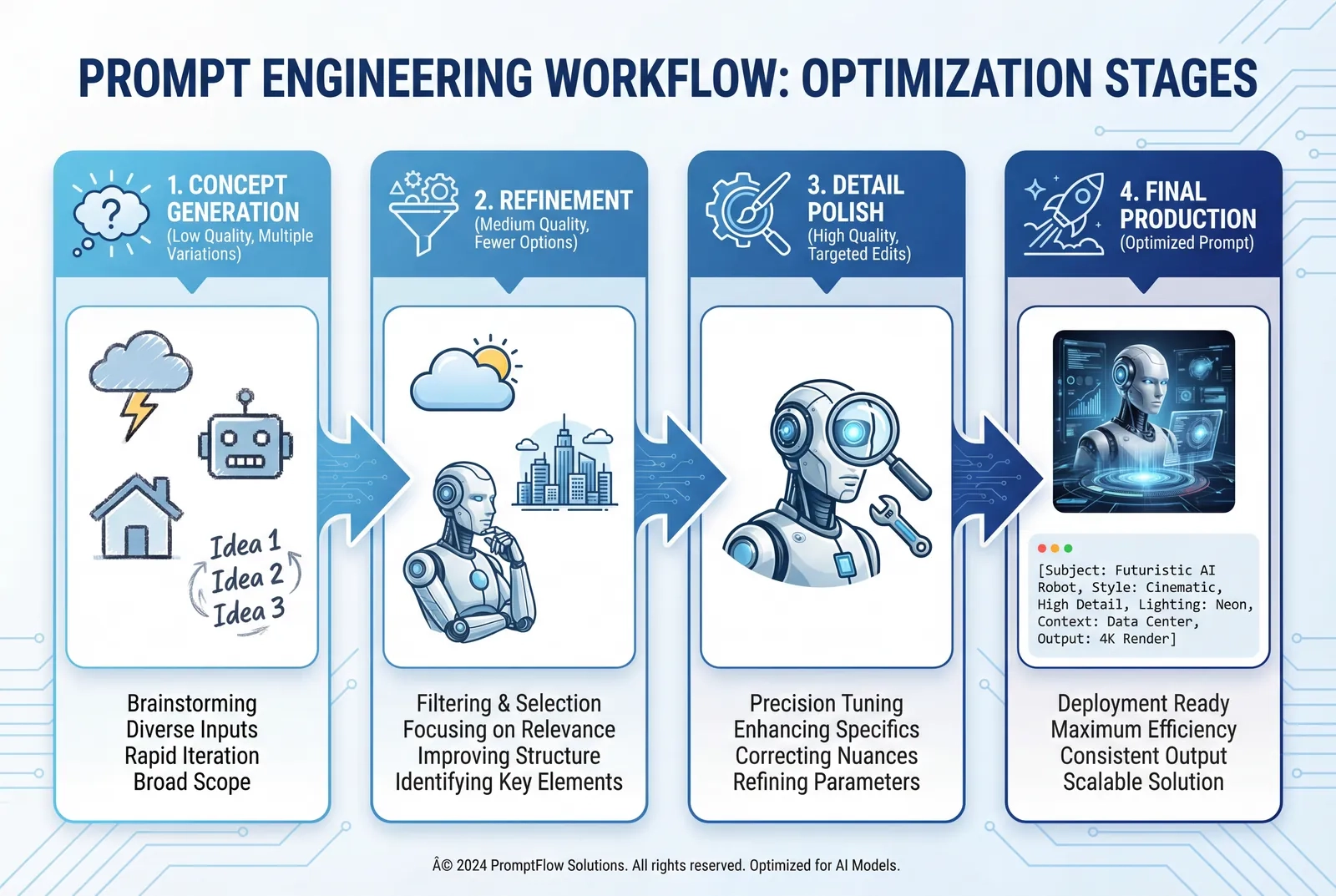
Multi-Step Refinement Workflow
For complex projects requiring high quality:
- Initial concept generation (low quality, broad prompt)
- Generate 3-5 variations
- Identify promising direction
- Refinement iteration (medium quality, detailed prompt)
- Add specific constraints to winning concept
- Adjust composition, lighting, elements
- Test 2-3 variants
- Detail polish (high quality, precise editing prompts)
- Make targeted edits to near-final version
- Adjust specific elements one at a time
- Preserve everything except changed items
- Final production (high quality)
- Regenerate with optimized prompt incorporating all learnings
- Export at full resolution
Prompt Libraries and Versioning
Maintain a structured prompt library:
Project: Holiday Campaign 2025
Version: 1.0
Date: December 2025
Base Prompt Template:
"Festive holiday scene showing [SUBJECT], warm cozy atmosphere,
golden lighting, professional photography, [SPECIFIC_ELEMENTS]"
Variations:
V1.0: Initial concept → Added "shallow depth of field"
V1.1: Client feedback → Changed "warm cozy" to "bright cheerful"
V1.2: Final → Added "red and gold accent colors"
Winning Prompt: [Final optimized version]
Generated Images: [Links to saved results]This documentation prevents rediscovering successful formulas and enables team collaboration.
