
A Developer's Guide to the Load Balancer Router

Instead of allowing one server to become overwhelmed, the router intelligently distributes incoming requests across a pool of servers or, in the context of modern AI applications, different AI models. The result is a highly available, performant application that delivers a seamless experience for your users.
How Does a Load Balancer Router Work?
At its core, a load balancer router is designed to eliminate single points of failure. In a typical single-server architecture, if that server is overloaded or goes offline, your entire application grinds to a halt.
A load balancer router sits between your users and your server pool, intercepting every incoming request and deciding which downstream resource is best equipped to handle it at that moment. This concept has evolved significantly from early hardware appliances to the sophisticated software layer that underpins modern, distributed systems. Understanding this principle is the first step toward building resilient systems, especially when dealing with the unpredictable nature of API traffic.
Why Every Modern Application Needs One
For developers, a well-implemented load balancer offers critical advantages:
- High Availability: If a server or API endpoint fails or becomes unresponsive, the router automatically removes it from the pool and redirects traffic to healthy instances. Your application remains online.
- Scalability: To handle increased load, you simply add more servers to the pool. The load balancer will begin routing traffic to them immediately, enabling horizontal scaling without downtime.
- Improved Performance: By distributing the workload, you ensure user requests are always handled by a responsive server, reducing latency and improving the overall user experience.
Think of a load balancer router as your application's first line of defense against outages. It transforms a collection of independent servers into a single, powerful, and resilient system.
Mastering this concept allows you to architect for resilience from the ground up, rather than treating it as an afterthought.
Understanding Core Load Balancing Algorithms
These algorithms provide the logic for distributing the workload. The infographic below illustrates how different strategies work together to manage network traffic effectively.
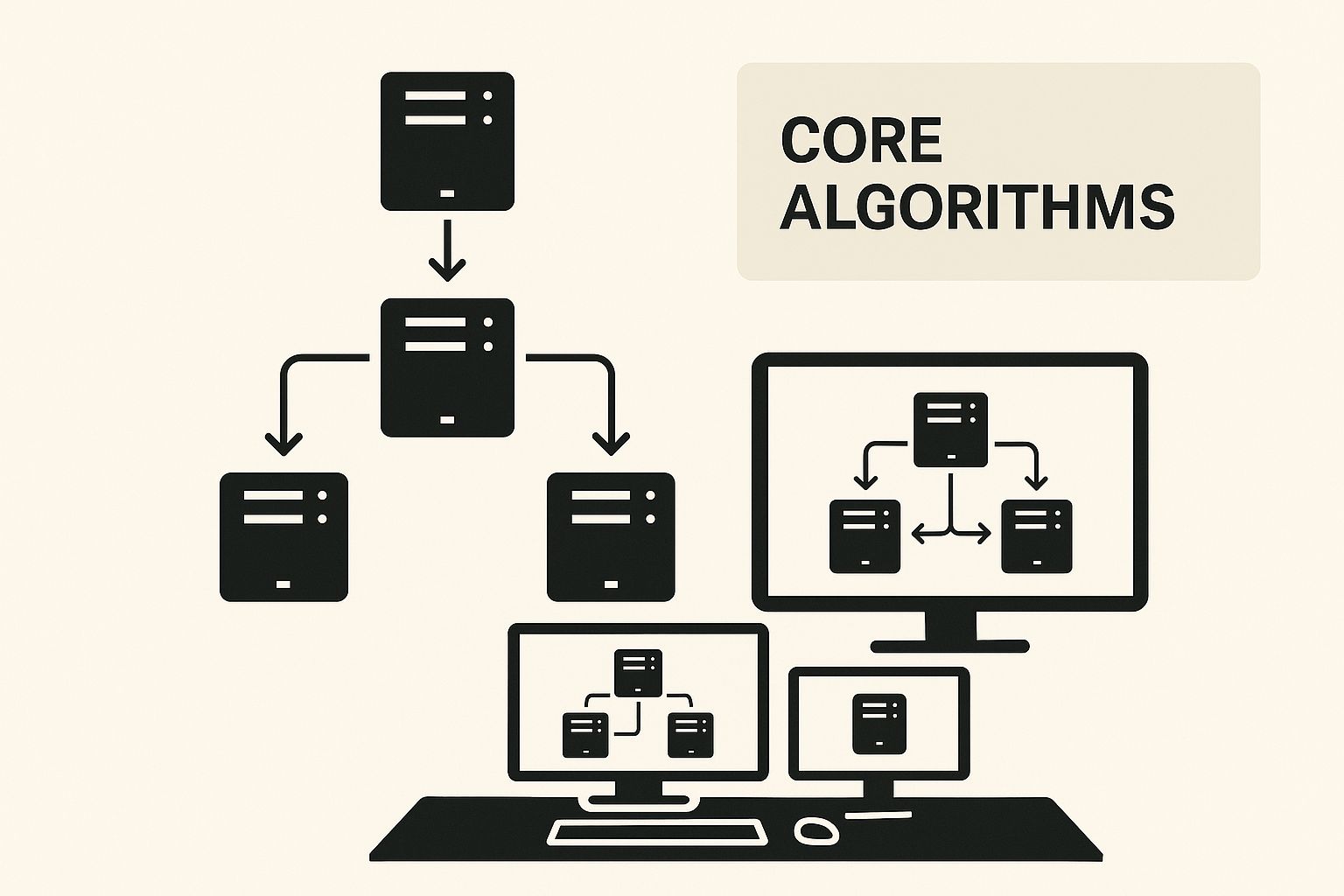
As you can see, these fundamental methods are the building blocks for more sophisticated routing decisions. The goal is to prevent any single server from becoming overwhelmed and causing a system-wide failure.
Common Distribution Methods
So, how does a load balancer decide where to send traffic? It typically uses one of several standard algorithms.
-
Round Robin: This is the simplest and most common method. The load balancer cycles through a list of servers, sending each new request to the next server in the sequence. It's predictable but assumes all servers have equal capacity and all requests have similar processing costs.
