

When an LLM API Wrapper Becomes Infrastructure
Most engineering teams don't set out to build an LLM API wrapper.
There is usually no kickoff doc, no explicit roadmap, and no moment where someone says, "Let's abstract all our model providers." Instead, wrappers emerge quietly—line by line—as teams try to keep production systems stable.
This article explains why wrappers often appear in production systems, how to recognize when one has crossed the line into infrastructure, and what decisions teams typically face next.
What an LLM API Wrapper Actually Is (in Practice)
In production systems, a wrapper is rarely a single component. It is a growing layer of logic that sits between your application and one or more LLM providers.
Common responsibilities include:
- Normalizing request and response schemas
- Handling retries, timeouts, and provider-specific errors
- Managing model selection or fallback logic
- Injecting prompts, system messages, or safety rules
- Tracking usage for cost attribution, logging, or audits
Most wrappers start as convenience code. Many end up becoming mission-critical paths.
Why Wrappers Emerge (Even When No One Plans Them)
Teams do not build wrappers because they want abstraction. They build them because direct integration often stops being reliable under production pressure.
Below are the most common forces that push teams in this direction.
1. Behavioral Inconsistency Is Harder Than Interface Inconsistency
API schemas are relatively easy to normalize. Runtime behavior is not.
Teams often encounter differences such as:
- Streaming responses that may stall, chunk differently, or fail silently
- Errors that can look similar but require different operational handling
- Timeouts that may behave unpredictably under load
- Subtle differences in prompt interpretation or truncation
When these issues surface in production, a common short-term response is to add local, provider-specific handling:
if provider == X:
retry differently
if streaming stalls:
fallback to non-streamOver time, these conditionals accumulate. A wrapper forms not to "clean the API," but to contain behavioral unpredictability.
2. Prompt Control Starts as Convenience, Ends as Policy
Early on, prompts are just strings passed from application code.
Later, they can become:
- Versioned assets
- Shared across multiple services
- Coupled to evaluation baselines
- Sometimes reviewed for safety, compliance, or quality standards (depending on the product and risk profile)
At this point, prompts stop behaving like application details and start behaving like configuration.
Wrappers can emerge to:
- Centralize prompt injection
- Enforce system-level instructions
- Reduce accidental drift across services
What looks like "prompt helpers" is often the first sign of policy centralization.
3. Cost Visibility Fractures Without an Intermediary Layer
Direct API usage can scatter cost signals across providers:
- Different pricing units
- Different billing cadences
- Different rate-limit semantics
Engineering teams often feel this pain early—sometimes before Finance does.
Wrappers can appear to:
- Track usage consistently
- Attribute cost to features or teams
- Apply guardrails before bills spike
This is not necessarily FinOps maturity. It is often defensive engineering.
4. Reliability Guarantees Do Not Scale Inside Product Code
As LLMs move from experiments to dependencies, teams may start needing:
- Fallbacks
- Provider rotation
- Graceful degradation
Embedding this logic directly in application code can create tight coupling and brittle paths.
A wrapper becomes a natural place to express reliability intent:
- "If this fails, try that."
- "If latency exceeds a threshold, downgrade."
- "If quota is hit, switch models."
At this stage, the wrapper is no longer optional glue. It can start enforcing service-level expectations.