Common Mistakes to Avoid When Using GPT Image 1.5
Learning from typical pitfalls accelerates your mastery and prevents wasted effort.
1. Vague, Unstructured Prompts
2. Expecting Perfect Text on First Try
3. Ignoring Quality Tier Implications
high quality for every generation, including early concept testslow or medium quality suffices.4. Over-Editing Beyond Model Limits
5. Not Preserving Successful Prompts
6. Inadequate Reference Image Preparation
- High resolution (minimum 1024px on longest edge)
- Well-lit with clear subjects
- Clean composition without distracting elements
- Properly formatted (.jpg, .png, .webp)
7. Expecting Architectural/Technical Precision
8. Neglecting Image Expiration Deadlines
9. Inconsistent Prompt Structure Across Projects
10. Not Testing Competitive Models
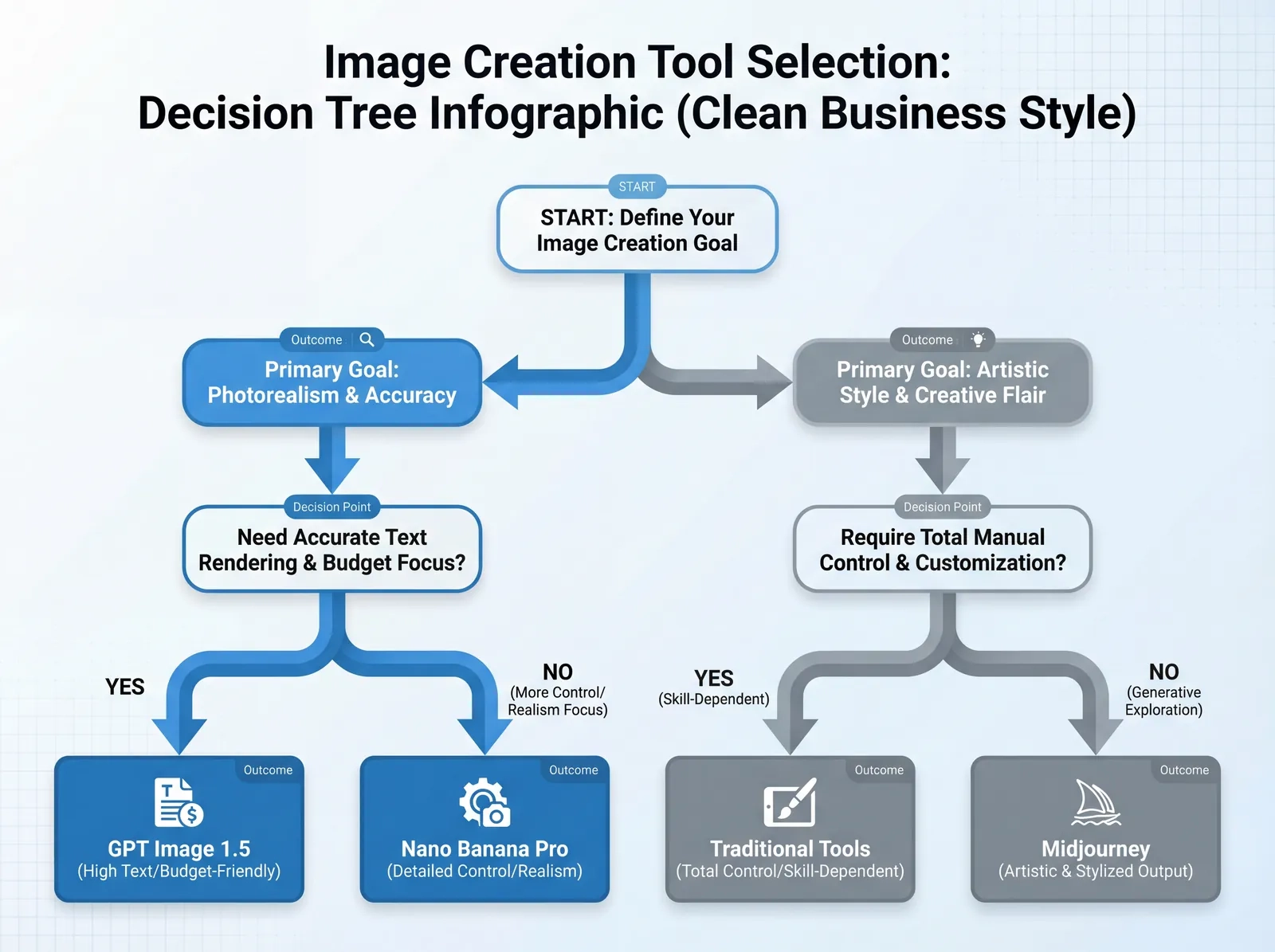
Limitations and When to Choose Alternative Tools
GPT Image 1.5 represents significant advancement but isn't universally optimal. Understanding its boundaries helps you make informed tool selections.