-
Least Connections: This is a more dynamic strategy. The algorithm routes new requests to the server with the fewest active connections. This is particularly effective in environments where connection durations vary, preventing one server from being tied up with long-running tasks while others are idle.
-
IP Hash: This method uses a hash of the client's IP address to consistently map that client to the same server. The primary benefit is session persistence (or "stickiness"), which is critical for stateful applications like e-commerce shopping carts where user session data must be maintained on a specific server.
Comparing Common Load Balancing Algorithms
Choosing the right algorithm depends on your application's specific requirements. This table breaks down the most common methods to help you compare them.
| Algorithm | How It Works | Best For | Potential Drawback |
|---|---|---|---|
| Round Robin | Distributes requests sequentially to each server in a list. | Environments where servers are identical and requests are uniform. | Doesn't account for server load or varying processing times. |
| Least Connections | Sends new requests to the server with the fewest active connections. | Situations with long-lived connections or uneven request loads. | Can be more computationally intensive to track connections. |
| IP Hash | Assigns a request to a specific server based on the source IP address. | Applications requiring session persistence (e.g., shopping carts). | Can lead to uneven distribution if certain IP addresses send many requests. |
| Weighted Round Robin | A variation of Round Robin where servers are assigned a "weight" based on their capacity. | Environments with servers of different processing capabilities. | Requires manual configuration of weights and adjustments over time. |
Ultimately, there is no single "best" algorithm. The goal is to align the distribution logic with your application's behavior and your infrastructure's architecture.
Weighted and Intelligent Routing
While these classic algorithms are effective for traditional web traffic, they fall short when routing AI requests across multiple providers. A simple Round Robin algorithm has no concept of cost or availability; it might blindly send your request to an expensive or unavailable provider. This is precisely the problem that an advanced load balancer router like EvoLink solves, intelligently routing your chosen model to the most cost-effective and reliable provider in real-time.
The Modern Challenge of AI Model Routing
Traditional load balancing assumes you're distributing traffic across a fleet of identical servers. This model works well for stateless web requests but breaks down completely when applied to the diverse ecosystem of AI models.