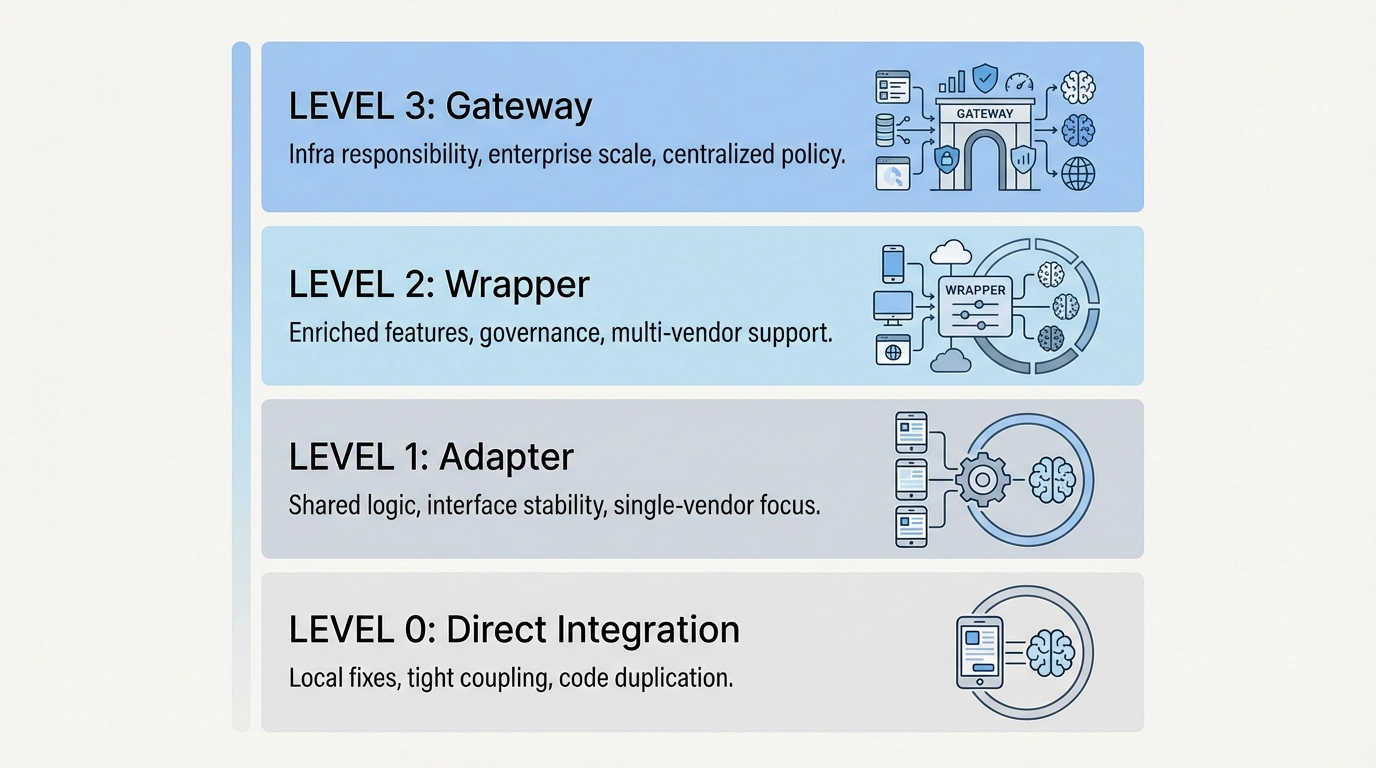
The Wrapper Maturity Model
Many teams underestimate how far their wrapper has already evolved. The table below outlines a common progression.
| Stage | What It Looks Like | Common Pain | What Usually Comes Next |
|---|---|---|---|
| Direct Integration | App calls providers directly | Scattered exceptions | Minimal adapter |
| Adapter | Unified schema, light helpers | Behavioral drift | Centralized retries |
| Wrapper | Prompts, routing, cost tracking | Ownership bottlenecks | Infra-level thinking |
| Gateway | Explicit contracts & observability | Trade-offs surfaced | Organizational alignment |
If your system is operating at Stage 2 or beyond, the wrapper often stops being purely temporary and starts taking on infrastructure-like responsibilities.
When a Wrapper Quietly Becomes Infrastructure
Teams often realize too late that a line has been crossed.
Common signals include:
- Multiple teams depend on the same wrapper
- Changes require coordination and rollout plans
- Failures affect unrelated services
- The layer needs documentation, ownership, and monitoring
At this point, the wrapper can start to function like a gateway layer—even if it isn't named or operated as one yet.
The difference is not just capability. It is intent and operation.