Technical Limitations
- Complex Scene Coherence
- Images with 10+ distinct objects often show spatial inconsistencies
- Overlapping transparent elements (glass, water) produce artifacts
- Multi-person scenes struggle with anatomical accuracy in crowds
- When it matters: Large group photos, complex product arrangements, detailed illustrations
- Photographic Realism Ceiling
- Some outputs still exhibit the "AI look" (over-smoothing, unnatural perfection)
- Skin texture and pore detail sometimes appear artificial
- Certain lighting scenarios (harsh midday sun, complex reflections) remain challenging
- When it matters: High-end fashion photography, documentary work, naturalistic portraiture
- Text Rendering Boundaries
- Body text longer than 20-30 words contains errors
- Non-Latin scripts unreliable
- Stylized fonts and handwriting inconsistent
- Text on curved surfaces distorts
- When it matters: Infographics with extensive text, multilingual content, decorative typography
- Cultural and Geographic Specificity
- Training data skews toward Western contexts [Unverified—inferred from output analysis]
- Regional architecture, clothing, and cultural details may lack authenticity
- Niche subcultures and specialized contexts underrepresented
- When it matters: Culturally specific marketing, regional campaigns, authentic representation requirements
- Iteration Depth Limits
- Quality degrades after 6-8 consecutive edits
- Accumulated artifacts compound over edit passes
- Face and logo consistency reduces with excessive iterations
- When it matters: Projects requiring 10+ refinement passes, extensive collaborative editing
When to Choose Alternative Tools
Choose Nano Banana Pro When:
- Photorealism is the primary requirement
- Social media content needs contemporary aesthetic trends
- Natural scenes (landscapes, crowds, events) dominate your needs
- Speed of adoption and ecosystem growth matter for team onboarding
Choose Midjourney When:
- Artistic interpretation adds value over literal accuracy
- Conceptual, abstract, or stylized work fits your brand
- Community-driven prompt libraries and styles benefit your workflow
- Creative vision matters more than production control
Choose Stable Diffusion When:
- You need complete control over model training and customization
- Budget constraints require free/open-source solutions
- Technical team can manage self-hosting and optimization
- Specialized fine-tuning for niche use cases is necessary
Choose Traditional Photography/Design When:
- Technical precision is non-negotiable (architecture, engineering, medical)
- Legal requirements mandate authenticated human-created content
- Brand values emphasize human artistry over AI assistance
- Budget allows for professional services and quality justifies cost
Choose Hybrid Workflows When:
- Projects require both AI efficiency and human quality control
- Text elements exceed AI capabilities
- Brand guidelines demand absolute consistency
- Compliance and authenticity verification are critical
Ethical and Legal Considerations
Frequently Asked Questions (FAQs)
1. How much does GPT Image 1.5 cost compared to hiring a designer?
However, designers provide creative direction, brand understanding, and technical precision AI cannot match. The optimal approach for many businesses is a hybrid model: use AI for high-volume, lower-stakes content (social media, concept testing, stock-style imagery) while reserving designer time for flagship campaigns, brand-defining work, and projects requiring human creative vision.
2. Can GPT Image 1.5 maintain consistent character appearance across multiple images?
- Generate initial character image with detailed description
- Save this image as your character reference
- Use image-to-image mode with the reference for subsequent generations
- Provide consistent prompt structure describing the character
- Accept that minor variations will occur—perfect consistency across wholly new generations is not yet reliable
For projects requiring absolute character consistency (animated series, brand mascots, ongoing campaigns), consider using the AI to generate initial concept, then work with an illustrator to create a definitive model sheet that can be referenced for all future work.