Models like GPT-4, Llama 3, and Claude Haiku are not interchangeable. They differ significantly in their reasoning capabilities, response latency, and, critically, their cost per token. This transforms the problem from simple traffic distribution to a complex, multi-objective optimization puzzle.
Using a basic Round Robin approach here is inefficient and costly. You might route a simple summarization task to your most powerful (and expensive) model, while a complex analytical query could be sent to a faster but less capable model, resulting in a suboptimal response.

From Uniform Servers to Multiple AI Providers
Once you select your desired AI model, an AI-native router must evaluate several factors for every request:
- Provider Cost: The same GPT-4 model can cost 10x more on one provider versus another. Finding the cheapest available provider for your chosen model delivers immediate savings.
- Provider Availability: Is the provider currently online and responsive? Real-time health checks ensure your requests always reach a working endpoint.
- Provider Latency: Which provider offers the fastest response time right now? Dynamic performance monitoring routes to the most responsive provider at that moment.
An intelligent AI router doesn't just balance load; it optimizes for business outcomes. For your selected model, it makes a dynamic, informed decision for every API call to deliver the best performance at the lowest possible cost by choosing the optimal provider.
A Code Example for Smart Provider Routing
This conceptual JavaScript function demonstrates the logic for selecting the optimal provider for a chosen model. It checks provider availability and cost to route to the best endpoint.
// A conceptual function to select the best provider for a chosen model
async function routeToProvider(selectedModel) {
// User has already selected GPT-4 as their model
const providers = [
{ name: 'OpenAI', endpoint: 'https://api.openai.com/v1/chat/completions', cost: 0.03, available: true },
{ name: 'Azure', endpoint: 'https://azure.openai.com/v1/chat/completions', cost: 0.035, available: true },
{ name: 'Provider-A', endpoint: 'https://api.provider-a.com/v1/gpt-4', cost: 0.015, available: true },
{ name: 'Provider-B', endpoint: 'https://api.provider-b.com/v1/gpt-4', cost: 0.012, available: false }
];
// Filter to only available providers
const availableProviders = providers.filter(p => p.available);
// Sort by cost, cheapest first
availableProviders.sort((a, b) => a.cost - b.cost);
// Select the cheapest available provider
const selectedProvider = availableProviders[0];
console.log(`Routing ${selectedModel} to ${selectedProvider.name} at $${selectedProvider.cost} per request`);
// In a real application, you would make the API call here
// const response = await fetch(selectedProvider.endpoint, { ... });
// return response.json();
return {
model: selectedModel,
provider: selectedProvider.name,
endpoint: selectedProvider.endpoint,
cost: selectedProvider.cost
};
}
// Example usage - user selected GPT-4
routeToProvider('GPT-4').then(result => console.log(result));While this code illustrates the core concept, building a production-ready system involves much more: managing API keys for dozens of providers, tracking real-time pricing and availability, implementing automatic failover when providers go down, and continuously monitoring performance.
Putting Advanced AI Routing into Action with EvoLink
Building an intelligent AI router from scratch is a significant engineering challenge. It requires managing multiple API keys, monitoring real-time model performance, coding robust failover logic, and continuously updating the system as new models are released. This is why a managed solution like EvoLink is a game-changer for development teams.
This unified approach dramatically reduces operational overhead and frees your engineering team to focus on your core product, not on managing AI infrastructure.
How Intelligent Routing Works in the Real World
Here's how EvoLink's core features deliver tangible benefits:
- Automatic Model Failover: If a primary provider like OpenAI experiences an outage or performance degradation, EvoLink automatically reroutes API calls to a healthy alternative provider offering the same model. Your application continues to function seamlessly.
- Dynamic Performance Routing: The system continuously monitors the latency and throughput of all available providers for your chosen model, sending each request to the provider that can deliver the fastest response at that moment.
- Intelligent Cost Optimization: EvoLink automatically routes your request to the most cost-effective provider for your chosen model, constantly comparing prices across dozens of providers to ensure you're always getting the best rate.