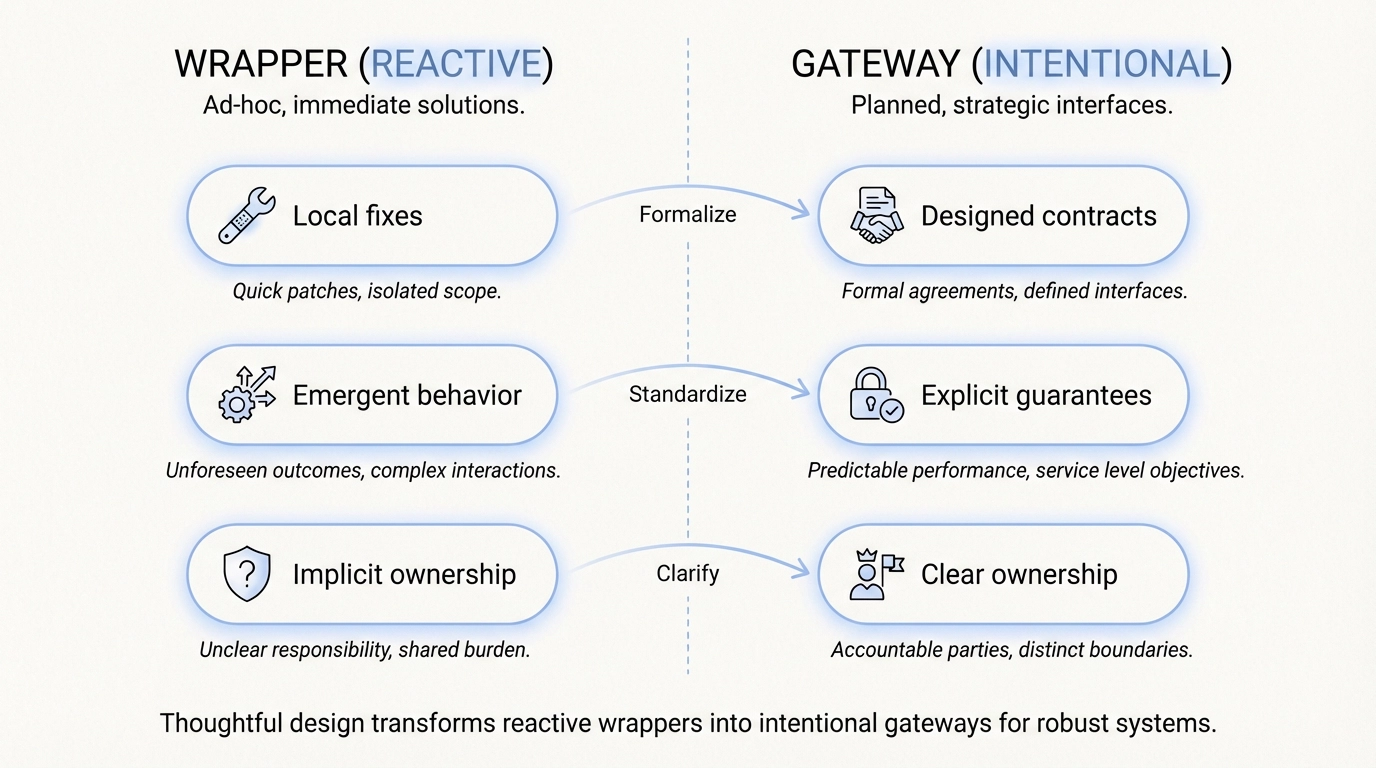
Wrappers are often reactive. Gateways are designed.
Build or Evolve: The Real Decision Teams Face
The question is rarely "Should we build a wrapper?" That decision has often already been made implicitly.
The real question becomes:
Ad hoc evolution often leads to:
- Hidden coupling
- Inconsistent guarantees
- Knowledge concentrated in a few engineers
Intentional infrastructure tends to bring:
- Clear contracts
- Observable behavior
- Explicit trade-offs
Neither path is universally right. But not choosing is still a choice.
Anti-Patterns to Watch For
Teams that struggle with wrappers often fall into similar traps:
- Provider-specific logic leaking into product code
- Multiple wrappers maintained by different teams
- Routing logic without evaluation baselines
- Cost tracking without usage attribution
- Critical paths with no telemetry or alerts
These patterns often signal that the system has outgrown informal abstraction.
A Simple Self-Assessment Checklist
If you answer "yes" to three or more, the wrapper is likely already part of your architecture:
- Do provider-specific conditionals appear across services?
- Are prompts injected or modified outside product code?
- Is there no single source of truth for LLM usage or cost?
- Is retry or fallback logic duplicated in multiple places?
- Would a provider outage require coordinated code changes?
If so, the wrapper is no longer optional.
👉 Next Step
the next question is whether direct APIs are still the right abstraction—or if a gateway is now worth the trade-off.
Closing Thought
Wrappers are not a mistake.
They are a symptom of scale, complexity, and production pressure.
The real risk is treating a critical abstraction layer as "just helpers" long after it has become infrastructure.
Understanding when a wrapper has crossed that boundary is the first step toward deciding what it should become next.
FAQ
What is an LLM API wrapper?
A wrapper is an intermediary layer that can normalize behavior, enforce policy, and manage reliability across one or more LLM providers.
When should a team build an LLM wrapper?
Many teams end up building one implicitly as soon as production reliability, cost control, or prompt governance become recurring concerns.
What is the difference between a wrapper and a gateway?
In practice, wrappers are often reactive collections of fixes, while gateways are intentionally designed infrastructure with explicit contracts.
How do I know when to move beyond a wrapper?
When multiple teams depend on it, outages propagate widely, and operational guarantees matter, the wrapper has likely become infrastructure and should be treated accordingly.