3. Does GPT Image 1.5 work in languages other than English?
- Spanish, French, German, Italian: Generally functional with some reduction in accuracy compared to English
- CJK languages (Chinese, Japanese, Korean): Prompt understanding exists but text rendering in images remains unreliable
- Other languages: Limited testing data available [Unverified]
4. How does GPT Image 1.5 handle copyright and intellectual property in generated images?
- Third-party IP: The model is designed to refuse generating content based on copyrighted characters, trademarked logos, or identifiable celebrity likenesses
- Training data: The model was trained on publicly available images, which may include copyrighted material used under fair use doctrines for training purposes
- Commercial use: Outputs can typically be used commercially, but review OpenAI's current terms and your specific use case
- Attribution: OpenAI does not require attribution for AI-generated images, but some platforms and contexts may require disclosure that content is AI-generated
5. Can I use GPT Image 1.5 to edit existing photos I own?
- Upload your own photos
- Request specific modifications via natural language prompts
- Preserve original elements while changing specified features
- Generate variations on your existing imagery
- The original photo is high quality (minimum 1024px)
- Lighting is good and subject is clearly visible
- The background isn't overly complex
- Your edit request is specific and targeted
6. What's the difference between GPT Image 1.5 and GPT Image 1.5 Lite?
gpt-image-1.5-lite) is the API model designation used by platforms like evolink.ai. Based on available documentation, "Lite" refers to the API endpoint name rather than indicating a reduced-capability version. The model accessible through this endpoint appears to be the same flagship GPT Image 1.5 model available in ChatGPT.Some platforms may offer additional quality tiers or parameter options that could be described as "lite" vs. "full" versions, but OpenAI's official model is simply "GPT Image 1.5." If cost or capability differences exist between platform implementations, check your specific API provider's documentation for clarification.
7. How long are generated image URLs valid, and how should I store images?
- Immediate download: Set up automated downloads in your workflow to capture images immediately after generation
- Cloud storage: Upload to your own S3, Google Cloud Storage, or similar service for permanent archiving
- Metadata preservation: Store associated prompts, parameters, and generation timestamps with each image for future reference
- Naming conventions: Use descriptive, searchable filenames that include project identifiers and version numbers
- Backup strategy: Maintain redundant copies for critical business assets
1. Generate image → receive temporary URL
2. Download image to local/cloud storage within 1 hour
3. Store permanent URL in your database
4. Delete temporary OpenAI URL from your records
5. Reference your permanent storage URL going forward8. Can GPT Image 1.5 generate images suitable for print, or is it only for digital use?
- 1024×1024 pixels (square)
- 1024×1536 pixels (portrait)
- 1536×1024 pixels (landscape)
| Print Size | DPI Needed | Suitable Resolution | GPT Image 1.5 OK? |
|---|---|---|---|
| Social media | 72 DPI | 1200×1200 | ✓ Yes |
| Website hero | 72-96 DPI | 1920×1080 | ✓ Yes |
| Presentation slides | 96-150 DPI | 1920×1080 | ✓ Yes |
| Business card | 300 DPI | 1050×600 | ⚠️ Marginal |
| 8×10" photo print | 300 DPI | 2400×3000 | ✗ No |
| Magazine full page | 300 DPI | 2550×3300 | ✗ No |
| Billboard | 150 DPI+ | 14400×4800+ | ✗ No |
- AI upscaling: Use specialized upscaling tools (Topaz Gigapixel, Real-ESRGAN) to increase resolution post-generation
- Print size limitation: Use AI-generated images only for smaller print elements (icons, spot illustrations) rather than full-bleed pages
- Digital-first strategy: Prioritize AI generation for digital channels and commission traditional photography/illustration for print campaigns
- Vector conversion: For logos and simple graphics, convert AI outputs to vector format for resolution independence
9. Is GPT Image 1.5 better than Midjourney for professional design work?
- You need precise control over iterative edits
- Workflow integration with ChatGPT benefits your team
- Text rendering in images is important
- API automation is required
- Logo and brand element preservation matters
- Speed (4x faster) justifies slightly lower artistic quality
- Enterprise features and support are priorities
- Artistic interpretation enhances your work
- Aesthetic quality is paramount
- Community prompt libraries and styles align with your brand
- You're creating concept art, illustrations, or creative campaigns
- Discord-based workflow fits your team structure
- Budget-conscious solutions are needed
- Use Midjourney for hero images, hero banners, and flagship creative
- Use GPT Image 1.5 for product variants, social content, and iterative client reviews
- Use traditional design for final polish and technical requirements
10. What happens to GPT Image 1 now that 1.5 is available?
- Superior performance (4x faster generation)
- Better instruction following
- Enhanced editing precision
- 20% lower costs for inputs and outputs
- Continued development and improvements