By intelligently directing traffic, developers using EvoLink often achieve cost savings between 20-70%. This isn't just about selecting the cheapest provider; it's about making the smartest provider choice for every request to balance performance and budget while using your preferred models.
A Practical Code Example with EvoLink
Consider this Python example. You provide a prioritized list of models, and EvoLink manages all routing, optimization, and failover automatically.
import os
import requests
# Set your EvoLink API key from environment variables
api_key = os.getenv("EVOLINK_API_KEY")
api_url = "https://api.evolink.ai/v1/chat/completions"
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}
# Define your preferred model with fallback options
# EvoLink routes each model to the cheapest available provider
# If your first choice is unavailable, it fails over to the next model in your list
payload = {
"model": ["openai/gpt-4o", "anthropic/claude-3.5-sonnet", "google/gemini-1.5-pro"],
"messages": [
{"role": "user", "content": "Analyze the sentiment of this customer review: 'The product is good, but the shipping was slow.'"}
]
}
try:
response = requests.post(api_url, headers=headers, json=payload)
response.raise_for_status() # Raise an HTTPError for bad responses (4xx or 5xx)
print(response.json())
except requests.exceptions.RequestException as e:
print(f"An API error occurred: {e}")This snippet demonstrates the power of abstraction. Your application code remains clean and focused on business logic, while a powerful load balancer router works in the background to make your application more resilient and cost-effective.
EvoLink eliminates the need to build and maintain a complex in-house system, providing a production-ready solution that delivers immediate results. This allows your team to integrate world-class AI capabilities faster and more efficiently.
Practical Routing Strategies You Can Implement
Let's explore four practical strategies you can implement.

Cost-Based Routing
This strategy prioritizes your budget. Cost-based routing automatically sends your request to the most affordable provider for your chosen model.
Latency-Based Routing
When user experience is paramount, latency-based routing is the optimal choice. It is essential for real-time applications like customer service chatbots or interactive AI tools where every millisecond matters.
The router continuously monitors the real-time performance of all available providers for your chosen model. When a request arrives, it is instantly forwarded to the provider with the lowest current response time, ensuring your users receive the fastest possible reply without changing which model you're using.
Failover Routing
Failover routing is your application's safety net. Inevitably, API providers experience outages or performance degradation. When this occurs, the router automatically reroutes requests to the next healthy model in a predefined priority list.
This strategy is fundamental to building high-availability systems that can gracefully handle provider failures without any impact on the end-user experience.
Frequently Asked Questions
What's the Difference Between a Load Balancer and a Router?
While often used together, these components serve distinct functions in a network.
Can I Just Build My Own AI Model Load Balancer?
Technically, yes, you can build a custom solution. However, the complexity of a production-grade AI router is substantial.
A robust solution requires more than just basic request distribution. You would be responsible for securely managing dozens of API keys, tracking real-time cost and latency for each model, implementing reliable health checks, and engineering effective failover logic. Furthermore, this system would require constant maintenance to incorporate new models and adapt to API changes.
This is where a managed solution like EvoLink provides significant value. We have already engineered a production-hardened system that handles all of this complexity. You get a single, unified API with intelligent routing built-in, allowing your team to focus on your core product instead of infrastructure. This approach can yield immediate cost savings of 20-70% and ensure high reliability from day one.
How Does a Load Balancer Router Actually Make My App More Reliable?
Reliability is achieved through two primary mechanisms: redundancy and automated health checks.
By distributing requests across multiple models or servers, a load balancer eliminates single points of failure. If one model API becomes unavailable or a server crashes, the application remains operational because traffic is automatically directed to the healthy alternatives.
The system also performs continuous health checks on each endpoint, much like monitoring vital signs. It regularly sends requests to verify that each endpoint is responsive. If an endpoint fails these checks or returns errors, the router instantly removes it from the active pool and seamlessly redirects new requests to the remaining healthy endpoints. This automatic failover is what ensures high availability, even during partial system failures.


